- The paper introduces GUIDE, which segments complex GUI agent trajectories into subtasks for more interpretable and actionable evaluations.
- GUIDE employs a three-stage pipeline—trajectory segmentation, subtask diagnosis, and overall synthesis—to mitigate context overload and precisely localize errors.
- Empirical results across industrial, web, and mobile benchmarks demonstrate GUIDE’s superior accuracy and robustness compared to traditional evaluation methods.
GUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis
Introduction
The assessment of GUI agent trajectories, particularly in long-horizon and visually complex automation tasks, has emerged as a critical requirement for robust agent development and evaluation. The paper "GUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis" (2604.04399) introduces GUIDE, a diagnostic evaluation framework predicated on the hierarchical decomposition of agent trajectories. GUIDE stands in contrast to monolithic LLM-as-judge paradigms by implementing segmentation of trajectories and multimodal subtask-level diagnosis, yielding interpretable and actionable reports. This approach directly addresses the failures of context overload and lack of interpretability endemic to holistic evaluators and informs both theoretical and practical advances in agentic evaluation.
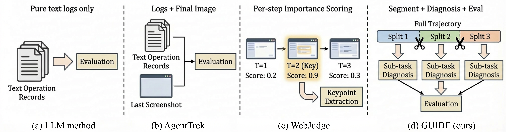
Figure 1: Comparison of evaluation paradigms; GUIDE uniquely decomposes trajectories into subtasks and applies stepwise structured diagnosis with bounded context.
Context and Motivation
Conventional trajectory evaluators, including LLM-based methods (text-only or multimodal), generally operate in one-shot or holistic judgment paradigms. These strategies are susceptible to two failure modes on complex trajectories: (1) context overload as sequence length increases and (2) failure localization opacity. Empirical evidence in the paper shows prior methods such as WebJudge experience severe accuracy decay (up to nearly 18 percentage points) as trajectory length increases beyond 50 steps.
Hierarchical decomposition, widely adopted for agent task planning and working memory, had not been leveraged systematically in evaluation. GUIDE adapts this principle to trajectory evaluation, segmenting the evaluation problem into manageable subunits (subtasks), which provides both context-bounding and explicit failure localization.
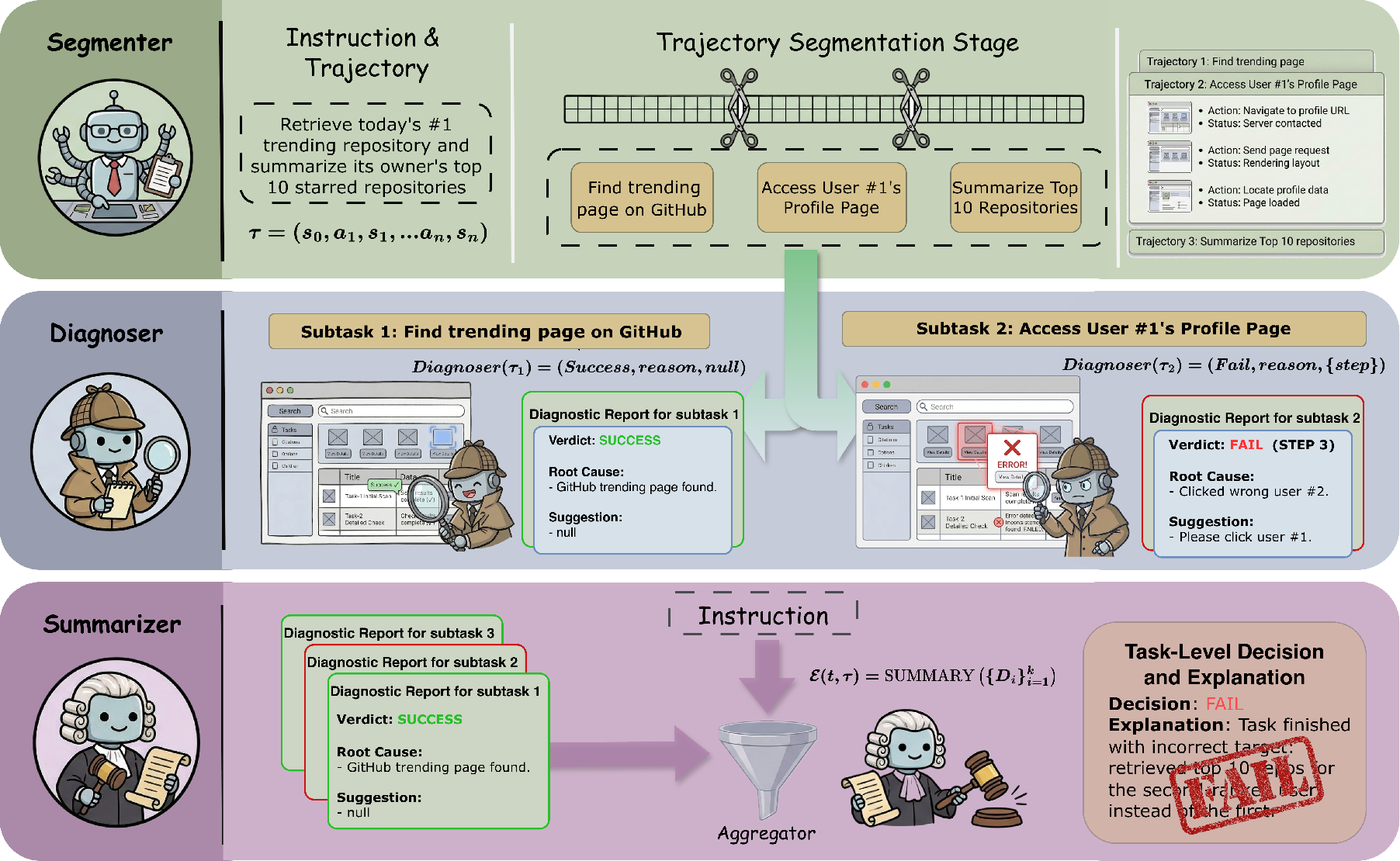
Figure 2: The GUIDE framework, which sequentially segments trajectories, diagnoses subtasks independently, then integrates results into a task-level summary.
Architecture of GUIDE
GUIDE comprises a three-stage hierarchical pipeline:
- Trajectory Segmentation: A LLM segments the action-observation trace into semantically coherent subtask units. The segmentation operates purely on the sequence of actions (textual), eschewing screenshots for efficiency and lower context requirements, and outputs both segment boundaries and a structured description for each subtask.
- Subtask Diagnosis: Each subtask segment is evaluated independently by a vision-LLM, which receives the segment actions, corresponding screenshots, the segment description, and the overall subtask list. The model generates a structured triple (vi,ei,ci) per subtask: a three-level completion verdict (success, partial, fail), an error analysis, and recommendations for correction at the step level. Output is strictly formatted for interpretability and direct developer actionability.
- Overall Summary: Diagnoses across subtasks are synthesized by a final LLM call, yielding a task-level verdict. Instead of a rigid aggregation (e.g., conjunctive criteria), the model reasons holistically, enabling nuanced judgments such as recovery from mid-trajectory errors or cumulative minor deficits.
This modular approach localizes reasoning context to subtask scope, directly enhancing both diagnosis fidelity and robustness against trajectory length growth.
Empirical Validation
GUIDE is validated against five baselines on three challenging benchmarks: an industrial e-commerce dataset (932 trajectories), AGENTREWARDBENCH (1,302 web trajectories across five environments), and AndroidBench (mobile device control).
Key findings include:
- On the industrial e-commerce dataset, GUIDE attains 95.80% accuracy, outperforming the strongest baseline by 5.35 percentage points. Accuracy remains stable (93–98%) across all trajectory length buckets, while competitors experience substantial degradation (WebJudge drops by 17.9 points, AgentTrek by 47.3).
- On AGENTREWARDBENCH, GUIDE achieves 89.21% precision, exceeding all other evaluators and maintaining 100% precision in several settings. Its superiority over the strongest prior method (GPT-4o with accessibility tree input) is noted at +19.4 precision points.
- On AndroidBench, GUIDE achieves 94.9% accuracy, surpassing previous SOTA autonomous evaluators and demonstrating robustness both across agent architectures and in the presence of human demonstration trajectories.
Ablation studies establish that segmentation is the critical driver of GUIDE’s gains: omitting it (evaluating full trajectories in one chunk) reduces accuracy by over 21 points. Diagnostic structure and flexible summary aggregation are both shown to confer measurable additional gains. Segmentation quality validation using both automated (MLLM-based) and manual annotation confirms that over 99% of produced segments are coherent and accurately described.
Analysis of Findings and Implications
GUIDE’s decoupling of diagnosis and summary, as well as its explicit error analysis, enable it to outperform existing methods especially as task complexity grows. The diagnostic outputs provide step-level error localization and recommendations, transforming evaluation from a binary metric into an actionable tool for agent debugging and refinement.
Notably, the framework is training-free, does not require task-specific rule authoring, and is readily deployable in zero-shot settings. This generality is shown to incur occasional failures in tasks with implicit or domain-specific completion norms; these could be mitigated through lightweight prompt adaptation by injecting additional domain knowledge.
Theoretically, GUIDE advances the case for bridging execution-time agent decomposition with analogous evaluation-time strategies. Practically, it establishes a blueprint for interpretable agent benchmarking in complex application domains and provides a foundation for further, potentially automated, feedback-driven agent improvement cycles.
Future Outlook
The GUIDE paradigm is likely to inform future frameworks that further integrate hierarchical evaluation with agentic self-improvement. Opportunities include:
- Augmenting Module 1 with more fine-grained or dynamic segmentation guided by explicit task graphs or causal analysis,
- Leveraging structured diagnostic outputs as supervisory or reward signals for agent self-correction and fine-tuning,
- Extending to interactive, real-time evaluation to support in-situ agent adaptation,
- Further generalization to richer input modalities (e.g., interactive UIs, 3D environments) and open-ended tasks.
Moreover, the modular design of GUIDE naturally admits rapid adaptation and composability, which is of particular relevance for evaluation in continually evolving digital domains.
Conclusion
GUIDE establishes a hierarchical, interpretable, and robust framework for GUI agent evaluation through sequential trajectory segmentation, multimodal subtask diagnosis, and holistic task-level judgment. Its effectiveness is demonstrated via consistent, strong empirical gains and the production of actionable diagnostic outputs. GUIDE’s architecture and demonstrated benefits point toward broader future trends in evaluation methodologies for increasingly sophisticated agent systems.