Nemotron-TwoTower: Diffusion Language Modeling with Pretrained Autoregressive Context
Abstract: Diffusion LLMs offer a promising alternative to autoregressive models due to their potential for parallel and iterative generation. However, existing approaches use a single network for both context representation and iterative denoising, forcing one model to serve both roles and limiting its capacity for either role. We propose TwoTower, a block-wise autoregressive diffusion model that decouples these roles into two towers: a frozen AR context tower that causally processes clean tokens, and a trainable diffusion denoiser tower with bidirectional block attention that refines noisy blocks via cross-attention to the context. Built on Nemotron-3-Nano-30B-A3B, an open-weight 30B hybrid Mamba-Transformer MoE model, and trained on approximately 2.1T tokens, Nemotron-TwoTower retains 98.7% of the autoregressive baseline's quality while offering 2.42X higher wall-clock generation throughput. We release the code and model weights at https://huggingface.co/collections/nvidia/nemotron-twotower.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (brief overview)
The paper introduces Nemotron-TwoTower, a new way for a LLM to write text faster without losing much quality. Instead of writing one word at a time like most models (called “autoregressive” or AR), it writes small chunks of words in parallel and cleans them up over a few quick passes (a “diffusion” style). To make this work well, the model is split into two parts (“two towers”): one part understands the clean text written so far, and the other part guesses and fixes the next chunk of words. This design reaches almost the same accuracy as the original model but generates text about 2.4 times faster.
What questions the paper tries to answer (key objectives)
The authors wanted to find out:
- Can we separate “understanding the past” and “writing the next words” into two different model parts so each can do its job better?
- Will this still work for a very large, modern model that mixes different building blocks (like attention, Mamba, and mixture-of-experts)?
- How much speed can we gain without losing much quality?
- Which design choices (like block size, timing info, and attention direction) help the most?
How the method works (explained simply)
Think of writing as a team effort:
- The first teammate (the AR context tower) is like a careful reader. It reads the text you already have and remembers it very well. This part is “frozen,” meaning it keeps its original skills and is not changed during training.
- The second teammate (the diffusion denoiser tower) is like an editor. It takes a small chunk (“block”) of blanked-out words and fills them in. It does this over a few steps: first rough guesses, then quick refinements.
Key ideas in everyday language:
- Tokens: These are just the small pieces of text (like words or word parts) the model uses.
- Blocks: Instead of writing one token at a time, the editor fills in a small group of tokens (e.g., 16) together.
- Diffusion for text: Imagine starting with a blanked-out sentence and, step by step, revealing the correct words. At each step, the model predicts the masked words, “commits” the ones it’s confident about, and keeps working on the tricky ones.
- Cross-talk between teammates: The editor can “peek” at the reader’s understanding to make better guesses. This happens layer-by-layer, so the editor gets rich clues about the context.
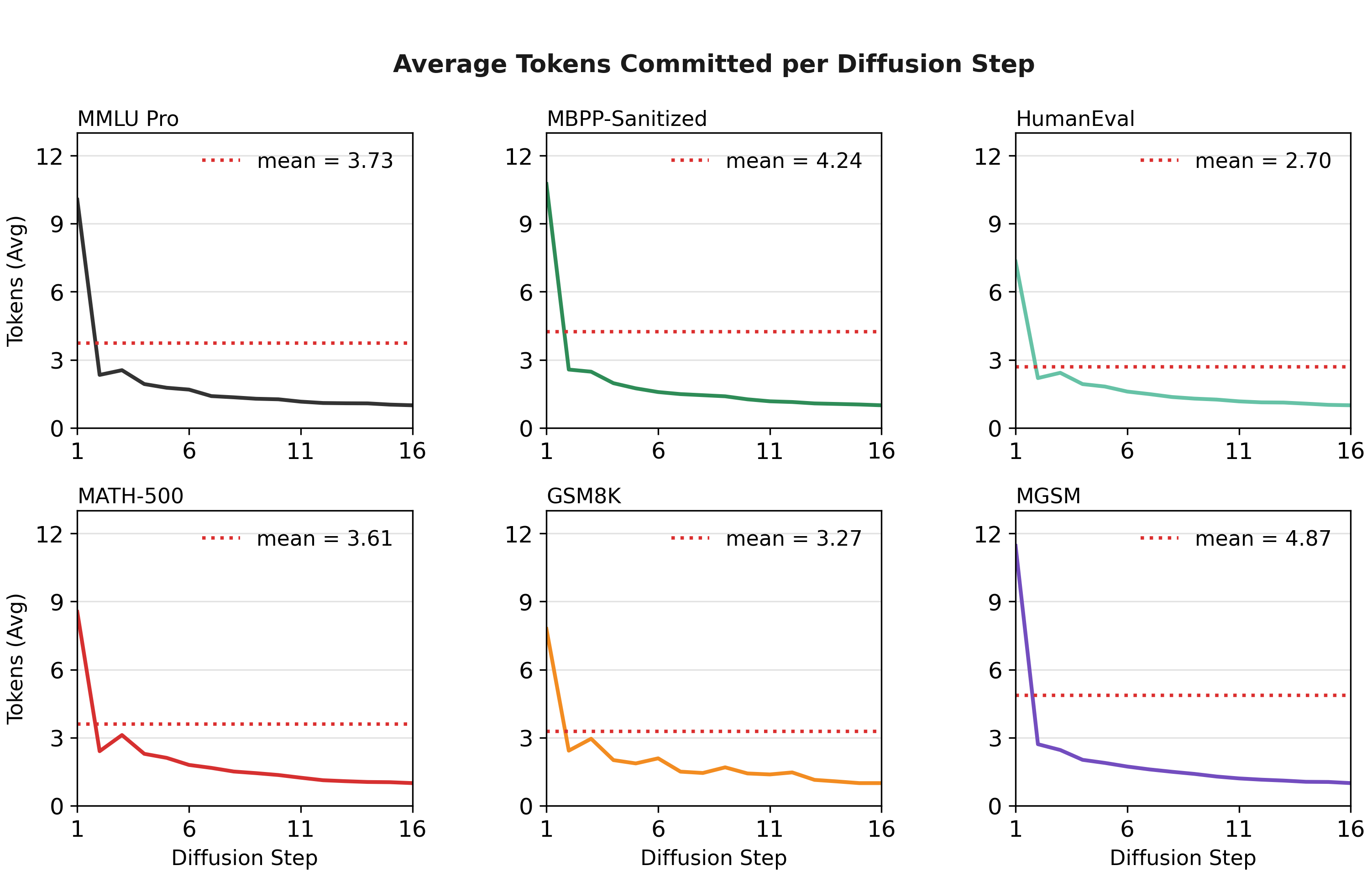
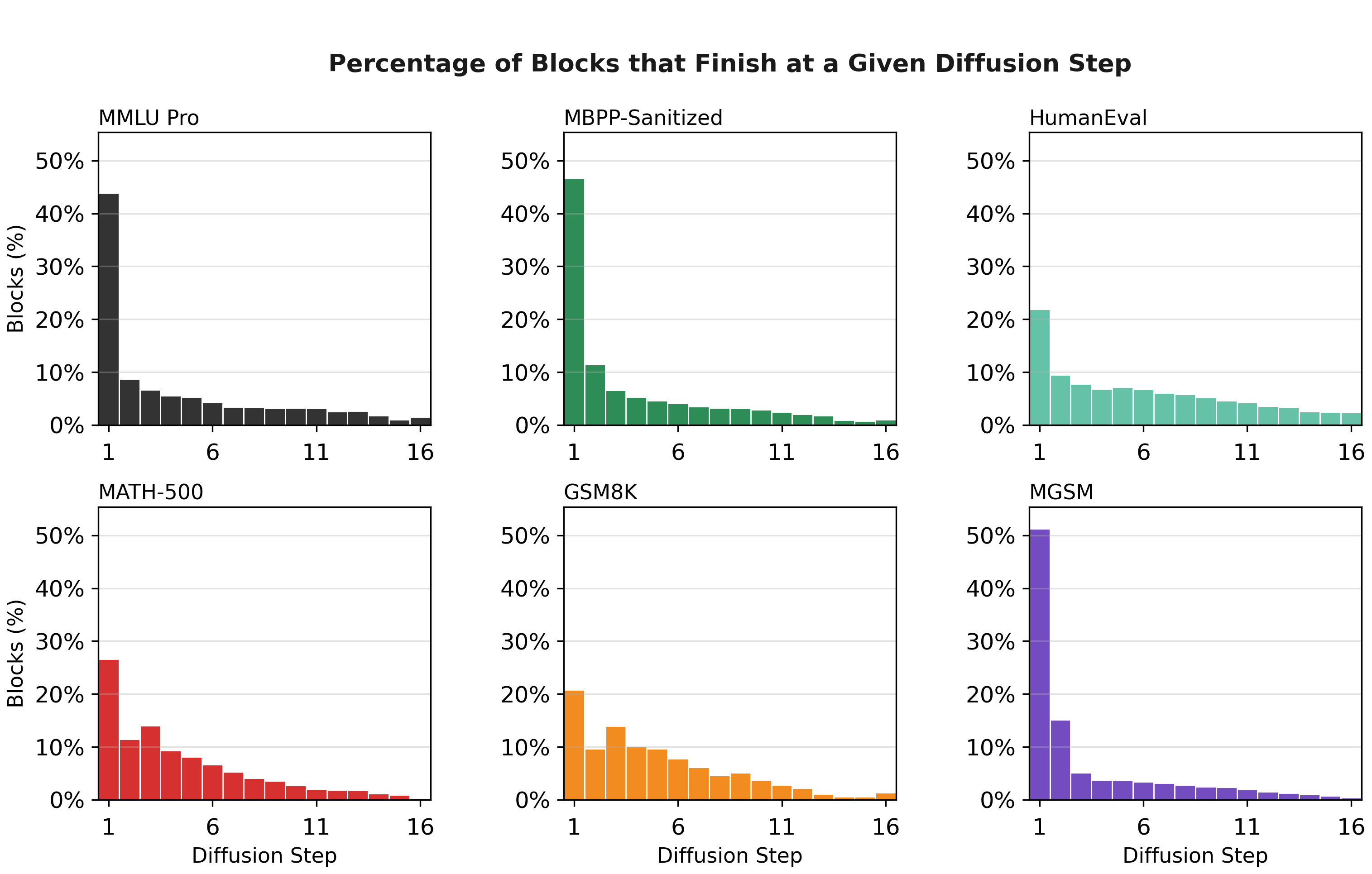
- Confidence-based committing: After each step, the editor keeps only the predictions it’s confident about and continues refining the rest. This lets the model lock in multiple correct tokens at once, which speeds things up.
Training approach in simple terms:
- The model starts from a strong, existing LLM (Nemotron-3-Nano-30B). The reader part stays fixed; only the editor learns.
- The editor is trained on about 2.1 trillion tokens (much less than the 25 trillion used to pretrain the original model).
- The editor learns with masked diffusion: it practices filling in masked-out blocks using hints from the reader and the current “noise level” (how much of the block is still masked).
- A small extra trick called “time conditioning” tells the editor what step it’s on in the clean-up process, which helps it make better choices.
What they found (main results and why they matter)
Here are the most important takeaways:
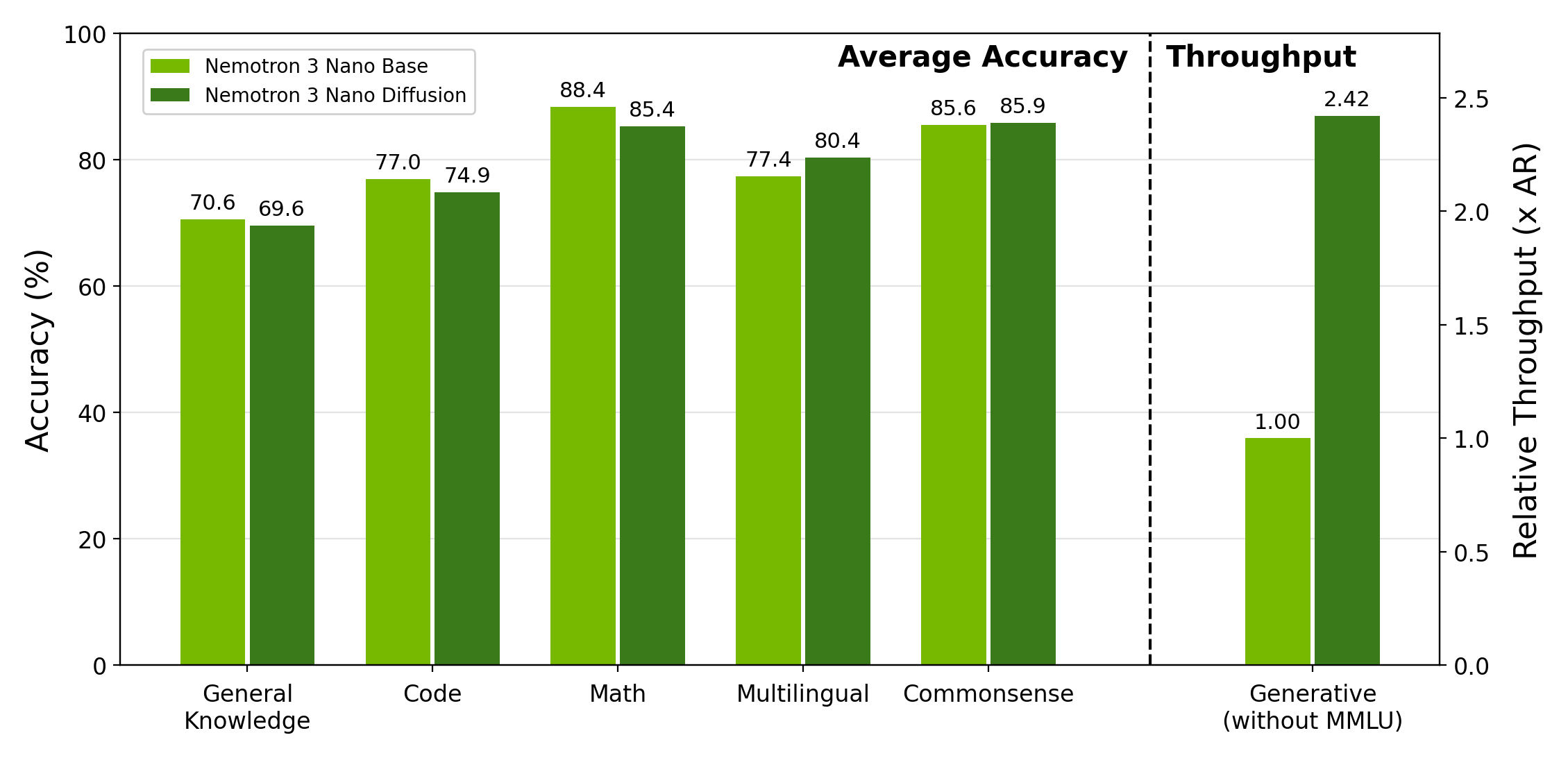
- Almost the same quality, much faster: The two-tower model keeps 98.7% of the original model’s accuracy but runs about 2.42× faster in real time.
- Multiple tokens per step: Early in the process, the editor often commits several tokens at once. This is a big reason it beats the one-token-at-a-time speed limit.
- Good trade-off controls: By adjusting how many refinement steps to run and how confident the model must be to commit a token, you can choose more speed or more accuracy.
- Design choices that help:
- Bidirectional attention inside each block (tokens in the block can look at each other both left and right) improves quality.
- Time conditioning (telling the editor which refinement step it’s on) also helps.
- Keeping Mamba layers causal (left-to-right) was better than making them bidirectional for this setup.
- Training the editor on smaller blocks (like 16 tokens) improved accuracy; going too big hurt quality.
- Freezing the reader (context tower) and training only the editor worked better than training both together.
Why this matters:
- It shows that we can retrofit big, pretrained LLMs to generate faster without retraining everything from scratch.
- Faster generation helps with real-world uses like chat, coding help, or long document writing, especially when server time and cost matter.
What this could mean going forward (implications and impact)
- Practical speed-ups: Apps that depend on LLMs could respond faster while keeping nearly the same quality.
- Reuse of existing models: Companies and researchers can take strong AR models they already have and upgrade their decoding speed with this two-tower method.
- Better control: The “confidence” and “steps” knobs let you decide how much to favor speed vs. accuracy for different tasks (like casual chat vs. precise math/code).
- Scalable path: The approach works on a large, modern model, suggesting it can scale further and be applied to other architectures.
- Open resources: The authors released code and model weights, making it easier for others to try, test, and improve the method.
In short, Nemotron-TwoTower splits the job into a reader and an editor, lets the editor fill in small chunks quickly, and uses smart checks to commit only the confident bits—delivering near-baseline quality at much higher speed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following concrete gaps and open questions highlight what remains uncertain or unexplored and can guide follow‑up research:
- Scalability across model sizes and architectures:
- How TwoTower behaves at different scales (e.g., ≤7B, 13B, ≥70B) and with non-hybrid backbones (pure Transformers, pure SSMs) is not evaluated.
- Generality to other widely used backbones (e.g., LLaMA/Mistral families) and tokenizers is untested.
- Post-training regimes and alignment:
- Impact of instruction tuning, RLHF, and safety tuning on the quality–throughput trade-off and stability of block diffusion is unknown.
- Whether speedups and accuracy hold for multi-turn chat, tool-use, function-calling, and RL-evolved decoding strategies is unstudied.
- Long-context and prompt-length sensitivity:
- No measurements of throughput/quality versus prompt length or extremely long contexts (despite claims that cache scaling matches AR).
- Asymptotic behavior of cross-attention to growing context (compute, latency, memory bandwidth) for very long inputs/outputs is not quantified.
- Inference compute/memory profile:
- Precise inference memory overhead from holding two full sets of weights (frozen context + denoiser) is not reported (e.g., per-GPU GB, feasibility on single-80GB GPUs).
- No breakdown of per-token/per-step FLOPs, cross-attention bandwidth costs, or latency components, nor comparison to AR/Medusa/speculative decoding kernels.
- Hardware and deployment variability:
- Throughput is reported only on 2×H100; behavior on A100, consumer GPUs, multi-node inference, and CPU–GPU heterogeneous setups is unknown.
- Sensitivity to kernel choices (e.g., FlashAttention versions) and MoE dispatch overhead in real deployments is not assessed.
- Block-size generalization and scheduling:
- Quality collapses when sampling uses larger blocks than training (e.g., S=64 vs S=16); training with a mixture of block sizes or curriculum on S is not explored.
- Dynamic or content-adaptive block sizing at inference (and its control signals) is not investigated.
- Sampler design and calibration:
- Default number of denoising steps T and early-stopping policies are not specified or analyzed; the single-block algorithm does not clearly early-stop once a block is fully committed.
- Confidence threshold γ relies on model logit calibration; there is no calibration analysis or adaptive γ policy across tasks or timesteps.
- Alternatives to confidence-unmasking (e.g., learned acceptance rules, temperature/top‑p within block, classifier-free guidance for discrete diffusion) are not compared.
- Diffusion schedule and training objective:
- Only a linear masking schedule (α_t=1−t) is used; learned or non-linear schedules, cosine schedules, or task-adaptive schedules are untested.
- The theoretically motivated 1/t importance weight is omitted for stability; the impact of alternative weights or variance-reduced estimators is not analyzed.
- No comparison to denoiser distillation, score-matching variants, or consistency models for discrete tokens.
- Tower interaction design:
- Layer-aligned cross-attention is chosen, but comparisons to cross-attending multiple context layers, pooled/adapter summaries, or last-layer-only conditioning are absent.
- Partial fine-tuning of the context tower (e.g., LoRA on select layers or attention-only tuning) versus fully frozen is only partially probed; fine-grained schedules are not explored.
- Representational drift between frozen context states and the evolving denoiser is not measured (e.g., mismatch effects across many committed blocks).
- MoE routing under diffusion:
- Effects of masked tokens and time-conditioning on expert specialization, load-balancing, and capacity usage (and their impact on latency and stability) are not analyzed.
- Potential routing pathologies (e.g., expert collapse for heavily masked inputs) and mitigation strategies are not studied.
- Mamba/SSM specifics:
- Only a simple bidirectional Mamba scan (averaged) is tested; more efficient bidirectional or chunked SSM designs and their training dynamics remain open.
- The requirement to match Mamba chunk size to block size (S) to expose states constrains design; kernel/architecture changes to decouple chunking from S are not provided.
- Error propagation and theoretical guarantees:
- No analysis of error accumulation across blocks when committing uncertain tokens or of convergence properties of the confidence-unmasking sampler is presented.
- Relationship between the learned masked conditional distributions and the AR conditional (e.g., NLL/perplexity consistency) is not theoretically or empirically established.
- Evaluation breadth and diagnostics:
- Limited task set (base pre-alignment) with modest degradation on code/math; no granular error analysis (e.g., typical failure modes in reasoning/coding).
- Robustness to distribution shift, adversarial/noisy prompts, multilingual long-form outputs, and stochastic decoding settings (temperature/top‑p) is not evaluated.
- Safety/toxicity, hallucination rates, calibration (ECE/Brier), and uncertainty quantification are not assessed.
- Combination with other acceleration methods:
- Integration with speculative decoding (e.g., draft–verify using the frozen AR tower), grammar-constrained decoding, or prefix-caching strategies is not explored.
- Training compute and efficiency:
- Added training cost from running the frozen context forward pass (to produce layer-aligned KV and Mamba states) is not quantified relative to AR baselines.
- Minimum adaptation token budget for the denoiser (data efficiency curves) is not studied.
- Tokenization and [MASK] handling:
- Introduction and handling of the [MASK] token in a purely AR-pretrained vocabulary is not detailed (e.g., initialization, embedding sharing, leakage into outputs).
- Alternatives to a single [MASK] symbol (e.g., multi-mask classes or learned null embeddings) and their effects are unexplored.
- Layer-wise KV reuse and bandwidth:
- Cross-attending to per-layer context states could amplify inter-layer bandwidth demands; trade-offs versus last-layer-only or compressed KV caches are not quantified.
- Reproducibility details:
- Token budget is inconsistently reported (~1.4T vs ~2.1T); key sampler hyperparameters (e.g., default T, γ selection procedure) and exact benchmark setups need clearer specification.
- Absolute throughput (tokens/sec, latency distributions) and power/energy metrics are not provided, complicating fair deployment comparisons.
- Downstream productization:
- Impact on determinism, serving-time variance, batching efficiency across heterogeneous requests, and integration into real-time systems is not examined.
These gaps suggest concrete avenues: multi-scale and multi-backbone studies; mixed and adaptive block-size training; principled sampler design with calibration/early stopping; alternative schedules and losses; fine-grained tower-tuning strategies; MoE/SSM-specific analyses and kernels; comprehensive compute/memory profiles; and broader, post-trained evaluations with safety and robustness diagnostics.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and methods can be used today, along with sectors, prospective tools/workflows, and key dependencies or assumptions.
- High-throughput LLM serving for chat and copilots (software, cloud/AI platforms)
- Use case: Replace one-token-at-a-time decoding with block-wise diffusion decoding to reduce latency and cost-per-token in interactive assistants, code copilots, and search/chat products.
- Tools/workflows: Integrate the released Nemotron-TwoTower weights and recipe into Megatron-LM or production serving stacks (e.g., Triton Inference Server), expose a “throughput–quality dial” via the confidence threshold γ and denoising steps T.
- Assumptions/dependencies: H100/A100-class GPUs (or equivalents) with sufficient memory for two tower weights; speedups depend on careful kernel/TP/MP configuration; quality/latency trade-offs must be tuned per task.
- Cost-efficient large-scale text generation pipelines (industry R&D, data engineering)
- Use case: Faster synthetic data generation (instruction data, augmentation, unit tests, documentation) with near-baseline quality for continuous retraining or evaluation farms.
- Tools/workflows: Batch block-wise decoding with adaptive confidence unmasking; autoscale γ/T per job SLA; log token-commit traces to monitor Pareto position.
- Assumptions/dependencies: Similar or better cost per output token relies on high GPU utilization and stable convergence of the denoiser in target domains.
- Low-latency reasoning and retrieval workflows (finance, support ops, enterprise search)
- Use case: Speed up multi-turn Q&A and retrieval-augmented generation by committing multiple tokens early per step while preserving strong left-to-right inductive bias for coherent answers.
- Tools/workflows: Couple TwoTower decoding with RAG; update γ dynamically when tool calls or retrieval hit-confidence is high.
- Assumptions/dependencies: Some reasoning-heavy tasks may require higher γ (trading off latency) to match AR quality; latency benefits hinge on prompt length and block size S.
- Throughput-aware code completion and review (software development)
- Use case: Improve IDE/code-review assistants’ responsiveness without large quality drops in code and math, as validated in the paper’s benchmarks.
- Tools/workflows: Integrate TwoTower decoding into IDE plugins; adapt S and γ by file size and context length.
- Assumptions/dependencies: Code-heavy tasks showed modest degradation vs AR; teams should A/B test for internal repos and libraries.
- Academic evaluation at scale with lower wall-clock time (academia, benchmarking groups)
- Use case: Run large benchmark suites (MMLU, GSM8K, MBPP, multilingual) faster to accelerate research cycles and hyperparameter sweeps.
- Tools/workflows: Use released weights; set S=16 (default) and sweep γ,T to position on the Pareto frontier; record sampling dynamics.
- Assumptions/dependencies: Report both quality and throughput to ensure fair comparison across decoding strategies.
- Drop-in decoding adaptation for existing AR backbones (model engineering)
- Use case: Convert strong pretrained AR models into faster generators by freezing the AR “context tower” and training only a denoiser tower on ~1–2T tokens.
- Tools/workflows: Start from an internal AR checkpoint; follow the paper’s two-stage curriculum; adopt layer-aligned cross-attention and adaLN time conditioning.
- Assumptions/dependencies: Requires access to original backbone and training infra; memory footprint increases (two towers); diffusion training still non-trivial but cheaper than full pretraining.
- Speculative verification and likelihood scoring sidecar (platform infra, safety)
- Use case: Reuse the frozen context tower for verification (AR scoring), selective rollbacks, or speculative decoding checks while the denoiser proposes tokens rapidly.
- Tools/workflows: Keep the context LM head; run occasional AR scoring on uncertain spans identified by low-confidence residual masks.
- Assumptions/dependencies: Extra scoring steps reduce net speedup; benefits highest when verification is sparse and targeted.
- Tunable latency tiers in LLM APIs (cloud services, MLOps)
- Use case: Offer API customers selectable “Fast,” “Balanced,” and “Max Quality” presets by adjusting γ, T, and S per request.
- Tools/workflows: SLA-aware routing that maps customer tier to decoding hyperparameters; per-request telemetry to adapt thresholds online.
- Assumptions/dependencies: Requires robust monitoring to prevent silent quality drift; tasks differ in sensitivity to block size.
- Knowledge-heavy document processing with near-AR quality (healthcare admin, legal ops)
- Use case: Summarization, triage, and template drafting for long documents at higher throughput while maintaining coherence aided by causal context tower.
- Tools/workflows: Process long contexts with a single prefix cache; chunk outputs with S=16 and adaptive γ to keep latency low.
- Assumptions/dependencies: Human-in-the-loop review remains essential in regulated domains; local validation needed for domain language.
- Energy and cost reporting for LLM operations (policy, sustainability teams)
- Use case: Demonstrate reduced wall-clock and potentially lower compute energy per response for compliance and ESG reporting.
- Tools/workflows: Track kWh/response and emissions factors; compare AR vs TwoTower under matched quality thresholds.
- Assumptions/dependencies: True energy reduction depends on actual GPU utilization and cluster scheduling; memory overhead of second tower may partly offset savings.
Long-Term Applications
These applications are feasible but likely require additional research, engineering, or ecosystem support (e.g., model/tooling changes, distillation, or safety work).
- Memory-efficient variants for edge/on-device inference (mobile, robotics)
- Vision: Distill the two-tower design into a compact single-tower or partially-shared-weights model; or quantize/prune towers to fit on-device.
- Dependencies: New training strategies for weight sharing or cross-tower distillation; optimized kernels for block-wise bidirectional attention on edge accelerators.
- Unified multi-modal diffusion decoding with frozen AR context (multimodal AI)
- Vision: Extend the context tower to encode text–vision/audio tokens and let a denoiser refine multimodal blocks in parallel (e.g., captioning, VQA, speech agents).
- Dependencies: Tokenization/unification across modalities; layer-aligned cross-attention across modality-specific layers; robust masking schemes for non-text tokens.
- Adaptive planning and tool-use with confidence-guided block commits (autonomous agents)
- Vision: Couple confidence-unmasking with tool selection/planning steps so high-confidence spans commit early and trigger tools faster; uncertain spans wait for further refinement.
- Dependencies: Calibrated confidence estimates; robust rollback/branching; scheduler that interleaves denoising with tool calls without losing speed gains.
- Safety, controllability, and audit hooks at the block level (governance, risk)
- Vision: Insert safety classifiers/filters between diffusion steps or at commit boundaries for red-teaming and policy enforcement without halting decoding.
- Dependencies: Low-latency safety models; standards for logging block-level traces; evaluation of how iterative refinement interacts with content filters.
- Task-aware, autotuned decoding controllers (AIOps, self-optimizing services)
- Vision: Online controllers that learn to set γ, T, and S per prompt/task to optimize a reward (quality, latency, cost), guided by telemetry and user feedback.
- Dependencies: Reliable reward signals; guardrails to avoid quality regressions; explainability for SLA compliance.
- Domain-specialized denoisers with frozen foundation contexts (vertical AI: healthcare, legal, finance)
- Vision: Keep a general-purpose AR context tower but train small domain-specific denoisers that plug into the same context, enabling “pair-and-swap” domain adapters.
- Dependencies: Demonstrations that denoisers can remain small; stable transfer without catastrophic interference; governance over mixing general and domain-specific states.
- Hybrid speculative–diffusion decoding for extreme throughput (cloud inference)
- Vision: Combine token-level speculative decoding and block-wise confidence unmasking to achieve >3× speedups at minimal quality loss.
- Dependencies: Careful orchestration to avoid redundant compute; efficient fallbacks when speculation fails; consistent caching across methods.
- Training-time acceleration via block-diffusion curriculum (foundation model training)
- Vision: Use masked diffusion phases during pretraining or finetuning to reduce training wall-clock and improve robustness to masking/noise.
- Dependencies: Curriculum design for AR↔diffusion co-training; stability at larger scales and mixtures (MoE, SSMs); reproducible quality gains.
- Real-time, low-latency assistants for time-critical operations (operations centers, trading support, robotics control rooms)
- Vision: Exploit multi-token commits per step to keep response latency within human interaction thresholds for decision support.
- Dependencies: Proven stability on long CoT and tool-use chains; carefully tuned γ for high-stakes contexts; rigorous validation and fallback to AR when confidence drops.
- Standards and benchmarks for quality–throughput Pareto reporting (policy, procurement)
- Vision: Institutionalize reporting of “% of AR baseline quality vs throughput” as a procurement and policy metric for public-sector and enterprise AI deployments.
- Dependencies: Community consensus on test suites and measurement protocols; neutral harnesses that support both AR and diffusion decoding uniformly.
- Cross-architecture generalization of the two-tower recipe (ecosystem maturity)
- Vision: Reference implementations for popular backbones (Transformers-only, RWKV, Mamba-only, MoE) with plug-and-play layer-aligned cross-attention and Mamba state seeding.
- Dependencies: Kernel/library support in vLLM/Transformers/TensorRT-LLM; community-validated configs for different model sizes; licensing clarity for open-weight distribution.
Glossary
- adaLN-single: A time-conditioning mechanism that modulates layer normalization parameters using a timestep embedding. "We condition the denoiser on the timestep using adaLN-single~\citep{peebles2023scalable, chen2023pixart}."
- AdamW: An optimizer with decoupled weight decay that often improves generalization and stability in deep learning. "We use BF16 precision, AdamW \citep{loshchilov2019decoupledweightdecayregularization}, and a Warmup-Stable-Decay learning rate schedule \citep{hu2024minicpmunveilingpotentialsmall} with peak learning rate \num{1e-4} and final learning rate \num{1e-6}."
- Autoregressive (AR) LLMs: Models that generate text by predicting the next token conditioned on previously generated tokens. "Autoregressive (AR) LLMs are the predominant paradigm in text generation~\citep{radford2019language, grattafiori2024llama, liu2024deepseek}."
- Bidirectional attention: An attention pattern allowing tokens within a block to attend to both left and right context (while remaining causal with respect to earlier blocks). "Within the block under refinement, the denoiser relaxes the causal mask: noisy tokens attend bidirectionally to other noisy tokens while remaining causal with respect to past clean blocks."
- Bidirectional Mamba-2: A variant running Mamba-2 both left-to-right and right-to-left and combining outputs to provide bidirectional context. "We also test a parameter-free bidirectional Mamba-2 variant by running the pretrained Mamba-2 weights left-to-right and right-to-left from zero states, then averaging the outputs."
- Block diffusion models: Diffusion-based LLMs that iteratively refine blocks of tokens rather than decoding strictly one token at a time. "We also consider the standard predict-and-noise sampler used in block diffusion models~\citep{arriola2025block, arriola2025encoder}, which predicts a clean block and then re-masks low-confidence positions according to the noise schedule."
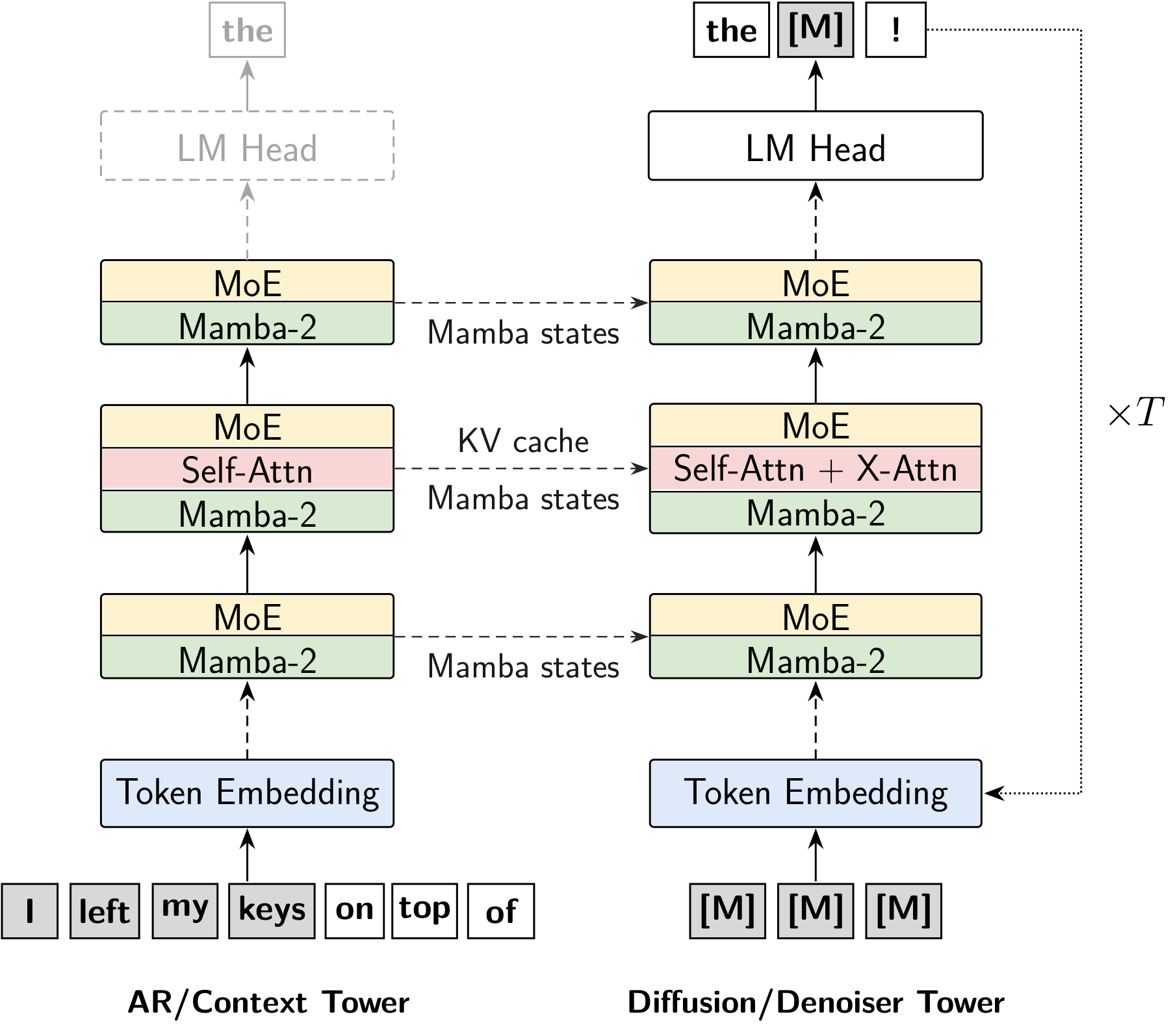
- block-wise autoregressive diffusion model: A model that generates in blocks using diffusion while committing blocks in an autoregressive order. "We propose TwoTower, a block-wise autoregressive diffusion model that decouples these roles into two towers: a frozen AR context tower that causally processes clean tokens, and a trainable diffusion denoiser tower with bidirectional block attention that refines noisy blocks via cross-attention to the context."
- Confidence unmasking: A sampling strategy that commits only high-confidence token predictions per step, leaving uncertain positions masked for further refinement. "Our main results use a confidence-unmasking variant with threshold : at each step, the denoiser predicts all currently masked tokens in parallel, predictions above are committed, and the remaining uncertain positions stay masked for later refinement."
- Context tower: The frozen autoregressive module that encodes clean context and supplies layer-wise states and caches to the denoiser. "Given a prompt, the AR context tower acts as a causal autoregressive model over the prompt and previously committed tokens, producing per-layer KV pairs and final Mamba states."
- Cross-attention: An attention mechanism where the denoiser attends to representations from the context tower. "a trainable diffusion denoiser tower with bidirectional block attention that refines noisy blocks via cross-attention to the context."
- Denoiser tower: The trainable module that iteratively refines masked/noisy tokens conditioned on context and timestep. "a trainable diffusion denoiser tower with bidirectional block attention that refines noisy blocks via cross-attention to the context."
- Diffusion LLMs: Models that construct text by iterative denoising in a discrete token space, enabling parallel refinement. "Diffusion LLMs offer a promising alternative to autoregressive models due to their potential for parallel and iterative generation."
- ELBO (Evidence Lower Bound): A variational objective that, here, motivates a specific weighting of the masked diffusion loss. "The masked diffusion ELBO motivates a time-weighted negative log-likelihood over masked tokens~\citep{sahoo2024simple, shi2024simplified};"
- KV cache: Stored key/value tensors from attention layers that allow efficient reuse of past computations during generation. "let denote the context-tower attention KV cache over previous clean blocks and the per-layer Mamba boundary states after block ."
- Layer-aligned cross-attention: Cross-attention connecting corresponding layers between towers so representations are matched by depth. "The cross-attention is layer-aligned: denoiser layer attends to context layer ."
- LM head: The final linear projection from hidden states to vocabulary logits used for token prediction. "Its final vocabulary projection/LM head is optional: it can be omitted in the default diffusion-generation path, where the context tower only needs to produce states, and retained when the context tower is used for speculative decoding,verification, likelihood evaluation, or AR scoring."
- Mamba-2: A state-space-model-based sequence layer used in the backbone alongside attention and MoE. "TwoTower is a general approach that can be applied to any pretrained autoregressive LLM. In this work we instantiate it on Nemotron-3-Nano-30B-A3B \citep{blakeman2025nvidia}, which consists of 52 layers: 23 Mamba-2 layers, 6 self-attention layers, and 23 mixture-of-experts (MoE) layers."
- Megatron-LM: A distributed training framework for large-scale LLMs with model parallelism. "We implemented the training loop in Megatron-LM\footnote{\url{https://github.com/nvidia/megatron-lm} \citep{megatron-lm}."
- Mixture-of-Experts (MoE): An architecture where tokens are routed to a subset of specialized expert networks to increase capacity efficiently. "which consists of 52 layers: 23 Mamba-2 layers, 6 self-attention layers, and 23 mixture-of-experts (MoE) layers."
- MoE routing: The mechanism that assigns tokens to experts, typically with load-balancing constraints. "We use the backbone's existing MoE routing mechanism, including sequence-level load balancing."
- Pareto curve: The frontier capturing trade-offs between two objectives, here quality and throughput. "The Pareto curve and task breakdown indicate that the two-tower diffusion model preserves most of the pretrained model's behavior."
- Prefix cache: A persistent cache of context states for the already-processed prefix used to speed up decoding. "At inference time, Nemotron-TwoTower introduces a fixed memory footprint for the context tower weights, while keeping a single prefix cache."
- Quality--throughput curve: A plot showing the trade-off between model accuracy and generation speed. "Quality--throughput curve across confidence thresholds and denoising budgets, normalized to the AR baseline."
- Sequence-level load balancing: A constraint ensuring expert assignments are balanced across tokens/sequences to avoid expert overload. "We use the backbone's existing MoE routing mechanism, including sequence-level load balancing."
- Speculative decoding: A technique where a draft model proposes tokens that are then verified (accepted or rejected) by a stronger model. "retained when the context tower is used for speculative decoding,verification, likelihood evaluation, or AR scoring."
- State-space model (SSM): A class of models representing sequences via linear dynamical systems; used in Mamba layers. "This roughly doubles per-layer state-space model (SSM) FLOPs;"
- Tensor-parallel rank: A shard of model parameters/compute across GPUs along tensor dimensions in parallel training. "we replicate these small modules on each tensor-parallel rank rather than sharding them, avoiding extra communication cost."
- Two-tower architecture: A design pattern with a frozen context encoder and a trainable denoiser connected layer-by-layer. "Two-tower architecture: a frozen AR context tower conditions a diffusion denoiser tower over each noisy block."
- Warmup-Stable-Decay learning rate schedule: An LR schedule with an initial warmup, a stable plateau, then a decay phase. "We use BF16 precision, AdamW \citep{loshchilov2019decoupledweightdecayregularization}, and a Warmup-Stable-Decay learning rate schedule \citep{hu2024minicpmunveilingpotentialsmall}"
- Wall-clock generation throughput: The end-to-end generation speed measured in real time, not just theoretical FLOPs. "Nemotron-TwoTower preserves 98.7\% of the AR baseline's aggregate benchmark quality while improving wall-clock generation throughput by 2.42."
Collections
Sign up for free to add this paper to one or more collections.

