- The paper introduces an autoregressive diffusion framework that transforms a bidirectional I2V model into a real-time, audio-driven video generator with precise lip synchronization.
- It leverages audio cross attention, distribution matching distillation, and sparse causal attention to maintain continuous, infinite-length video streams while minimizing latency and error accumulation.
- System optimizations, including CUDA stream and multi-GPU setups, enable seamless FaceTime-style video conferencing and efficient real-time deployment.
Real-Time Audio-Driven FaceTime Video Generation via Autoregressive Diffusion Models
Introduction
The paper "TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models" addresses the critical challenge of high-latency issues in real-time video conferencing by presenting a novel solution that adapts state-of-the-art (SOTA) video generation models into efficient, real-time character animators. The core innovation lies in transforming a pretrained bidirectional video diffusion model into an autoregressive system capable of audio-driven character animation. This paper steps into this challenge by redesigning the model architecture and system workflow to support infinite-length video streaming without error accumulation.
Model Architecture and Techniques
The enhanced video generation capabilities originate from modifying a pretrained 18-billion-parameter image-to-video (I2V) model, which becomes a Text-Image-Audio to Video (TIA2V) system. Three key modifications underpin this transformation:
- Audio Cross Attention: Integrating audio as an additional conditioning signal alongside existing text and image inputs. This is achieved by adding cross-attention layers to accommodate audio embeddings within sequences, facilitating accurate lip synchronization (Figure 1).
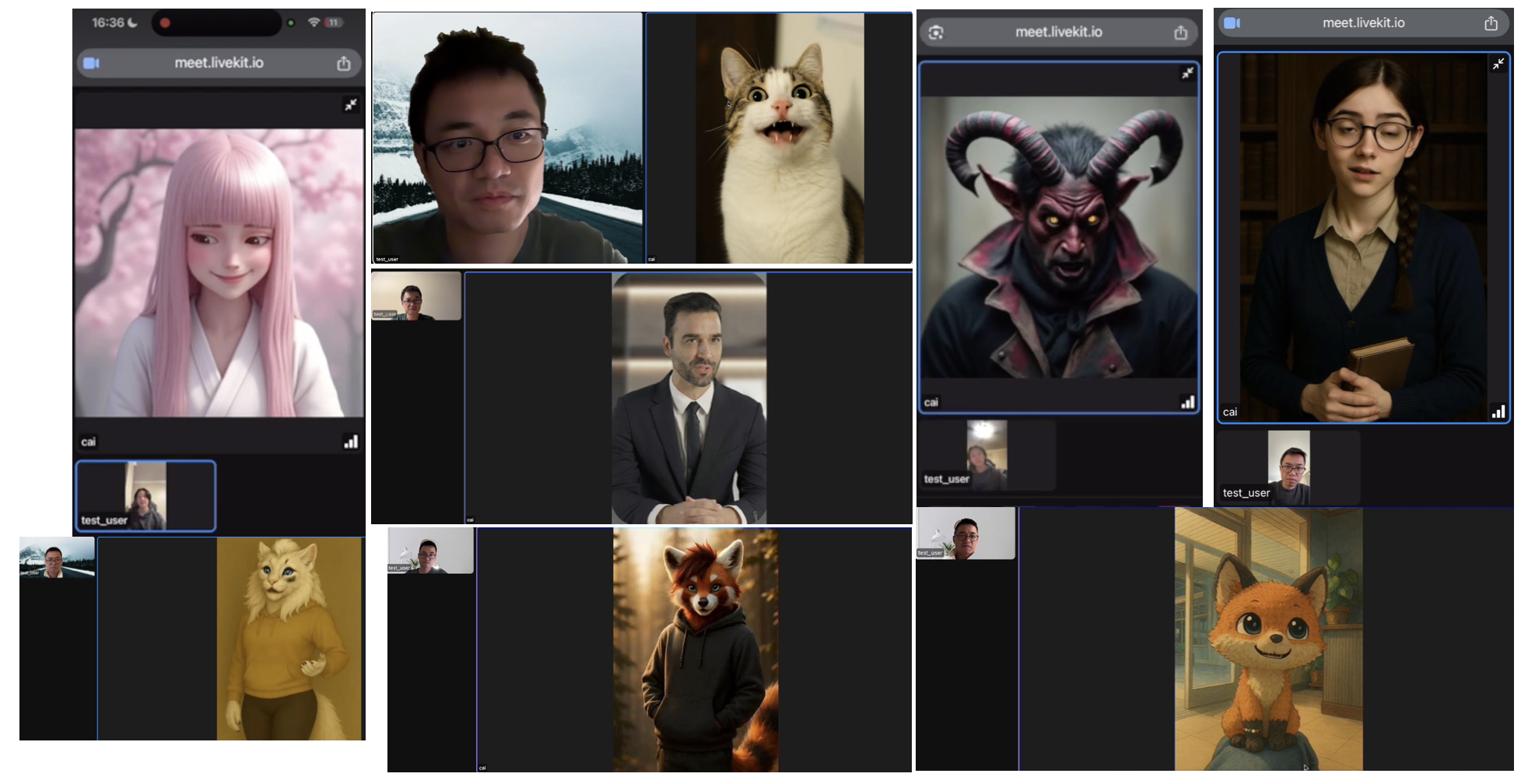
Figure 1: TalkingMachines provides a framework to generate highly dynamic, immersive FaceTime experiences based on different character styles.
- Distribution Matching Distillation (DMD): This distillation process transforms the bidirectional teacher model into a sparse causal autoregressive student model, enabling infinite-length and real-time video streaming. It does so by minimizing the reverse KL divergence between distributions from a multi-step teacher and a few-step student generator. Noteworthy adjustments include a uniform timestep across chunks to maintain continuity, optimizing training with both real clips and synthetic generated data, and fine-tuning using a regression loss to achieve convergence stability (Figure 2).
- Sparse Causal Attention: Leveraging an autoregressive strategy by employing sparse causal attention masks, allowing streams of video frames to be efficiently generated. Tokens in each chunk of frames attend to only specific chunks, reducing memory requirements and preventing error accumulation by always referencing a clean initial image.
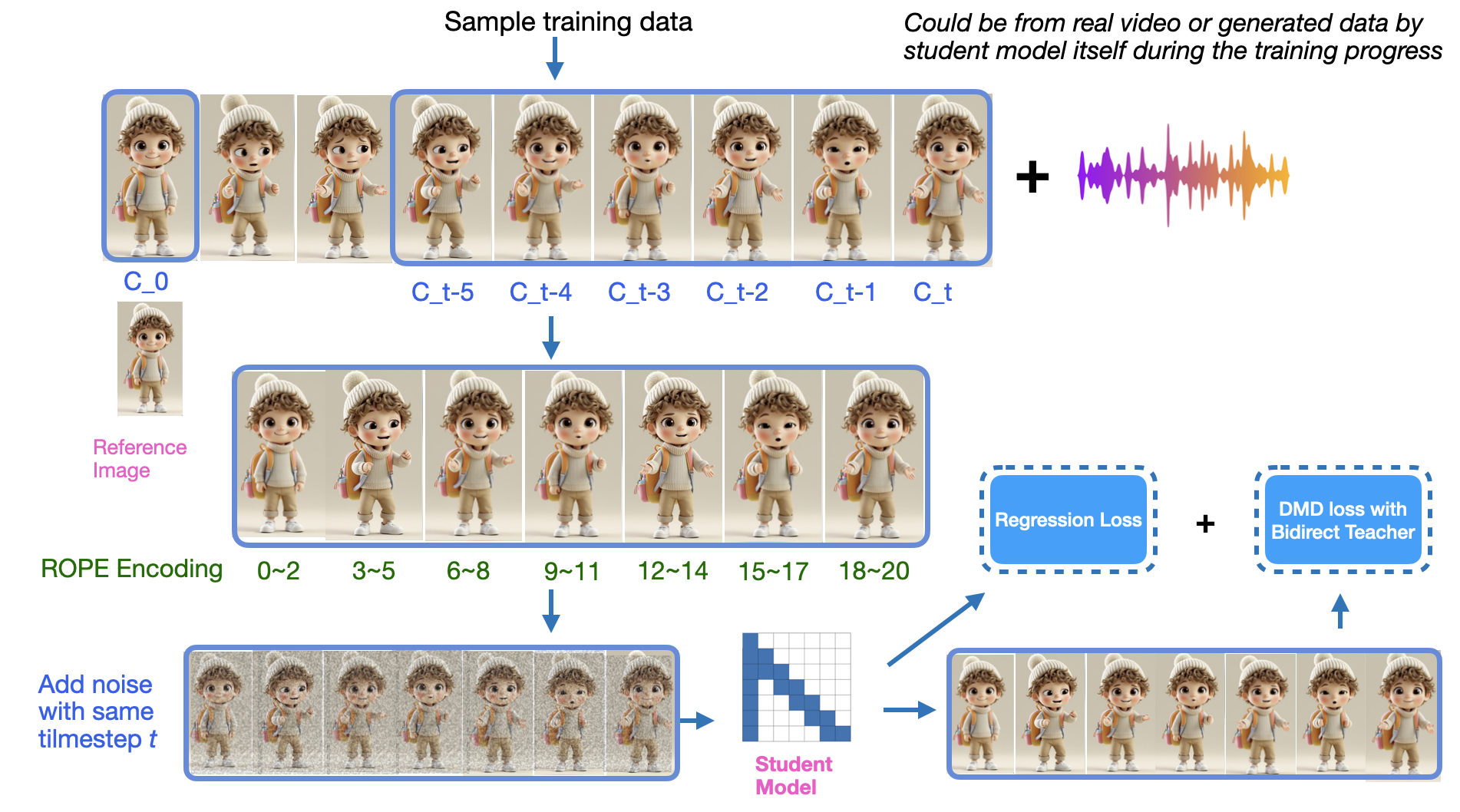
Figure 2: Overview of the DMD training workflow for TalkingMachines. The diagram illustrates the asymmetric distillation process where a bidirectional teacher model is distilled into an autoregressive student model.
Engineering and System Optimizations
The system's architecture further optimizes performance using the following:
- Score-VAE Disaggregation: By disaggregating the diffusion model and VAE decoder across separate devices, communication between devices is optimized. This is crucial for adhering to real-time latency constraints, particularly when employing sequence parallelism techniques.
- CUDA Stream Optimizations: Efficiently manages data transfers using parallelized CUDA streams, allowing operations to occur simultaneously and thereby enhancing throughput.
- Real-Time Server Design: The deployment utilizes a multi-GPU configuration for distinct processing tasks (independent diffusion and VAE decoding processes), optimizing pipeline efficiency. Specifically, integrating a 2-GPU setup where one handles diffusion and the other VAE decoding achieves real-time processing benchmarks (Figure 3).
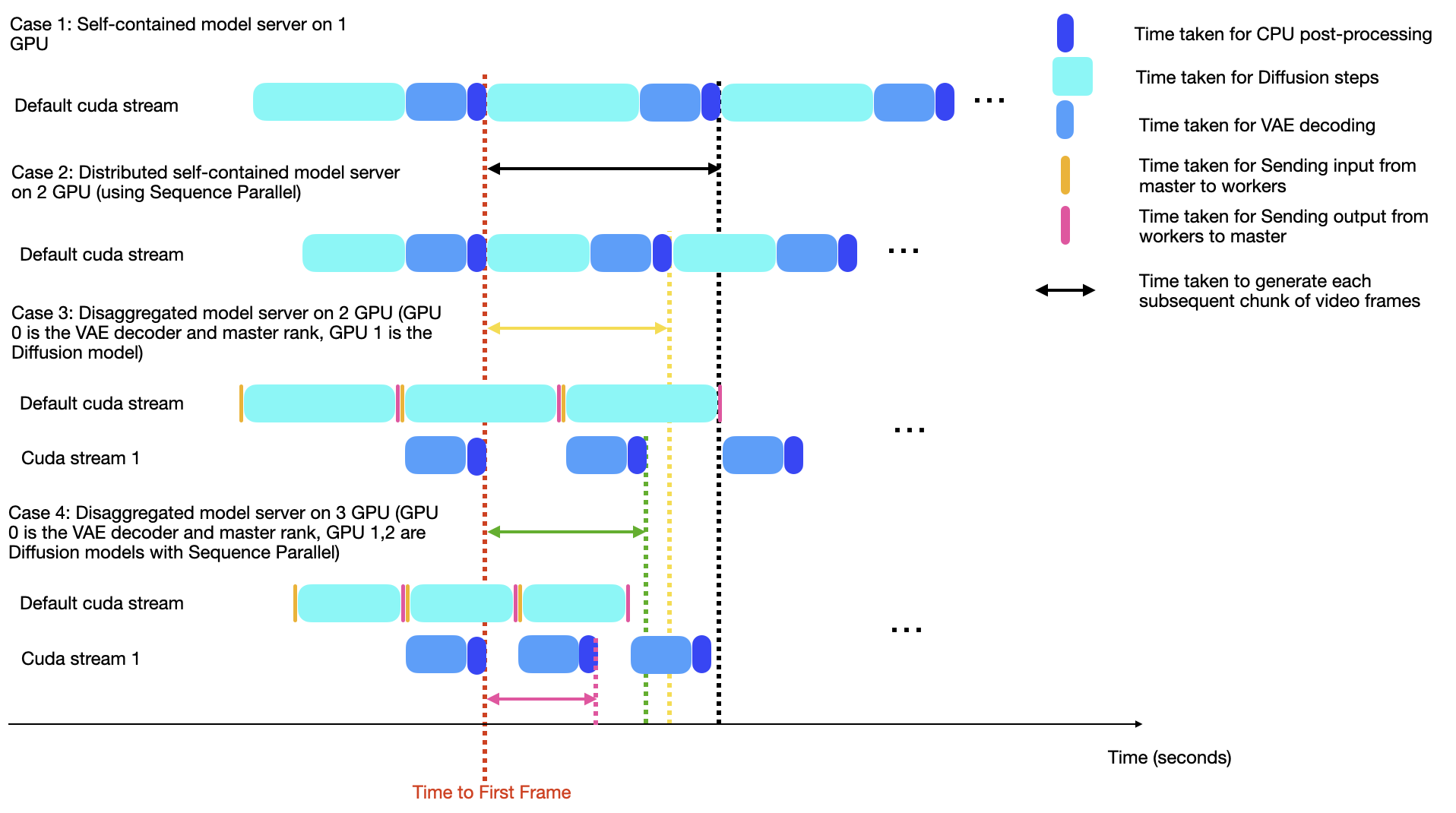
Figure 3: Runtime analysis comparing the latency of various server designs like a simple self-contained server, and our Score-VAE disaggregation server, both with and without Sequence Parallelism.
Applications and Deployment
The paper demonstrates an application scenario utilizing the TalkingMachines model integrated with audio LLMs, producing real-time interactive FaceTime-style video calls. The system architecture supports webRTC streaming via platforms such as LiveKit, offering seamless end-user access across different devices. This implementation underscores the practicality of deploying such complex AI models for real-time communication, maintaining synchronization between generated video and input audio signals.
Conclusion and Future Directions
"TalkingMachines" represents a significant stride in addressing latency constraints in interactive AI systems through innovative use of diffusion models. By tailoring models for audio-visual integration and optimizing inference pipelines, the outputs extend beyond traditional frameworks to offer scalable, low-latency AI experiences. However, the work identifies room for advancements, notably through large-scale audio-visual pretraining iterations to further enhance the scalability and expressiveness of the model. Future efforts should explore deeper integration of audio modalities upfront in the training processes to harness large multimodal datasets, potentially advancing the robustness and versatility of real-time AI-video synthesis.
The architectural and methodological contributions of this paper lay a foundation for further exploration of real-time applications in video conferencing, interactive media, and broadcast systems.

