VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
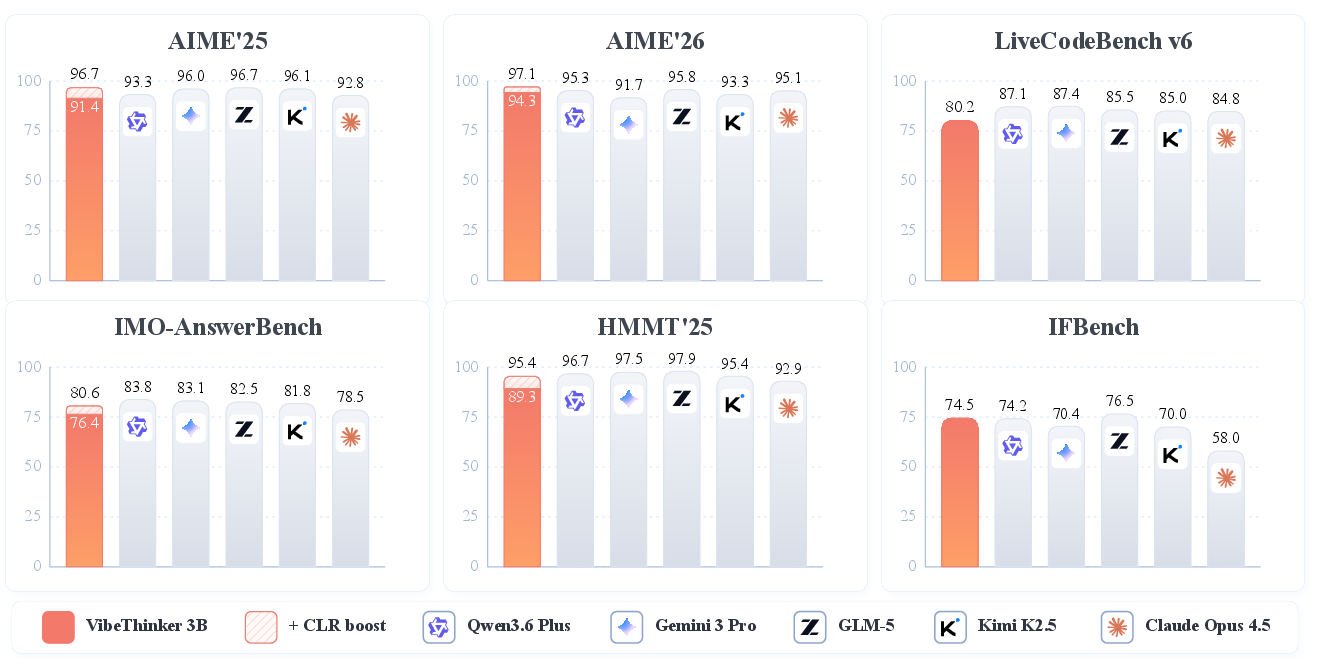
Abstract: This technical report introduces VibeThinker-3B, a compact dense model with 3B parameters developed to investigate how far verifiable reasoning can be pushed within a strictly small-model regime. Building upon the Spectrum-to-Signal post-training paradigm, we systematically enhance the model through an optimized pipeline that includes curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation. Experimental evaluations demonstrate that VibeThinker-3B achieves frontier-level performance on highly demanding verifiable tasks. Specifically, it attains a score of 94.3 on AIME26 (improving to 97.1 with claim-level test-time scaling), an 80.2 Pass@1 on LiveCodeBench v6, and exhibits strong out-of-distribution generalization with a 96.1\% acceptance rate on recent unseen LeetCode contests. This effectively places it in the performance band of first-tier reasoning systems, matching or exceeding flagship models that are orders of magnitude larger, such as DeepSeek V3.2, GLM-5, and Gemini 3 Pro. Furthermore, a score of 93.4 on IFEval confirms that this extreme reasoning enhancement does not compromise strict instruction controllability. Extending our previous 1.5B work, these findings motivate the Parametric Compression-Coverage Hypothesis, which views verifiable reasoning as compressible into compact reasoning cores, while open-domain knowledge and general-purpose competence require broad parameter coverage over facts, concepts, and long-tail scenarios. This perspective suggests that compact models are not merely deployment-efficient substitutes, but a complementary path toward frontier-level performance in parameter-dense capability regimes.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces VibeThinker‑3B, a small AI LLM with about 3 billion “knobs” (called parameters). Its main goal is to see how far a small model can go at step‑by‑step problem solving that can be checked automatically—things like math problems (where there’s a right answer) and coding tasks (where you can run tests). The surprising result: with the right training, this small model performs at the level of some of the best, much larger models on these “verifiable” tasks.
The main questions the paper asks
- Can a strictly small model (3B) reach top‑tier results on hard, checkable problems in math and code?
- Can it do this without losing the ability to follow instructions carefully?
- Why do small models do so well on reasoning, but still lag on broad, fact‑heavy knowledge tests?
- Is there a basic rule that explains which abilities need lots of parameters and which ones can be “compressed” into a small model?
Their answer is a new idea: the Parametric Compression‑Coverage Hypothesis. In simple terms:
- Reasoning (like solving math step by step) can be compressed into a small “reasoning core.”
- Knowledge (like knowing countless facts across many fields) needs wide coverage, which usually takes many more parameters.
How they trained the model (in simple terms)
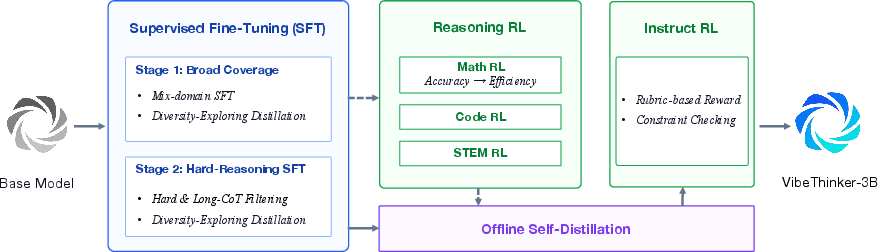
They start from a 3B base model and run a careful, multi‑step “training pipeline,” like a well‑planned study routine. Here’s the idea using everyday language:
- First, they do Supervised Fine‑Tuning (SFT): This is like showing the model lots of worked examples with solutions. They:
- Build and clean a big practice set across math, code, science questions, regular chat, and instruction following.
- Use “multi‑path” examples, keeping several different correct solution paths for the same question. Think of this as showing the model many good ways to solve a problem, not just one.
- Apply strict quality checks so bad or copied data doesn’t slip in.
- Use a two‑stage “curriculum”: start broad and easier, then focus on longer, tougher reasoning problems.
- Then, they do Reinforcement Learning (RL): This is like having a coach give points when the model’s answers pass tests. They:
- Use verifiable rewards—math answers are checked, code is run against tests, and multiple‑choice or science questions are validated.
- Focus training on questions near the model’s skill limit (not too easy, not too hard), so practice is challenging but doable. This is guided by an algorithm they call MGPO, which prefers problems where the model is roughly 50/50 right and wrong.
- Keep long reasoning chains intact by using a long context window, so the model learns solid multi‑step thinking.
- Train across domains in sequence: first Math → then Code → then STEM reasoning.
- A neat twist for efficiency: Long2Short Math RL
- After the model learns to be accurate, they reward shorter correct solutions over longer ones—like practicing to explain clearly without rambling. Importantly, this only reorders rewards among correct solutions, so accuracy isn’t sacrificed.
- Offline Self‑Distillation: The model learns from its best earlier solutions, like a student re‑studying their own top work. They pick which solutions to copy back into the model by scoring how “learnable” each one is for the current model.
- Instruct RL: Finally, they train the model to follow instructions exactly (format, order, number of items, etc.), so it can be both smart and well‑behaved. They use rule checks (for strict tasks) and graded rubrics (for open tasks).
Altogether, this follows their “Spectrum‑to‑Signal” idea: first show a wide spectrum of good ways to solve problems, then amplify the strongest, most reliable signals.
What they found and why it matters
- Top results on hard, checkable benchmarks:
- Math: AIME 2026 score 94.3, rising to 97.1 with a smart test‑time trick; very strong on other math contests too.
- Coding: LiveCodeBench v6 Pass@1 of 80.2 (that’s a tough live coding benchmark).
- Real‑world coding contests: On recent LeetCode weekly/biweekly contests, it passed 96.1% of first‑try submissions (Python), close to top proprietary systems.
- Instruction following: IFEval score 93.4, showing it didn’t lose discipline after all that reasoning training.
- Claim‑Level Reliability Assessment (CLR): a test‑time boost
- Instead of blindly voting on whole long solutions, CLR picks out a few key “claims” (important steps), has the model re‑check them, and trusts answers whose key steps hold up. This improved math scores without changing the model itself, and saved tokens compared to rechecking entire long explanations.
- Where it still lags:
- On heavy knowledge tests (like GPQA‑Diamond), it’s good but not top. This fits their hypothesis: broad knowledge breadth needs many parameters for coverage, while pure reasoning can be compact.
Why this matters:
- It shows a 3B model—tiny compared to 100B+ giants—can be a first‑tier reasoner on tasks you can verify (math/code), if you train it right.
- This can lower costs, speed up responses, and make strong reasoning more accessible to schools, researchers, and devices with limited compute.
What this could change going forward
- Decouple reasoning from knowledge:
- Use small, efficient “reasoning cores” for solving structured, checkable problems.
- Pair them with larger knowledge sources (or tools) when you need encyclopedic facts.
- Make powerful AI more accessible:
- Smaller models use less memory and energy, so high‑level reasoning can run on cheaper hardware or even local devices.
- Training strategy matters as much as size:
- Building a broad solution “spectrum,” then amplifying reliable “signals,” plus careful instruction tuning, can unlock big gains without just making models huge.
In short, VibeThinker‑3B suggests that “thinking well” and “knowing everything” are different skills for AI. Thinking can be compressed into a small model and still reach frontier levels on tasks we can verify, while broad knowledge still benefits from bigger models. This points to a future where compact reasoning models and large knowledge systems work together.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, framed to guide follow‑up research.
- Data scale and composition transparency: The report omits dataset sizes, domain mix ratios, and exact sources for SFT, RL, self-distillation, and Instruct RL; releasing or detailing these is necessary for reproducibility and to assess what data volumes are required to reach the reported performance.
- Decontamination rigor and auditing: “Strict decontamination” is referenced but only n‑gram filtering and basic heuristics are described; stronger overlap audits (e.g., fuzzy/semantic similarity, edit distance, date filtering) and public contamination reports are needed, especially given teacher-model–generated data and recent competition benchmarks.
- Ablations on pipeline components: There is no quantitative attribution of gains to key stages (two‑stage curriculum SFT, MGPO RL, Long2Short RL, offline self‑distillation, Instruct RL); controlled ablations are needed to isolate which components are necessary and how they interact.
- On‑policy RL vs. off‑policy tradeoffs: The switch to fully on‑policy training improves stability, but the added sample/computational costs are not quantified; ablations should report sample efficiency, wall‑clock, and throughput impacts, and whether lighter-weight mismatch mitigations suffice.
- MGPO hyperparameter sensitivity: The choice of γ, group size G, clipping ε, and the target p0=0.5 are not analyzed; sensitivity studies and principled selection guidelines are needed to generalize MGPO beyond the reported setting.
- Reward verifiers and LLM-as-judge reliability: For mathematics and STEM, LLM judgments complement rule checks, but no error rates, disagreement analyses, or adversarial tests are reported; a calibrated assessment of judge noise and reward hacking susceptibility is needed.
- STEM reward design details: The paper mentions “answer matching with option verification” without specifying validators, heuristics, or coverage; releasing schemas and measuring false positives/negatives would clarify robustness.
- Long2Short RL side effects and generality: While designed to reduce tokens, the approach’s actual token savings, latency gains, and impact on solution robustness are not quantified; it is unclear if it hurts hard problems that benefit from verbose reasoning or whether it generalizes to coding/STEM tasks.
- Sequence catastrophic forgetting and consolidation: Sequential Math→Code→STEM RL is followed by offline self‑distillation, but there is no measurement of forgetting across domains per stage; experiments comparing interleaved vs. sequential RL and the efficacy of self‑distillation in preserving earlier skills are needed.
- Specialist model “parameter merging” method: The procedure to merge domain specialists at the parameter level is not described (e.g., weight interpolation, task arithmetic, Fisher weighting); reproducible methodology and stability analyses are needed.
- Single long‑context RL choice: The claim that a 64K single‑stage context is superior to progressive expansion is anecdotal; controlled comparisons across base models and training states are required to validate when this reversal holds.
- Long‑context capability evaluation: Despite training with 64K context, there is no long‑context benchmark evaluation (e.g., LongBench, RULER, LV-Eval) to validate retrieval and reasoning over extended contexts; such tests would substantiate the long‑context design choices.
- Claim-Level Reliability Assessment (CLR) specifics: The claim extraction method, self‑verification prompts, and sensitivity to M (number of claims) are not detailed; studies on extraction quality, robustness to spurious claims, same‑model verifier bias, and comparisons to alternative TTA/self‑consistency baselines are needed.
- CLR compute–accuracy tradeoffs and domain scope: The inference cost of 32 trajectories and self‑verification is not reported, nor is CLR tested on coding or instruction tasks; profiling and domain‑wise evaluations would clarify practical deployment value.
- Fairness of evaluation settings: VibeThinker-3B is evaluated with standardized sampling (e.g., temperature=1.0) and multiple generations per item, while many baselines’ numbers are taken from reports with different settings; re‑evaluating baselines under matched decoding and sampling budgets is needed for rigorous comparisons.
- Coding generalization scope: Evaluations focus on Python and a limited set of suites (LCB v6, OJBench, LeetCode contests); cross-language performance (e.g., C++, Java), resource‑constrained settings (time/memory), and real‑world robustness (security pitfalls, undefined behavior) are not assessed.
- OJBench performance diagnosis: The relatively low OJBench score (38.6) contrasts with LCB v6; a failure analysis by category (I/O, data structures, corner cases) would identify deficits and guide targeted improvements.
- Knowledge-intensive performance gap: The model lags top systems on GPQA-Diamond; the proposed Reasoning–Knowledge Decoupling paradigm lacks concrete integration experiments (e.g., retrieval-augmented generation, tool use, lightweight knowledge adapters) to test whether small models can close the gap with external knowledge.
- Hypothesis testing for “Parametric Compression-Coverage”: The Compression–Coverage Hypothesis is not formalized or empirically validated beyond performance claims; experiments with pruning, lottery‑ticket analyses, mechanistic probes, and cross‑task transfer to locate and measure a “reasoning core” are needed.
- Safety, robustness, and alignment breadth: Beyond IFEval/IFBench, there is no evaluation on jailbreak resistance, toxicity, harmlessness, bias, hallucination propensity, or instruction‑constraint adversaries; standardized safety suites and human evals are needed.
- Multilingual and multimodal scope: All reported evaluations appear monolingual and text‑only; testing cross‑lingual math/coding and extending the pipeline to multimodal reasoning remain open.
- Robustness to adversarial or noisy inputs: There is no study of prompt perturbations, distractors, or adversarial reasoning traps; stress tests and uncertainty‑aware decoding would quantify stability.
- Generalization beyond strictly verifiable tasks: The focus is math and coding with explicit verifiers; planning, causal reasoning, scientific hypothesis generation, and other non‑verifiable reasoning are not explored.
- Data and artifact release: It is unclear whether training data, reward models/validators, and evaluation scripts will be released; without them, community reproduction and validation of claims is limited.
- Compute and efficiency reporting: Training budgets (FLOPs, GPUs, hours), inference latency, memory footprint, and token/output savings from Long2Short and CLR are not reported; cost–performance curves are needed to support “parameter efficiency” claims in practical deployments.
- Teacher-model dependence and bias: SFT and distillation rely on strong teachers and majority voting; the extent to which teacher errors or stylistic biases propagate into the 3B model is unquantified; cross‑teacher ensemble studies and de‑biasing strategies are open avenues.
- Reward gaming detection: With verifiers and rubric reward models in play, there is no analysis of learned exploitation (e.g., format hacking, test leakage heuristics); red‑team audits and countermeasures are needed.
- License and compliance considerations: The base model (Qwen2.5-Coder-3B) and synthesized data licenses are not discussed; clarifying legal constraints affects data release and downstream use.
These gaps point to concrete experiments and releases that would strengthen the empirical claims, improve reproducibility, and extend the proposed reasoning–knowledge decoupling beyond current, verifier‑friendly tasks.
Practical Applications
Overview
The paper presents VibeThinker-3B, a 3B-parameter small LLM that achieves frontier-level performance on verifiable reasoning tasks (math, coding, STEM) via a post-training pipeline combining curriculum SFT, MaxEnt-Guided Policy Optimization (MGPO) RL, Long2Short RL for token efficiency, offline self-distillation, and Instruct RL. It also introduces Claim-Level Reliability Assessment (CLR), a lightweight test-time scaling method that boosts accuracy without retraining. The authors propose the Parametric Compression-Coverage Hypothesis and a Reasoning-Knowledge Decoupling paradigm, arguing that high-density verifiable reasoning can be compressed into compact models, while knowledge breadth requires larger parameter “coverage.”
Below are practical applications distilled from these findings, methods, and innovations.
Immediate Applications
These applications can be deployed now using the released model or its methods, given standard engineering effort and typical infrastructure.
- Cost-efficient code generation and repair in CI/CD
- Sectors: Software, DevOps
- What: Use VibeThinker-3B in continuous integration to draft solutions for failing tests, auto-generate patches, or propose boundary-case handling, leveraging its strong LiveCodeBench v6 Pass@1 and sandbox-verified reasoning.
- Tools/products/workflows:
- IDE/CLI assistants (e.g., VS Code extension) with unit-test-driven prompting
- CI bots that propose “first-pass” fixes and test augmentations before human review
- Assumptions/dependencies:
- Reliable, deterministic sandbox execution and comprehensive test suites
- Language/runtime coverage relevant to target codebases
- Security isolation for executing untrusted code
- Algorithmic practice tutor and grader for competitive programming
- Sectors: Education, EdTech
- What: A tutoring system that generates hints, validates student submissions, and offers step-focused feedback for LeetCode-like problems, reflecting the model’s 96.1% first-attempt acceptance on recent contests.
- Tools/products/workflows:
- LMS plugin that provides scaffolding and targeted hints
- Auto-grader that matches solutions against hidden tests and verifies intermediate claims
- Assumptions/dependencies:
- Rights to use problem sets and tests
- Guardrails to avoid revealing full solutions when only hints are intended
- Strict-format instruction-following microservices
- Sectors: Software, Data/Analytics, Enterprise IT
- What: Backend services for reliably producing structured outputs (JSON, CSV, SQL, templated text) under hard constraints, supported by high IFEval/IFBench scores and Instruct RL with rule-based validators.
- Tools/products/workflows:
- “Format-locked” endpoints for ETL prompt-automation or report generation
- Schema validators and ordering/keyword checkers in the loop
- Assumptions/dependencies:
- Well-defined schemas and validator rules
- Clear failure handling and retry logic
- Claim-Level Reliability Assessment (CLR) as a test-time wrapper
- Sectors: Software, Education, Research
- What: A drop-in inference-time enhancement that selects answers via claim-level self-verification, improving Pass@1 on math/STEM tasks without retraining.
- Tools/products/workflows:
- Lightweight CLR library wrapping existing generation endpoints
- Reliability-weighted aggregation by answer equivalence class
- Assumptions/dependencies:
- Budget for K-shot sampling (e.g., K=32) and claim extraction
- Effective self-verification prompts; diminishing returns on non-verifiable tasks
- On-device and edge reasoning for verifiable workflows
- Sectors: Mobile, Embedded/IoT, Robotics (planning subroutines)
- What: Deploy 3B-parameter reasoning cores locally for tasks with verifiable outputs (e.g., constraint checks, small planning routines, schedule validation).
- Tools/products/workflows:
- Quantized GGUF builds (e.g., llama.cpp), vLLM serving optimized for small models
- Local validators for constraints and consistency checks
- Assumptions/dependencies:
- Adequate memory/compute on target devices
- Tasks expose verifiable objectives (tests, rules, or checkers)
- Token-efficiency optimization to reduce inference cost
- Sectors: Software, Cloud Ops, API providers
- What: Apply Long2Short RL (or reward shaping) to cut verbose reasoning while preserving accuracy, lowering latency and token spend in production.
- Tools/products/workflows:
- Fine-tuning pipelines with length-aware reward redistribution
- Post-generation trimming guided by claim verification
- Assumptions/dependencies:
- Access to verifiable rewards (math checkers/test suites)
- Monitoring to ensure truncation doesn’t harm correctness
- Data curation and distillation recipes for compact models
- Sectors: Academia, Startup R&D, Open-source
- What: Adopt the paper’s multi-path distillation, rigorous filtering, and learning-potential selection to train strong SLMs on modest budgets.
- Tools/products/workflows:
- Spectrum-to-Signal SFT datasets with multi-solution traces
- Offline self-distillation with length-bucketed NLL scoring
- Assumptions/dependencies:
- Access to capable teacher models and license-compliant datasets
- Robust decontamination and quality filters
- Workload routing to reduce cost and emissions
- Sectors: Enterprise IT, Policy (Green AI)
- What: Operational policies that route verifiable reasoning tasks (math/coding with tests) to 3B models, escalating to larger models only for knowledge-heavy queries.
- Tools/products/workflows:
- Router/orchestrator selecting model based on task verifiability
- Cost and carbon dashboards showing savings
- Assumptions/dependencies:
- Clear task classification and success criteria
- Stable SLAs for escalations and fallbacks
- STEM content authoring and validation
- Sectors: Education, Publishing
- What: Generate variations of math/STEM problems and verify solutions/traces using built-in verifiers and multi-path reasoning.
- Tools/products/workflows:
- Problem synthesis with answer/rationale checks
- Difficulty-targeted curricula via length/difficulty filters
- Assumptions/dependencies:
- High-quality verifiers for correctness and leakage checks
- Editorial oversight to maintain pedagogical quality
Long-Term Applications
These require additional research, integration, or scaling before broad deployment.
- Decoupled architectures: small reasoning cores + large knowledge backends
- Sectors: Software, Enterprise AI, Search
- What: Systems that pair a compact reasoning engine (3B) with retrieval, tools, or a larger knowledge model, reflecting the paper’s Reasoning-Knowledge Decoupling paradigm.
- Tools/products/workflows:
- Toolformer-style routing, retrieval-augmented reasoning (RAR)
- Hybrid pipelines: 3B for search/composition; large model for knowledge gaps
- Assumptions/dependencies:
- Reliable retrieval/tool integration and latency budgets
- Robust routing heuristics and evaluation of combined systems
- Verifiable agentic planners for robotics and industrial automation
- Sectors: Robotics, Manufacturing, Logistics
- What: Use small reasoning cores for task planning with embedded checkers (constraints, safety rules), plus claim-level verification to score candidate plans.
- Tools/products/workflows:
- Simulator-in-the-loop plan validation
- Safety rule engines and temporal-logic checkers
- Assumptions/dependencies:
- High-fidelity simulators and formalized constraints
- Domain-specific verifiers for non-textual actions
- Formal methods and theorem-proving assistance
- Sectors: Software verification, Academia (Math/CS)
- What: Assist interactive theorem proving (Lean/Isabelle/Coq) by generating candidate proof steps and validating claims; CLR-like scoring of proof subgoals.
- Tools/products/workflows:
- Translators between natural language, tactic scripts, and proof states
- Proof-checker-driven rewards for RL
- Assumptions/dependencies:
- Large-scale supervised data for formal domains
- Tight integration with proof assistants’ APIs
- RegTech and compliance automation with verifiable logic
- Sectors: Finance, Legal/Compliance
- What: Map regulations into machine-checkable constraints; generate compliance rationales and verify claims for audits.
- Tools/products/workflows:
- Rule compilers and constraint validators
- Reliability-weighted reporting with claim-level audits
- Assumptions/dependencies:
- Up-to-date regulatory knowledge via retrieval or expert-curated rules
- Human-in-the-loop review for legal accountability
- Grid, operations research, and scheduling with checkers
- Sectors: Energy, Transportation, Supply Chain
- What: Solve constrained optimization heuristics (e.g., scheduling, routing) where feasibility and objective improvements can be verified by simulators or constraints.
- Tools/products/workflows:
- OR/solver wrappers to verify candidate solutions
- Multi-path sampling + claim checks to explore the search space
- Assumptions/dependencies:
- Accurate simulators and objective functions
- Domain tuning and data for performance at scale
- AI-native assessment at scale in education
- Sectors: Education, Testing
- What: End-to-end assessment generation, adaptive testing, and claim-based grading with fairness controls.
- Tools/products/workflows:
- Item banks with verified answers and multi-solution rationales
- Bias monitoring and item-response-theory (IRT) calibration
- Assumptions/dependencies:
- Policy acceptance for AI graders; rigorous validity/reliability studies
- Equity auditing and human oversight
- Open, reproducible RL pipelines for small models
- Sectors: Academia, Open-source
- What: Standardized MGPO implementations, long-context on-policy RL, and offline self-distillation recipes as community toolkits.
- Tools/products/workflows:
- Reference implementations with plug-in verifiers
- Benchmark suites emphasizing decontamination and verifiability
- Assumptions/dependencies:
- Shared data standards and replicable compute environments
- Sustained maintenance and documentation
- Safety and governance: claim-level reliability as a general metric
- Sectors: Policy, Risk, Safety
- What: Use claim-level verdicts and reliability-weighted aggregation to evaluate reasoning quality, detect brittle chains, and support audit trails.
- Tools/products/workflows:
- Reliability dashboards and alerts for production LLMs
- Red-teaming harnesses focusing on critical-claim falsification
- Assumptions/dependencies:
- Robust claim extraction across domains
- Calibration studies to link reliability scores to real-world risk
- Multilingual, domain-specialized compact reasoners
- Sectors: Global software, STEM publishing, Regional education
- What: Extend the approach to other languages and domain idiolects (e.g., legal math, biomedical calculations) with domain verifiers.
- Tools/products/workflows:
- Domain-specific SFT/RL corpora and validators
- Multilingual CLR variants
- Assumptions/dependencies:
- High-quality, licensed multilingual datasets and verifiers
- Additional post-training for language-specific conventions
- Marketplaces of verifiable micro-services
- Sectors: SaaS, Platforms
- What: Curated endpoints for math, code, data wrangling, or validation—each backed by a compact model plus checkers, with clear SLAs and reliability scores.
- Tools/products/workflows:
- Service catalog with per-task reliability and cost
- Router that composes multiple micro-services per workflow
- Assumptions/dependencies:
- Standardized verifiers and interoperable APIs
- Governance for versioning and reproducibility
Cross-cutting Assumptions and Dependencies
- Verifiability is central: The strongest gains occur where tasks have objective checkers (answers, unit tests, constraints, simulators).
- Cost/latency trade-offs: CLR and multi-sample inference improve reliability but increase token and compute costs.
- Knowledge limitations: For open-domain or long-tail knowledge, a retrieval layer or a larger model remains necessary.
- Deployment environment: Safe sandboxes for code execution, schema validators, and long-context serving (e.g., 64K) improve outcomes.
- Data governance: Quality filtering, decontamination, and licensing are prerequisites for training and evaluation integrity.
Glossary
- Answer verification: Automatic checking of whether a generated final answer matches the ground truth. "At the distilled response level, we screen reasoning traces through a combination of answer verification, code sandbox execution, and LLM majority voting."
- Chain-of-Thought (CoT): An explicit sequence of intermediate reasoning steps produced by a model. "Given the substantial variance in Chain-of-Thought (CoT) lengths within the first stage data, we employ sequence packing to enhance training efficiency."
- Claim-Level Reliability Assessment (CLR): A test-time method that scores and selects answers based on validating key intermediate claims. "CLR denotes Claim-Level Reliability Assessment, a claim-level test-time scaling strategy."
- claim-level test-time scaling: Test-time enhancement that operates on key claims within reasoning traces rather than entire trajectories. "improving to 97.1 with claim-level test-time scaling"
- clipping coefficient: The hyperparameter that bounds policy update ratios in a clipped policy objective. "where is the group-relative advantage, is the token-level probability ratio between the current and old policies, and is the clipping coefficient."
- cosine annealing schedule: A learning-rate schedule that decays following a cosine curve. "The learning rate follows a cosine annealing schedule and decays to a minimum value of ."
- curriculum learning: Training that progresses from easier/broader data to harder/long-horizon data in stages. "thereby supporting the introduction of a two-stage curriculum learning strategy."
- data decontamination: Removal of training samples overlapping with evaluation benchmarks to avoid leakage. "Extensive evaluations across multiple independent competition systems, under strict data decontamination, confirm the exceptional parameter efficiency of VibeThinker-3B..."
- dense model: A neural network where most parameters are active (non-sparse) during inference. "This technical report introduces VibeThinker-3B, a compact dense model with 3B parameters..."
- Diversity-Exploring Distillation: An SFT technique that preserves multiple valid solution paths to maintain reasoning diversity. "Following VibeThinker-1.5B, we apply Diversity-Exploring Distillation in both SFT stages..."
- empirical group accuracy: The observed proportion of correct rollouts for a given prompt group. "The empirical group accuracy is computed as:"
- GRPO: A policy-gradient method using group-relative baselines and PPO-style clipping. "This weight is applied to the group-relative advantage inside a GRPO-style clipped objective:"
- group-relative advantage: An advantage estimate computed relative to other samples in the same prompt group. "where is the group-relative advantage, is the token-level probability ratio between the current and old policies, and is the clipping coefficient."
- Instruct RL: Reinforcement learning focused on instruction following and adherence to constraints. "We finally apply Instruct RL to convert the reasoning-enhanced checkpoint into a more reliable user-facing model."
- length-normalized negative log-likelihood: Per-token NLL used to assess how well the student models a given trajectory. "we compute the length-normalized negative log-likelihood under the student model:"
- linear warmup: Gradual increase of the learning rate from zero to its initial value at the start of training. "The first stage is trained for 5 epochs with a 5% linear warmup."
- LLM-as-judge: Using a LLM to evaluate the correctness or quality of outputs. "we jointly use math verify and LLM-as-judge to evaluate answer consistency."
- Long2Short Math RL: An RL phase that promotes shorter correct reasoning by reweighting rewards among correct trajectories. "We further introduce Long2Short Math RL to improve reasoning efficiency by reducing redundant tokens without sacrificing accuracy."
- long-context window: A large maximum input/output token span to preserve complete reasoning traces. "we directly conduct RL with a single 64K long-context window, reducing rollout truncation and better preserving long-horizon reasoning trajectories."
- majority voting: Aggregating multiple model outputs by selecting the most common result. "generate pseudo-labels via majority voting, establishing the foundation for subsequent distillation and training."
- MaxEnt-Guided Policy Optimization (MGPO): An RL algorithm that prioritizes prompts near maximum-entropy correctness (around 50%) for stable learning. "utilize MaxEnt-Guided Policy Optimization (MGPO) in the RL stage to amplify high-value reasoning signals (the 'Signal')."
- maximum-entropy principle: Preference for learning on uncertain cases to maximize information gain. "Inspired by the maximum-entropy principle, this weighting mechanism encourages RL updates to focus on prompts with sufficient uncertainty..."
- multi-domain reinforcement learning: RL applied across several verifiable domains (e.g., math, code, STEM). "curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation."
- Multi-path Reasoning Distillation: Distilling multiple complete solution traces per query to cover diverse valid methods. "Multi-path Reasoning Distillation. For reasoning-intensive samples in mathematics, code, and STEM, we adopt a multi-path distillation approach..."
- n-gram-based filtering: Heuristic filtering that removes samples with repetitive or contaminated n-gram patterns. "N-gram-based filtering. We discard samples containing anomalous repetitive segments, templated degeneration patterns, or n-gram overlaps with evaluation sets..."
- on-policy: Collecting and optimizing on data generated by the current policy to avoid mismatch issues. "perform all RL stages in an on-policy manner."
- out-of-distribution generalization: Strong performance on data from distributions not seen during training. "and exhibits strong out-of-distribution generalization with a 96.1% acceptance rate on recent unseen LeetCode contests."
- parameter-dense capabilities: Abilities that can be compressed into a compact core of parameters. "they can be broadly divided into parameter-dense capabilities and parameter-expansive capabilities."
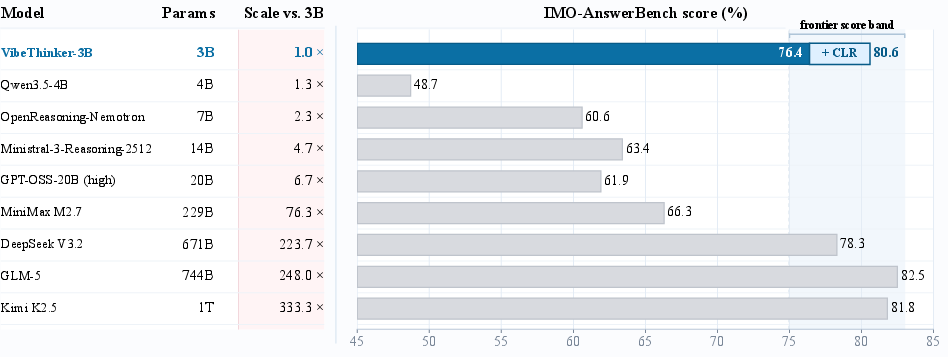
- parameter efficiency: Achieving high performance with relatively few parameters. "Parameter efficiency on IMO-AnswerBench, a highly demanding benchmark..."
- parameter-expansive capabilities: Abilities requiring wide parameter coverage over diverse knowledge. "they can be broadly divided into parameter-dense capabilities and parameter-expansive capabilities."
- Parametric Compression-Coverage Hypothesis: The view that reasoning compresses into compact cores while knowledge requires expansive parameter coverage. "we introduce the Parametric Compression-Coverage Hypothesis, which posits that foundational model capabilities differ..."
- Pass@1: The probability that the first generated solution passes verification or tests. "an 80.2 Pass@1 on LiveCodeBench v6"
- Pass@K: The probability that at least one of K sampled solutions is correct. "evaluate their Pass@K performance on domain-specific probing sets."
- policy optimization: Methods for improving a model’s action-selection policy via gradients and rewards. "These domains share the same policy optimization framework, but use different reward sources and verification mechanisms..."
- Reasoning-Knowledge Decoupling Paradigm: A framework separating reasoning depth from knowledge breadth in scaling strategies. "we propose the Reasoning-Knowledge Decoupling Paradigm to reveal the highly specialized potential of smaller models."
- rejection sampling: Discarding sampled trajectories that fail verification to curate training data. "We first perform rejection sampling with domain-specific verifiers to remove incorrect trajectories."
- reward models: Learned evaluators that score outputs for qualities like helpfulness or adherence. "we use rubric-based reward models to evaluate helpfulness, coherence, instruction adherence, and redundancy."
- rubric-based rewards: Reward signals derived from structured criteria rather than hard verifiers. "By combining constraint checking with rubric-based rewards under the same on-policy RL framework, Instruct RL reinforces strict controllability..."
- sandbox execution: Running generated code in an isolated environment to verify correctness. "At the distilled response level, we screen reasoning traces through a combination of answer verification, code sandbox execution, and LLM majority voting."
- self-verifier: A model that attempts to validate or falsify its own intermediate claims. "the model acts as its own self-verifier, attempting to falsify or validate these extracted claims to yield binary verdicts ."
- sequence packing: Concatenating shorter sequences into batches to improve training efficiency. "Given the substantial variance in Chain-of-Thought (CoT) lengths within the first stage data, we employ sequence packing to enhance training efficiency."
- Spectrum-to-Signal Principle (SSP): A paradigm where SFT builds a diverse solution spectrum and RL amplifies correct signals. "The overall post-training framework continues the Spectrum-to-Signal Principle (SSP) introduced in VibeThinker-1.5B"
- student model: The model being trained to imitate or absorb behaviors from a teacher or trajectories. "distilled back into a unified student model through supervised fine-tuning"
- supervised fine-tuning (SFT): Supervised training post pretraining to adapt a base model to target tasks or behaviors. "First, in the Supervised Fine-Tuning (SFT) stage, we have upgraded the rigorous data synthesis and filtering pipeline..."
- teacher models: Stronger models used to generate labels or reasoning traces for distillation. "we further perform multiple independent samplings using strong teacher models and generate pseudo-labels via majority voting..."
- test-time scaling: Procedures at inference time (no parameter updates) to improve accuracy by aggregating or verifying samples. "We additionally evaluate VibeThinker-3B with Claim-Level Reliability Assessment (CLR), a test-time scaling strategy..."
- token-level probability ratio: The per-token ratio of new to old policy probabilities used in clipped objectives. "where is the group-relative advantage, is the token-level probability ratio between the current and old policies, and is the clipping coefficient."
- verifiable rewards: Rewards computed from objective checks (answers, tests) rather than subjective judgments. "For each prompt , we sample responses from the old policy and evaluate them with verifiable rewards."
- vLLM: A high-throughput inference engine used as the backend for evaluation. "All VibeThinker-3B evaluations are performed with vLLM as the inference backend."
Collections
Sign up for free to add this paper to one or more collections.

