- The paper introduces a framework that dissects hallucinations into legally motivated claim types and employs the Risk Direction Index for directional error analysis.
- It utilizes a calibrated multi-agent debate pipeline that targets dominant error modes, achieving a 45% reduction in fabricated clause detections.
- The approach enables risk-aware legal AI deployment by revealing significant disparities in hallucination rates and guiding targeted mitigation strategies.
LegalHalluLens: Typed Hallucination Auditing and Calibrated Multi-Agent Debate for Trustworthy Legal AI
Overview
"LegalHalluLens: Typed Hallucination Auditing and Calibrated Multi-Agent Debate for Trustworthy Legal AI" (2606.18021) introduces a comprehensive auditing and mitigation framework tailored for legal AI contract workflows, targeting the critical problem of unreliable clause extraction and uninformative aggregate hallucination metrics. By dissecting hallucination failures into four legally motivated claim types and introducing the Risk Direction Index (RDI), the paper establishes a more actionable foundation for deployment, procurement, and accountability decisions. Furthermore, it demonstrates that per-category calibration enables a small open model combined with a typed multi-agent debate pipeline to rival commercial API systems at a fraction of the inference cost.
Typed Hallucination Profiles and Aggregation Failure
Aggregate hallucination rates (e.g., ∼52\%) conceal the complexity and practical risks underlying clause extraction for legal contracts. The paper empirically validates that different claim types—numeric, temporal, obligation/entitlement, factual—exhibit consistent and substantial gaps in hallucination rates across diverse LLM architectures:
- Numeric and obligation claims display hallucination rates of 65–74%, while temporal claims are markedly lower at 29–35%.
- The within-model gap between the worst and best categories is 38–41 percentage points, a disparity not visible under aggregate reporting.
This typological consistency means that aggregate metrics are non-actionable for compliance. Models scoring similarly in aggregate can have vastly different reliability on the most legally consequential clauses.
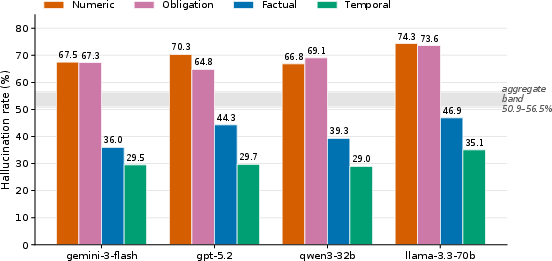
Figure 1: Typed hallucination rates on the 510-contract benchmark reveal substantial per-category disparities, with numeric and obligation failures significantly higher than temporal.
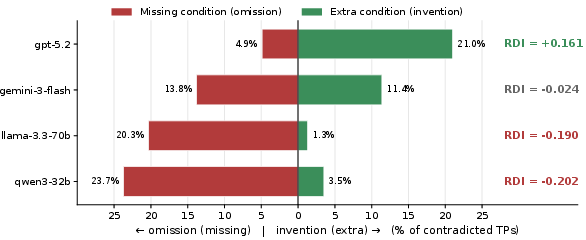
Directional Risk Characterisation with RDI
Beyond the magnitude of hallucinations, the directionality of errors—whether models invent conditions (overstatement) or suppress them (understatement)—is vital for legal deployment. LegalHalluLens operationalises this via the Risk Direction Index (RDI), a signed scalar reflecting net omission vs. invention bias:
Typed Debate Pipeline for Calibrated Mitigation
Building on the diagnostic power of typed profiles and RDI, LegalHalluLens implements a six-role debate pipeline, with Skeptic challenges and gate asymmetries directly calibrated to detected failure modes:
- Typed Skeptic questions target the dominant error mode per claim type, driving focused deliberation.
- Addition/deletion gates enforce conservative policies, especially for high-failure types, based on empirical FAR/FRR ratios.
- Re-extraction is triggered for structural extraction errors, promoting targeted repair over redundant debate.
This approach moves beyond generic debate mitigation (which treats all errors equally), enabling a small open model to match commercial systems' performance on composite score and achieve a 45% reduction in fabricated clause detections.
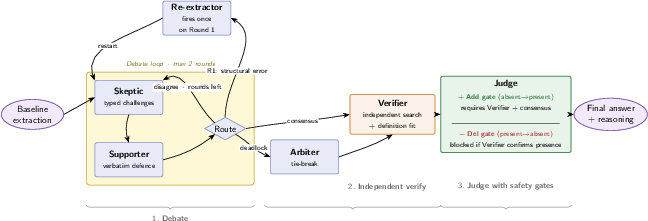
Figure 3: The debate pipeline is structured to focus deliberation and decision making on typed failure modes, with asymmetric gates tailored for risk mitigation.
Per-Type Mitigation and Direction Correction
Calibration of the debate pipeline yields the predicted outcome: gains are concentrated on the highest-failure claim types, and error direction is measurably corrected.
- False positives among obligation and factual claims drop significantly, aligning with baseline profiles, while temporal claims remain essentially unchanged.
- The RDI for obligation clauses is shifted from omission-heavy toward balanced by targeted Skeptic interventions.
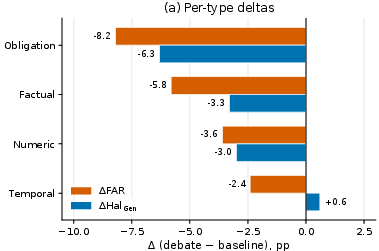
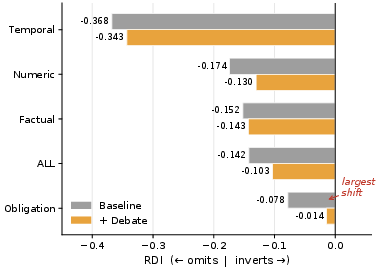
Figure 4: Mitigation gains by claim type show strong concentration on obligation and factual categories, validating typed calibration as an effective specification.
Practical and Theoretical Implications
The diagnostic tools (typed profiles and RDI) equip practitioners to make deployment decisions that reflect real legal exposure, not aggregate metrics. The methodology is transferrable to any oracle-verifiable legal corpus, supporting direction-aware procurement and post-deployment monitoring. The calibrated debate pipeline demonstrates that structured interventions targeting measured failure modes can substantially improve trustworthiness and efficiency, opening avenues for low-cost wildcard models to challenge commercial offerings.
For regulatory and compliance applications, model selection can be guided by specific risk profiles: omission-dominant systems are unsuitable for contractual enforceability, while invention-dominant systems may be deployed for liability-sensitive workflows with robust human review. The framework also lays the groundwork for more nuanced agent designs in AI auditing, moving away from generic multi-agent pipelines toward per-type calibration.
Future Directions
Key extensions include:
- Generalisation studies across jurisdictions and document types to verify the stability of the typed gap and RDI.
- Evaluation in retrieval-augmented setups, where additional failure modes interplay with clause extraction quality.
- Development of human-validated evaluation judges to refine RDI's cardinal interpretation and eliminate judge-dependence noise.
- Minimal-prompt and ablation studies of generic vs. typed calibration debate pipelines.
Broader investigation into how legal AI frameworks can leverage these diagnostics for risk disclosures, governance, and human-in-the-loop review is warranted, especially as deployment scales into adversarial or high-compliance environments.
Conclusion
LegalHalluLens provides robust evidence that aggregate hallucination metrics are inadequate for legal AI deployment decisions, unveiling a consistent and substantial 38–41 percentage point typed gap and directional risk profiles obscured by aggregate reporting. Typed hallucination profiles and RDI are actionable diagnostics, enabling practitioners to calibrate mitigation strategies and agent design. The calibrated debate pipeline demonstrates practical gains: a 45% reduction in fabricated clause detections and strong concentration of improvements on the claim types where risk is highest. For trustworthy legal AI, evaluation and mitigation must be typologically and directionally specific.