- The paper introduces a 22B-parameter autoregressive model that achieves real-time audio-visual streaming for interactive social video synthesis.
- It employs dual data pipelines integrating synthetic curricula with real social media videos, featuring rigorous filtering for robust cross-modal alignment.
- The model incorporates agentic planning and buffering modules to decouple generation from high-level control, ensuring coherent, sub-second output.
MaineCoon: Technical Advances Toward Real-Time Audio-Visual Social World Modeling
Introduction and Motivation
MaineCoon (2606.17800) introduces a rigorously engineered, 22B-parameter, real-time autoregressive audio-visual world model, optimized for social video generation and interaction at scale. Unlike preceding world models largely constrained to passive video synthesis or physically grounded domains, MaineCoon’s architectural and algorithmic choices are predicated on addressing the unique structure of social media content—requiring moment-to-moment synchrony between facial dynamics, speech, and emotional resonance, all under strict latency and long-horizon consistency constraints.
The work formalizes and motivates the "social world model" paradigm: a generative structure designed not simply for physical simulation, but to participate as an active, multimodal agent in human-centric social dynamics. MaineCoon notably achieves real-time, sub-second streaming generation (up to 47.5 FPS at 480p) for synchronized audio-video on commodity compute, outstripping all prior open models in both speed and joint modality quality benchmarks.
Data Infrastructure for Social-Interactive Audio-Visual Generation
Recognizing that social-media “liveness” diverges sharply from cinematic or synthetic video corpora, the MaineCoon pipeline integrates dual data pathways: a synthetic curriculum specifically designed to match long-horizon, prompt-switching supervision requirements, and a massive real-video pathway curated from short-form, speech-centric social media. The latter emphasizes rigorous synchronization filtering, speaker identification, shot stability, and audio-visual correspondence.
The synthetic pipeline employs a director-style taxonomy for prompt and scenario diversity, with multi-stage filtering and trajectory caching for all candidate clips, ensuring full supervision over action, dialogue, and scene switching.
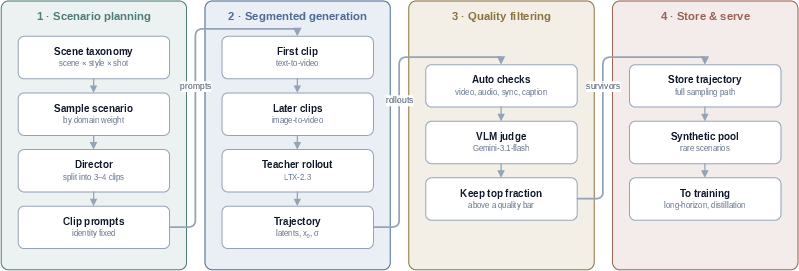
Figure 1: The synthetic pipeline samples scenarios, splits them into clips with evolving dialog/action, and retains full sampling trajectories for consistency objectives.
The real-video pipeline applies hierarchical filtering—face detection, crosstalk removal, stringent lip-sync verification, and automatic text/audio alignment—prior to domain balancing for under-represented scenarios (e.g., high-motion, multi-person interactions).
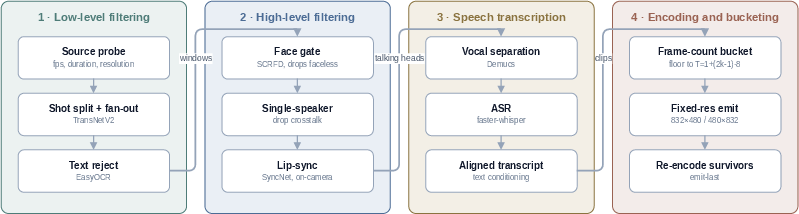
Figure 2: Real-video pipeline selects segments with visible, speaking participants, filters multi-speaker crosstalk and out-of-domain scenarios, and standardizes all features.
The authors introduce SocialVideo Bench, a domain-balanced benchmark evaluating not just conventionally used visual/motion metrics but comprehensive audio-visual and alignment scores targeted at reflecting the complexity of real social videos.
Forcing-free Streaming Training with Self-Resampling and Alignment
MaineCoon’s model core is a causal audio-visual diffusion transformer operating on synchronized latent chunks. The training paradigm discards dependence on bidirectional, teacher-forced objectives. Native streaming autoregressive (AR) training incorporates a robust self-resampling regime: the model periodically conditions on degraded, model-induced histories (using stop-gradient rollouts) to close the train-test context gap and make long-horizon decoding resilient to error accumulation and temporal drift.
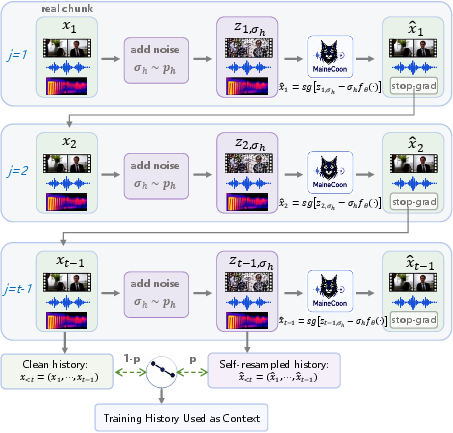
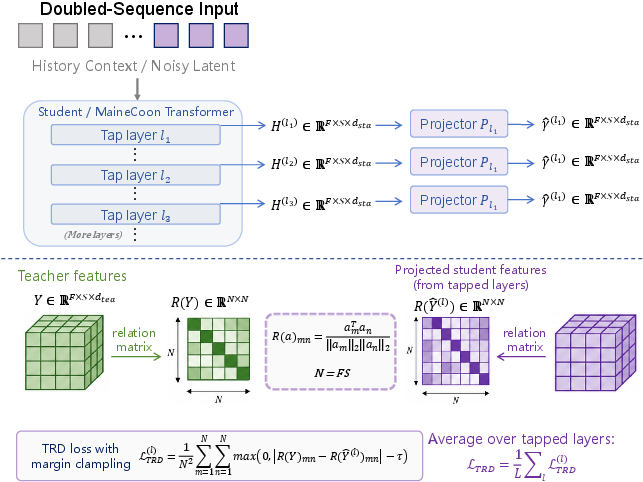
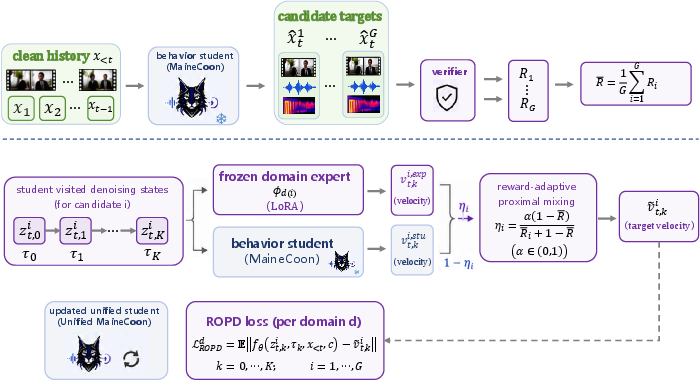
Figure 3: Self-resampling generates perturbed past chunks to simulate deployed context and makes the network robust to its own prediction errors.
To further accelerate convergence and enforce structured semantic space, MaineCoon aligns intermediate transformer representations to a frozen, high-capacity, self-supervised video encoder (V-JEPA 2) by relational (cosine-similarity) distillation, facilitating rapid emergence of coherent cross-modal coordination.
The post-training phase employs multi-domain Direct Preference Optimization (DPO) and Reinforced On-Policy Distillation (ROPD). Specialists (via LoRA adapters) are trained for high-drift domains (e.g., far shot, multi-person, high-motion), and a unified student is refined using a feedback mixture of reward signals and expert priors, ensuring consistent behavior across previously underperforming scenarios without compromising generalization.
Agentic Streaming Inference: Planning, Memory, and Buffering
A key novelty is MaineCoon’s agentic, training-free streaming inference stack. This system decouples high-level "planning" (prompt evolution, interaction handling, degradation observation/repair) from the generative kernel:
- Agentic Planner: A LLM (Gemma 4 26B MoE) dynamically authors the prompt stream and observes (with vision-LLMs and custom drift heuristics) for narrative and visual consistency. Repairs are implemented forward-only; no resets interrupt viewer experience.
- Agentic Cache Manager: Implements a bounded, persistent KV-cache over the streaming transformer—anchoring scene and subject tokens, capping context length within trained distribution, and applying statistical and semantic correction only to memory tokens (never emitted latents), thereby mitigating drift accumulation over minute-scale generation.
- Look-Ahead Buffer Controller: Regulates buffer size between generation and playback heads, trading responsiveness for robustness in real-time streaming, ensuring user interaction maps seamlessly into the content stream without user-visible lag or output discontinuities.
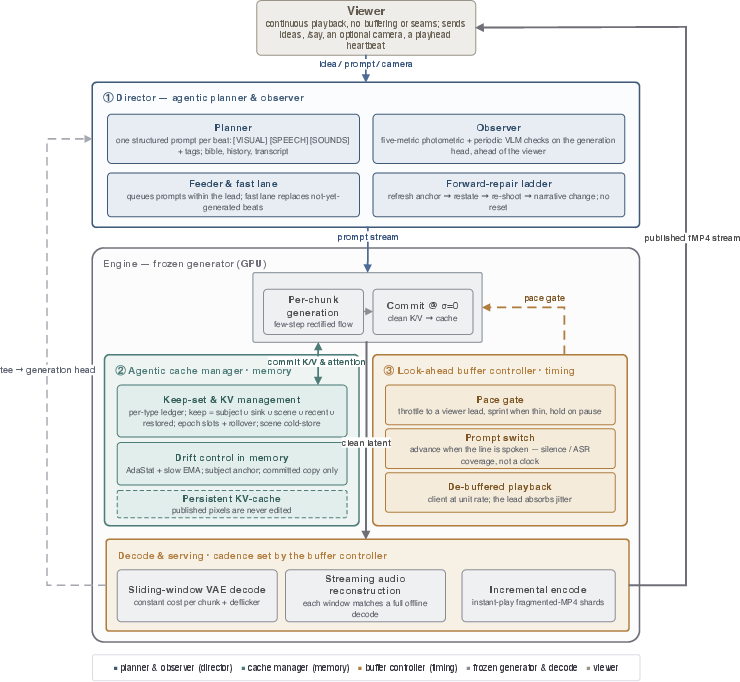
Figure 4: Planning, memory, and buffer controls are delegated to separable agentic controllers interfacing atop the frozen MaineCoon generator.
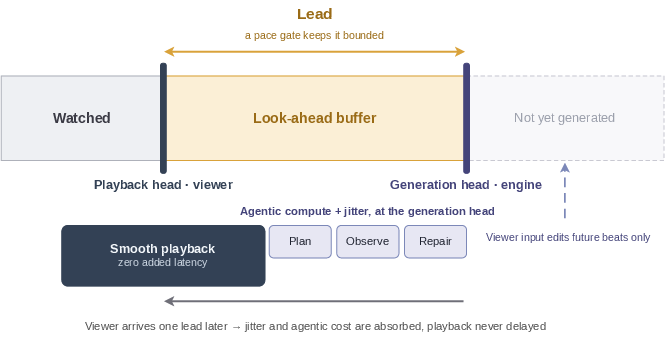
Figure 5: Streaming look-ahead buffer decouples playback from generation headroom, allowing agentic compute to act ‘ahead’ of the viewer.
The model’s efficacy is extensively validated on SocialVideo Bench, where MaineCoon not only surpasses all open baselines in aggregate joint audio-visual metrics (0.934 average, with 5.8–10.1% SOTA improvements on AVH and JAVIS), but also demonstrates practical streaming rates >4× faster than 14B-32B competitors. Notably, this is achieved on a single H100, with throughput faster than 1.3B-parameter models limited to video-only tasks.
Qualitative results highlight robust, TikTok-native style synthesis across a variety of social domains: high-fidelity lip synchronization, subject identity maintenance under interaction and prompt switches, coherent multi-person dialogs, expressive emotional transitions, and idiomatic meme timing/delivery.

Figure 6: MaineCoon synthesizes long-horizon social video (e.g., TikTok clips) with authentic, high-detail human portraits and temporally stable performance.

Figure 7: Dense Speech generation preserves alignment and expressivity over extended dialogue.

Figure 8: Music and vocal domain example captures vocal timbre and body rhythm across the stream.

Figure 9: Two-person interaction shows consistent speaker identity and natural turn-taking in synced audio-visual output.

Figure 10: Dance/high-motion clips maintain spatial coherence and avoid ghosting artifacts.

Figure 11: Emotional performance tracks facial and prosodic changes smoothly across time.

Figure 12: Meme generation demonstrates narrative reversals and expressive, social-media style interaction.
Theoretical and Practical Implications
MaineCoon establishes that large-scale, real-time, streaming multimodal generation for social interaction is now achievable with commodity GPU resources. The paradigm shift articulated—toward active social world models—necessitates modeling social “physics”: high-dimensional, rapid, non-Markovian dynamics where human intent, affect, and interaction are the true invariants, not just visual persistence.
Practically, these advances will enable construction of AI-native social platforms with fluid, uninterrupted, and emotionally resonant engagement untethered from deterministic, physical-world constraints or batch-inference. The architectural decoupling of fast reactive modules (for sub-second synchronization and backchanneling) and slow deliberative planners (for conversation and scenario engineering) points toward cognitive architectures with dual-system real-time control, crucial for persistent multi-user worlds and full-duplex interaction.
In the context of contemporary world models, MaineCoon’s approach challenges reliance on teacher forcing, static context pipelines, and non-causal architectures, demonstrating empirical superiority in the highly volatile, interaction-driven domains that typify human sociality.
Conclusion
MaineCoon represents a critical technical milestone for audio-visual generative modeling in social settings, combining an efficient, truly streaming causal transformer backbone with alignment, robustness, and agentic control. Its real-time efficiency, interaction handling, and high-fidelity streaming open a clear trajectory toward more ambitious social world models. Future work will build upon these advances by incorporating active human observation/state simulation modules, scaling beyond single agents to complex, real-time multi-agent and multi-user scenarios, and fusing reactive/planning subsystems for seamless, emotionally intelligent interaction and world modeling.

