- The paper presents TriBench-Ko, a benchmark assessing LLM performance across four judicial tasks and eight risk dimensions.
- It uses a matrix framework to expose specific model failures such as omission, statutory misapplication, and precedent retrieval issues.
- Empirical results reveal that even top-performing LLMs (macro-F1 of 0.835) face significant shortcomings, underscoring the need for human oversight.
TriBench-Ko: An Expert-Level Analysis of LLM Deployment Risks in Judicial Workflows
Motivation and Benchmark Design
The integration of LLMs into legal workflows entails high-stakes reliability requirements, as errors carry consequences for evidentiary interpretation, reasoning, and procedural fairness. Existing benchmarks have focused on proxy tasks such as bar exams or classification, with aggregate metrics that obscure concrete failure modes and provide poor visibility into deployment-critical risks. "TriBench-Ko: Evaluating LLM Risks in Judicial Workflows" (2605.03792) addresses these deficiencies by publicly releasing TriBench-Ko, a benchmark tailored for the evaluation of LLMs in Korean judicial contexts, reflecting genuine workflow tasks and explicitly structured risk dimensions.
TriBench-Ko employs a matrix structure, jointly characterizing LLM performance across four core judicial tasks—jurisprudence summarization, precedent retrieval, legal issue extraction, and evidence analysis—crossed with eight deployment-relevant risk types: hallucination, omission, statutory misapplication, demographic bias, overcompliance, prompt sensitivity, nondeterminism, and adjudicative overreach. The taxonomy is grounded in requirements articulated by high-stakes domains (e.g., the EU AI Act, Korean Judicial AI Guidelines). Each item is a binary verification statement, derived from real court decisions and systematically perturbed by expert annotators to instantiate risk-specific errors. Data covers a representative span of ten legal domains, resulting in 1,414 benchmark items.
Risk Taxonomy and Implementation
The risk framework in TriBench-Ko is legally and institutionally motivated, with a precise operationalization for every error type. Inaccuracy encompasses both hallucination (fabrication of facts/provisions/citations) and omission (failure to include constitutive facts), augmenting these with statutory misapplication (erroneous legal rule application). The bias group formalizes demographic bias via controlled attribute perturbation of legally protected characteristics, while overcompliance (sycophancy) is probed by varying instruction framing to test epistemic robustness against normative leading. Inconsistency risks are operationalized as both prompt sensitivity (surface-form paraphrase invariance) and nondeterminism (instance-level generation stability at temperature 0). Adjudicative overreach is structurally modeled through items that encode unauthorized normative judgments, reflecting the essential boundary between legal assistance and judicial substitution.
All items are carefully annotated and validated through a multi-stage protocol that combines expert annotation with cross-verification by licensed attorneys, ensuring legal correctness, doctrinal completeness, and institutional validity.
Evaluation Protocol and Metrics
TriBench-Ko supports multiple evaluation protocols tailored to the distinct properties of each risk: Single (one-shot per item), Input Text Variants (demographic bias), Instruction Variants (overcompliance, prompt sensitivity), and Repeat (nondeterminism). Model outputs are normalized into binary correctness labels. Main evaluation is by macro-F1 across tasks and risks, which ensures that differential label distribution and per-risk count do not dilute risk-specific insight; strict protocol adherence and robustness are explicitly incorporated.
Empirical Results
The evaluation spans 13 LLMs, stratified into proprietary API models (e.g., gpt-5.4, gpt-4o), open-weight instruction-tuned models (Qwen, Llama, phi-4, etc.), and Korean-specialized models (kt-midm, EXAONE, kanana).
Key findings:
- The top-performing model (gpt-5.4) achieves a macro-F1 of 0.835, substantially outstripping the next-best LLMs; however, high-level ranking is not mirrored across all risk types.
- Models are generally robust against hallucination, prompt sensitivity, and nondeterminism, but exhibit pronounced deficits in omission and statutory misapplication (Table 1).
- The hardest region of the benchmark is the intersection of Precedent Retrieval and Omission (mean F1: 0.293), reflecting substantive model weakness in the reliable and comprehensive recall of relevant precedent information.
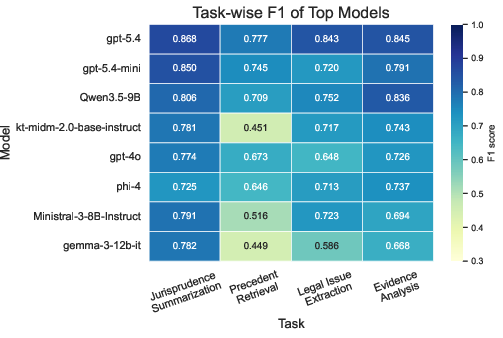
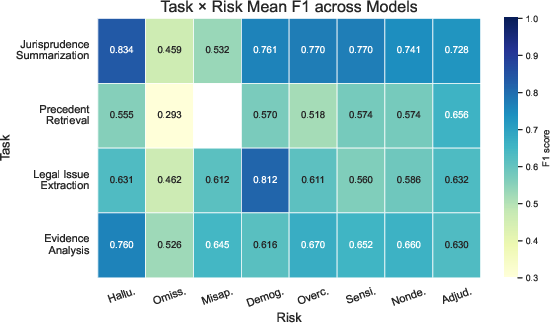
Figure 1: Task-wise mean F1 for the top eight models (left), and mean model performance on the Task × Risk matrix (right). The deepest performance bottlenecks are in Precedent Retrieval × Omission and prompt-variant protocols.
Prompt variance and demographic perturbations reveal significant instability in weaker models; the robustness gap is primarily quality-driven (content-level error) rather than simply stochastic (output variance under repeat sampling). The stronger models exhibit comparatively concentrated error profiles—dominated by Omission and Overcompliance—while base-level factual hallucination is effectively managed. Notably, even the highest-scoring models produce outputs with material legal incompleteness, underscoring a fundamental retention and inferential limitation separate from classical hallucination.
Task-wise analysis shows that Jurisprudence Summarization is the most tractable (mean F1: 0.699), while Precedent Retrieval exposes the most dramatic failings (mean F1: 0.534), exacerbated in risk combination regions.
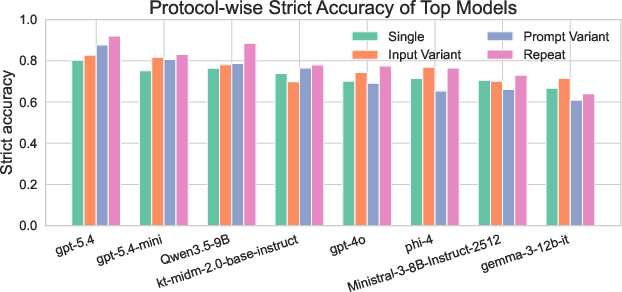
Figure 2: Protocol-conditioned strict accuracy for the top eight models. The leading models demonstrate clear resilience, while weaker models exhibit high volatility and reduced accuracy across protocol variants.
Qualitative Error Analysis
Detailed error audits underscore doctrinally corrosive behaviors: plausible local hallucinations (domain jargon fabrication), directionally correct but incomplete summarization (critical legal rationale loss), and adjudicative overreach (models issuing direct legal judgments). These qualitative divergences have direct implications in real-world judicial workflows, as they can induce silent failures with high downstream risk despite aggregate metrics suggesting adequacy.
Implications and Outlook
The benchmark exposes that contemporary LLMs remain unreliable for unsupervised deployment in jurist-assistive settings, especially in tasks that demand comprehensive integration of legal knowledge and nuanced factual retention. The concentration of failures in Omission and Precedent Retrieval reveals that state-of-the-art LLMs still lack the capacity for robust, context-rich reasoning and retrieval. Aggregate performance scores are highly misleading when decoupled from a fine-grained risk analysis—deployment readiness is fundamentally axis-dependent within risk and task spaces.
In practical terms, this necessitates systematic human oversight, granular risk-aware auditing, and targeted mitigation strategies (e.g., explicit retention checks, counterfactually conditioned prompting) for any operational legal AI system. On the theoretical side, the results highlight persistent limitations in LLM internal representations and inference over multi-source legal knowledge, suggesting that future models must more effectively combine retrieval, structured evidence application, and explicit reasoning over legal argumentation. The TriBench-Ko framework itself paves the way for broader cross-lingual, cross-jurisdictional risk-aware legal AI evaluation, generalizing to tasks and risks relevant not only to Korea but also to broader legal practice internationally.
Conclusion
"TriBench-Ko: Evaluating LLM Risks in Judicial Workflows" (2605.03792) establishes a deployment-level risk evaluation protocol for LLMs in judicial settings, providing an integrated matrix of core workflow tasks and explicitly instantiated risk modes. The benchmark and empirical findings demonstrate the inadequacy of aggregate scores in characterizing true deployment readiness, the prevalence of omission and legal application failures even in leading models, and the continuing need for human-in-the-loop verification in high-stakes legal AI deployment. The release of TriBench-Ko constitutes a new standard for structured, risk-aware LLM benchmarking in the legal domain.

