- The paper presents a novel interactive system that extracts minimal and sufficient evidence from web agent trajectories to enhance verification.
- It reconstructs web pages with precise state, allowing users to interactively verify agent reasoning and correct errors seamlessly.
- Empirical results show significant reduction in verification time and effort, improving accuracy and usability for complex web tasks.
Motivation and Limitations of Current Transparency Approaches
The rapid progress in LLM-based web agents has enabled delegation of complex, multi-step web tasks such as product search, option comparison, and transaction execution. However, robust verification of agent outputs remains challenging, particularly as web agents frequently exhibit suboptimal grounding, lose track of task objectives, or miss critical details, leading to potentially erroneous conclusions even amidst plausible reasoning traces. Existing transparency paradigms—comprehensive trajectory logs, source links, screenshots, and LLM-generated summaries—are fundamentally limited: they require users to passively consume overwhelming information or accept potentially unfaithful explanations, often failing to surface actionable state or verifiable evidence.
Consequently, effective human oversight is hampered by information overload and insufficient evidence traceability. Detailed logs are indiscriminately verbose, source links lack page state contextualization, screenshots are static, and LLM summaries are susceptible to rationalizing incorrect decisions equivalently to correct ones. The verification burden is inherently shifted onto users, precluding interactive scrutiny and revision.
HANSEL System Design and Evidence Extraction Pipeline
HANSEL (Highlighting Agent Navigation Steps as Evidence Links) reframes verification as an interactive process by extracting minimal, actionable evidence from web agent trajectories and presenting them as live, navigable views. The system operationalizes three primary design goals:
- Minimal Sufficient Evidence Exposure: Only pages directly supporting the agent’s answer are surfaced, reducing cognitive load and information volume.
- Direct Evidence Access with Page State Reconstruction: Evidence pages are reconstructed with preserved environmental state (applied filters, search queries, scroll positions) and embedded as interactive webviews, permitting users to probe, modify, and verify in situ.
- Evidence Gap Visibility: HANSEL flags unverifiable claims or reasoning steps, facilitating error awareness and intervention.
The extraction pipeline standardizes heterogeneous agent logs by decomposing them into an ordered sequence of (observation,reasoning,action) tuples. An LLM is then prompted with the user query, agent answer, and standardized trajectory to identify evidence pages and corresponding evidence snippets. Abandoned or unsuccessful plans, blocked pages, and navigation-only steps are excluded. Evidence snippets localize task-relevant content within each evidence page, supporting granular verification.
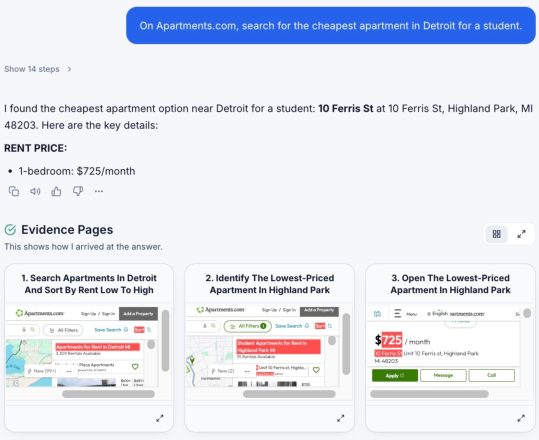
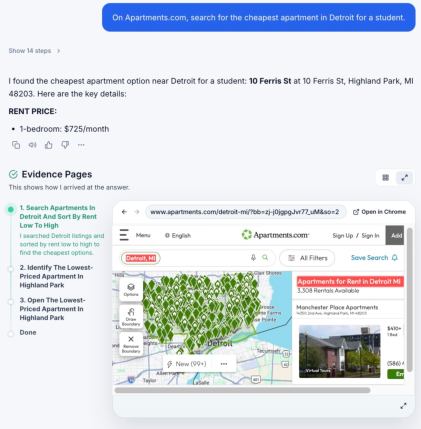
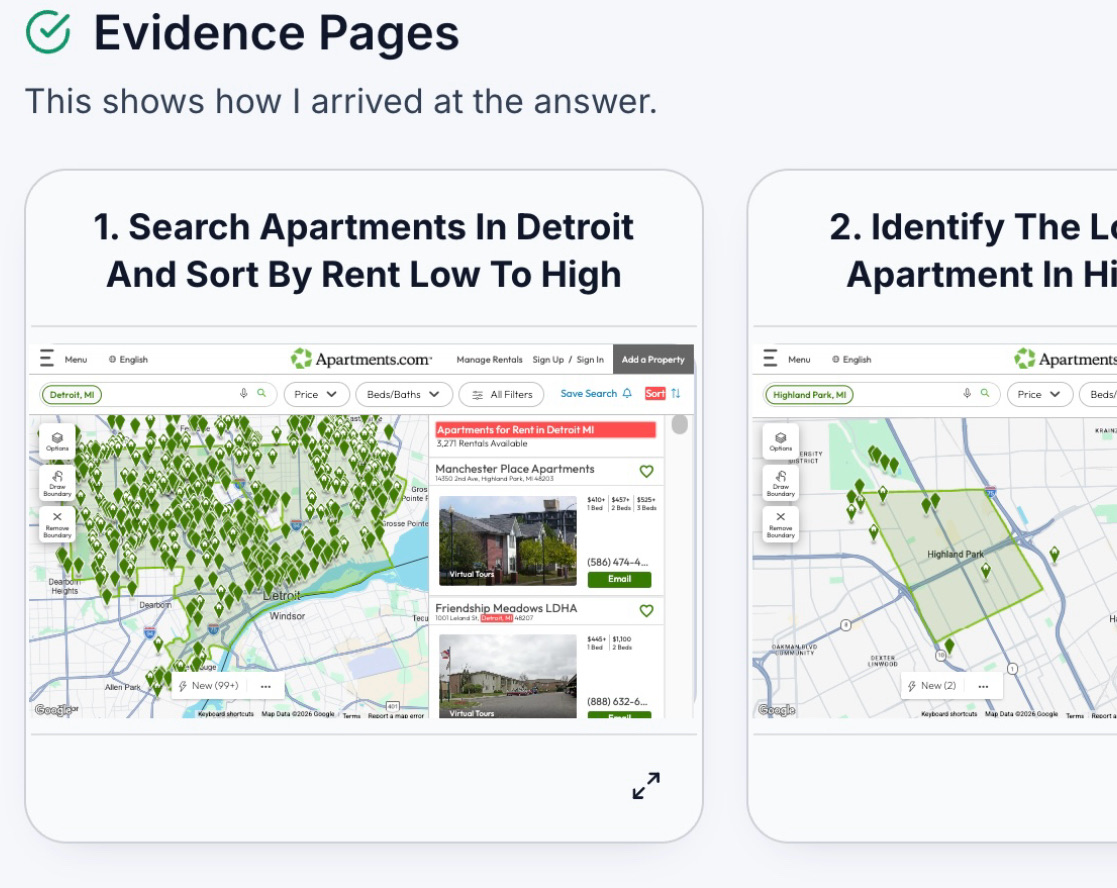
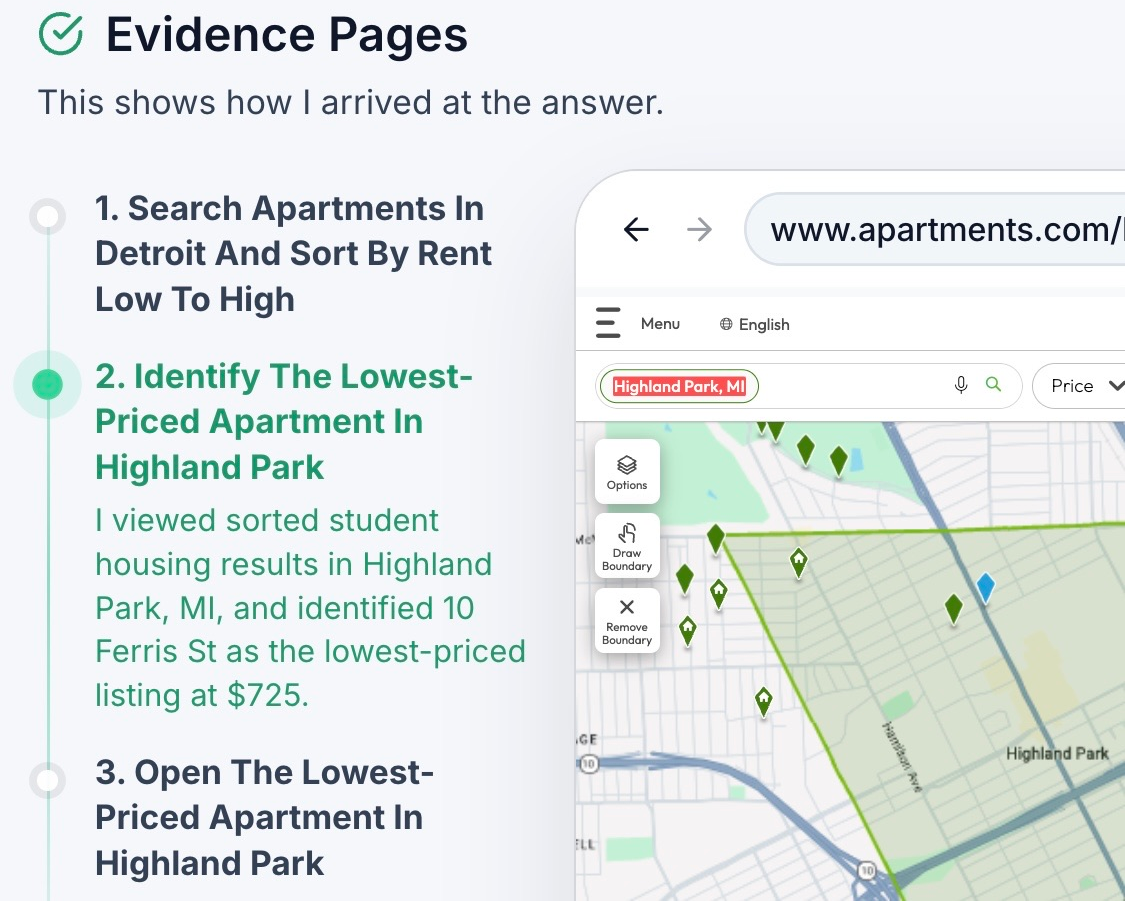
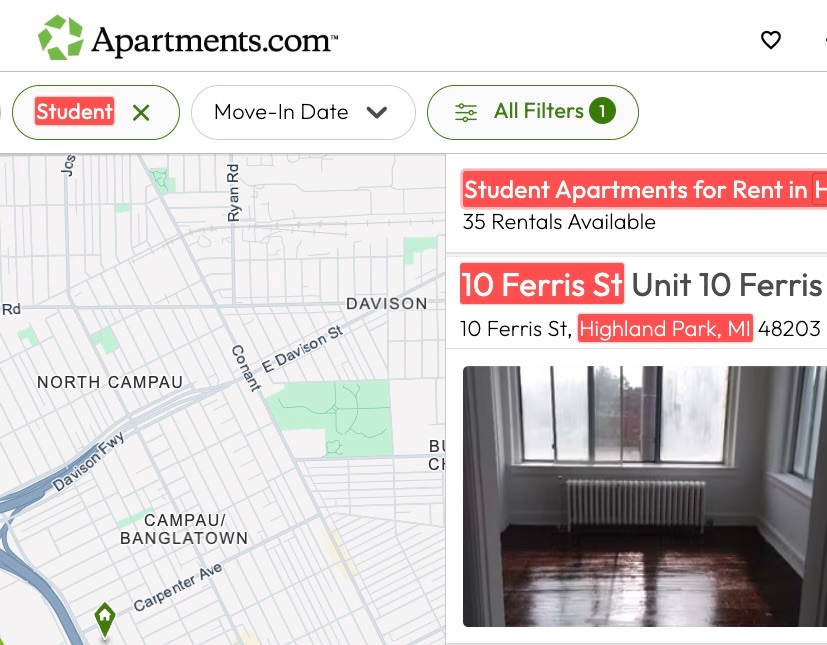
Figure 1: Overview of HANSEL’s extraction and presentation of evidence pages with preserved state and highlighted snippets for interactive verification.
Empirical Trajectory Analysis
Manual annotation of 45 tasks from AssistantBench and Online-Mind2Web benchmarks reveals acute information overload: agents execute an average of 13.16 steps and visit 6.02 pages per task, but only 3.33 steps (25.34%) and 2.18 pages (36.16%) directly contribute to answers. In 62.22% of cases, fewer than three pages suffice for verification. The analysis substantiates that a concise set of evidence pages is sufficient and necessary for efficient human oversight.
HANSEL's extraction module achieves strong numerical results over 45 tasks:
- Evidence Page Extraction F1: 0.861 (Precision: 0.837, Recall: 0.888)
- Snippet-level Precision: 0.887
The system reduces information volume by 61.6%, distilling 271 trajectory pages to 104 evidence pages, enabling users to focus only on salient reasoning steps and evidence.
Interactive Evidence Interface and Reasoning Visualization
HANSEL’s interface embeds evidence pages as live webviews, reconstructing the agent’s navigational context via action replay and highlighting extracted snippets. Two complementary layouts are provided:
- Grid View: Exposes all evidence pages in timestamp order, supporting holistic reasoning verification and rapid error detection.
- Carousel View: Enables sequential inspection with page-level summaries and detailed descriptions.
Key agent actions—such as filter applications, sort changes, and constraint settings—are visually surfaced, allowing users to interact directly with evidence and correct minor agent errors without external navigation.
User Study: Impact on Verification Efficiency and Perceived Usability
A controlled user study with 14 participants demonstrates that HANSEL substantially improves verification efficiency and subjective experience compared to a standard conversational agent interface:
- Task Completion Accuracy: 75.0% (baseline) vs. 82.14% (HANSEL)
- Completion Time (correct answers only): 130.4s (HANSEL) vs. 167.7s (baseline); reduction is statistically significant (p<.001)
- Perceived Effort (Likert scale): Median 2.89 (HANSEL) vs. 4.39 (baseline); significant reduction (p=.012)
- Unique Pages Visited per Task: HANSEL users consistently browsed fewer pages, relying on surfaced evidence rather than reconstructing agent trajectories manually.
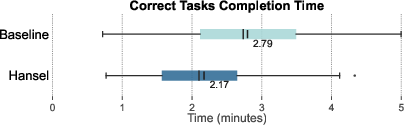
Figure 2: Task completion time per interface, showing HANSEL’s significant reduction in verification duration for correct answers.
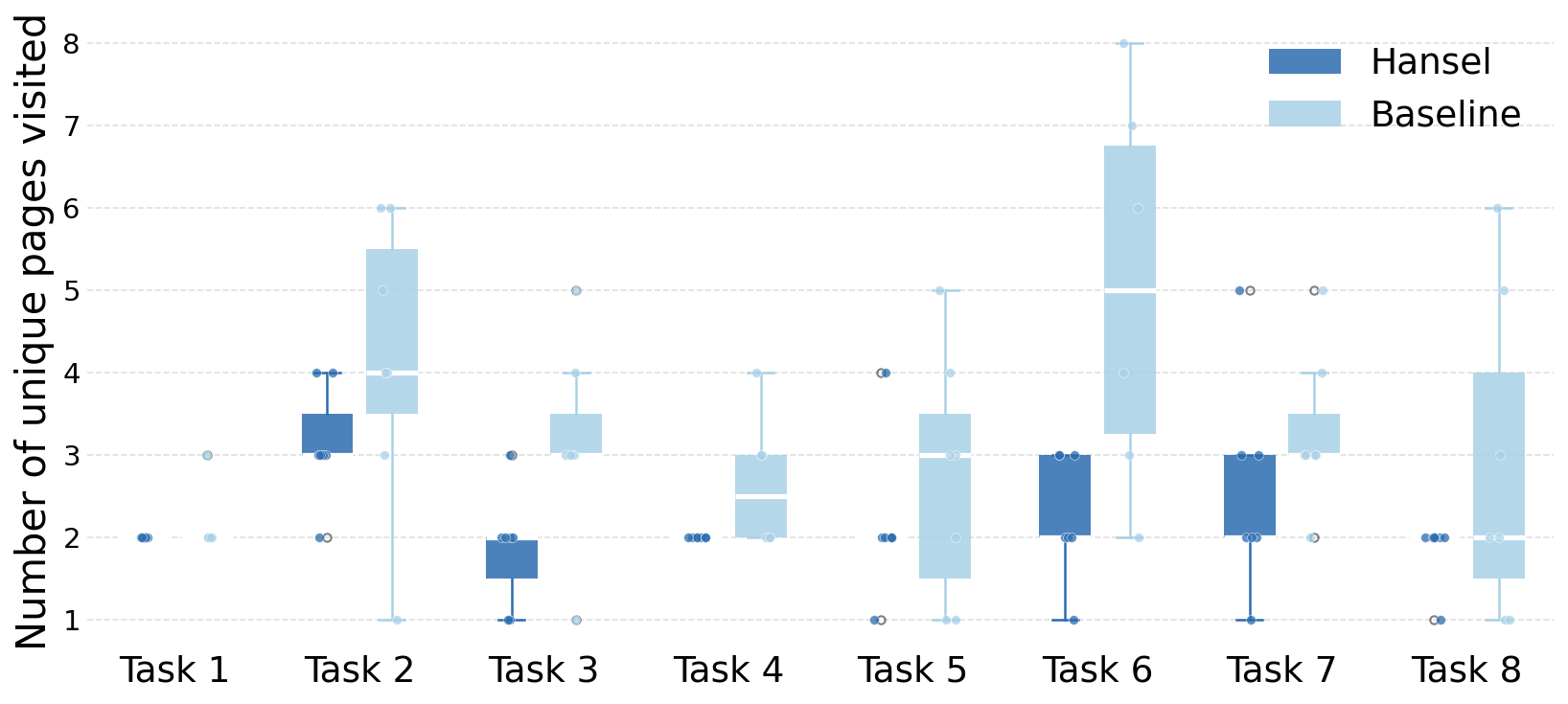
Figure 3: Unique pages visited during tasks, evidencing HANSEL’s reduction in verification navigation overhead.
All participants rated HANSEL higher on usability, verification ease, error identification, understanding agent reasoning, and correction capabilities, and strongly preferred it over the baseline for post-hoc agent oversight.
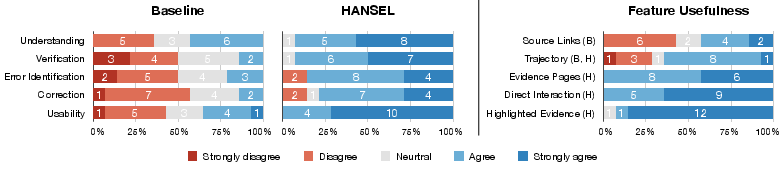
Figure 4: Post-study survey responses comparing HANSEL and the baseline, highlighting marked preference and perceived utility of HANSEL’s interactive features.
Qualitative Findings and Theoretical Implications
The study reveals divergent verification strategies: HANSEL users primarily engage evidence pages directly, using highlights and state reconstruction to identify errors and revise responses efficiently, especially on unfamiliar domains. Baseline users often reconstruct agent workflows externally, increasing effort and risk of missed errors. HANSEL’s interactive evidence presentation shifts the verification paradigm from passive consumption to active engagement, though overreliance on agent-surfaced evidence can induce miscalibrated trust if users do not critically scrutinize highlighted artifacts.
This finding aligns with existing literature on AI-assisted decision-making, demonstrating that evidence presentation substantially shapes user trust orientation and verification rigor. Interactive explanation interfaces, as instantiated in HANSEL, foster more effective oversight and error detection, but require further design to calibrate confidence and encourage critical engagement.
Limitations and Future Directions
HANSEL’s performance is contingent on trajectory quality and alignment with user mental models. Divergent agent strategies may surface suboptimal evidence, hindering verification. The study’s single-session design and platform-specific interaction constraints limit generalizability. Long-term adaptation, scalable deployment with robust page reconstruction, and adaptation for tasks lacking clear ground truths are open research challenges.
Potential future work includes:
- Adaptive prompting to guide critical inspection of evidence, especially for claim types prone to agent overconfidence or error.
- Automated uncertainty flagging and cognitive forcing functions to mitigate overreliance.
- Extension of evidence artifacts beyond web tasks to preference-driven or open-ended scenarios, supporting iterative human-agent collaboration.
Conclusion
HANSEL introduces an interactive evidence extraction and verification paradigm for web agent oversight, operationalizing minimal, actionable evidence from agent trajectories and presenting it as live, navigable, and highlight-augmented views. The system achieves high evidence extraction quality and substantially reduces verification time and effort. These results substantiate that interactive verification interfaces enable more efficient, accurate, and usable agent output verification, motivating adoption and further research into robust, user-centered agent transparency mechanisms for real-world applications of LLM-based web agents (2606.18671).