LLM-in-Sandbox Elicits General Agentic Intelligence
Abstract: We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces “LLM‑in‑Sandbox,” a way to let AI LLMs use a safe, virtual computer while they work. Inside this private “computer playground,” the AI can:
- look up resources (like the internet),
- read and save files, and
- write and run small programs.
The surprising idea: even for tasks that aren’t about coding (like math word problems, science questions, or long documents), giving the AI a computer to explore helps it solve problems better and more reliably.
What questions were the researchers asking?
The authors focus on three main questions:
- If we give an AI a safe computer to use, will it naturally use tools like the web, files, and code to solve non-coding tasks better?
- Can we train AIs to get better at using this “sandbox,” even if we only have ordinary, non-agent training data (no special tool-use demos)?
- Is this approach practical in the real world—fast enough, cheap enough, and simple enough to deploy?
How did they do it?
The “sandbox”: a safe computer playground
Think of the sandbox as a locked, temporary computer—like a guest account that’s isolated from everything else. The AI can:
- run commands (like a terminal),
- read/write files (like notes, documents, or results), and
- install tools it needs (for example, a math or chemistry library).
The base setup is intentionally minimal: just Python and a few basic scientific libraries. If the AI needs something else, it can fetch and install it during the task.
The workflow: think, act, check, repeat
The AI solves a task in small steps:
- Thinks about what to do next (e.g., “I should search this document”).
- Takes an action in the sandbox (run a command, edit a file, execute a script).
- Reads the result (what happened).
- Decides the next step or submits the final answer.
This loop continues for several turns, like a student doing a mini research project with a computer.
Training the AI to explore (LLM‑in‑Sandbox‑RL)
Some smaller/weaker models don’t naturally use the sandbox well—they “wander” and waste steps. To fix this, the authors created a training method:
- They give the AI tasks where the clues are placed as files in the sandbox (like a scavenger hunt across documents).
- The AI gets a simple reward: a “thumbs up” only if the final saved answer is correct (no step-by-step hints).
- Over time, the AI learns practical habits: find the right files, run useful scripts, and avoid busywork.
Importantly, they only used regular, general-purpose data (like articles and questions), not special “tool-use” datasets.
What did they find?
Here are the main takeaways, with simple examples:
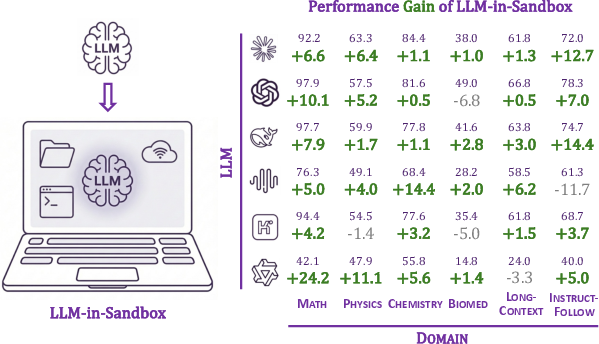
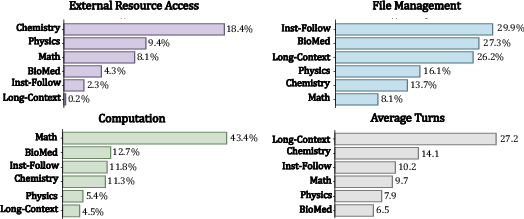
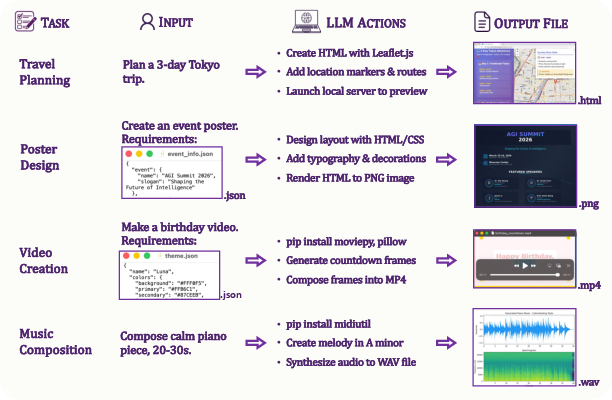
- Letting strong AIs use the sandbox boosts performance on many non-code tasks.
- Mathematics and science: AIs write small scripts to calculate and check answers instead of doing it all “in their head.”
- Chemistry: AIs install domain tools to convert chemical names into structures and then compute properties.
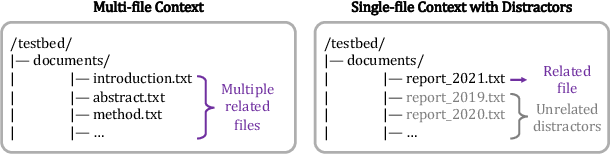
- Long documents: Instead of stuffing a huge report into the prompt, AIs load files in the sandbox and use search tools (like “find lines mentioning X”), then extract answers efficiently.
- Following tricky instructions: For example, if the task says “write three sentences with the same length and no overlapping words,” the AI writes a script to measure lengths and check word overlaps—much more reliable than guessing.
- Training with LLM‑in‑Sandbox‑RL helps weaker models become competent explorers.
- Before training: weaker models took many turns but used few useful tools.
- After training: they used the internet, files, and code more often and solved tasks in fewer turns.
- It generalizes widely.
- The training used only general data where context lives in files, yet the benefits carried over to many domains (math, physics, chemistry, biomedicine, long texts, instruction-following) and even to software engineering tasks.
- Surprisingly, skills learned in the sandbox also improved the model’s normal, text-only mode—suggesting better habits like organizing steps and verifying answers.
- It can be more efficient—especially for long documents.
- By keeping big documents as files instead of stuffing them into the prompt, token usage (and thus cost) dropped a lot—up to about 8× fewer tokens in long-context scenarios.
- The system scaled well and didn’t need heavy, per-task setups; one lightweight image worked for many tasks.
- It’s practical and available.
- The team released a Python package that works with common LLM backends (like vLLM and SGLang) and APIs.
Why is this important?
- Makes AIs more capable: Giving an AI a “computer to use” turns it from a pure text predictor into a problem-solver that can look things up, organize information, and run checks.
- Handles long and complex tasks: The sandbox lets AIs deal with large documents and strict formatting rules far more reliably.
- Easier training and deployment: The RL method doesn’t need special tool-use datasets, and the sandbox is light to run—making it practical for real-world systems.
- Broad improvement: Skills learned while exploring (like searching, verifying, and structuring work) seem to spill over into everyday AI use, even without the sandbox.
In short, LLM‑in‑Sandbox is like handing the AI a safe laptop. It explores, installs tools, writes small programs, and checks its work—leading to better results across many subjects, especially when dealing with big, messy, or rule-heavy tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper—framed to be concrete and actionable for future research.
- Security and safety of sandboxed internet access: no formal threat model or evaluation of risks from package installation, prompt injection from web content, data exfiltration, supply-chain attacks (e.g., malicious apt/pip packages), or misuse of network resources; lacks whitelisting, vetting, resource quotas, and runtime policy enforcement strategies.
- Reproducibility under nondeterminism: external resources (web pages, package versions, network availability) and runtime installations introduce run-to-run variability; no systematic reproducibility protocol (version pinning, mirroring, deterministic caches, network snapshotting) or measurement of outcome variance across repeated trials.
- Baseline breadth and attribution: comparisons primarily against vanilla LLM and text-only RL; missing head-to-head baselines with established agent/tool frameworks (e.g., browser agents, retrieval-augmented systems, AutoGPT-style planners, SWE agents) on the same non-code tasks to isolate the sandbox’s unique contribution.
- Meta-capability ablations: no controlled experiments disabling one capability at a time (internet access, file I/O, code execution) to quantify each component’s causal impact on performance and efficiency across domains.
- Reward design and credit assignment: outcome-only rewards may be sparse for multi-step exploration; untested alternatives (dense/shaped rewards for correct file navigation, tool calls, intermediate checks), off-policy relabeling, or hierarchical RL to improve sample efficiency and stability.
- Failure handling and robustness: observed package conflicts and tool installation issues are anecdotal; lacks systematic evaluation of recovery strategies (rollback, dependency resolution, caching, retries), impact of transient network errors, and failure mode taxonomy.
- Scaling laws for sandbox RL: unknown relationships between data scale, compute budget, interaction length, and generalization gains; no scaling studies (curves, plateaus, diminishing returns) or guidance on optimal training regimes.
- Generalization breadth: evaluation domains exclude many real-world settings (law, finance, multimodal documents with tables/figures, GUI/web-browser interactions); unclear if sandbox skills transfer to tasks requiring structured extraction, OCR, or visual reasoning within a multimodal sandbox.
- Model diversity and language coverage: training/evaluation limited to two open-weight models and a small set of proprietary systems; missing analyses across sizes, architectures, languages (non-English), and instruction-following vs. code-specialized models to assess universality.
- Statistical rigor: several gains are modest; no confidence intervals, hypothesis testing, or seed-based variance reporting to establish significance and reliability of improvements.
- Long-context retrieval quality: token savings are shown, but no accuracy/recall analysis of file-based grep/sed workflows versus full-context reading; need metrics for missed evidence, parsing failures, and sensitivity to document structure/layout.
- Environment isolation vs. scalability: single shared image reduces footprint but risks environment pollution and cross-task interference (persisted installations, files); lacks evaluation of per-task isolation, cleanup policies, image layering, and their effects on throughput and reproducibility.
- Toolset minimalism trade-offs: only three tools (bash, file editor, submit); unexplored whether adding structured tools (search APIs, calculators, retrievers, dataframes) improves reliability and efficiency, and how tool discoverability/schema design affects learning and performance.
- Mechanisms of transfer to vanilla LLM mode: observed increases in structural/verification patterns are correlational; no causal analyses or controlled studies explaining why agentic skills learned in sandbox transfer to text-only generation.
- Efficiency characterization gaps: throughput reported but lacks latency distributions (p50/p95), cold-start overhead for sandbox/container init, GPU utilization, memory I/O contention, and end-to-end orchestration costs under higher concurrency (>64) and diverse workloads.
- SWE capability retention: general-data sandbox RL modestly improves SWE-bench Verified, but no long-term or larger-scale assessment of catastrophic forgetting or trade-offs when training on non-code tasks; need retention tests across multiple SWE benchmarks and versions.
- Safety of code execution: beyond host isolation, no assessment of commands that can exhaust resources (fork bombs, large downloads), how quotas are enforced (CPU/mem/disk/network), or how to detect/mitigate harmful behaviors within the container.
- Benchmark integrity and leakage controls: internet-enabled agents risk retrieving benchmark-specific answers; current “reframing” and manual checks are informal; need standardized anti-leakage protocols, logging, and public trajectories for auditing.
- Observability and instrumentation: capability usage is identified via pattern matching, which may yield false positives/negatives; open need for robust telemetry (action schemas, event logs, provenance), standardized taxonomies of tool use, and automatic labeling for analysis.
- Prompting strategies: only one exploration-focused system prompt is reported; missing ablations of prompt components, adaptive prompting (self-reflection, ToT, planning), and policies that guide safer/more efficient exploration.
- Curriculum and task design: sandbox RL uses general context tasks placed in files, but no study of curricula (progressive difficulty, distractor density), multi-document graph structures, or instruction schemas that best teach exploration skills.
- Data and training reproducibility: unclear whether the RL training data, code, and runs are fully released (licenses, versions, preprocessing); need documented pipelines enabling third parties to replicate results end-to-end.
- Human-in-the-loop and governance: no integration of oversight, escalation, or guardrails (approval for installations, sensitive network access, data export) for deployment; open question how to design interactive policies that balance autonomy with safety.
- Policy, compliance, and licensing: runtime installation of packages and fetching content introduces licensing and compliance questions (e.g., GPL, data usage policies); no framework for tracking licenses, provenance, and enabling audit/compliance controls.
Practical Applications
Immediate Applications
Below are actionable, deployable-now uses that leverage the paper’s sandboxed agent paradigm and the released Python package.
- Long-context document analytics without prompt stuffing (token-cost reduction)
- Sectors: finance (10-K/10-Q, risk reports), legal (e-discovery, contracts), healthcare (clinical guidelines, payer policies), education (textbook chapters), government (public comments, policy texts).
- Tools/products/workflows: File-first Q&A service that mounts documents into /testbed/documents and returns /testbed/answer.txt; “TokenSaver” wrapper for LLM gateways to automatically offload large contexts to the sandbox filesystem; connectors to S3/GCS/SharePoint for zero-copy doc mounting.
- Assumptions/dependencies: Access to the provided Python package; Docker/OCI runtime for isolation; basic Python + scientific stack available; document sanitization; I/O policies and timeouts; no need for model retraining.
- Compliance and audit automation using shell and Python
- Sectors: finance (SOX, AML), legal (policy checks), enterprise IT (config drift, license scanning).
- Tools/products/workflows: “Compliance Auditor Bot” that compiles grep/sed/Python scripts from policies and runs them against mounted corpora; produces reproducible logs and an answer.txt report; scheduled jobs via CI/CD.
- Assumptions/dependencies: Deterministic rules or heuristics; read-only mounts to prevent data alteration; auditable command logs; allow-listed shell tooling.
- High-precision instruction following with code-enforced constraints
- Sectors: marketing (brand/legal constraints), localization (length/character sets), education (rubrics), publishing (style guides).
- Tools/products/workflows: “Format Enforcer” agent that generates content, then validates with scripts (length, regex, lexical overlap) and iterates until constraints are met; exports validated deliverables.
- Assumptions/dependencies: Sandbox can execute Python; clear, machine-checkable constraints; latency tolerance for multi-iteration loops.
- On-demand domain tool augmentation in a safe, isolated VM
- Sectors: pharma/materials (OPSIN/RDKit for chemical structures, QSAR), academic labs (numerical solvers), media (ffmpeg), GIS (GDAL).
- Tools/products/workflows: “ChemAgent in Sandbox” that installs OPSIN/RDKit at runtime, converts names → structures, computes properties; cached layer for common tools to speed cold starts.
- Assumptions/dependencies: Internet or internal mirror access for apt/pip; egress controls; license compliance; package integrity checks.
- Lightweight ETL and data wrangling from semi-structured files
- Sectors: operations, analytics, customer support (logs, CSVs), public sector (bulk PDFs).
- Tools/products/workflows: “ETL-in-a-Box” that writes small pandas/regex scripts to clean, join, and summarize files; saves outputs as CSV/JSON.
- Assumptions/dependencies: Stable filesystem mounting; resource limits to prevent runaway jobs; schema drift handling.
- Reproducible research assistant for academics and data teams
- Sectors: academia, enterprise analytics.
- Tools/products/workflows: “Repro Lab Assistant” that reads methods/datasets from files, writes analysis scripts, executes them, and stores artifacts; full terminal transcript kept for provenance.
- Assumptions/dependencies: Version pinning for reproducibility; storage of artifacts; optional offline mode with pre-mirrored packages.
- Training weaker in-house models to use tools via LLM-in-Sandbox-RL
- Sectors: software, platform teams, vendors with on-prem LLMs.
- Tools/products/workflows: “Agentic RL Trainer” that converts internal corpora into file-based context tasks and applies outcome-reward RL to elicit purposeful sandbox exploration; evaluation harness for before/after.
- Assumptions/dependencies: Simple rule-based rewards (e.g., exact match, regex); compute budget for RL; logging/telemetry; no agent-specific data required.
- Secure agent execution gateway for regulated environments
- Sectors: finance, healthcare, public sector.
- Tools/products/workflows: “Sandbox Gateway” that provisions per-request containers with constrained CPU/memory, read-only mounts, network allow-lists, and audit logs; integrates with vLLM/SGLang backends.
- Assumptions/dependencies: Container orchestration (Kubernetes/Nomad); enterprise IAM; secrets isolation; egress filtering.
- Unified evaluation harness for agentic capabilities
- Sectors: model evaluation, MLOps.
- Tools/products/workflows: “SandboxEval” that benchmarks models across math/physics/chem/biomed/long-context/instruction-following with file-based contexts and per-turn logs.
- Assumptions/dependencies: Dataset licenses; stable task generators; metric definitions and guards against benchmark leakage.
- Personal knowledge management on a laptop
- Sectors: daily life.
- Tools/products/workflows: “Desktop Sandbox Assistant” that processes large PDFs/notes locally, extracts answers, and enforces formatting or citation constraints via small scripts—private by default.
- Assumptions/dependencies: Local Docker; local model or API; no internet required if tools bundled.
Long-Term Applications
These rely on further research, scaling, or productization beyond the current package and experiments.
- Enterprise “virtual workstation” copilot (general OS-level agent)
- Sectors: cross-industry.
- Tools/products/workflows: Persistent, policy-aware agent that installs tools, navigates file shares, calls internal APIs, and produces validated outputs with provenance.
- Assumptions/dependencies: Strong multi-tenant isolation, RBAC, secrets governance, fine-grained policy enforcement, robust rollback/snapshotting, and advanced safety filters.
- Retrieval-free “file-first RAG” alternatives at scale
- Sectors: knowledge management, legal, finance, support.
- Tools/products/workflows: Replace vector-store-heavy stacks with file-based navigation/search (grep/ripgrep/Lightweight indexes) and scripted extraction to reduce token costs and simplify infra.
- Assumptions/dependencies: Enterprise-wide doc normalization; change detection; hybridization with RAG where needed; search quality evaluation.
- Automated scientific discovery pipelines
- Sectors: pharma/materials/energy/biomed.
- Tools/products/workflows: “AutoSci Sandbox” that pulls literature, installs domain simulators, runs parameter sweeps, and writes papers/notebooks with code/data artifacts.
- Assumptions/dependencies: Access to HPC/GPU, licensing for domain tools, curated reward signals for RL, rigorous reproducibility and compliance.
- Clinical summarization and coding from complete EHR timelines
- Sectors: healthcare.
- Tools/products/workflows: “ChartCoder Sandbox” that ingests long EHR exports, reconciles multi-document context, validates coding rules via scripts, and produces auditable outputs.
- Assumptions/dependencies: PHI-safe sandboxes, HITRUST/ISO compliance, FDA/ONC considerations, human-in-the-loop review.
- Regulatory and policy intelligence at national scale
- Sectors: public policy, compliance.
- Tools/products/workflows: “Policy Insight Engine” to parse millions of pages, detect changes, simulate rule effects with code checks, and draft impact summaries.
- Assumptions/dependencies: Scalable container orchestration, offline mirrors for stability, dedup/versioning, measurable accuracy and provenance.
- Multi-agent tool ecosystems with resource-aware orchestration
- Sectors: platform engineering, IT automation.
- Tools/products/workflows: “Agent Mesh” where specialized sandbox agents (searcher, extractor, verifier) coordinate via task graphs, share artifacts, and respect quotas.
- Assumptions/dependencies: Scheduling, job preemption, artifact registry, inter-agent protocols, credit assignment for RL at scale.
- Foundation-model training with LLM-in-Sandbox-RL at scale
- Sectors: model providers, large enterprises.
- Tools/products/workflows: Massive-scale RL using general file-based tasks to elicit durable agentic behaviors transferable back to text-only mode.
- Assumptions/dependencies: Distributed RL infra, safety-aligned reward design, curriculum over capabilities (file ops, computation, external tools), evaluation suites.
- Provenance, verification, and governance-by-design
- Sectors: audit, legal, safety.
- Tools/products/workflows: “Agent Ledger” capturing cryptographic hashes of container images, commands, files, and outputs for replay; policy proofs of what executed where.
- Assumptions/dependencies: Deterministic containers, signed artifacts, tamper-evident logs, retention policies.
- Edge and offline sandbox agents
- Sectors: field operations, education, defense.
- Tools/products/workflows: On-device agents that run with pre-bundled packages and no internet, handling large local datasets and enforcing constraints via code.
- Assumptions/dependencies: Model + tools fit device constraints, content-addressed caching, battery/perf budgets, delayed sync.
- Safety-hardened sandboxes and supply-chain security
- Sectors: security, regulated industries.
- Tools/products/workflows: Mandatory access controls, syscall filtering, allow-listed package registries, untrusted-code sandboxes, and runtime anomaly detection.
- Assumptions/dependencies: OS hardening (e.g., seccomp/AppArmor), curated internal mirrors, SBOMs, continuous security monitoring.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Model capability: Gains are largest with stronger agentic models; weaker models benefit after LLM-in-Sandbox-RL. Choice of base model affects success.
- Network and package access: Many workflows assume controlled internet or internal mirrors; strict egress policies may require pre-bundling tools.
- Security and compliance: Docker isolation is necessary but not sufficient; add MAC policies, resource limits, and audit logging; handle licenses/PII.
- Reproducibility: Pin versions and snapshot environments to ensure consistent results across runs; cache heavy dependencies.
- Reward design for RL: Outcome-based rewards must be reliable (exact match, programmatic checks) to avoid reward hacking.
- Latency/throughput: Multi-turn exploration can add latency; batch jobs and caching mitigate this; long-context tasks often see net token/cost savings.
- Human-in-the-loop: For sensitive domains (clinical/legal), include review and exception handling before finalization.
Glossary
- agentic frameworks: Multi-turn systems that let models autonomously use tools to solve tasks. "Recently, agentic frameworks empowered models to leverage diverse tools across multiple turns"
- agentic LLMs: LLMs equipped with autonomous tool-use behaviors for planning and acting. "strong agentic LLMs exhibit generalization capabilities to exploit code sandboxes"
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning before giving answers. "Chain-of-thought prompting then elicited reasoning by guiding models to decompose problems into steps"
- code execution: Running programs to compute or verify results within the environment. "Code execution: writing and executing arbitrary programs."
- code sandbox: An isolated virtual computer environment where the model can run commands, edit files, and access the network. "enabling LLMs to explore within a code sandbox (i.e., a virtual computer)"
- containerized: Packaged into containers for isolation and portability across systems. "The containerized nature ensures isolation from the host system"
- Docker containers: OS-level virtualized environments used to isolate and run applications. "typically an Ubuntu-based system implemented via Docker containers"
- execute_bash: A tool interface that executes arbitrary shell commands inside the sandbox. "execute_bash for executing arbitrary terminal commands"
- external resource access: Capability to fetch information or tools from outside services such as the internet. "External resource access: fetching resources from external services (e.g., the internet);"
- file I/O operations: Programmatic reading and writing of files. "file I/O operations (e.g., open(), json.load)"
- File management: Organizing, reading, writing, and persisting data via the file system. "File management: reading, writing, and organizing data persistently;"
- File-based Context: Supplying input documents as files in the environment rather than via the prompt. "Long-Context Tasks Benefit from File-based Context."
- FLOPs: Floating-point operations, a measure of computational workload. "inference FLOPs scale linearly with token count"
- In-context learning: Learning from examples embedded in the prompt without weight updates. "In-context learning showed that models could generalize to new tasks without task-specific finetuning"
- Instruction Following: An evaluation domain where models must comply with detailed task instructions. "Instruction Following"
- Instruction Pre-Training: A data-generation/training stage that synthesizes instruction-like tasks for broad capabilities. "Instruction Pre-Training"
- LLM-in-Sandbox: The proposed paradigm where LLMs operate inside a virtual computer to solve tasks. "We introduce LLM-in-Sandbox"
- LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL): An RL method training models to explore the sandbox using only general non-agentic data. "LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL)"
- LLM-RL: A reinforcement learning baseline that trains on text-only tasks without sandbox interaction. "LLM-RL"
- Long-Context Understanding: Tasks requiring comprehension of very large inputs that exceed model context limits. "Long-Context Understanding"
- meta-capabilities: High-level abilities (external access, file management, code execution) that enable general task solving. "three meta-capabilities"
- NVIDIA DGX: A high-performance computing node used for serving and experimentation. "We use a single NVIDIA DGX node for all experiments"
- open-weight: Models whose parameters are publicly available for download and fine-tuning. "frontier proprietary, open-weight, code-specialized"
- OPSIN: A tool/library for converting chemical names to structures. "downloads the OPSIN library"
- outcome-based rewards: RL rewards given based solely on the correctness of the final output. "With only outcome-based rewards"
- pattern matching: Identifying behaviors by searching for predefined textual or command patterns. "We identify these behaviors through pattern matching on model actions"
- R2E-Gym: A software engineering task suite/environment used for training/evaluation. "software engineering data from R2E-Gym"
- RDKit: An open-source cheminformatics library for manipulating chemical data. "RDKit installed but fails to import due to NumPy version conflicts"
- ReAct framework: A prompting/control paradigm that interleaves reasoning and acting with tool feedback. "Our workflow builds on the ReAct framework"
- Reinforcement Learning: Learning via trial-and-error with rewards guiding behavior. "Reinforcement Learning (LLM-in-Sandbox-RL)"
- rule-based functions for rewards: Hand-crafted evaluators that deterministically compute RL rewards. "We use rule-based functions for rewards."
- sandbox capability usage rate: A metric quantifying how often core capabilities are invoked per interaction. "Sandbox capability usage rate comparison"
- SciPy: A Python scientific computing library providing numerical routines. "SciPy"
- SGLang: An LLM serving/inference engine used for hosting models. "SGLang~\citep{sglang}"
- str_replace_editor: A tool for creating and editing files within the sandbox. "str_replace_editor for file creation, viewing, and editing"
- submit: A tool call signaling task completion and final answer readiness. "submit for indicating task completion"
- SWE agents: Software engineering code agents that operate in sandboxed environments. "SWE agents may require up to 6 TB of storage for task-specific images"
- SWE-bench Verified: A benchmark for software engineering tasks with verified solutions. "SWE-bench Verified"
- SWE-RL: Reinforcement learning approaches specialized for software engineering in sandboxes. "SWE-RL"
- token consumption: The number of tokens processed per query, directly tied to compute cost. "dramatically reduces token consumption by up to 8×"
- tool call: A model-invoked action to use a tool (e.g., execute_bash) during interaction. "Model generates tool call a_t"
- trajectory: The sequence of actions/outputs generated during an RL episode or agent run. "the model generates a trajectory"
- Ubuntu-based system: A sandbox OS base built on Ubuntu for consistent environments. "an Ubuntu-based system"
- vLLM: A high-throughput LLM inference backend. "vLLM~\citep{vllm}"
- virtualized computing environment: A software-simulated system providing isolation and controlled capabilities. "A code sandbox is a virtualized computing environment"
Collections
Sign up for free to add this paper to one or more collections.