- The paper introduces a formal taxonomy with 83 hallucination types in optimization modeling across objectives, variables, constraints, and implementation.
- The paper leverages a multi-agent system, OptArgus, to dynamically route artifacts through specialized auditors, enhancing structured error localization.
- The paper demonstrates significant performance improvements over baseline models, notably reducing false positives and improving localization metrics on multiple benchmarks.
Taxonomy-Grounded Hallucination Detection in LLM-Based Optimization Modeling: An Analysis of OptArgus
Motivation and Problem Space
The increasing adoption of LLMs for translating natural-language optimization problems into symbolic models and solver code presents a fundamental challenge: numeric agreement on objective values does not guarantee that the underlying optimization problem semantics are faithfully captured. Artifacts may appear numerically correct yet still misrepresent the decision structure, leading to what the authors term "optimization-modeling hallucinations." These span erroneous objectives, variable domains, constraints, or code implementations—failures that can critically undermine trustworthy automation for decision-support systems in sensitive domains.
To systematically address this problem, the authors introduce optimization-modeling hallucination detection as a formal structured consistency auditing task over the triplet (P,M,S), where P is the natural-language problem, M the symbolic model, and S the solver implementation. They develop an expert-driven taxonomy covering hallucination types in objectives, variables, constraints, and implementation, operationalizing the detection task as fine-grained structured prediction over taxonomy-grounded element labels.
Hallucination Taxonomy and Empirical Artifacts
A hallmark of this work is the first fine-grained, operational taxonomy of optimization-modeling hallucinations. The taxonomy covers 83 specific failure types partitioned into objective, variable, constraint, and implementation families, each mapped to subcategories (e.g., direction errors, domain relaxations, aggregation mistakes, code misregistration).
Figure 1, referenced in the text, visually demonstrates how seemingly minor symbolic or code deviations yield structurally distinct models—a reversed objective direction, incorrectly relaxed variable domains, aggregation errors, or implementation omissions—that may persist even under objective-value agreement.
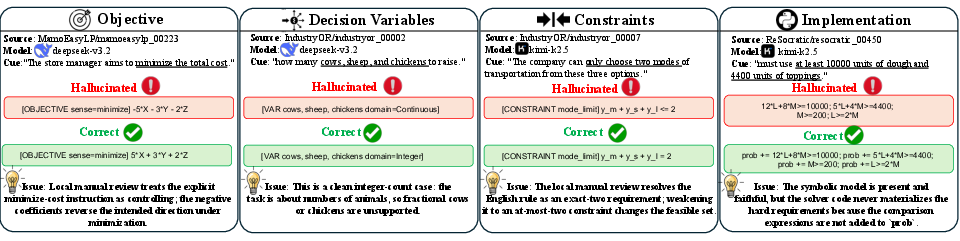
Figure 1: Representative optimization-modeling hallucinations, contrasting hallucinated and corrected fragments across objectives, variables, constraints, and implementation.
The authors further present a compact "fishbone" visualization of the taxonomy, summarizing the organization of failure modes for systematic study and detector specialization.
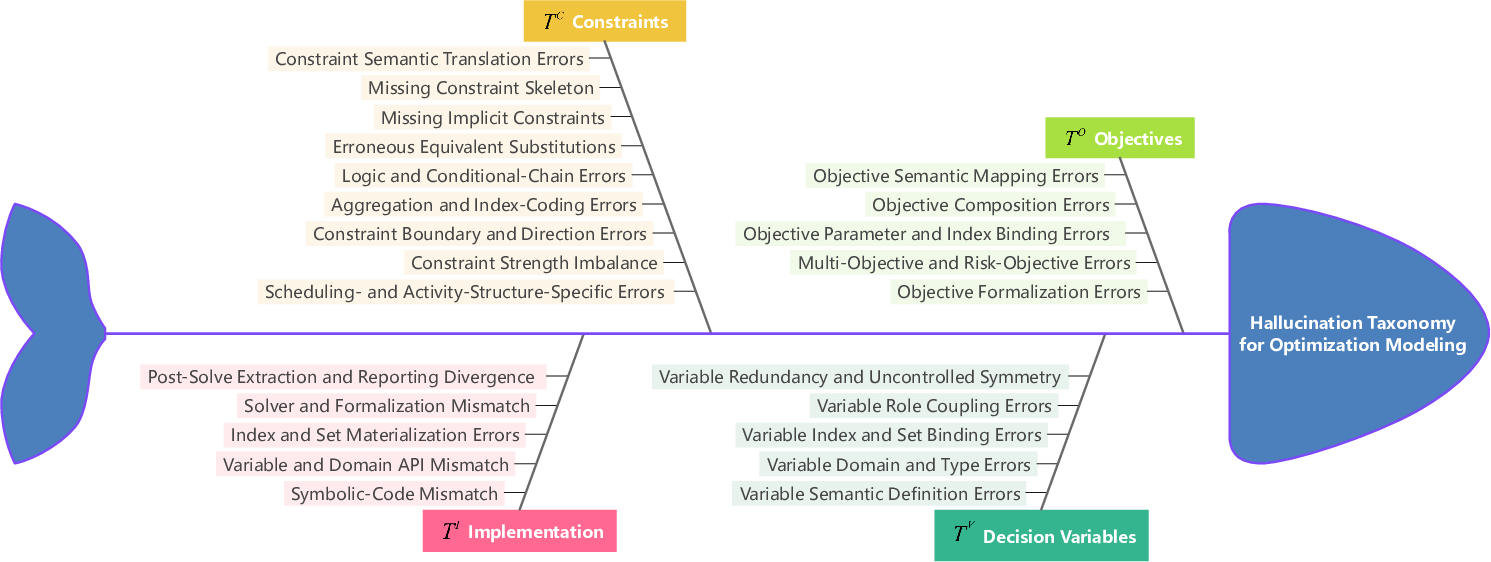
Figure 2: OR-expert-built optimization-modeling hallucination taxonomy, partitioned into objective, variable, constraint, and implementation families.
System Architecture: OptArgus
The core methodological innovation is OptArgus, a multi-agent hallucination detector. OptArgus routes (P,M,S) artifacts through a conductor to four dedicated specialists (objective, variable, constraint, implementation), each applying role-specific verification criteria derived from the taxonomy. Findings are coordinated, consolidated, and reranked before generating an auditable report.
This multi-agent system is architected for selective, non-exhaustive routing: the conductor identifies the branches most relevant for each instance, initiates targeted audits, and invokes cross-agent review only when necessary. Specialist outputs are mapped to a canonical state representation comprising semantic schemas, symbolic and implementation graphs, dependencies, and a blackboard for accumulating evidence and execution state.

Figure 3: OptArgus workflow, from conductor triage to specialist auditing, cross-agent critique, finding consolidation, and auditable report visualization.
The system ensures the separation of symbolic hallucinations (semantic translation failures) from implementation hallucinations (symbolic vs. code misalignment), and supports modular abstention—an essential property for retaining trustworthiness in automated model review.
Benchmark Suite, Metrics, and Baseline
To rigorously evaluate both clean-case restraint and error localization, the authors introduce a three-part benchmark suite:
- Clean Benchmark: 484 OR-expert-validated artifacts ensuring ground-truth correctness for measuring restraint and false-alarm rate.
- Injected Benchmark: 1,266 controlled, single-error artifacts each designed to instantiate a unique taxonomy item for precise localization.
- Natural Benchmark: 6,292 real LLM-generated artifacts across a diverse model panel, fully annotated by OR experts for major-category and artifact-level hallucinations.
A monolithic single-agent detector with access to the same taxonomy, artifact triplet, and output schema serves as the primary baseline for attributional comparison. The evaluation protocol reports metrics for clean-case empty report rate, mean findings, Top-1 localization at multiple taxonomy levels (major category, subcategory, specific type), and artifact- and major-category-level F1 scores.
Experimental Analysis and Numerical Results
OptArgus demonstrates significant improvements over the single-agent baseline across all benchmarks:
- On the clean benchmark, OptArgus achieves an empty-report rate of 0.853 (vs. 0.483 for the baseline), showing a strong reduction in false alarms, and reduces mean false-positive findings to 0.159 (vs. 0.556).
- On the injected benchmark, OptArgus shows stronger localization on single-error artifacts: Top-1 major-category hit of 0.767 (+0.044 over baseline), subcategory hit of 0.473 (+0.042), and specific-type hit of 0.403 (+0.064), while making fewer extraneous findings (1.224 vs. 2.151).
- On the natural benchmark, OptArgus improves artifact-level Halluc-F1 (0.617 vs. 0.521), with major gains in Variable-F1 (0.495 vs. 0.328) and Objective-F1 (0.541 vs. 0.404), as well as summary metrics (Macro-F1 and Micro-F1 improved by 0.13 and 0.107, respectively).
Ablation studies show that both specialist calibration, dynamic routing rescue, and deterministic consolidation are essential for these gains; exhaustive fan-out offers modest further improvement at significant computational cost. Backbone sensitivity analysis demonstrates consistent performance improvements over multiple LLM backbones.
Implications, Limitations, and Prospects
Practically, the results establish that modular, taxonomy-grounded multi-agent auditing is a scalable and interpretable method for reliability assurance in LLM-based optimization modeling. Theoretical implications include:
- Optimization-modeling correctness cannot be reduced to instance-level objective agreement. Structural error detection must operate at the level of symbolic-model and code alignment with problem semantics.
- The error space is inherently modular and structured, supporting the use of modular detection strategies and fine-grained taxonomies.
- Modular, specialist-driven auditing with explicit abstention and deterministic consolidation outperforms monolithic or naive multi-agent approaches in both calibration and localization, across both controlled and real-world error distributions.
Future work could extend this principled detection framework to:
- Diagnosis–repair–verification loops integrating detection and artifact correction.
- Scalability to larger, more complex industrial modeling benchmarks.
- Integration with agentic LLM systems for interactive, explainable diagnosis and verification.
- Richer natural-distribution error annotation at deeper taxonomy levels.
The authors note limitations chiefly in benchmark scale, the cost of expert annotation, recall at deeper taxonomy levels for natural artifacts, and in fully automating hallucination repair.
Conclusion
OptArgus represents a significant advancement in the rigorous auditing of LLM-generated optimization models, moving the field beyond reliance on superficial objective matching. Its taxonomy-driven, multi-agent architecture yields quantifiable improvements in clean-case restraint, precise localization, and natural-distribution detection. This structured approach sets a new template for reliability in automated optimization modeling and lays the groundwork for the next generation of verifiable, trustworthy AI-driven decision-support systems.

