- The paper introduces CausalCine, a framework that unifies causal multi-shot learning, dynamic memory routing, and step-compressed distillation for coherent long-form video generation.
- The methodology supports interactive, low-latency generation with online prompt injections and maintains cross-shot consistency using content-aware memory routing.
- Experimental results show improved text alignment, shot-cut accuracy, and inter-shot identity consistency compared to traditional autoregressive baselines.
CausalCine: Real-Time Autoregressive Generation for Multi-Shot Video Narratives
Introduction
The paper "CausalCine: Real-Time Autoregressive Generation for Multi-Shot Video Narratives" (2605.12496) presents a comprehensive architecture for scalable, interactive, real-time video synthesis that supports generation of coherent multi-shot narratives with online prompt injection and causal content propagation. Contrasting with previous approaches, which either require quadratic-cost, bidirectional attention or are limited to short-horizon, single-shot rollouts, CausalCine unifies causality, memory-aware recall, and step-compressed inference for story-driven, long-form video generation.
Methodology
CausalCine consists of three core technical advances:
- Causal Multi-Shot Learning: The model is first tuned on long, natively multi-shot video corpora via chunked, causal, teacher-forcing supervision. Shot boundaries, prompt switches, and entity reappearances are all exposed during pretraining in a strictly autoregressive, chunk-wise formulation, ensuring that the model internalizes the correct progression and recall across shots. Notably, multi-shot learning precedes any step-distillation; direct distillation from a short, bidirectional teacher yields inferior shot consistency and transition control.
- Content-Aware Memory Routing (CAMR): To address the limitations of fixed-window or positionally-anchored memory, CAMR dynamically routes attention to historical key-value entries selected by per-chunk, attention-based relevance scores. Memory frames most semantically aligned with the current generation are selected, allowing for cross-shot recall not strictly tied to temporal proximity. Positional encoding (Block-Relative RoPE) ensures valid phase alignment regardless of historical depth. This mechanism enables preservation and reintroduction of entities after long temporal gaps.
- Step-Compressed Distillation and Adversarial Stabilization: Distribution Matching Distillation (DMD) is applied after the base model learns multi-shot causal structure, compressing the autoregressive rollout from many steps to four denoising steps per chunk. An auxiliary adversarial head regularizes camera motion and subject framing, mitigating sequence-level drift during long rollouts.
Real-Time Interactive Generation and Experience
CausalCine supports online prompt editing and immediate continuation. Chunks are generated sequentially, streaming with 16 FPS latency on current-generation GPU clusters, with prompt tokens injected at shot boundaries and referenced on the fly. This enables interactive content creation workflows in which users can "direct" evolving narratives, insert events dynamically, and recall previously generated content.

Figure 1: CausalCine streams video chunks causally, supports online shot-level prompts during rollout, and enables later shots to recall earlier content without recomputation.
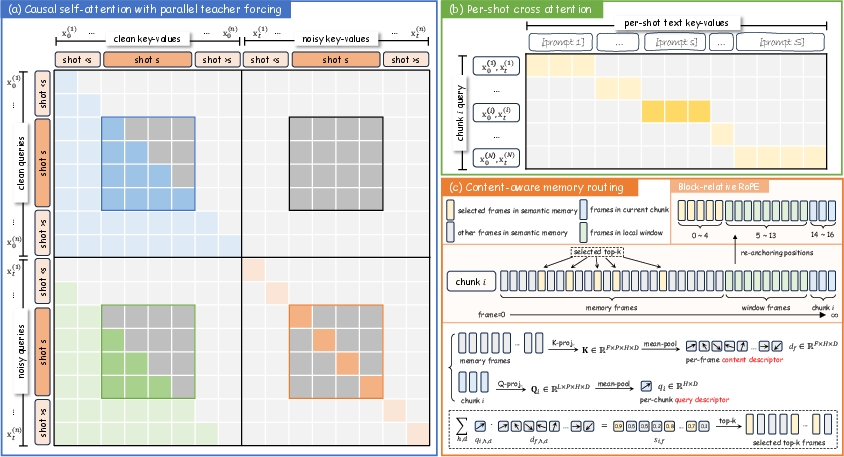
Figure 2: (a) Multi-shot teacher forcing in parallel, (b) per-shot conditioning, (c) content-aware memory routing with block-relative RoPE ensures robust long-context dependencies during arbitrarily long rollouts.
Experimental Results
Experiments are performed using a 14B-parameter video backbone (Wan2.1-T2V-14B). The evaluation protocol covers both qualitative and quantitative multi-shot alignment, temporal consistency, and visual quality metrics—including LAION aesthetic scores, ViCLIP text-video alignment, CLIP/DINO-based subject and background consistency, Gemini-driven reasoning benchmarks, and shot-cut accuracy as measured by TransNetV2-based temporal segmentation.
CausalCine exhibits stronger text alignment, improved shot-cut accuracy, and greater inter-shot identity consistency compared to recent autoregressive baselines (e.g., Self-Forcing, MemFlow, ShotStream, Infinity-RoPE). The model's causal framework nearly closes the gap with bidirectional state-of-the-art approaches (e.g., HoloCine, MultiShotMaster), with the advantage of supporting streaming, low-latency rollout and online prompt updates.

Figure 3: CausalCine outperforms baseline AR models, maintaining coherent shot progression and preventing semantic stagnation or repetition.

Figure 4: Results from the causal generator are competitive with bidirectional baselines on visual quality and consistency.
Ablation and Component Analysis
Detailed ablations highlight several critical findings:
- Ordering of Causal Learning and Step Compression: Models that undergo causal, multi-shot adaptation prior to distillation outperform those with direct step-compression from short, bidirectional teachers, especially regarding identity and prompt-alignment across cuts.

Figure 5: Without explicit causal multi-shot pretraining, step-compressed students exhibit intra-shot instability and identity loss across shots.
- Memory Router: CAMR significantly enhances cross-shot recall compared to first-frame or no-memory baselines, demonstrated via specialized benchmarks focusing on subject reappearance after extended absences.

Figure 6: Content-aware memory routing enables retrieval of relevant historical context, ensuring identity consistency across temporally distant shots.
- Distillation Quality and GAN Regularization: The four-step DMD student retains the multi-shot causal structure and visual fidelity of the deep-step teacher at a fraction of the inference cost.

Figure 7: The distilled student maintains the base model's shot-level structure and subject identity with much-reduced computational demands.
- Adversarial Regularization: GAN-based sequence stabilization attenuates drift in camera and subject framing.

Figure 8: Adversarial regularization produces more temporally stable, realistically composed sequences.
Failure Modes and Limitations
A persistent failure mode is fine-grained physical state continuity across cuts—for example, in a multi-shot coffee-making sequence, subtle spatial relations, and physical processes may not persist through transitions, even though scene layout and high-level context are preserved. CausalCine’s content-aware memory aids semantic recall, but explicit small-object, physical state tracking and action-level causality are not guaranteed.

Figure 9: CausalCine sometimes fails to maintain physically consistent object states across shots, despite overall narrative coherence.
Limitations also include reliance on large backbones, currently restricting efficient deployment to high-end hardware. Nevertheless, causal formulation is not intrinsically scale- or hardware-bound and could benefit from further backbone optimization and quantization.
Implications and Future Directions
CausalCine operationalizes interactive, real-time, multi-shot video generation with robust shot transitions and entity recall. This framework brings causality, memory awareness, and prompt-continuable generation into practical regimes for creative, cinematic, or agent-driven long-form video workflows. For future research, directions include enhancement of fine-grained state continuity via object-centric memory, tighter integration of structured story or action constraints, and adaptation to world-model or robotic settings where persistent, interactive recall is essential.
Conclusion
CausalCine demonstrates that fully autoregressive, chunk-wise video generation—when augmented with long-context aware memory routing and explicit multi-shot structure learning—matches the coherence and quality of bidirectional systems while enabling real-time, interactive control and low-latency streaming. This architecture establishes a viable path for flexible, prompt-adaptive, open-ended video generation at scale, and future extensions are likely to focus on fine-grained consistency, scalable deployment, and integration with agentic reasoning or world modeling (2605.12496).