- The paper presents a trace-level evaluation framework that reveals outcome equivalence does not ensure behavioral mimicry between humans and GUI agents in search applications.
- It demonstrates that while agents achieve comparable task success with fewer actions, their query formulation and navigation patterns differ significantly from human behavior.
- The study highlights the importance of integrating trace-level analysis into evaluation pipelines to prevent bias from agent idiosyncrasies in production search systems.
Trace-Level Evaluation of GUI-Agent and Human Behavior in Production Search Systems
Introduction and Motivation
The proliferation of LLM-driven GUI agents has enabled direct interaction with applications, automating complex workflows and user simulation for system evaluation. Traditional assessment of these agents has focused predominantly on task success, grounding, and completion rates. However, the equivalence of outcome does not ensure behavioral alignment, a gap with substantial implications when such agents are used as user proxies in evaluating or optimizing interactive search systems. This paper proposes, formalizes, and empirically instantiates a trace-level evaluation framework to systematically dissect and contrast the behavioral trajectories of humans and GUI agents in multi-hop, production-grade search applications (2604.07929).
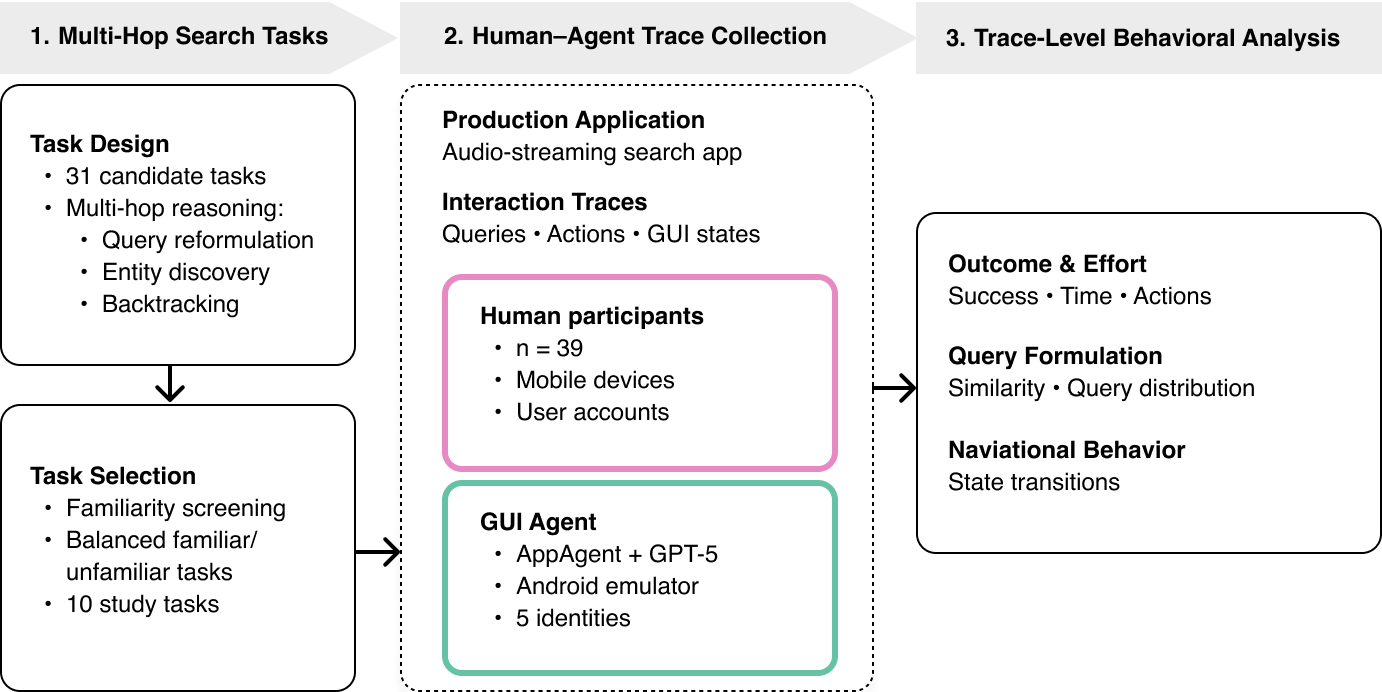
Figure 1: Overview of the trace-level evaluation framework, detailing task design, synchronized trace extraction in a live search application, and multi-faceted behavioral comparison.
Methodological Framework
The framework encompasses three core axes for trace-level analysis:
- Task Outcomes and Effort: Measures include success rates, temporal efficiency, and interaction effort (action counts).
- Query Formulation: Assesses the lexical and distributional similarity of queries issued by agents and humans, including first-query matching and coverage of the full query space.
- Navigation Behavior: Models agent and human navigation as Markovian transition graphs between reduced semantic interface states, allowing quantification of overlap and structural divergence.
The empirical setup utilizes the Spotify mobile application in production, leveraging 39 participants and a state-of-the-art agent (AppAgent + GPT-5) to execute a stratified set of ten multi-hop queries. Tasks span linear reasoning chains and entity bridging, and both intervention and analysis are conducted on real, personalized accounts to maximize ecological validity.
Main Empirical Findings
Task Outcomes and Action Efficiency
Agent and participant cohorts display comparable task success rates (~56% vs 53%); however, agents accomplish this with fewer actions but significantly higher completion times, owing primarily to model inference and emulator overhead rather than behavioral inefficiency. Filtering for strict in-app reasoning compliance further calibrates these comparisons by eliminating shortcut run artifacts.
Both initial and aggregate queries issued by agents are highly aligned with participant queries in lexical and informational space. SequenceMatcher and TF-IDF/cosine measures confirm that agent-participant query similarity closely mirrors participant-participant variability. However, agent queries are notably more consistent across runs than human queries, revealing reduced lexical entropy in the agent's policy.
Distributional analysis indicates that agents' compact query vocabularies cover the dense core of participant queries more efficiently than random participant subsets, though not reaching the diverse coverage of an oracle using only the most frequent participant queries.
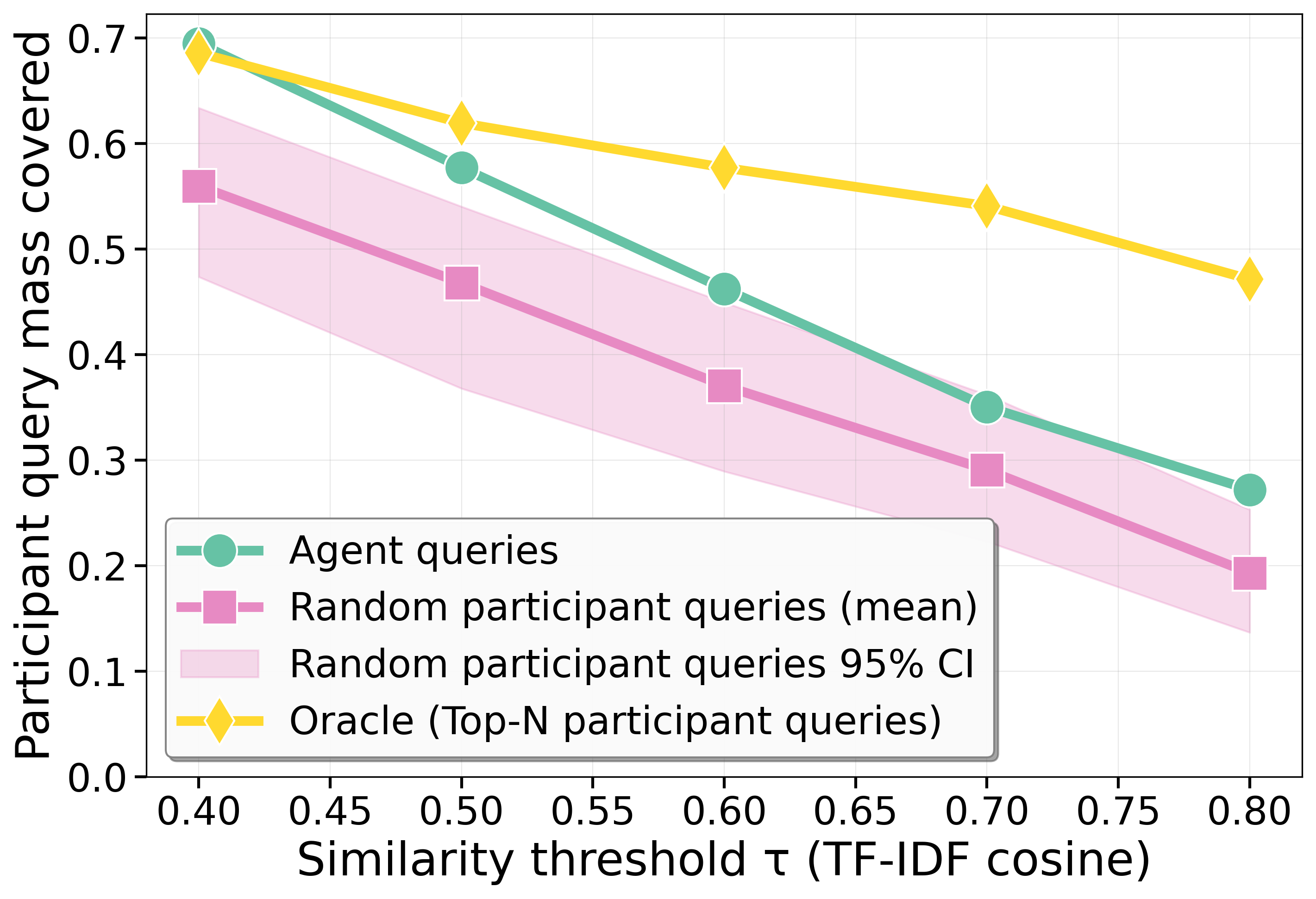
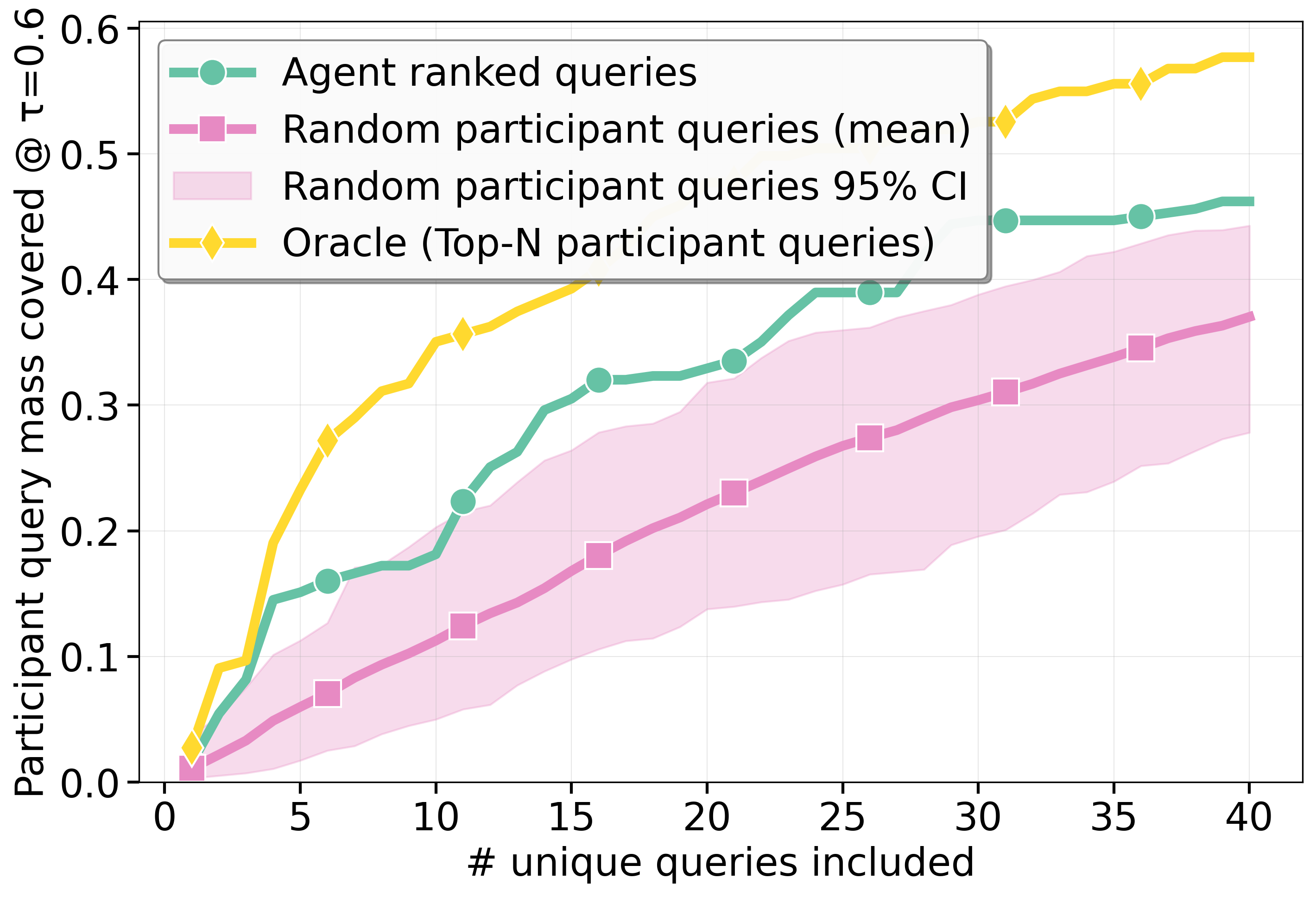
Figure 2: Coverage of agent-generated queries versus participants' query space across varying similarity thresholds, highlighting the efficiency of agent queries relative to both random and oracle baselines.
Navigation Behavior
A pronounced stylistic divergence is observed in navigation. Agents favor search-centric, low-branching strategies with strong self-transition biases on the search state and deterministic, goal-driven transitions. In contrast, human participants employ more content-centric and exploratory trajectories, characterized by higher branching and frequent transitions into ephemeral content pages (e.g., artist, playlist, episode).
Macro-averaged top-k Jaccard overlaps of navigation graphs show agent-human agreement for high-frequency backbone transitions, with greater divergence emerging in the long tail of task-specific, lower-frequency behaviors. Thus, agents and humans traverse overlapping interface skeletons but diverge substantially in exploratory branches.
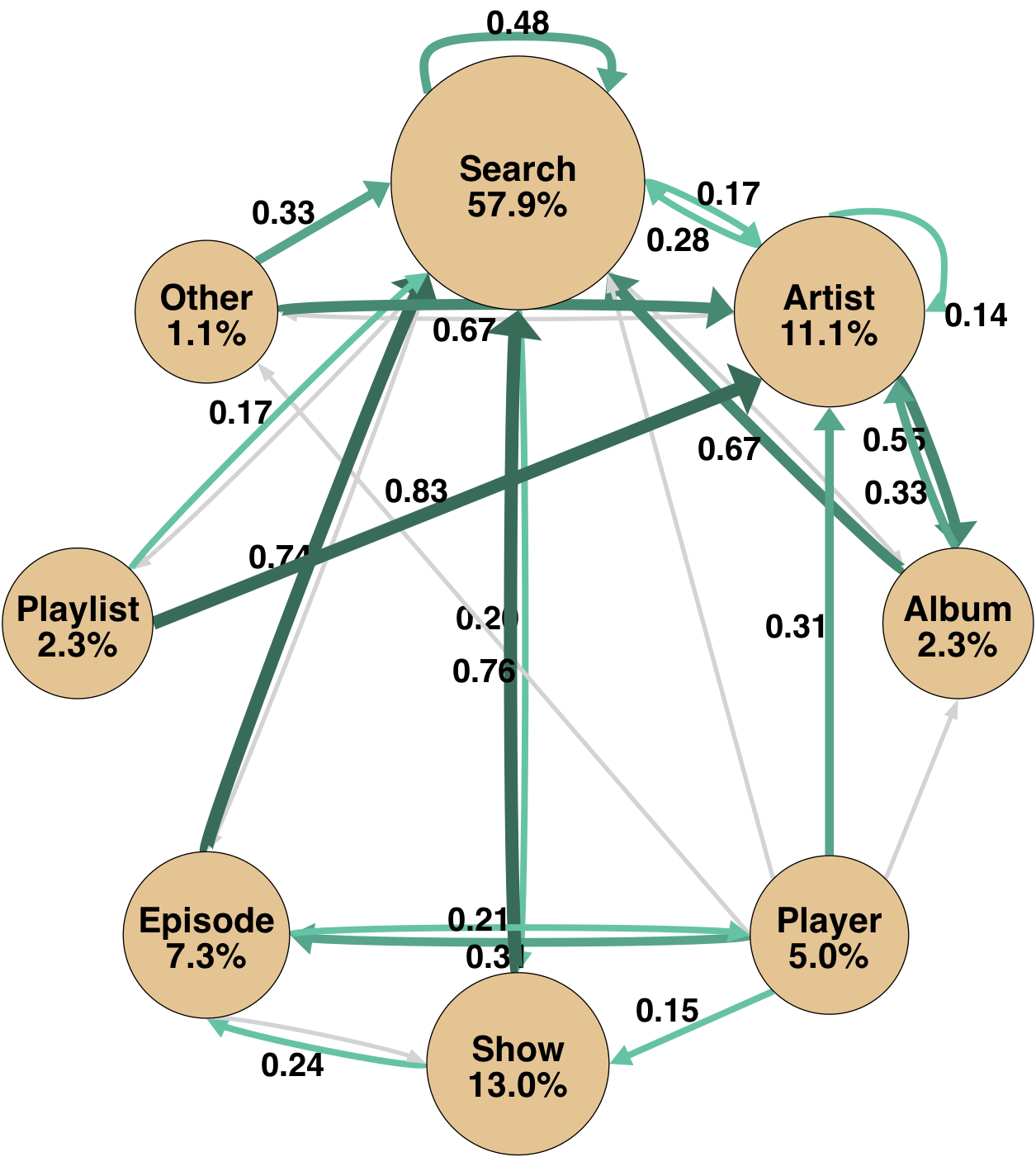
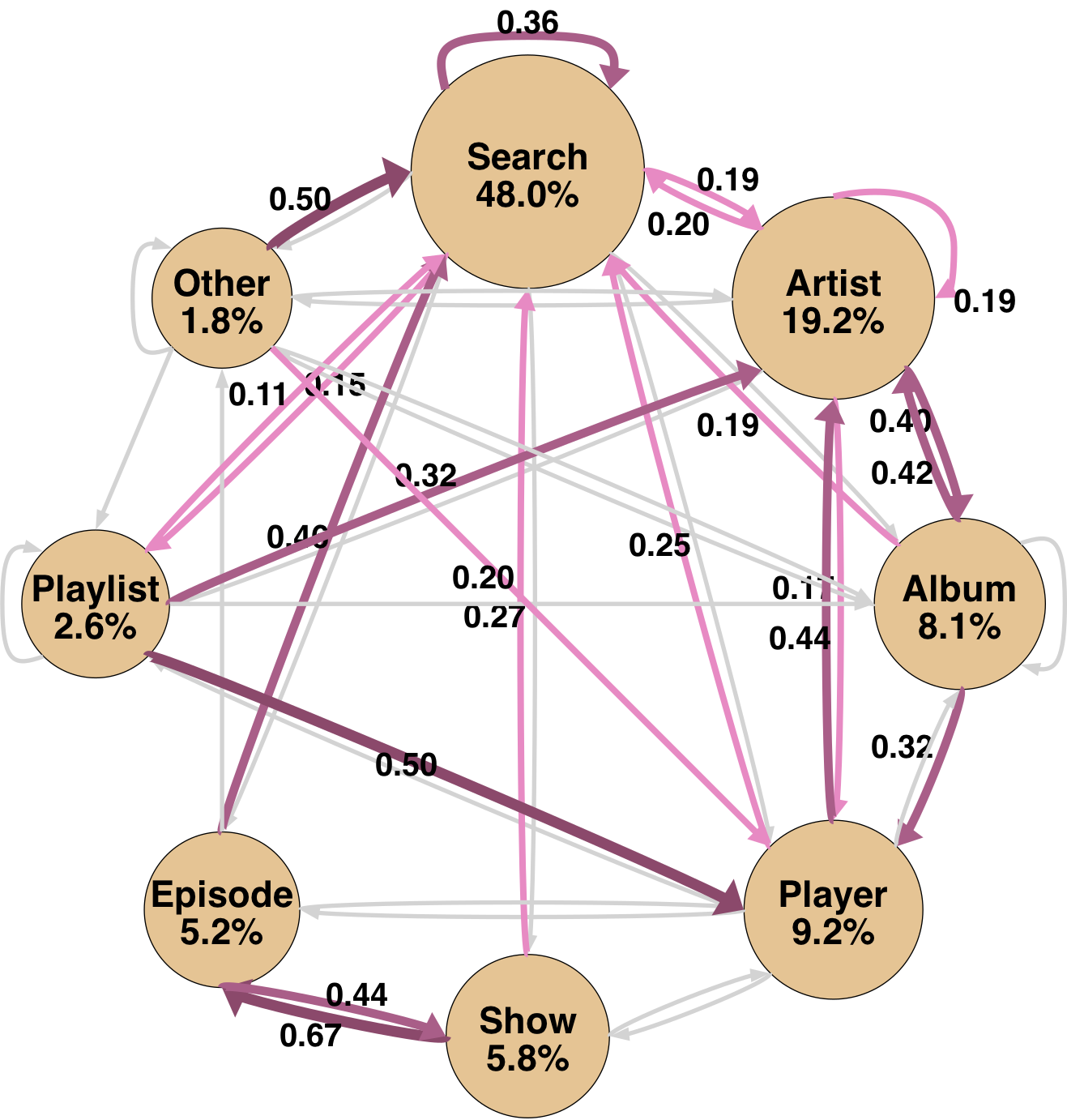
Figure 3: Macro-averaged state transition graphs for agents and human participants, visually emphasizing the differential concentration and branching patterns.
Implications and Practical Lessons
The empirical evidence strongly supports the paper's principal claim: outcome equivalence and query similarity do not guarantee behavioral mimicry between agents and users. This has practical ramifications in settings where agent-driven traces are used for A/B testing, recommendation tuning, or interface design. Reliance on outcome-based evaluation risks systematic drift of system optimization toward agent idiosyncrasies rather than true user needs. Rigorous behavioral auditing using the proposed framework is therefore imperative before deploying agents in proxy-user roles.
Key recommendations include the routine supplementation of success-based metrics with trace-level behavioral diagnostics, systematic auditing for shortcut-induced artifacts, and explicit human-agent alignment validation in production settings.
Limitations and Future Directions
This work is domain- and architecture-specific, though both the framework itself and the core findings are broadly portable across applications and agent paradigms. The study is limited by its focus on a single application domain and one high-capacity agent; replicability across additional domains, interfaces, and agent architectures is a critical avenue for further work.
Future research should target the design of agent training objectives that balance outcome optimality with behavioral fidelity, as well as the development of richer evaluation benchmarks capturing not only what agents achieve but how they achieve it. Integrating explicit human-like exploration incentives into agent policies or reward functions is a promising, open challenge.
Conclusion
This study delivers a rigorous, multi-dimensional framework and empirical baseline for evaluating and understanding the gap between human and GUI-agent behaviors in realistic information-seeking environments. The findings establish that comparable outcomes and language alignment do not imply behavioral isomorphism in system navigation. Trace-level analysis is essential for reliable proxy-use of agents in system evaluation and optimization pipelines, especially as LLM-driven automation becomes pervasive in user-facing applications. The structured framework and empirical insights presented are key stepping stones for future AI methodology, robust evaluation practice, and the design of behaviorally-aligned interactive agents.