- The paper introduces PROClaim, a courtroom-inspired multi-agent framework that employs progressive RAG, role-switching, and self-reflection to verify controversial claims.
- It achieves an 81.7% accuracy on the Check-COVID benchmark, marking a 10.0 pp improvement by dynamically integrating adversarial evidence and heterogeneous adjudication.
- The methodology mitigates issues like hallucination and overconfidence by ensuring auditable, robust verification through structured debates and iterative evidence curation.
Courtroom-Style Multi-Agent Deliberation with Progressive RAG and Role-Switching for Robust Controversial Claim Verification
Introduction
This work proposes PROClaim, a structured, courtroom-inspired multi-agent deliberation framework for zero-shot claim verification using LLMs. It is specifically designed to overcome reliability failures in high-stakes fact-checking, particularly those attributed to hallucination, shallow reasoning, and overconfidence. The central innovations include explicit legal roles, progressive retrieval-augmented generation (P-RAG), structured evidence negotiation, multi-level self-reflection, heterogeneous judicial panels, and a role-switching diagnostic to test evidence-grounded inference. Empirical results on the Check-COVID benchmark show a substantial accuracy improvement (81.7%, +10.0 pp over baselines) and ablation demonstrates the efficacy of individual components.
Methodology
PROClaim recasts claim verification as an adversarial legal process, allocating roles (Plaintiff, Defense, Judges, Critics, Expert Witnesses) to distinct LLMs. The pipeline is initialized by decomposing a claim into atomic premises for premise-specific targeted retrieval, using a dense embedding FAISS index of COVID-19 PubMed abstracts and premise-adaptive query vectors.
The evidence pool is constructed via a dual-stage process. Agents (counsels) issue stance-conditioned queries, targeting both supporting and refuting evidence, thereby precluding topical echo chambers endemic to top-K RAG. Evidence is further filtered by stringent admissibility metrics, combining relevance and source credibility (mirroring Daubert Standard principles).
The core engine is Progressive RAG (P-RAG), an iterative mechanism admitting only semantically novel evidence (novelty ≥0.20) and refining queries using local debate context, explicit self-identified evidence gaps, and meta-level discovery needs surfaced by self-reflection. Stopping criteria combine novelty saturation, reflection stability, critic resolution, and judicial signals. This dynamic drives broad and deep evidence curation across rounds.
Each debate round includes evidence discovery (via P-RAG), structured arguments, on-demand expert testimony, self-reflection, and independent critic evaluation. Self-reflection is quantitatively scored for logic, novelty, and rebuttal engagement and drives adaptive debate termination and evidence queries. Role-switching is deployed post hoc, swapping adversarial roles and re-running the full debate to probe consistency; the stability and contradiction profile informs a final consistency-weighted verdict.
Judgment is rendered by a panel of three independent, heterogeneous LLMs, voting after a six-stage evaluation (evidence, argument validity, scientific reliability, PRAG process, deliberation quality, and final verdict). Confidence is calculated via a calibrated consensus-plus-quality weighting, further adjusted by self-reflection and role-switch metrics, with robust calibration (ECE = 0.034).
Results
Main Pipeline Performance
The PROClaim framework achieves a majority-vote accuracy of 81.7% on Check-COVID with rapid convergence and robust reliability (mean panel κ=0.468). The oracle performance ceiling (best-of-three judges) is 95.8%, showing the framework's structural resolution capacity. Inter-judge disagreement rates (51.1%) confirm genuine diversity in panel behavior and error-correction via aggregation.
Ablation isolates the principal driver of performance gain as P-RAG (+7.5 pp), underscoring the importance of iterative, novelty-filtered retrieval for comprehensive evidentiary coverage. Role-switching (+4.2 pp), multi-judge panels (+3.3 pp), and self-reflection (+0.8 pp) further contribute, with self-reflection primarily acting as a cost-control and debate-efficiency lever.
Notably, removing P-RAG increases inter-judge agreement (from κ=0.468 to $0.599$) while reducing accuracy by 7.5 pp, exposing the epistemic bubble effect: confident, but incorrect, convergence in the absence of dynamic, adversarial evidence influx.
Debate Dynamics
Dynamic evidence evolution and argumentation are empirically characterized. Debates most frequently terminate by reflection plateau or judicial signals, with novelty saturation rarely triggering early cessation.
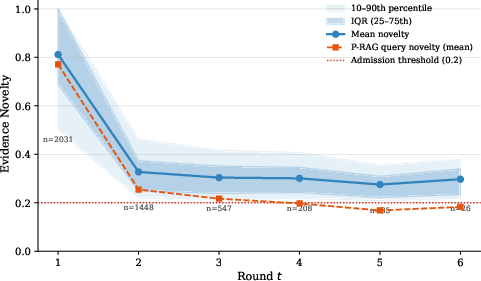
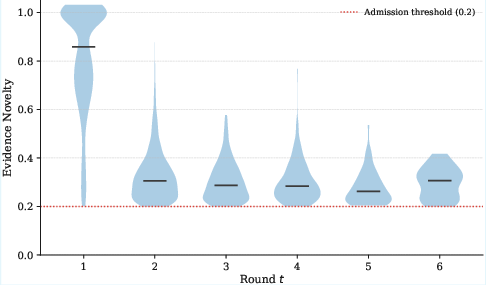
Figure 1: Novelty decay across rounds, with evidential acquisition flattening near the 0.20 threshold after round 4, denoting retrieval saturation and efficient corpus utilization.
Reflection trajectories display sharp plateauing in correct predictions but high volatility in incorrect predictions, serving as an emergent behavioral reliability marker. Rounds-to-consensus metric confirms a structural negativity bias: REFUTE claims converge significantly faster, with panel judges over-producing negative (refute, inconclusive) verdicts, mirroring their training-induced caution.
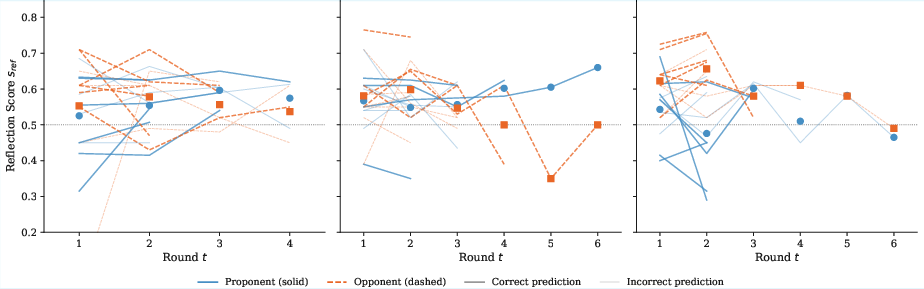
Figure 2: Reflection score trajectories stratified by debate resolution type, highlighting increased instability and extended deliberation in incorrect or highly contested judgments.
Comparison to Baselines
While single-pass LLMs with static RAG (e.g., GPT-5-mini) can approach high accuracy (85.8%), they do not exhibit deliberative traceability or adversarial robustness. Standard multi-agent debate baselines without structural protocol or P-RAG score considerably lower (71.7%). The principal value of the courtroom model is in adversarial resilience: variance in judge trajectories acts as a logic-level "lie detector"—incapable of being replicated by single-shot, instruction-anchored models.
Cost, Generalization, and Adjudicatory Diversity
PROClaim is approximately 11× more token-intensive than minimalist debates but maintains a strict cost–accuracy Pareto front. The pipeline generalizes to non-domain-specific datasets (FEVEROUS: 78.3%, HealthVer: 72.0%) with minimal accuracy loss, affirming the architecture’s domain independence.
Panel diversity analysis shows error profiles of judges are highly complementary (over-refutation/abstention), justifying the necessity for heterogeneous panels. The system structurally suppresses sycophancy—agents have high role-play consistency even under role-switching and sustain adversarial friction with minimal concession rates and persistent reflection deltas well above staleness thresholds.
Theoretical and Practical Implications
PROClaim reconceptualizes claim verification as a process-dependent task, where reliability is a product of system-level adversarial friction, evidence evolution, and cross-agent diversity, not just model-level score maximization. The critical finding is that true deliberative robustness is a function of continual integration of adversarially surfaced evidence, repeated trajectory introspection, and heterogeneous, multi-level evaluation. The pipeline’s outputs are inherently auditable, providing not only verdicts but also structured meta-evidence (deliberative logs, reflection histories) necessary for post-hoc human review and regulatory compliance.
This approach is highly extensible. Future research directions include scaling to live corpora, expanding to additional regulated domains (scientific integrity, biomedical guidelines, legal compliance), and architectural cost downsizing through early-exit mechanisms and model distillation. Ultimately, adoption of such structured, deliberative LLM frameworks is a necessary prerequisite for reliable, accountable deployment of LLMs in real-world high-stakes AI systems.
Conclusion
PROClaim delivers a rigorously structured, adversarial, and auditable framework for controversial claim verification, empirically outperforming existing multi-agent and single-shot systems. Its core contribution is the unified orchestration of progressive retrieval, role-specialization, dynamic self-reflection, role-switching, and heterogeneous adjudication, collectively mitigating the epistemic bubble and reducing systematic biases. These methodological advances underscore the necessity of moving beyond accuracy-focused, black-box LLM deployment toward transparent, process-driven AI systems, with clear theoretical and societal impact for reliable, high-stakes automated reasoning.