- The paper introduces an autoregressive, diffusion-based framework that generates high-quality, full-band stereo audio with low latency in an online setting.
- It employs a causal vision encoder with temporal differencing and a continuous audio VAE to ensure precise audio-visual synchronization and efficient token modeling.
- Experimental results show superior performance over offline baselines on AAA gameplay data, achieving real-time operation with high semantic and temporal alignment.
SoundReactor: Frame-level Online Video-to-Audio Generation
Introduction and Motivation
The paper introduces the frame-level online video-to-audio (V2A) generation task, a setting where audio must be generated autoregressively from video frames as they arrive, without access to future frames. This is in contrast to the conventional offline V2A paradigm, which assumes the entire video sequence or large chunks are available in advance. The online constraint is critical for interactive applications such as live content creation, real-time generative world models, and robotics, where low-latency, causal, and temporally aligned audio generation is required.

Figure 1: The frame-level online V2A task restricts the model to only past and current frames, unlike the offline setting where the entire video is available.
The authors propose SoundReactor, a framework explicitly designed for this online V2A setting. The design enforces end-to-end causality, targets low per-frame latency, and aims for high-quality, semantically and temporally aligned full-band stereo audio generation.
Model Architecture
SoundReactor consists of three main components: (a) video token modeling, (b) audio token modeling, and (c) a multimodal autoregressive (AR) transformer with a diffusion head.
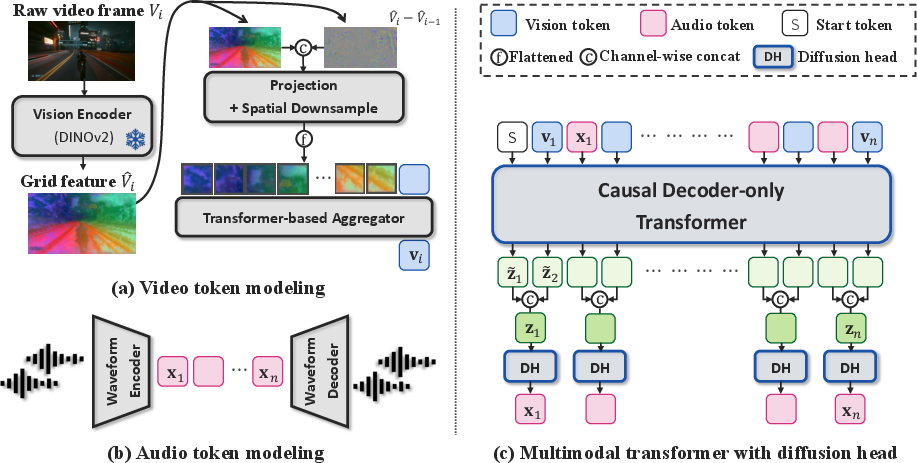
Figure 2: Overview of SoundReactor, showing the video token modeling, audio token modeling, and the multimodal AR transformer with diffusion head.
Video Token Modeling
- Utilizes a lightweight DINOv2 vision encoder to extract grid (patch) features from each frame.
- Temporal cues are injected by concatenating the difference between adjacent frame features.
- Features are projected, flattened, and aggregated via a shallow transformer to yield a single token per frame.
- This approach is fully causal and efficient, as it does not require future frames or non-causal attention.
Audio Token Modeling
- Employs a VAE trained from scratch to encode 48kHz stereo waveforms into continuous-valued audio latents at 30Hz.
- Continuous latents are preferred over discrete tokenization (e.g., RVQ) for higher reconstruction quality and simplified AR modeling, as only one latent per frame is predicted.
- A decoder-only, LLaMA-style transformer receives interleaved, frame-aligned audio and video tokens.
- The diffusion head, following the MAR paradigm, models the conditional distribution of the next audio latent given past audio and current/past video tokens.
- The transformer backbone uses RMSNorm, SwiGLU, and RoPE for positional encoding.
- The diffusion head is accelerated via Easy Consistency Tuning (ECT), enabling few-step or even single-step sampling at inference.
Training and Inference
Training proceeds in two stages:
- Diffusion Pretraining: The model is trained with a next-token prediction objective using a denoising score matching (DSM) loss under the EDM2 framework. The AR transformer and diffusion head are jointly optimized.
- Consistency Fine-tuning (ECT): The model is further fine-tuned to accelerate the diffusion head, reducing the number of function evaluations (NFEs) required for sampling while maintaining sample quality.
At inference, the model autoregressively generates audio latents one frame at a time, conditioned only on past and current video frames. Classifier-Free Guidance (CFG) is applied at the transformer level for controllable conditioning strength.
Experimental Results
Dataset and Evaluation
- Experiments are conducted on OGameData250K, a large-scale dataset of AAA gameplay videos with 48kHz stereo audio.
- The primary evaluation is on 8-second clips, with additional tests on 16-second sequences for context window extension.
- Metrics include FAD, MMD, KL divergence (PaSST), FSAD, IB-Score, DeSync, and subjective listening tests.
SoundReactor outperforms the offline AR baseline V-AURA on all objective metrics except DeSync, and achieves strong subjective ratings in human evaluations for audio quality, semantic alignment, temporal alignment, and stereo panning.
Ablation Studies
- Diffusion Head Size: Larger diffusion heads are necessary for high-dimensional audio latents; small heads fail to produce valid audio.
- ECT Fine-tuning: Fine-tuning the entire network during ECT yields the best results, but fine-tuning only the diffusion head is still effective.
- CFG Scale: Optimal performance is achieved with CFG scales between 2.0 and 3.0.
- Vision Conditioning: Temporal differencing of grid features is critical for audio-visual synchronization; PCA compression of grid features can be used without loss of performance.
Implementation Considerations
- Computational Requirements: Training requires 8×H100 GPUs, with ~36 hours for diffusion pretraining and ~20 hours for ECT fine-tuning.
- Model Size: The full model is 320M parameters (250M transformer, 70M diffusion head), with a 157M parameter VAE.
- Inference: Efficient due to lightweight vision encoder, AR transformer with KV-cache, and ECT-accelerated diffusion head.
- Deployment: Real-time operation is feasible on a single H100 GPU; causal VAE decoding is required for streaming applications.
Implications and Future Directions
SoundReactor establishes a new paradigm for online, frame-level V2A generation, enabling interactive and real-time multimodal applications. The framework demonstrates that high-quality, temporally aligned, full-band stereo audio can be generated causally with low latency, making it suitable for live content creation, generative world models, and robotics.
The use of continuous audio latents and causal vision conditioning represents a significant shift from prior offline, chunk-based, or non-causal approaches. The successful application of ECT for diffusion head acceleration in the AR setting is notable, as it enables practical deployment without sacrificing quality.
Future work should address:
- Scaling to longer context windows and minute- to hour-scale generation.
- Incorporating larger or more semantically rich vision encoders while maintaining causality and efficiency.
- Improving the fidelity of causal VAE decoders for streaming.
- Extending to more diverse real-world datasets and tasks beyond gaming.
Conclusion
SoundReactor provides a principled and effective solution to the frame-level online V2A generation problem, achieving high-quality, low-latency, and causally aligned audio generation. The framework's architectural choices, training strategies, and empirical results set a new standard for interactive multimodal generative models and open new avenues for research in real-time audio-visual synthesis.