Connect the Dots: Training LLMs for Long-Lifecycle Agents with Cross-Domain Generalization Via Reinforcement Learning
Abstract: This work presents a general framework for training LLMs to "Connect the Dots" (CoD), a meta-capability required by long-lifecycle agents: as an LLM-based AI agent gets deployed in an environment, it solves a long sequence of tasks while continuously exploring the environment, learning from its own experiences, and iteratively self-updating its context about the environment, thereby achieving progressively better performance on future tasks conditioned on the updated context. Major components of the CoD framework include: (1) algorithm design and infrastructure for end-to-end reinforcement learning (RL) with long rollout sequences interleaving solve-task and update-context episodes; (2) tasks and environments for incentivizing and eliciting the targeted meta-capability in LLMs during training, as well as for faithfully measuring progress during evaluation. We present proof-of-concept implementations of the CoD framework, including a GRPO-style RL algorithm with fine-grained credit assignment, as well as tasks and environments tailored to the targeted meta-capability (rather than domain-specific LLM capabilities or standard task-by-task RL). Empirical results validate the efficacy of end-to-end RL training in the CoD setting, and demonstrate the potential for out-of-distribution generalization -- within the training domains, across different domains, and from CoD to Ralph-loop settings -- of the elicited meta-capability. Our investigation of CoD connects several lines of prior works, and opens up new opportunities for advancing LLMs and AI agents. To facilitate further research and applications, we release our implementations at \url{https://github.com/agentscope-ai/Trinity-RFT/tree/research/cod/examples/research_cod}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explain It Like You’re 14: “Connect the Dots” for Smarter AI Agents
What’s this paper about?
This paper shows a new way to train LLMs—the kind of AI that chats and writes—to act more like long-term helpers (agents) that learn while they work. The authors call this skill “Connect the Dots” (CoD). It means the AI doesn’t just try to solve each task from scratch; it also keeps track of what it has learned in that place and uses those notes to do better next time.
What big questions are the authors trying to answer?
- How can we train AI to keep learning during use, not just before it’s deployed?
- How can an AI remember helpful facts about one environment (like a game or computer system) and use those facts to solve new tasks there?
- Can this “connect the dots” skill transfer across different kinds of tasks and worlds?
How did they approach the problem?
A simple picture of their idea
- Think of an AI as a player dropped into a new world (like a game level or a computer system).
- It faces a long line of tasks in that same world.
- Between tasks, it writes itself a short “hint” (like a note to future-self) about how this world works—so the next task becomes easier.
- Over time, the AI learns faster and performs better because it keeps and improves these notes.
The authors split this into two parts:
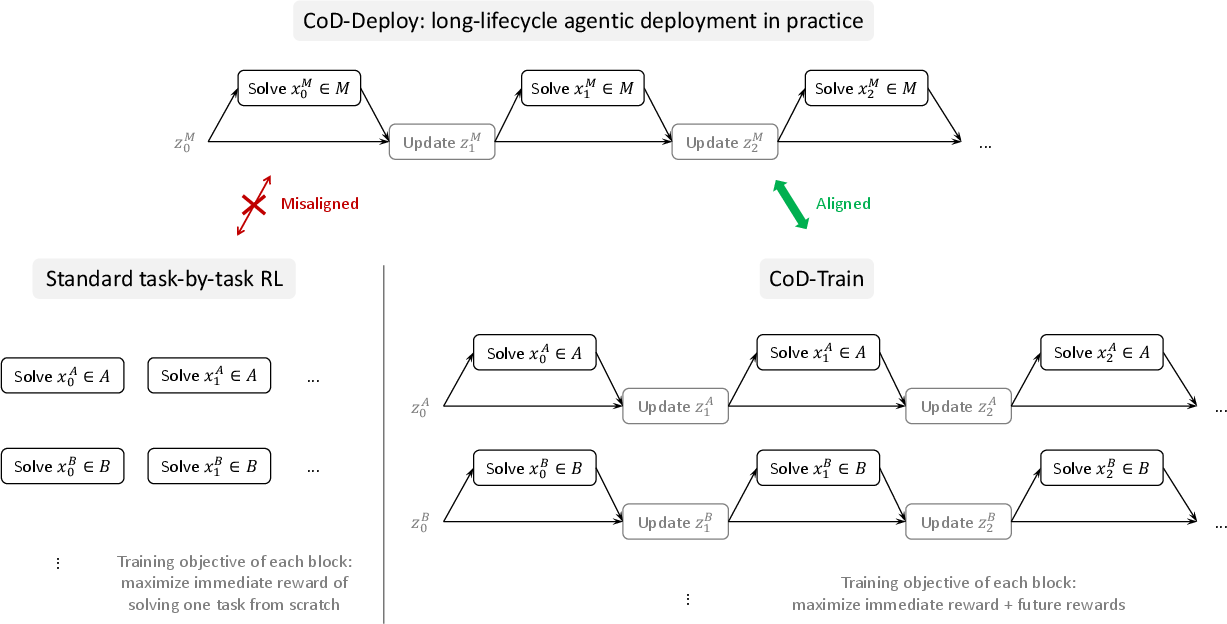
- CoD-Deploy: How the AI behaves in the real world—solve a task, update its notes, solve another task, and so on.
- CoD-Train: How they train the AI using the same pattern—lots of practice runs that alternate between solving tasks and updating notes.
The training method in everyday terms
They use reinforcement learning (RL), which is “learning by trial and error.” The AI:
- Tries something.
- Gets a reward if it helps (like a score).
- Changes its behavior to do better next time.
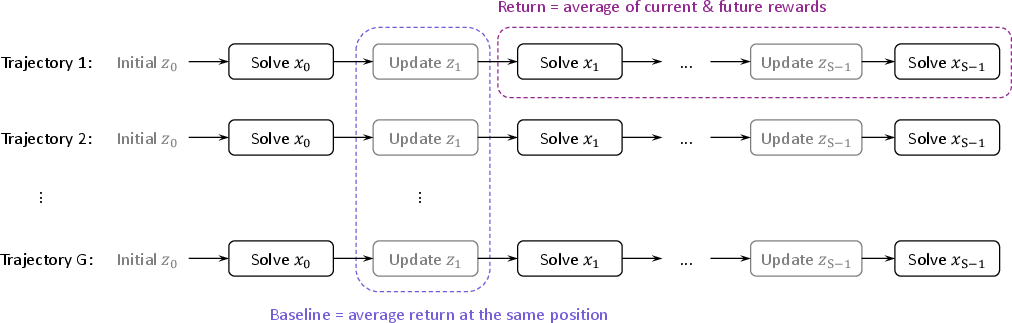
A key challenge is “credit assignment”—figuring out which actions earlier on deserve credit for success later. The authors:
- Give rewards not just for the current task but also consider how choices affect future tasks.
- Use a policy-gradient method (a GRPO-style algorithm) to update the AI’s behavior.
- Make “fine-grained” credit decisions episode by episode (instead of lumping all rewards together), which helps the AI learn which notes and strategies truly helped down the line.
The “worlds” (environments) they used to train and test
They designed special practice worlds that encourage the AI to keep and use notes:
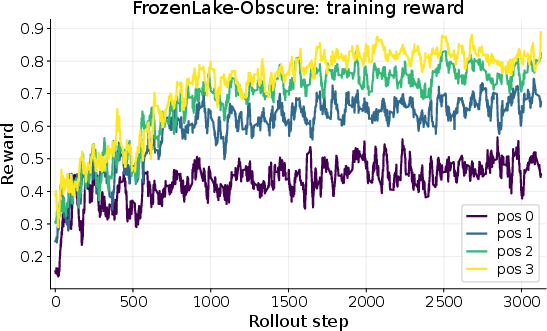
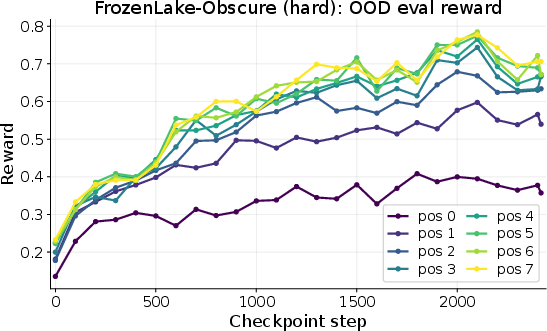
- FrozenLake-Obscure: A grid maze where the movement buttons (A/B/C/D) secretly map to directions (up/down/left/right), and this mapping changes per world. You can’t know the controls at first—you must discover them and write them down. Without notes, you’re stuck guessing each time.
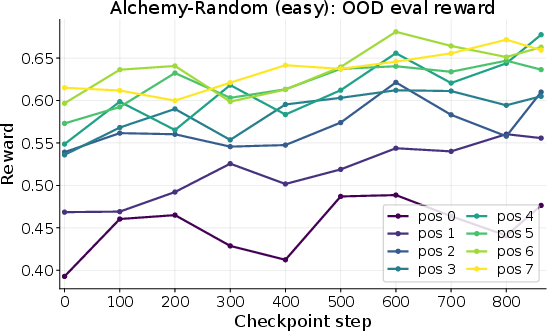
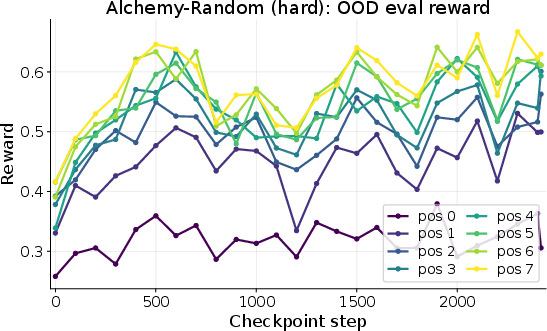
- Alchemy-Random: A “mix-and-make” game with elements and hidden recipes that change per world. To make a target item, you need to discover (and remember) which combos work. Notes about recipes help a lot on later tasks.
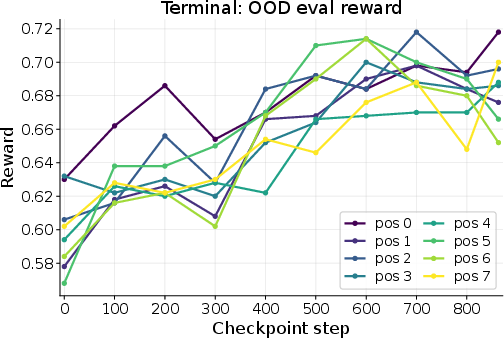
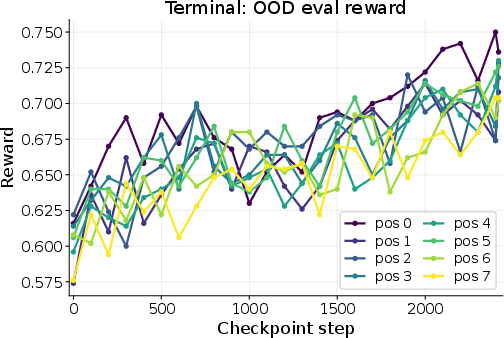
- TerminalSimulator: A pretend computer terminal (like MacOS/Linux/Windows). The best solution depends on the system and file details, so exploring and keeping notes can improve performance.
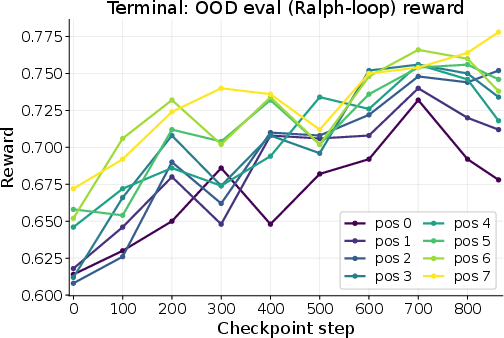
They also tested a “Ralph-loop” situation—repeating attempts on the same task—like trying multiple drafts of the same answer and improving each time using your own feedback.
What did they find?
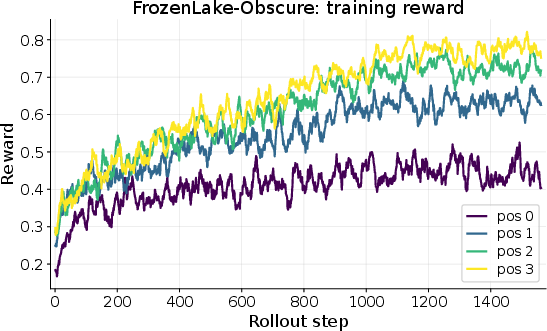
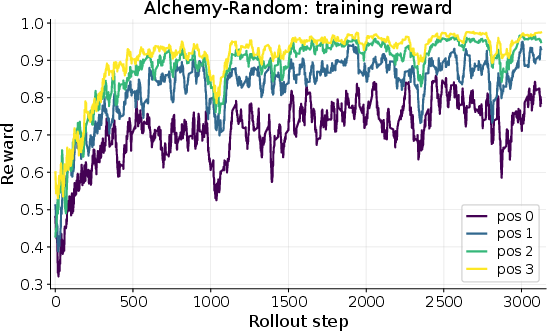
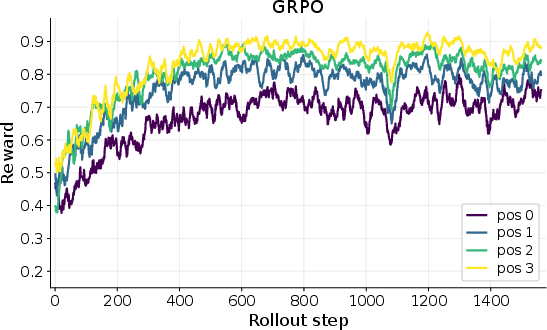
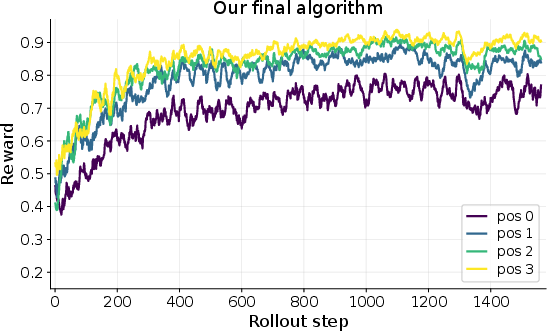
- Training the AI with CoD improves performance noticeably when tasks repeat within the same world:
- In FrozenLake-Obscure, the success rate on the very first task (with no notes) only increased from about 18% to 45%—limited by hidden info you just can’t know at the start.
- But by the fourth task in the same world (with notes), success jumped from about 28% to 76%. That’s because the AI learned and reused the secret control mapping.
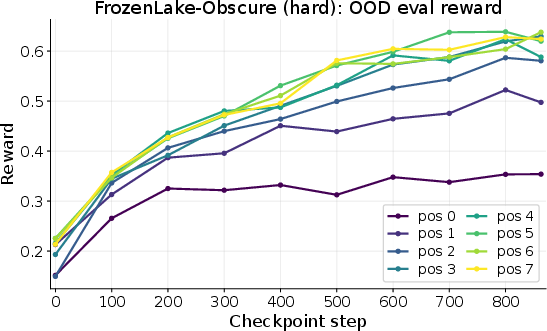
- The “connect the dots” skill transfers:
- It held up on harder versions of the same games (bigger maps, more elements).
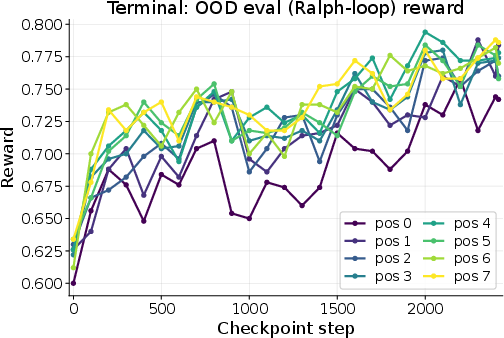
- It also helped in different domains (like TerminalSimulator) and in the Ralph-loop setting (repeated attempts at the same task).
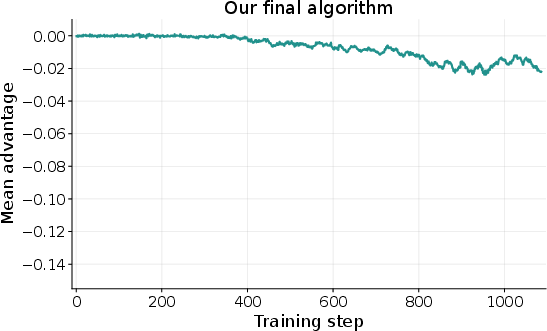
- The training method (fine-grained rewards and episode-by-episode credit) was important to get stable learning with long sequences.
Why is this important?
- Real-life assistants and agents need to adapt on the job—like a coding helper that learns a team’s style, or a personal assistant that learns a user’s preferences. This work trains AI to do that: explore, keep useful notes, and improve steadily.
- It reduces how much hand-crafted “agent scaffolding” (complex rules written by humans) is needed for long-term, reliable behavior.
- The skill is a meta-skill (a way of learning), not just a single-task trick—so it can generalize across different kinds of tasks and environments.
Final thoughts, limits, and what’s next
- Today’s implementation stores a simple “hint” between tasks. Future versions could use richer memory (like files of learned skills or longer-term memory banks).
- The training algorithm works well but still uses some heuristics; more polished, theory-backed methods could improve stability and speed.
- The test worlds are games and simulations; the next step is to scale this to broader, messier real-world settings and longer sequences.
If you think of the AI as a student, this paper is about teaching that student not just to pass one test, but to keep a notebook, learn from every attempt, and become better and better as the semester goes on—no matter which class they’re in.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
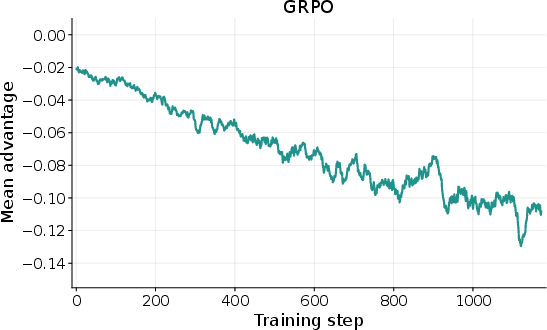
- RL algorithm grounding: The GRPO/REC-style method with adaptive re-weighting lacks theoretical analysis; no study of bias/variance trade-offs, convergence, or stability compared with PPO/GAE, V-trace, or critic-based methods.
- Credit assignment at scale: Returns are defined as the average of rewards-to-go with per-position baselines; no investigation of discounting, finite windows, or multi-timescale credit assignment for longer sequences.
- Baseline comparability: Group baselines ignore that episodes at the same position start from different contexts z; no context-aware value functions or baselines conditioned on z are explored.
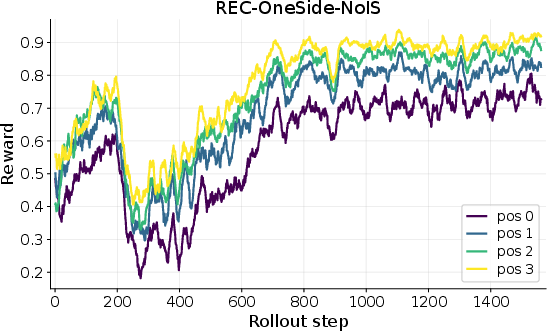
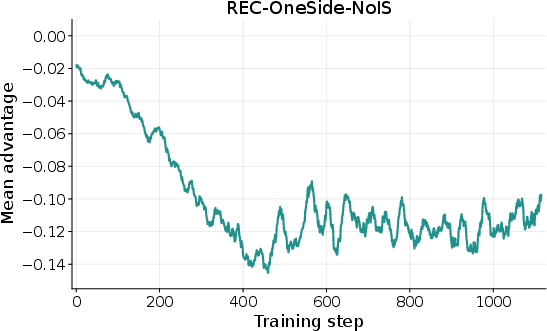
- Off-policy bias: Importance sampling is removed (REC-OneSide-NoIS) without quantifying induced bias or comparing to IS-stabilized or V-trace-style corrections.
- Training instability in mixed domains: Observed instability in Setting B (mixed environments) is not resolved; no analysis of domain interference, curriculum design, or per-domain normalization to stabilize learning.
- Reward design for update-context episodes: Update episodes receive only a “format” reward; no intrinsic metrics (e.g., information gain, compressibility, expected future value add) to directly incentivize useful context updates.
- Exploration-exploitation control: No explicit exploration strategy (e.g., curiosity, UCB, Thompson sampling); balancing exploration to discover transferable knowledge vs exploiting the current context is unaddressed.
- Context representation limits: Cross-episode context is a single “hint” string; no persistent memory, retrieval-augmented storage, skill libraries, or structured artifacts (files, graphs) were tested.
- Compute and context budgeting: The agent cannot decide when/how much to “think” or update context; no controller to learn compute allocation across solve-task vs update-context episodes.
- Memory scaling and management: No methods for compressing, retrieving, or pruning growing context; no study of prompt-window constraints, hint truncation policies, or compression fidelity.
- What to learn in weights vs in context: The system does not decide what should be internalized into model weights vs kept in external context; no regularizers or information bottlenecks to induce such partitioning.
- Long sequence scaling: Training used sequences of length 4 and evaluation length 8; no scaling laws or stability tests for much longer sequences representative of real long-lifecycle deployment.
- Non-stationary environments: CoD-Train/Deploy on drifting or evolving environments is untested; no metrics for catastrophic forgetting or adaptation lag across shifts.
- Stochasticity and partial observability: Environments appear mostly deterministic and structured; robustness under stochastic transitions, noisy feedback, and partial observability remains unknown.
- Causal attribution of gains: TerminalSimulator improvements may stem from in-episode behaviors rather than cross-episode CoD; no ablations disabling context updates, freezing hint quality, or comparing to reflection-and-retry baselines.
- Baseline comparisons: No empirical comparison against meta-RL approaches (e.g., RL2, LaMer, MAGE, Orbit), sequential inference scaling RL, or reflection-and-retry pipelines under matched compute.
- Real-world external validity: Generalization is shown on synthetic games and a terminal simulator; no evaluations on realistic long-lifecycle tasks (e.g., personal assistants with user memory, multi-month repository maintenance).
- Safety and robustness of context: No mechanisms to prevent accumulation of spurious, adversarial, or poisoned context; no uncertainty estimation, verification, or confidence-weighted hint integration.
- Adversarial and deceptive settings: No tests with environments containing misleading clues or reward hacking opportunities for update-episodes; resilience to prompt injection within hints is unmeasured.
- Evaluation metrics: Success rate dominates; missing metrics include context quality/accuracy, transfer efficiency (delta performance from early to late positions), exploration cost, time-to-success, forgetting rate, and compute overhead.
- Sample efficiency and compute cost: Token counts, environment steps, and wall-clock compute are not reported; no comparison of sample efficiency vs standard RL or reflection-based pipelines.
- Model scaling and generality: Only Qwen3-8B-Instruct is tested; no cross-model-family or model-size scaling results to understand capacity dependence and generalization trends.
- Mixture training strategies: No investigation of curriculum schedules, domain-balanced sampling, replay buffers, or gradient surgery to mitigate cross-domain interference.
- Credit granularity: Token-mean aggregation is used; no exploration of per-turn/per-action weighting, step-wise grouping, or variance-reduction techniques tailored to multi-episode trajectories.
- Return shaping for update-episodes: Update-context rewards do not estimate expected downstream improvement; no counterfactual or hindsight-based credit (e.g., leave-one-update-out) to evaluate an update’s utility.
- Tool use and external memory: CoD is not integrated with vector databases, filesystem artifacts, or skill repositories; no study of retrieval policies or long-term skill evolution.
- Privacy and governance: Long-lifecycle context for real users raises privacy and data governance issues; no techniques for on-device storage, differential privacy, or access control are discussed.
- Cross-environment interference: Potential negative transfer when switching environments is not measured; no namespacing, context isolation, or per-environment memory segmentation is proposed.
- Robustness to prior knowledge leakage: For tasks like FrozenLake-Obscure, the model might infer mappings from prior training; no controls or checks to ensure information-theoretic limits are respected during evaluation.
- Integration into post-training pipelines: The proposed integration strategies (sequential stage, CoD teacher distillation/merging) are untested; no measurements of interference/synergy with domain-specific RLVR or SFT.
- Long-horizon within-episode tasks: Most tasks are short or structured; no tests on complex multi-tool, web-navigation, or real-world planning tasks requiring deep intra-episode context management.
- Theoretical limits and guarantees: Beyond toy examples, there is no formal characterization of when and how CoD yields information-theoretic or sample-efficiency gains over task-by-task RL.
- Hyperparameter sensitivity: No systematic study of sensitivity to rollout group size, advantage normalization, clipping, re-weighting temperature, or synchronization intervals.
- Reproducibility details: Key training statistics (random seeds, rollout counts, environment instances, code paths for stability fixes) are not fully specified for precise replication.
Practical Applications
Immediate Applications
Below are concrete ways to use the paper’s findings and tooling today, given the released implementation and demonstrated gains on synthetic and terminal-style tasks.
- CoD training and evaluation toolkit adoption
- Sector: Academia, AI labs, agent platforms
- What: Use the released Trinity-RFT CoD workflows, GRPO-style algorithm with fine-grained credit assignment, and the provided environments (FrozenLake-Obscure, Alchemy-Random, TerminalSimulator) to train/evaluate agent meta-capability for context updating across tasks.
- Tools/Workflows: End-to-end RL with interleaved solve-task and update-context episodes; per-position advantage baselines; environment-wise meta-workflow; “hint” memory appended to prompts.
- Assumptions/Dependencies: Clean, automatable reward signals per task; sufficient compute and long-context inference; environment APIs that expose textual feedback; willingness to run RL rather than purely SFT.
- Agent scaffolding simplification via trained CoD meta-capability
- Sector: Agent platforms, software vendors
- What: Reduce brittle hand-crafted memory heuristics by inserting a CoD post-training stage so agents learn to update and exploit context natively.
- Tools/Workflows: Add CoD-Train as a sequential stage in post-training; use Trinity-RFT integration; evaluate on CoD counterparts of existing benchmarks.
- Assumptions/Dependencies: Pipeline integration effort; reward design and logging; monitoring for drift during training.
- DevOps/SRE terminal copilots that learn environment quirks across tickets
- Sector: Software/IT operations
- What: Terminal agents that, during day-to-day use, maintain a short “hint” (e.g., OS/version specifics, path conventions, throttling rules) and leverage it on subsequent tickets to reduce retries and command errors.
- Tools/Workflows: CoD-Deploy loop in a sandboxed terminal; periodic update-context episodes to refine hints from observed failures/successes.
- Assumptions/Dependencies: Sandboxing and rollback; audit logs; outcome rewards (e.g., task success within step budget); guardrails for destructive commands.
- Repository-aware coding assistants that accumulate project-specific context
- Sector: Software engineering
- What: IDE or chat-based coding agents that learn build/run commands, code style, test configuration, and CI idiosyncrasies over a sprint, improving fix/build rates over time.
- Tools/Workflows: Interleave coding attempts with update-context notes; “hint” includes verified commands, failure signatures, and accepted patterns; optional Ralph-loop for repeated failing tests.
- Assumptions/Dependencies: Permissioned repo access; clear success criteria (tests pass, build succeeds); retrieval or memory size management; human-in-the-loop approvals.
- Customer support agents that refine internal SOPs with environment context
- Sector: Customer service/CRM
- What: Agents learn product/version mappings, escalation policies, and knowledge base quirks across tickets to reduce handle time and misrouting.
- Tools/Workflows: CoD-Deploy across ticket sequences; hints store validated steps and disambiguation rules; rewards from resolution, QA scores, or supervisor feedback.
- Assumptions/Dependencies: PII and compliance controls; robust feedback channels; task similarity within queues.
- Process automation bots that adapt to firm-specific form schemas
- Sector: Enterprise RPA, back-office ops
- What: Bots that quickly learn variant field names, validation rules, and document layouts across similar forms (e.g., expense, invoice, onboarding).
- Tools/Workflows: Update-context episodes when a validation error occurs to add schema notes; reward from system acceptance checks.
- Assumptions/Dependencies: Access to validation endpoints; privacy constraints; drift monitoring.
- Research and evaluation harness for meta-RL on LLMs
- Sector: Academia, evaluation organizations
- What: Use the CoD environments and the fine-grained credit assignment scheme to benchmark cross-episode learning dynamics and OOD generalization.
- Tools/Workflows: In-domain OOD tests (harder instances, longer sequences), cross-domain transfer to new environments, Ralph-loop settings for repeated attempts.
- Assumptions/Dependencies: Synthetic environments may not fully reflect real-world complexity; careful interpretation of cross-domain gains (esp. TerminalSimulator).
- Better test-time scaling (Ralph-loop) via CoD-trained policies
- Sector: Software, scientific automation, reasoning systems
- What: Improve multi-try, reflect-and-retry workflows by training models that update and exploit context effectively across attempts.
- Tools/Workflows: Apply CoD-Train, then deploy in Ralph loops where attempts are the “task sequence.”
- Assumptions/Dependencies: Availability of measurable per-attempt reward; stable prompt/memory protocols.
Long-Term Applications
These require further research, scaling, richer memory systems, safety frameworks, or real-world environment integration.
- Persistent, privacy-preserving personal assistants that learn over months
- Sector: Daily life, consumer software
- What: OS-level assistants that continually accumulate user preferences, device configurations, and routines to streamline tasks (scheduling, home automation, shopping).
- Tools/Workflows: Richer memory (files, skills, knowledge graphs) beyond simple hints; periodic update-context episodes; governance to decide weights vs. context learning.
- Assumptions/Dependencies: Explicit consent and privacy; memory governance (retention/forgetting); handling non-stationary preferences; edge vs. cloud compute.
- Autonomous software maintenance and repo stewardship
- Sector: Software engineering
- What: Agents that maintain dependency health, refactor modules, fix flaky tests, and update CI/CD policies across many tasks while learning project quirks.
- Tools/Workflows: Long-lifecycle CoD-Deploy integrated with CI gates; offline sandboxes; risk-aware reward shaping (e.g., rollout success without regressions).
- Assumptions/Dependencies: Strong safety gates (approval workflows, canarying, rollbacks); rich evaluation harnesses; memory scaling and retrieval quality.
- EHR-aware clinical workflow assistants
- Sector: Healthcare
- What: Agents that learn local EHR templates, order sets, and documentation norms to reduce clicks and errors, and to pre-populate notes safely.
- Tools/Workflows: Simulated CoD environments before live deployment; high-confidence reward signals (chart audit, guideline conformance); human review loops.
- Assumptions/Dependencies: Regulatory clearance, bias/fairness checks, strict auditability, deterministic behavior requirements; robust fail-safes.
- Site-adaptive industrial and warehouse robots
- Sector: Robotics, manufacturing, logistics
- What: Embodied agents that learn site-specific maps, tool affordances, and safety constraints across tasks (pick/pack, inspection, replenishment).
- Tools/Workflows: CoD integrated with embodied RL and sensor feedback; update-context episodes that write skills and maps; sim-to-real transfer.
- Assumptions/Dependencies: High-fidelity simulators; safety certification; reliable reward instrumentation; latency and compute constraints on-device.
- Financial operations copilots that learn internal schemas and controls
- Sector: Finance, accounting, risk/compliance
- What: Agents that adapt to firm-specific ledgers, reconciliation quirks, and compliance steps across monthly/quarterly cycles to cut close times and errors.
- Tools/Workflows: CoD-Train with realistic simulators; memory-backed SOPs; policy-driven approvals; anomaly detection as reward signal.
- Assumptions/Dependencies: Strong audit trails; regulatory alignment; drift detection; role-based access control.
- Government case-management and form-processing agents
- Sector: Public sector, policy
- What: Agents that adapt to agency-specific requirements, legacy systems, and changing eligibility rules while improving throughput and accuracy.
- Tools/Workflows: CoD evaluation standards for transparency; reproducible update-context logs; human-in-the-loop adjudication.
- Assumptions/Dependencies: FOIA/compliance, fairness guarantees, accessible audit logs, procurement and certification pathways.
- Generalist CoD models via on-policy distillation and model merging
- Sector: AI labs, platform providers
- What: Train domain-specific CoD teachers, then merge (or distill) into generalist agents that retain cross-domain context-update proficiency.
- Tools/Workflows: On-policy distillation pipelines; staged CoD-Train integrated with domain RLVR; curriculum of diverse CoD environments.
- Assumptions/Dependencies: Large-scale compute; stability of multi-domain RL; evaluation suites that capture long-lifecycle performance.
- Rich memory architectures and governance for long-lifecycle agents
- Sector: Agent platforms, MLOps
- What: Move from “hint” strings to governed memory banks, skill files, and knowledge graphs with write/read policies and automatic pruning.
- Tools/Workflows: Update-context episodes produce structured artifacts; validators score memory usefulness; retrieval-augmented action selection.
- Assumptions/Dependencies: Memory bloat control; attribution and provenance tracking; standardized memory schemas and APIs.
- Standards and benchmarks for long-lifecycle agent evaluation
- Sector: Standards bodies, eval orgs, academia
- What: Establish CoD-style benchmarks that measure cross-task learning, non-stationarity handling, and OOD generalization across domains.
- Tools/Workflows: Public leaderboards with sequence-length scaling; protocol for reward density, credit assignment, and safety reporting.
- Assumptions/Dependencies: Community consensus on metrics; open, reproducible environments; scalable evaluation infrastructure.
- Cloud auto-ops agents that adapt runbooks across heterogeneous stacks
- Sector: Cloud/SRE
- What: Agents that learn per-account quirks (quotas, IAM patterns, network topologies) across incidents/changes to accelerate MTTR and reduce misconfigurations.
- Tools/Workflows: Incident simulators; CoD-Deploy in staging; reward from MTTR reduction and post-incident QA.
- Assumptions/Dependencies: Strict RBAC; blast-radius controls; comprehensive logging and rollback.
- Data engineering assistants that learn pipeline idiosyncrasies
- Sector: Data/ML engineering
- What: Agents that learn DAG structures, transient failure signatures, and vendor/API quirks to fix jobs and optimize SLAs over time.
- Tools/Workflows: Update-context from error logs and successful remediations; rewards from SLA adherence and cost reduction.
- Assumptions/Dependencies: Access to observability data; stable reward instrumentation; shadow-mode deployment before autonomy.
- Marketplace of CoD training environments and simulators
- Sector: MLOps tooling, ecosystem
- What: Curated, domain-specific CoD environments (IT, finance, retail, robotics-lite) for safer pre-deployment training and benchmarking.
- Tools/Workflows: Environment catalogs with reward APIs; scenario difficulty scaling; connectors to Trinity-RFT-like frameworks.
- Assumptions/Dependencies: Standardized interfaces; licensing and data generation policies; maintenance of environment diversity.
- Safety and governance frameworks for self-updating agents
- Sector: Policy, risk, corporate governance
- What: Policies and tooling for oversight of agents that maintain/update their own context: logging, reproducibility, rollback, red-teaming, privacy.
- Tools/Workflows: Memory change audit trails; gated update-context episodes; approval workflows; periodic safety evaluations under CoD protocols.
- Assumptions/Dependencies: Organizational commitment to safety; regulatory clarity; cross-disciplinary collaboration.
Notes on feasibility and key dependencies across applications
- Reward design and instrumentation are critical: CoD relies on meaningful, frequent rewards per task and clear termination criteria.
- Memory scaling and governance: Moving from short “hints” to persistent, structured memory requires retrieval quality, pruning, provenance, and privacy controls.
- Safety, compliance, and auditability: Especially for regulated domains (healthcare, finance, public sector), strong guardrails, deterministic modes, and human oversight are prerequisites.
- Generalization limits: Current empirical evidence uses synthetic/game-like domains and an 8B model; real-world performance will depend on richer environments, larger models, and longer sequences.
- Compute and infrastructure: End-to-end RL for LLMs is resource-intensive and benefits from long-context models, efficient sampling, and robust RL infra (e.g., Trinity-RFT).
- Deciding what to learn in weights vs. context remains an open research area; expect iterative tuning of training curricula and memory protocols.
Glossary
- Advantage: A baseline-centered measure of how much better an action/logit is than expected, used to weight policy-gradient updates. "Finally, we define advantages as"
- Agent scaffolds: Hand-designed control structures around an LLM (planning, tools, memory) that help it operate over long horizons. "agent scaffolds with sophisticated design"
- Alchemy-Random: A synthetic environment with randomized elements and recipes where agents must discover valid combinations across tasks. "Alchemy-Random is another game scenario"
- Baseline (policy gradient): A reference value (here, per-position group mean return) subtracted from returns to reduce variance in gradient estimates. "the baseline at position is defined as"
- CoD (Connect the Dots): The paper’s meta-capability where an agent learns across a sequence of tasks by updating and using context about its environment. "CoD meta-capability"
- CoD-Deploy: The deployment-time process interleaving solving tasks and updating the agent’s context in a long-lifecycle environment. "CoD-Deploy is an abstraction of long-lifecycle agentic deployment"
- CoD-Train: The RL post-training process that mirrors CoD-Deploy to optimize model weights for the CoD meta-capability. "CoD-Train denotes the corresponding RL post-training process"
- Credit assignment: The problem of attributing delayed rewards to earlier actions/episodes in long trajectories. "credit assignment across solve-task and update-context episodes"
- Dynamic-programming principle: The Bellman-style idea of maximizing both immediate and future rewards for each decision/episode. "We adopt the classical dynamic-programming principle"
- End-to-end reinforcement learning (RL): Training the policy across full multi-episode trajectories rather than isolated steps or tasks. "end-to-end reinforcement learning (RL)"
- Format reward: A small auxiliary reward given to encourage properly formatted outputs during context-update episodes. "we assign only a small format reward"
- FrozenLake-Obscure: A variant of FrozenLake where the mapping from abstract actions (A/B/C/D) to directions is hidden and permuted per environment. "FrozenLake-Obscure is analogous to the classic FrozenLake game"
- GiGPO: An RL algorithm (“Group-in-Group Policy Optimization”) that leverages repeated “anchor states” across trajectories. "employ the GiGPO algorithm"
- GRPO (Group Relative Policy Optimization): A policy-gradient variant that uses group-relative baselines to compute advantages without a learned critic. "a GRPO-style RL algorithm"
- Hierarchical reinforcement learning: Multi-level RL where higher-level decisions (e.g., across tasks) guide lower-level behavior; CoD adds a level above task-level RL. "From the perspective of hierarchical reinforcement learning"
- Importance sampling (IS) weights: Weights that correct for distribution shift between rollout (behavior) and current (target) policies in off-policy updates. "importance-sampling (IS) weight"
- Information-theoretic limit: A performance ceiling imposed by unavailable information, regardless of strategy, when solving tasks from scratch. "This imposes an information-theoretic limit"
- LLM inference scaling: Increasing test-time performance via additional or structured LLM calls (sequential/parallel), often with self-improvement. "LLM inference scaling at test time"
- Meta reinforcement learning: Training agents to rapidly adapt to new tasks by learning how to learn from within-episode/within-sequence experience. "meta reinforcement learning"
- OOD generalization (Out-of-distribution generalization): The ability to transfer the learned capability to unseen domains, environments, or settings. "out-of-distribution generalization"
- On-policy distillation: Distilling a student model from a teacher using trajectories sampled from the current policy, aligning training and data distributions. "on-policy distillation"
- Outcome reward: A scalar reward signal assigned to the result of each task/episode, used for policy learning. "outcome rewards"
- PPO (Proximal Policy Optimization): A clipped policy-gradient algorithm that stabilizes updates by constraining policy changes. "Standard PPO and GRPO calculate the gradient update"
- Ralph-loop: A repeated-attempt setting for the same task where the agent reflects and retries to improve its solution. "Ralph-loop settings"
- REC (REINFORCE-with-clipping): A REINFORCE variant that uses clipping to stabilize gradient estimates. "REINFORCE-with-clipping (REC) series"
- REC-OneSide-NoIS: A REC variant using one-sided clipping and no importance-sampling weights for stability and simplicity. "REC-OneSide-NoIS"
- RED-Weight: An adaptive reweighting heuristic to balance positive/negative gradients and stabilize training. "RED-Weight method"
- Return (rewards-to-go): The (possibly averaged) sum of current and future rewards used as the training target for each episode. "mean of rewards-to-go"
- RL2 paradigm: A meta-RL formulation where an RNN’s hidden state serves as cross-episode context within a concatenated trajectory. "RL paradigm"
- Rollout trajectory: A sequence of states, actions, and rewards generated by interacting with environments under a policy. "rollout trajectory"
- TerminalSimulator: A simulated terminal environment for evaluating command-line task-solving abilities. "TerminalSimulator is a simulation scenario"
- Trinity-RFT: A modular, decoupled LLM-RL framework used to build the paper’s training infrastructure. "Trinity-RFT"
- Underspecification: A condition where task/environment specifications are incomplete, requiring online adaptation and context management. "environments with underspecification"
- Update-context episode: An episode dedicated to distilling and storing newly learned information/skills into persistent context for future tasks. "For each update-context episode, we assign only a small format reward"
Collections
Sign up for free to add this paper to one or more collections.

