Robot Learning from a Physical World Model
Abstract: We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
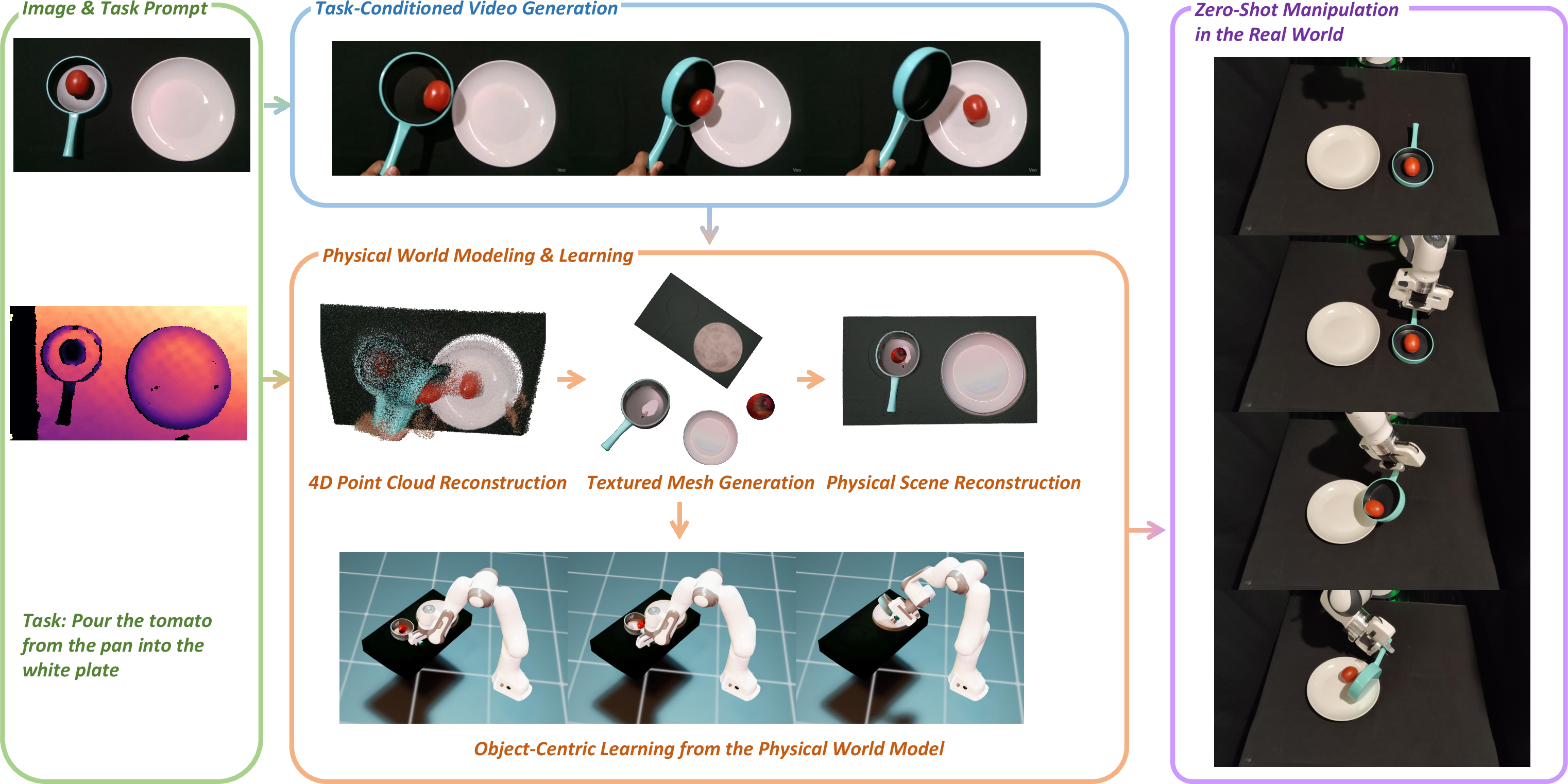
This paper introduces PhysWorld, a system that teaches robots how to do tasks by “watching” videos and then practicing in a realistic, physics-based virtual world. Instead of collecting lots of real robot data, the system generates a short video from a single picture and a text command (like “put the book on the shelf”), builds a matching 3D scene that follows real-world physics, and learns actions that a real robot can perform safely and accurately.
Key Objectives
PhysWorld aims to answer three simple questions:
- Can robot-friendly videos be generated from a single image and a task instruction?
- Can we turn those videos into a believable, physics-correct 3D world the robot can learn in?
- Can a robot learn actions from that world without any real-world training data and still succeed on real tasks?
How It Works (Methods)
Think of the system like learning from a tutorial video, building a realistic “game level,” then practicing inside that level until you can do it for real.
Step 1: Make a task video from a single picture and text
- Input: one RGB-D image (a color photo plus depth, which tells how far things are) and a task command.
- A video generator creates a short clip showing the task being done (for example, a book being placed on a shelf).
In everyday terms: you give the system one photo of the scene and the instruction, and it makes a “how-to” video of what should happen next.
Step 2: Rebuild the physical world from the video (the “digital twin”)
Robots need more than pixels; they need a world with shapes, sizes, and physics (gravity, friction).
PhysWorld reconstructs the scene in 4D:
- 4D means 3D space plus time. It’s like a flipbook of 3D snapshots showing how objects move.
It then creates a physically usable version of the scene:
- Object and background meshes: a “mesh” is a digital shell of an object (like the skin of a 3D model).
- Physical properties: add mass and friction so objects behave realistically (heavy pots don’t fly away, books don’t slide like ice).
- Gravity alignment: make sure “down” in the model is the same as down in the real world.
- Collision optimization: adjust object placements so nothing starts out stuck inside something else.
Analogy: imagine you’re rebuilding the room from the video inside a physics-based game engine (like a more realistic Minecraft), making sure the floor is flat, gravity works, and objects don’t overlap.
Step 3: Teach the robot to follow object motion (not hand motion)
Instead of copying hand or robot arm movements from the video (which can be messy or hallucinated), PhysWorld tracks objects themselves:
- It estimates each object’s pose over time (where it is and how it’s rotated).
- The robot learns to move so that the object ends up in the same place and orientation as shown in the video.
This is called object-centric learning: follow the object, not the hand.
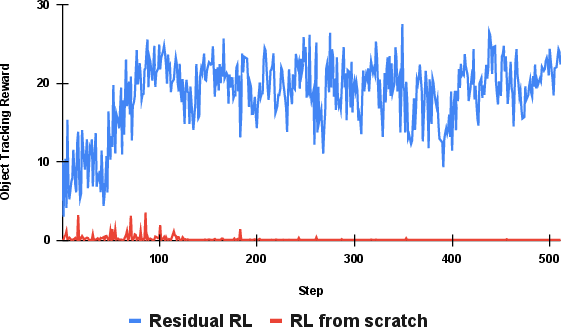
Step 4: Residual reinforcement learning (learn smart corrections)
Reinforcement learning (RL) teaches the robot by trial and error using rewards (like points in a game) inside the physics model.
PhysWorld adds RL on top of simple “baseline” actions:
- Baseline actions: try a standard grasp and a motion plan (like using a basic recipe).
- Residual RL: learn small corrections that improve the baseline (like tweaking the recipe to get better results).
This makes learning faster and more reliable because the robot isn’t starting from scratch; it’s refining something that’s already close.
Step 5: Deploy on a real robot
After training in the digital twin, the robot performs the task in the real world—without additional real-world practice.
Main Findings
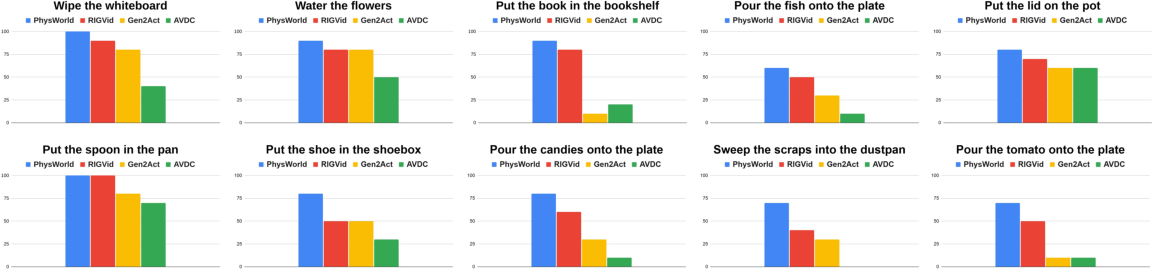
Across many real tasks (like “put the book on the shelf,” “pour candy onto a plate,” “put the lid on the pot”), PhysWorld shows:
- Higher success rates: On average, it succeeds about 82% of the time, beating a strong baseline method at 67%.
- Better reliability: The physics-based world reduces common failures like bad grasps and lost tracking.
- Object-centric works better than hand-centric: Following objects (not hands) led to big gains (for example, “book to bookshelf” success jumped from 30% to 90%).
- Faster learning: Residual RL learns quicker and more robustly than starting RL from scratch.
Why This Matters
- No real robot training data needed: PhysWorld can learn from generated videos and simulations, saving time and cost.
- More generalizable: It works across different tasks and scenes because it doesn’t depend on carefully collected demonstrations.
- Physically grounded: By respecting gravity, friction, and collisions, the learned actions are safer and more accurate when transferred to real robots.
- A step toward “watch and do”: Robots can learn from visual instructions and practice in a realistic virtual world, then act correctly in real life.
Limitations and Future Impact
- The virtual world isn’t perfect: If the reconstructed 3D scene isn’t accurate (especially in hidden areas), the robot might be off. Better multi-view scans or improved generators could help.
- Sim-to-real gaps: Physics simulators aren’t exactly the real world, but the paper shows solid results despite that.
Overall, PhysWorld shows a practical way to turn “what you see” in a video into “what a robot can do,” using a smart combination of video generation, physics modeling, and efficient learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or underexplored in the paper, intended to guide future research:
- Dependence on high-quality video generation: most models yield low “usable-video” ratios; no method is provided to automatically detect, rank, repair, or filter generated videos for downstream use.
- Single-sample supervision: policies are trained from a single generated video per task; the value of aggregating multiple diverse generations, multi-hypothesis learning, or consensus planning remains unexplored.
- Monocular 4D depth calibration: aligning MegaSaM depth via a single global scale/shift using only the first frame may not correct per-frame biases or temporal drift; methods for temporally consistent metric calibration and uncertainty-aware reconstruction are needed.
- Background completion assumptions: the object-on-ground and planar support assumptions for occluded regions can fail (e.g., shelves, hanging objects, concave geometries); generalizable 3D completion without strong planar priors is open.
- Image-to-3D object meshes from a single view: occluded geometry is hallucinated; the impact of shape errors on grasping/contacts is not quantified, and strategies to reduce them (active perception, multi-view capture, priors with uncertainty) are not developed.
- Gravity alignment reliance on ground-plane RANSAC: scenes without a reliable planar support or with sloped/curved supports are not handled; robust gravity estimation without planar assumptions is an open question.
- Limited collision optimization: only vertical translations are optimized against a background SDF; lateral adjustments, object–object collisions, and full 6-DOF placement optimization are not addressed.
- Physical property estimation via VLM commonsense: friction, mass, and compliance parameters are not validated or adapted; systematic system identification, online adaptation, and uncertainty bounds are absent.
- Lack of articulated-object modeling: joints, kinematic constraints, and articulation discovery for doors, drawers, lids, etc., are not incorporated into the world model or policy learning.
- Non-rigid and fluid phenomena: deformables (cloth, cables) and fluids (e.g., watering plants) are not physically modeled; the approach for tasks requiring fluid/soft-body dynamics is unclear.
- Object pose supervision robustness: use of FoundationPose on generated videos under motion blur/occlusion/hallucinations is brittle; recovery strategies when pose tracking fails are not provided.
- Viewpoint consistency: the method assumes the generated video’s viewpoint aligns with the robot’s camera; handling viewpoint mismatch or moving cameras at deployment is not studied.
- Sim-to-real gap in contacts: no systematic domain randomization or identification is presented for contact/friction discrepancies; real-world sensitivity to simulator parameters is unquantified.
- Residual RL dependence on baseline actions: when grasp proposals or motion plans are severely wrong, it is unclear how reliably residuals can recover; diagnostics and fallback mechanisms are not described.
- Reward shaping limitations: simple position/quaternion L2 penalties may not capture task-specific constraints (e.g., insertion tolerances, force profiles); more physically meaningful and task-agnostic rewards are needed.
- Policy generalization: policies appear to be trained per task; learning a single multi-task policy across many generated demonstrations and testing cross-task generalization is not explored.
- Real-time deployment details: latency, update rates, and robustness under sensor noise, delays, and perception dropouts are not specified; end-to-end closed-loop performance analysis is missing.
- Safety and constraint handling: executing possibly hallucinated plans lacks safety filters or constraint enforcement; human-in-the-loop oversight or runtime verification is not addressed.
- Automatic video selection: although a “usable ratio” is reported, no automatic confidence scoring or selection mechanism (for poses, physics plausibility, or task consistency) is proposed.
- Generator–world model co-training: the proposed future direction (training generators for physical plausibility using the world model) is not instantiated; how to define training signals and prevent mode collapse is open.
- Compute and scalability: reconstruction, mesh generation, property estimation, and per-task RL training costs are not measured; approaches to amortize or reuse components across tasks are not provided.
- Multi-object concurrent manipulation: scalability to multiple simultaneously manipulated objects with complex contact chains is untested; inter-object coupling and sequencing remain open.
- Tool-use transfer: generated tools may differ in geometry/affordance from real tools; strategies to reconcile shape/affordance mismatches for reliable grasps are not discussed.
- Robustness to clutter and domain shifts: performance under heavy clutter, lighting variations, and texture changes is not reported; failure modes in such settings are unknown.
- Perception at deployment: reliance on
FoundationPosefor real-time 6D object pose across categories/occlusions is not benchmarked; fallbacks (e.g., trackers, multi-sensor fusion) are absent. - Uncertainty propagation: uncertainties from video generation, reconstruction, properties, and pose estimation are not propagated into planning/RL; belief-space or risk-aware control is not explored.
- Long-horizon tasks and re-planning: integration of multiple videos, subgoal discovery, mid-task re-generation, and recovery from execution errors over long horizons is not studied.
- Baseline scope: comparisons are limited to zero-shot methods; head-to-head with data-rich baselines (e.g., BC-Z, diffusion policies) would better contextualize benefits and limitations.
- Component-level ablations: the contributions of gravity alignment, property estimation, collision optimization, and pose-supervision choices are not isolated or quantified.
- Reality–video consistency: when generated videos depict objects not present (or with mismatched geometry) in the real scene, no mechanism checks consistency or triggers re-generation/correction.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the methods and findings of the paper, with standard engineering integration and safety checks.
- Physically grounded prompt-to-policy prototyping for robots (software, robotics R&D)
- Description: Rapidly create manipulation policies from a single RGB-D scene image and a text task (e.g., “put the lid on the pot”) by generating a task-conditioned video, reconstructing a digital twin, and training an object-centric residual RL policy in simulation before real-world execution.
- Sectors: Manufacturing (fixture-less assembly variants), warehousing (ad hoc sorting/put-away), service robotics (kitchen/household), research labs.
- Tools/products/workflows: “Prompt→Video (Veo3/Tesseract)→4D reconstruction (MegaSaM + metric calibration)→Mesh generation (image-to-3D, inpainting)→VLM-based physical property estimation→gravity alignment & collision optimization→object pose tracking (FoundationPose)→baseline grasp+plan (AnyGrasp, cuRobo)→residual RL (PPO)→deployment” toolchain; ROS/Isaac/MuJoCo plugin that packages PhysWorld.
- Assumptions/Dependencies: Access to an image-to-video generator with sufficient “usable-video” quality; one RGB-D image with known intrinsics for metric calibration; tasks dominated by rigid-body interactions; available grasping and motion planning baselines; simulator fidelity adequate for the task’s contact dynamics; human-in-the-loop safety validation.
- Zero-shot execution of simple household/service tasks (service robotics, consumer robotics)
- Description: Execute everyday tasks demonstrated in the paper—e.g., putting a book in a bookshelf, placing a lid, pouring from a pan to a plate, sweeping into a dustpan—without collecting robot demonstrations, by grounding generated video motions into object-centric policies.
- Sectors: Home assistance, hospitality, light food service, facilities maintenance.
- Tools/products/workflows: On-robot “task authoring” via text prompts; onboard or edge inference to generate demo video, reconstruct scene, and learn/refine residual policy; fallback to baseline grasp-and-plan if residual policy fails.
- Assumptions/Dependencies: Structured environments and moderate clutter; safe end-effector and grasp coverage; reliable pose estimation for target objects in the current scene; human supervision for deployment and recovery.
- Synthetic training and evaluation data generation for manipulation (academia, software)
- Description: Use the pipeline to generate physics-grounded demonstrations at scale for benchmarking manipulation algorithms and evaluating sim-to-real transfer under controlled perturbations (friction, mass, clutter).
- Sectors: Academic research, robotics software vendors, benchmarking bodies.
- Tools/products/workflows: Dataset generator that emits scene meshes, object trajectories, and reward logs; “usable-video ratio” as a standardized metric for evaluating video generators for robotics.
- Assumptions/Dependencies: Licensing/usage rights for video generators; reproducible seeds and metadata for scientific rigor; simulator parameter logging.
- Rapid “digital twin from one view” for manipulation trials (simulation vendors, digital twin)
- Description: Produce a physically interactable digital twin from a single RGB-D snapshot and a generated video, enabling fast what-if testing (e.g., grasp stability, clearance checks).
- Sectors: Simulation platforms, industrial simulation/QA, robotics integrators.
- Tools/products/workflows: One-click conversion to textured meshes; VLM-aided mass/friction defaults; automatic gravity alignment and collision-free initialization.
- Assumptions/Dependencies: Object-on-ground/supporting-surface assumption for occlusion completion; coarse property estimates acceptable for initial trials; manual override interfaces for material/physics corrections.
- Low-cost teaching modules for robot manipulation (education)
- Description: Hands-on labs where students go from text prompts to executable policies, studying object-centric tracking, residual RL, and sim-to-real pitfalls.
- Sectors: Universities, bootcamps, corporate training.
- Tools/products/workflows: Courseware that bundles the pipeline; assignments comparing optical flow vs. point tracks vs. object poses (showing robustness of pose tracking); ablations on baseline vs. residual RL.
- Assumptions/Dependencies: Compute for video generation; access to simulators and entry-level manipulators; curated tasks with clear safety envelopes.
- Safety-aware human-in-the-loop robot programming (industry)
- Description: Use the generated videos as interpretable task “intent” and the physical world model for validation (clearance, reachability, IK feasibility) before execution in facilities.
- Sectors: Manufacturing changeover, logistics, lab automation.
- Tools/products/workflows: Visual “intent preview” + automatic feasibility checks; policy sandboxing in sim; operator approval gates.
- Assumptions/Dependencies: Clear safety policies; reliable perception of scene objects; fail-safes and E-stop integration.
- Vendor-neutral evaluation harness for video generation in robotics (academia, software)
- Description: Benchmark multiple I2V models (e.g., Veo3, Tesseract) by the downstream “usable-video” ratio and success rates on a fixed set of manipulation tasks using the same PhysWorld pipeline.
- Sectors: Research, model providers, standards bodies.
- Tools/products/workflows: Reproducible benchmarking suite with fixed prompts, camera intrinsics, and tasks; per-task success criteria and logs.
- Assumptions/Dependencies: Stable generator APIs; versioned artifacts; community adoption.
Long-Term Applications
These applications are feasible with further research, scaling, or productization (e.g., better generative models, higher-fidelity simulation, more robust perception).
- General-purpose manipulation via large-scale generated curricula (service robotics, manufacturing)
- Description: Train broad, generalizable policies by synthesizing diverse task videos and world models at scale, then distill into deployable policies that adapt to novel objects and layouts.
- Sectors: Household robotics, small-batch manufacturing, retail restocking.
- Tools/products/workflows: “PhysWorld Studio” for massive curriculum generation; continual learning with residual policies; policy distillation from many prompt-conditioned trainings into a unified model.
- Assumptions/Dependencies: Higher “usable-video” quality across long horizons; more accurate property estimation and contact modeling; robust cross-domain sim-to-real transfer.
- Autonomous assistants with object-centric shared autonomy (healthcare, eldercare, logistics)
- Description: Use generated videos to propose object motion plans and constraints that a human can accept/adjust; robots refine via residual RL and execute safely around people.
- Sectors: Hospitals (fetch-and-carry), eldercare (tidy-up, placing objects), office logistics.
- Tools/products/workflows: Mixed-initiative UI showing predicted object trajectories; intent correction via voice/gesture; on-device residual policy adaptation.
- Assumptions/Dependencies: Reliable human-robot interaction safety; on-the-fly re-planning and perception under occlusion; regulatory clearance.
- Standards and policy frameworks for AI-generated demonstrations in robotics (policy, governance)
- Description: Establish documentation and audit standards for using generated content in robot training, including source transparency, safety validation in a physical world model, and bias/hallucination mitigations.
- Sectors: Regulatory bodies, industry consortia, standards organizations.
- Tools/products/workflows: Model cards and “demo cards” for generated videos; checklists for physics validation and failure mode analyses; traceable logs linking prompts→videos→policies→outcomes.
- Assumptions/Dependencies: Multi-stakeholder cooperation; alignment with existing safety standards (e.g., ISO/IEC for robots).
- Physics-grounded content creation for AR/VR and digital twins (media, construction, smart buildings)
- Description: Create interactable, physically consistent scenes from single-view captures plus generated videos, enabling realistic planning and training in virtual environments.
- Sectors: AR/VR training, smart facility planning, AEC (architecture/engineering/construction).
- Tools/products/workflows: Single-view-to-interactable-digital-twin pipelines; physics-consistent “what-if” simulations for layout, reach, and access.
- Assumptions/Dependencies: Improved occlusion completion for complex geometry; material/structure inference beyond commonsense heuristics.
- Automated task authoring for robot fleets (software platforms, MLOps for robotics)
- Description: Fleet-scale “Prompt→Skill” services where operators specify goals and the system generates validated skills, monitors sim-to-real gaps, and performs scheduled re-training.
- Sectors: 3PL logistics, micro-fulfillment centers, large campuses.
- Tools/products/workflows: Policy registries, A/B testing of generated skills, automated safety gates (IK, collision, force thresholds), telemetry-driven residual re-training.
- Assumptions/Dependencies: Scalable inference and training infrastructure; robust monitoring; change management in dynamic environments.
- Safer development of high-risk manipulation via simulation-first learning (energy, heavy industry)
- Description: Train policies on generated demonstrations and world models for hazardous tasks (e.g., handling hot/corrosive items) before any real trials; use residual RL to adapt conservatively on real hardware.
- Sectors: Energy, chemical processing, mining, nuclear.
- Tools/products/workflows: High-fidelity contact/thermal models; expanded property estimation (temperature-dependent friction, compliance), conservative policy constraints.
- Assumptions/Dependencies: Advanced simulators and sensors; rigorous risk assessment; certifications.
- Cross-embodiment transfer with object-centric targets (multi-robot ecosystems)
- Description: Learn object-centric policies that transfer across grippers/arms by re-targeting object pose trajectories and letting residuals capture embodiment-specific corrections.
- Sectors: Robotics OEMs, integrators, multi-vendor deployments.
- Tools/products/workflows: Embodiment adapters that map object-centric plans to different kinematics; residual layers fine-tuned per robot; shared simulation assets.
- Assumptions/Dependencies: Consistent perception stacks; alignment of safety and control interfaces; variability in hardware tolerances.
- Continuous scene reconstruction and active perception for improved world models (research → product)
- Description: Extend from single RGB-D image to multi-view/active scanning to reduce reconstruction errors and close sim-to-real gaps in cluttered or deformable environments.
- Sectors: Advanced service robotics, inspection.
- Tools/products/workflows: Onboard scanning behaviors; multi-view fusion; online update of digital twins and re-optimization of policies.
- Assumptions/Dependencies: Efficient SLAM/NeRF/3DGS pipelines; real-time mesh updates; handling of non-rigid objects and fluids.
- Compliance-aware pouring, insertion, and tool use (advanced manipulation)
- Description: Integrate richer physical models (fluids, deformables, tight-tolerance contacts) to tackle complex tasks suggested by generated videos (e.g., precise insertions, food manipulation).
- Sectors: Food service, lab automation, small-part assembly.
- Tools/products/workflows: Hybrid simulators for rigid/deformable/fluids; tactile feedback integration; learning residuals over compliant control.
- Assumptions/Dependencies: Simulator advances; better sensing (force/tactile/vision); domain-specific safety envelopes.
- Curriculum learning for robust residual RL (academia, platforms)
- Description: Systematically stage baseline→residual training using progressively harder generated videos and perturbations to yield resilient policies.
- Sectors: Research labs, platform providers.
- Tools/products/workflows: Auto-curricula generators; robustness test suites (friction shifts, occlusions, adversarial clutter); reward shaping libraries for object-centric tracking.
- Assumptions/Dependencies: Scalable training compute; reliable measurement of robustness; reproducible perturbation models.
Notes on overarching assumptions and dependencies that affect feasibility:
- Video generation quality is a bottleneck; higher “usable-video” ratios (as with Veo3 in the paper) translate to more reliable downstream policies.
- The pipeline assumes access to at least one RGB-D observation for metric calibration and known camera intrinsics; pure RGB workflows would require new scale-recovery strategies.
- VLM-based physical property estimation is approximate; mission-critical deployments require manual overrides, calibration routines, or system identification.
- Sim-to-real gaps remain; contact-rich, deformable, or fluid dynamics need improved models and sensing for high-stakes tasks.
- Safety, compliance, and regulatory review are essential for real deployments; human-in-the-loop approvals and monitoring should be standard.
Glossary
- 4D spatio-temporal representation: A representation that captures 3D geometry evolving over time (time is the 4th dimension). "we first estimate a 4D spatio-temporal representation."
- Adam: An adaptive stochastic gradient optimizer that uses estimates of first and second moments of gradients. "This objective penalizes penetrations, i.e., negative SDF values, and is minimized by gradient descent using Adam with gradient clipping and early stopping."
- camera rays: Rays traced from the camera center through image pixels into 3D space. "we cast camera rays through occluded pixels and compute their nearest intersections"
- canonical textured mesh: A 3D mesh of an object in a standardized pose with texture applied. "producing a canonical textured mesh ."
- collision optimization: The process of adjusting object placements to eliminate or minimize interpenetrations. "Collision optimization is to optimize the placement of each object with respect to the background mesh so that all objects maintain a minimum clearance to avoid initial collisions."
- dynamic point clouds: Time-varying sets of 3D points representing changing scene geometry. "we can also obtain dynamic point clouds through un-projection."
- end-effector: The tool or gripper at the tip of a robot arm that interacts with the environment. "where is the end-effector position,"
- FoundationPose: A foundation model for estimating 6D object poses from images. "we use FoundationPose~\cite{foundationpose} to recover per-frame object poses"
- Gaussian splats: A point-based rendering/reconstruction representation using Gaussian primitives. "or Gaussian splats~\cite{3DGS}"
- generative priors: Prior knowledge induced by generative models, used to regularize or guide reconstruction/learning. "we introduce a novel method that effectively tackles this problem with generative priors."
- Geometry-aligned 4D reconstruction: Reconstructing scene structure and motion over time while aligning geometry consistently across frames. "Geometry-aligned 4D reconstruction."
- gravity alignment: Transforming reconstructed geometry into a world frame consistent with the gravity axis. "Gravity alignment is to transform from camera to world frame so that the scene is consistent with the world gravity axis, which is crucial for physically plausible simulation."
- height-map triangulation: Constructing a mesh surface by triangulating a 2.5D height field. "we then reconstruct the background mesh via height-map triangulation and apply as the texture."
- Huber weights: Weights derived from the Huber loss to reduce the influence of outliers in robust regression. "where denotes the set of valid pixels and are Huber weights that downweight outliers."
- image-to-3D generator: A model that produces a 3D shape (mesh) from a single image. "we apply an image-to-3D generator~\cite{trellis} to , producing a canonical textured mesh ."
- inverse dynamics: Predicting the actions/forces that caused observed state transitions. "learn inverse dynamics or policy models to align generated video frames with real robotic actions."
- inverse kinematics: Computing joint configurations that achieve a desired end-effector pose. "assigning a negative reward when inverse kinematics or motion planning fail."
- metric-aligned depth maps: Depth maps scaled and shifted to correspond to real-world metric units. "producing metric-aligned depth maps that enable consistent 4D spatio-temporal reconstruction of the scene geometry."
- object-centric residual reinforcement learning: An RL approach that focuses on tracking object motion while learning residual corrections on top of a baseline controller. "through object-centric residual reinforcement learning with the physical world model."
- object-on-ground assumption: The assumption that objects rest on supporting surfaces, aiding completion of occluded geometry. "We address this with an object-on-ground assumption: objects are supported by the background, so their occluded regions are either planar supporting surfaces or extend to infinity (bounded by scene limits)."
- optical flows: Per-pixel motion vectors between consecutive video frames. "such as optical flows~\cite{avdc}, sparse tracks~\cite{gen2act}, or object poses~\cite{RIGVid}."
- orientation quaternion: A four-dimensional unit quaternion representing 3D rotation. "where is the object position and is its orientation quaternion."
- PPO: Proximal Policy Optimization, a policy-gradient algorithm for reinforcement learning. "and adopt PPO~\cite{ppo} as the learning algorithm."
- RANSAC: Random Sample Consensus, a robust algorithm for model fitting in the presence of outliers. "We estimate the ground plane normal from segmented plane points using RANSAC,"
- real-to-sim-to-real: A pipeline that reconstructs real scenes in simulation for training, then transfers policies back to the real world. "Real-to-sim-to-real methods reconstruct a physical scene from observations and embed it in simulators for policy learning."
- registration: Aligning shapes or point clouds into a shared coordinate frame. "through registration."
- residual reinforcement learning: Learning a corrective policy that adds to a baseline action to improve performance. "we propose a residual reinforcement learning method that combines the merits of both paradigms"
- signed distance field (SDF): A scalar field where each point’s value is the distance to the nearest surface, signed by inside/outside. "We voxelize the background mesh into a signed distance field (SDF)"
- sim-to-real gaps: Performance discrepancies between simulation and the real world. "may introduce additional sim-to-real gaps."
- skew-symmetric matrix: A matrix representation of cross products used in rotation exponential maps. "where is the skew-symmetric matrix of ."
- sparse tracks: A small set of tracked feature points across frames used to represent motion. "such as optical flows~\cite{avdc}, sparse tracks~\cite{gen2act}, or object poses~\cite{RIGVid}."
- temporally consistent depth estimate: Depth predictions that are coherent across consecutive frames. "which produces a temporally consistent depth estimate for each frame."
- un-projection: Converting depth pixels back into 3D points in camera coordinates. "through un-projection."
- vision-LLMs (VLMs): Models trained to jointly process and reason about images and text. "we leverage commonsense knowledge from vision-LLMs (VLMs) to estimate these properties."
- voxelize: Convert geometry into a grid of volumetric cells (voxels). "We voxelize the background mesh into a signed distance field (SDF)"
- world model: An internal model of environment structure/dynamics used for planning or learning. "This world model provides realistic physical feedback, enabling scalable robot learning to imitate generated video motions in a physically consistent manner."
- zero-shot: Performing a task without any task-specific training data or demonstrations. "enabling zero-shot robotic manipulation in the real world"
Collections
Sign up for free to add this paper to one or more collections.