Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
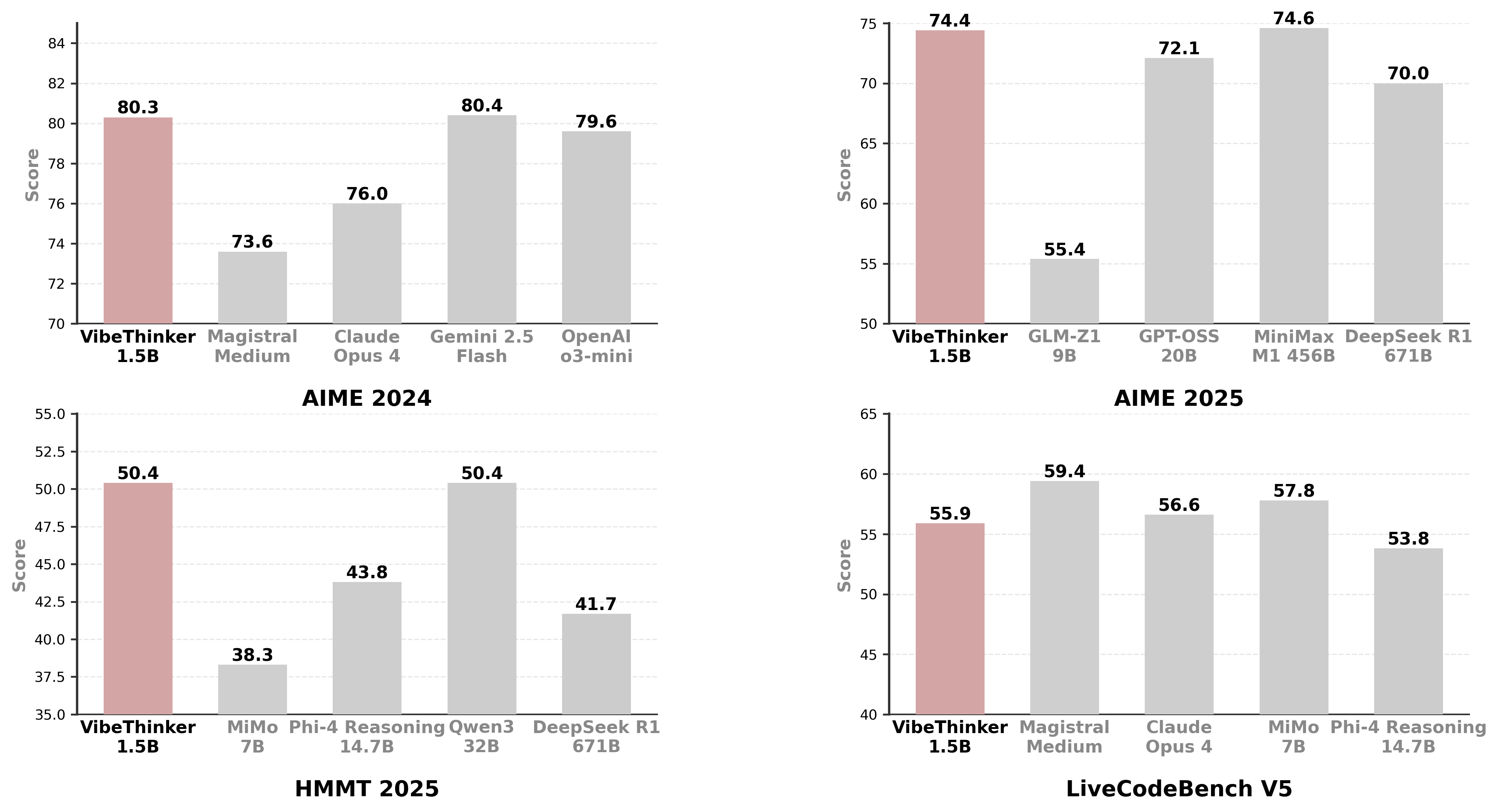
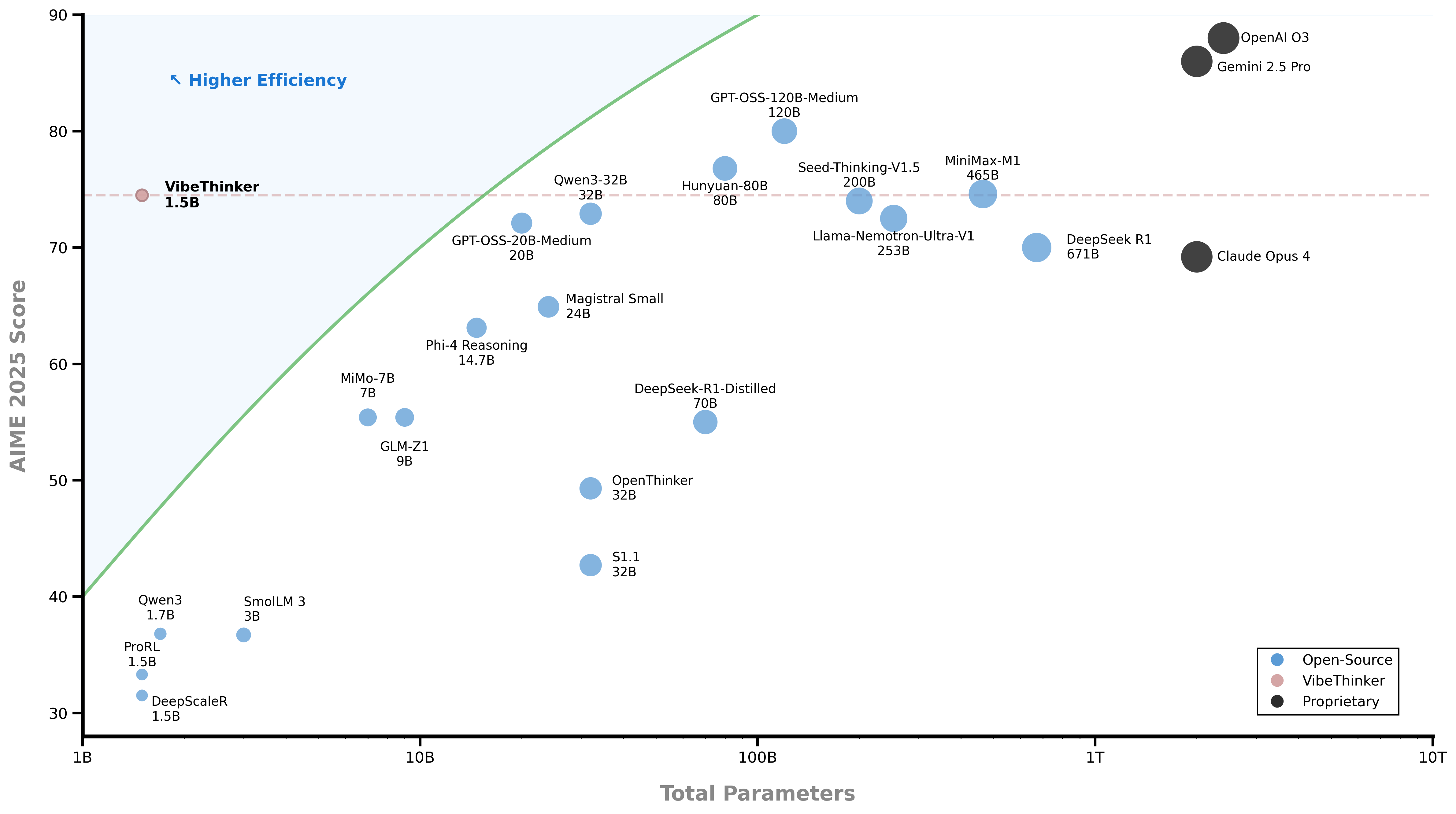
Abstract: Challenging the prevailing consensus that small models inherently lack robust reasoning, this report introduces VibeThinker-1.5B, a 1.5B-parameter dense model developed via our Spectrum-to-Signal Principle (SSP). This challenges the prevailing approach of scaling model parameters to enhance capabilities, as seen in models like DeepSeek R1 (671B) and Kimi k2 (>1T). The SSP framework first employs a Two-Stage Diversity-Exploring Distillation (SFT) to generate a broad spectrum of solutions, followed by MaxEnt-Guided Policy Optimization (RL) to amplify the correct signal. With a total training cost of only $7,800, VibeThinker-1.5B demonstrates superior reasoning capabilities compared to closed-source models like Magistral Medium and Claude Opus 4, and performs on par with open-source models like GPT OSS-20B Medium. Remarkably, it surpasses the 400x larger DeepSeek R1 on three math benchmarks: AIME24 (80.3 vs. 79.8), AIME25 (74.4 vs. 70.0), and HMMT25 (50.4 vs. 41.7). This is a substantial improvement over its base model (6.7, 4.3, and 0.6, respectively). On LiveCodeBench V6, it scores 51.1, outperforming Magistral Medium's 50.3 and its base model's 0.0. These findings demonstrate that small models can achieve reasoning capabilities comparable to large models, drastically reducing training and inference costs and thereby democratizing advanced AI research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VibeThinker-1.5B, a small AI model (with 1.5 billion parameters) that can think and reason very well—especially in math and coding—while costing much less to train than giant models. The main idea is that with smart training focused on diversity and careful reinforcement learning, a tiny model can reach reasoning abilities close to huge, expensive models.
What questions does the paper ask?
The paper explores simple but important questions:
- Can a small AI model reason as well as much larger ones?
- If yes, what kind of training helps a small model think more clearly and solve tough problems?
- Can we reduce training costs and energy use while keeping high performance?
How did the researchers approach it?
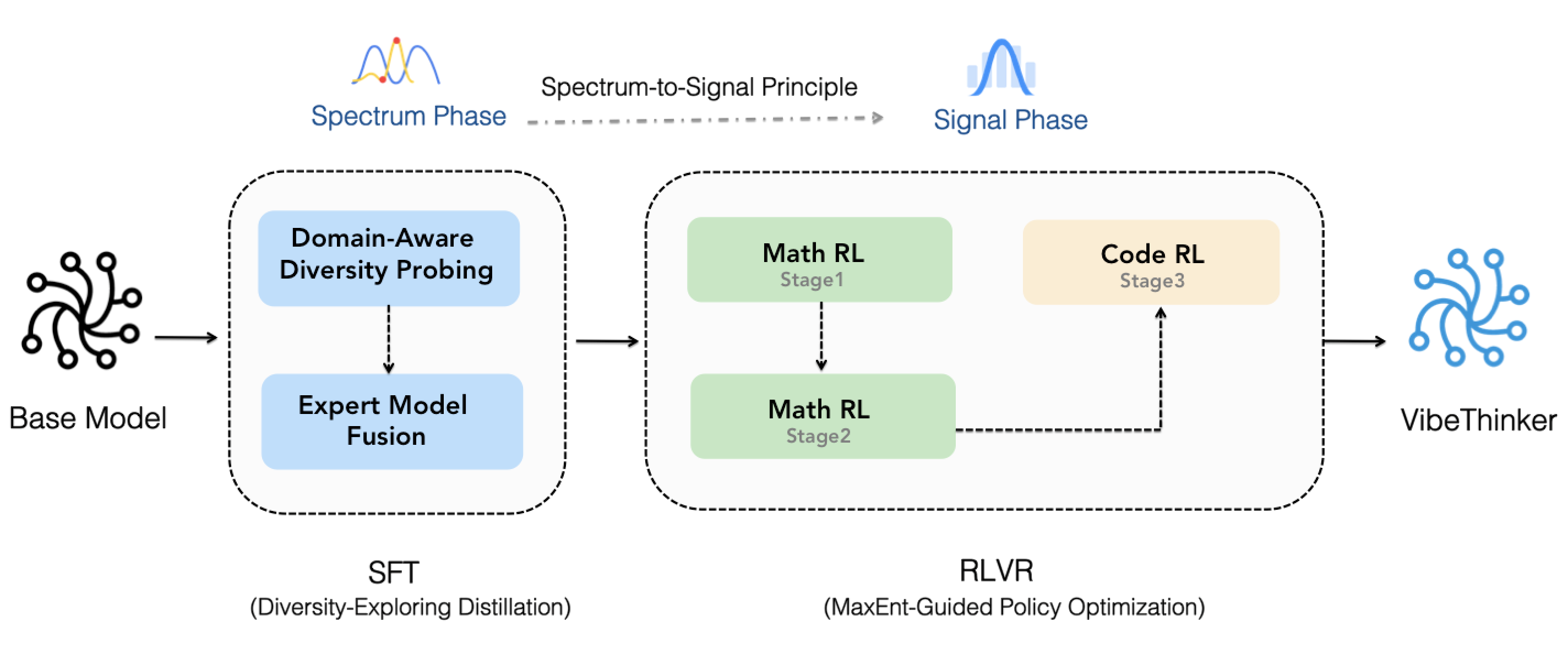
The team used a two-step training plan they call the “Spectrum-to-Signal Principle.” Think of it like tuning a radio:
- First, “find many stations” (build a wide spectrum of possible answers).
- Then, “lock onto the clearest station” (amplify the best answer).
Step 1: Supervised Fine-Tuning (SFT) — the “Spectrum Phase”
- What it is: The model learns from example questions and answers (like a student studying solved problems).
- Goal: Not just “get one right answer” but “produce many different good answers.” This increases variety, which helps later learning.
- Key idea: Maximize “Pass@K”—that’s the chance that at least one of K attempts is correct. Imagine you take 10 shots at a goal; even if some miss, you want at least one to score.
- How they did it:
- Domain-Aware Diversity Probing: They split math into sub-areas (like algebra, geometry, calculus, statistics). For each area, they tracked which checkpoints produced the most diverse correct solutions.
- Expert Model Fusion: They combined these “specialist” checkpoints (each good at one sub-area) into one model—like assembling a team of experts into a single brain.
Step 2: Reinforcement Learning (RL) — the “Signal Phase”
- What it is: The model tries solving problems and gets a reward when it’s correct, learning to prefer successful reasoning paths.
- Goal: Pick and amplify the best answers from the diverse pool created in SFT.
- Key idea: MGPO (MaxEnt-Guided Policy Optimization)
- “MaxEnt” means focusing on problems where the model is most unsure (around 50/50 right vs. wrong). That’s the sweet spot for learning—hard enough to teach, but not impossible.
- The algorithm gives more weight to these uncertain problems so the model learns faster and more efficiently.
Keeping tests fair: Data decontamination
- The team carefully removed any training data that overlapped with test questions (so the model couldn’t just memorize answers).
- They used text cleaning and n-gram matching to avoid leaks.
- Despite concerns in other studies, their model performed well on 2025 benchmarks that weren’t available during base model training, suggesting genuine generalization.
Cost and efficiency
- Training used about 3,900 GPU hours on H800s, costing under $8,000—far cheaper than large models that can cost hundreds of thousands of dollars.
- Small models are also cheaper to run and can even work on phones or cars.
What did they find?
In simple terms: The tiny model did great.
Here are the highlights from tough benchmarks:
- Math:
- AIME 2024: 80.3
- AIME 2025: 74.4
- HMMT 2025: 50.4
- These scores beat or match very large reasoning models like DeepSeek R1 (671B parameters) and are close to some top commercial systems.
- Coding:
- LiveCodeBench v6: 51.1
- This is competitive with big-name models and much higher than the base model (which scored 0.0 before training).
- Knowledge (GPQA Diamond):
- 46.7
- This is lower than giant general-purpose models, showing small models still struggle with broad encyclopedic knowledge.
Why this matters:
- The model is 100×–600× smaller than many leading systems but still reasons very well.
- It costs much less to train and run, making advanced AI more accessible to researchers, schools, and startups.
Why is this important?
- It challenges the idea that “bigger is always better” for reasoning.
- It shows that careful training—first encouraging diverse answers, then rewarding the best ones—can unlock strong logic in small models.
- It makes AI research less dependent on huge compute budgets, allowing more people to participate and innovate.
- It could reduce energy use and environmental impact by avoiding massive models when not needed.
Limitations and future directions
- General knowledge: The model still lags far behind very large models on broad, fact-heavy tests like GPQA. Improving small models’ world knowledge is an open challenge.
- Coding: While strong, performance trails the very best large models. Better base pretraining on code could help.
- Not a drop-in replacement: The authors release VibeThinker-1.5B mainly as proof that small models can reason well, not as a final product.
Takeaway
With smart training focused on diversity first (many ways to solve a problem) and signal later (boost the best solutions), a small model can think like a big one in math and coding—at a fraction of the cost. This approach could make advanced AI more affordable, fair, and widely available, while pushing the field to rethink the “bigger is better” mindset.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Reproducibility details are insufficient: exact training datasets (names, counts, token totals), proprietary synthetic data generation recipes, prompts, and verification scripts are not released; seeds, training logs, and full hyperparameters (optimizer, learning rates, batch sizes, schedules, gradient clipping, precision/AMP settings) are missing.
- RL specifics are under-specified: GRPO/MGPO group size G, rollout counts per query, KL penalties, clipping ε, entropy regularization λ schedule, checkpointing cadence, early stopping criteria, and reference policy choice are not detailed.
- Verifier design is unclear: math answer normalization, unit handling, tolerance for numeric equality, symbolic equivalence checking, and how flaky or non-deterministic code execution is handled (sandboxing, time/memory limits, retries) are not documented.
- “Pass@K-optimized SFT” lacks a concrete training objective: the paper selects checkpoints by Pass@K on probe sets but does not specify a loss or procedure that directly optimizes Pass@K during SFT; it is unclear how to implement this beyond checkpoint selection without overfitting.
- Domain partitioning and probe-set construction are under-defined: how sub-domains are chosen beyond a coarse math split, how this generalizes to coding (and its sub-domains), and how probe-set quality, difficulty, and representativeness are validated are not described.
- Quality and biases of LLM-generated probing sets are not assessed: there is no error auditing of generated items/answers, nor safeguards against teacher-style leakage that could bias selection or subsequent training.
- Expert model fusion lacks ablations: why unweighted parameter averaging is preferred, whether alternative mergers (e.g., Fisher-weighted merges, task-balanced weights) perform better, and how cross-domain interference is mitigated are open.
- Alternative integration strategies are not explored: ensembling, routing/MoE, or sparse adapters for specialists vs. raw parameter merges are not compared, leaving unclear whether merging is optimal for diversity retention.
- SSP (Spectrum-to-Signal Principle) claims need causal evidence: ablations isolating (i) domain-aware diversity probing, (ii) fusion, and (iii) MGPO are missing; it is unknown which component contributes how much and on which tasks.
- MGPO theory and robustness are unproven: no convergence guarantees, sensitivity analyses for noisy p_c estimates (especially when G is small), smoothing or Bayesian estimation of uncertainty, and trade-offs between exploration focus and catastrophic forgetting are discussed.
- Curriculum side-effects in MGPO are unexplored: focusing on p_c≈0.5 may neglect very hard or very easy examples, potentially harming tail performance or calibration; mechanisms for balanced coverage/replay are not described.
- Catastrophic forgetting across RL stages (math→code) is not evaluated: retention metrics, rehearsal buffers, or interleaved training strategies are absent.
- Evaluation comparability is imperfect: decoding settings, sampling budgets, and prompt formats differ across baselines; variance/confidence intervals, seed sweeps, and standardized test-time compute budgets (e.g., same n-samples and max tokens) are not reported.
- Test-time compute trade-offs are not quantified: impact of number of samples K, temperature, and CoT length on accuracy and latency is not systematically analyzed; practical deployment budgets vs. accuracy are unclear.
- Long-context claims lack validation: the model is trained to 16K/32K and evaluated with max 40K tokens, but there is no targeted long-context benchmark (e.g., recall over 32K) or analysis of memory usage, throughput, and degradation with context length.
- Generalization beyond math/code is underexplored: performance on commonsense reasoning, long-form QA, multilingual tasks, legal/medical domains, tool-augmented tasks, and agentic settings is not reported.
- Knowledge weakness is acknowledged but unaddressed: strategies to close the 20–40 point GPQA gap (e.g., retrieval augmentation, knowledge-tuned pretraining, tool use) are left as future work without experiments or roadmaps.
- Safety, alignment, and robustness are not evaluated: jailbreak resistance, harmful content, hallucination, calibration, refusal behavior, and adversarial robustness are not assessed; effects of diversity optimization on safety are unknown.
- Data decontamination is limited: 10-gram matching is likely insufficient for semantic leakage; no embedding-based or paraphrase-aware checks, no public contamination reports, and no itemized lists of removed overlaps are provided.
- Base-model contamination concerns remain unresolved: arguments rely on benchmark release timelines rather than thorough base-model audits; no independent replication with a different base model to rule out latent leakage.
- Cost and carbon claims are partial: pretraining costs are externalized to the base model; H800 cost assumptions and energy/carbon accounting are not provided; inference cost vs. accuracy curves (as sampling/computation increases) are missing.
- Deployment feasibility is not demonstrated: real edge-device benchmarks (latency, memory footprint, quantization effects, batch throughput) and accuracy impact under quantization are absent.
- Error analysis is missing: no qualitative or quantitative breakdown of failure modes (by math topic, code language/library, error types), making it hard to target future improvements.
- Reward design beyond outcome correctness is unexplored: stepwise/process supervision vs. outcome-only rewards, partial-credit schemes, and robustness to spurious success are not tested.
- Data/source licensing and compliance are not addressed: licenses for open datasets, teacher models, and generated probes, and compatibility with the released model license, are unspecified.
- Stability across random seeds is unknown: no report of run-to-run variance or failure rates; robustness of SSP/MGPO under perturbations (e.g., noisy verifiers, different probe sets) is untested.
- Scalability of SSP/MGPO to other modalities/tasks is untested: applicability to multimodal reasoning, planning, or non-verifiable tasks (where automatic reward is hard) is an open question.
- Potential negative effects of diversity-first SFT are unmeasured: whether maximizing diversity harms calibration, coherence, or truthfulness in non-reasoning tasks is not studied.
- Benchmarks’ differing definitions are acknowledged but not harmonized: LiveCodeBench v6 differences (131 vs. 454 problems) can bias comparisons; results under both definitions or a standardized suite are not provided.
- Retained capabilities on general chat/instruction-following are unknown: effects of SSP/MGPO on everyday assistant quality (helpfulness, harmlessness, follow-up coherence) are not evaluated.
- Architectural details are omitted: tokenizer, positional encoding scheme for long context, normalization layers, RoPE scaling method, and architectural modifications (if any) to the Qwen2.5-Math-1.5B base are not described.
- Hyperparameter selection for domain split and fusion is ad hoc: the choice of N=4 math sub-domains and equal weights w_i lacks justification; automatic or data-driven selection is not explored.
- Correlation between Pass@K during SFT and downstream RL gains is asserted but not quantified: no statistical analysis showing how increases in Pass@K predict RL improvements across tasks/datasets.
- Tool use is not considered: calculator, code interpreter, or retrieval integration (which may help knowledge tasks) is absent; the interaction of SSP/MGPO with tool-augmented policies is an open area.
- Reliability under imperfect verifiers is not studied: sensitivity to false positives/negatives in verifiers and mitigation strategies (e.g., consensus checking, cross-verification) are not explored.
Practical Applications
Overview
The paper presents VibeThinker-1.5B, a compact 1.5B-parameter reasoning model that achieves state-of-the-art performance in mathematics and competitive coding benchmarks at a fraction of the cost and energy of very large models. Its core methodological contributions are:
- Spectrum-to-Signal Principle (SSP): Decouples supervised fine-tuning (SFT) and reinforcement learning (RL) objectives, optimizing SFT for output diversity (high Pass@K) and using RL to amplify the correct signal from that spectrum.
- Two-Stage Diversity-Exploring Distillation: Domain-aware diversity probing to select specialist SFT checkpoints, followed by expert model fusion (model merging) to create a unified spectrum-optimized model.
- MaxEnt-Guided Policy Optimization (MGPO): An RL framework that prioritizes problems with maximal uncertainty (near 50% correctness during rollouts), focusing training where learning gains are greatest.
Below are practical applications derived from these findings, grouped by deployment horizon. Each item notes sector(s), actionable use cases, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These applications can be deployed now or with modest engineering effort, leveraging the released model and methods.
- Sector: Software engineering
- Application: On-device or low-cost coding assistants that focus on verifiable tasks (unit-test generation, bug localization, algorithmic scaffolding).
- Tools/products/workflows:
- IDE plugins integrating VibeThinker-1.5B for multi-sample suggestions with Pass@K-based acceptance.
- Test harnesses (e.g., LiveCodeBench-style verifiers) for automatic correctness checks.
- vLLM-backed microservices with temperature/top_p tuned for diversity.
- Assumptions/dependencies:
- Reliable verifier suites and coverage; tasks with binary rewards (compile/run tests).
- Adequate context length and repository indexing; quantization (int4/int8) for edge deployment.
- Sector: Education
- Application: Math tutoring and problem-solving assistants for high school/undergrad contest-style problems (AIME/HMMT-type), step-by-step reasoning with validation.
- Tools/products/workflows:
- Mobile apps offering offline math help powered by a quantized 1.5B model.
- Problem set generators with auto-checkers and solution diversity (Pass@K-guided hints).
- Assumptions/dependencies:
- Focus on math/coding domains where verifiers are robust; safety and pedagogy layers required.
- Limited encyclopedic knowledge; curriculum alignment is needed.
- Sector: AI platforms/MLOps
- Application: SSP-aligned post-training workflow to boost reasoning in existing small models.
- Tools/products/workflows:
- “Pass@K-first SFT” trainer that probes subdomains, tracks diversity scores, and selects specialist checkpoints.
- Expert model fusion pipelines (parameter merging with weight control).
- MGPO scheduler as a drop-in replacement for standard GRPO/PPO advantage weighting.
- Assumptions/dependencies:
- RLHF infrastructure (TRL or equivalent), reward models/verifiers, multi-rollout sampling for uncertainty estimation.
- Domain partitioning and probing datasets (auto-generated or curated).
- Sector: Academia (research and teaching)
- Application: Low-cost replication and extension of reasoning research without large compute budgets.
- Tools/products/workflows:
- Course labs that demonstrate SSP/MGPO; open notebooks showing Pass@K vs Pass@1 trade-offs.
- Community benchmarks with strict data decontamination pipelines (n-gram filters and normalization).
- Assumptions/dependencies:
- Access to commodity GPUs; clean separation of training/evaluation data; transparent reporting.
- Sector: Privacy-first consumer apps
- Application: On-device math/coding assistants that run offline for privacy (e.g., homework help, small script generation).
- Tools/products/workflows:
- Quantized model deployments in mobile/desktop apps; model-card disclaimers and guardrails.
- Assumptions/dependencies:
- Long-context support in local runtimes; battery/memory constraints; licensing compliance.
- Sector: Operations analytics (logistics/energy/finance)
- Application: Internal analytics assistants for schematic problem solving (e.g., numerical reasoning, formula derivations, scenario testing).
- Tools/products/workflows:
- “Reasoning microservice” that returns diverse candidate solutions and selects via verifiers.
- Assumptions/dependencies:
- Domain-specific validators and structured inputs; limited general-knowledge coverage acknowledged.
- Sector: Policy and sustainability
- Application: Procurement and sustainability teams evaluate small-model strategies to reduce cost and carbon footprint.
- Tools/products/workflows:
- CO2 and cost calculators comparing 1.5B vs 100B+ deployments.
- Internal guidelines to pilot small-model-first approaches for math/coding workflows.
- Assumptions/dependencies:
- Task suitability (verifiable domains); performance baselines; existing governance processes.
Long-Term Applications
These require further research, scaling, domain adaptation, or integration with external systems.
- Sector: Healthcare
- Application: Domain-specialized tiny reasoning models for clinical decision support or protocol adherence with verifiable steps.
- Tools/products/workflows:
- SSP/MGPO pipelines adapted to medical subdomains (diagnostics, dosing), with strict verifiers and expert oversight.
- Assumptions/dependencies:
- High-stakes safety, regulatory approval, medical-grade datasets, robust verification beyond binary correctness.
- Sector: Robotics and autonomous systems
- Application: On-device planning and task sequencing using small reasoning models for embedded systems.
- Tools/products/workflows:
- Integration with motion planners; ensemble of subdomain specialists (perception, planning, manipulation) merged via expert model fusion.
- Assumptions/dependencies:
- Real-time constraints; sensory grounding; safety certifications; domain-specific reward functions.
- Sector: Finance and legal compliance
- Application: On-prem reasoning engines for compliance checks and explainable procedural reasoning.
- Tools/products/workflows:
- Verifier-backed rule checking (e.g., policy-as-code), Pass@K exploration to surface diverse interpretations before final validation.
- Assumptions/dependencies:
- Formal rule encodings; strong knowledge coverage (current gap in GPQA-like domains); auditability and governance.
- Sector: Mobile silicon and edge AI
- Application: “Reasoning co-processor” workflows in NPUs/TPUs to bring long-chain reasoning offline.
- Tools/products/workflows:
- Model compression, sparsity, and streaming long-context inference; API-level OS integration for apps.
- Assumptions/dependencies:
- Hardware support for long contexts; memory bandwidth; efficient sampling; sustained accuracy under quantization.
- Sector: Education (advanced)
- Application: Personalized curricula and proof tutors that adaptively select problems at maximum uncertainty (MGPO-style).
- Tools/products/workflows:
- Pedagogical agents that tune difficulty via entropy deviation, provide diverse hints, and verify solutions stepwise.
- Assumptions/dependencies:
- Longitudinal learning data, educational efficacy studies, content licensing, safety in student-facing systems.
- Sector: Energy and sustainability policy
- Application: Data-center decarbonization strategies prioritizing small-model workloads for verifiable tasks.
- Tools/products/workflows:
- Policy frameworks that incentivize small-model-first deployments, with reporting standards on compute and emissions.
- Assumptions/dependencies:
- Clear task classification; performance guarantees; industry adoption; measurement standardization.
- Sector: AI standards and governance
- Application: Industry-wide decontamination and evaluation protocols for reasoning benchmarks (math/code).
- Tools/products/workflows:
- Open-source tooling for text normalization, n-gram filtering, benchmark lineage tracking; Pass@K-aware reporting standards.
- Assumptions/dependencies:
- Community consensus, benchmark stewardship, transparent releases.
- Sector: AI research platforms
- Application: Swarm-of-small-models and mixture-of-experts built on SSP (subdomain specialists merged and optimized via MGPO).
- Tools/products/workflows:
- Dynamic gating, specialist discovery via diversity probing, periodic model merging and RL cycles.
- Assumptions/dependencies:
- Stable merging without catastrophic interference; scalable uncertainty estimation; multi-domain verifiers.
- Sector: General knowledge augmentation
- Application: Bridging the small-model gap on encyclopedic knowledge while preserving reasoning efficiency.
- Tools/products/workflows:
- Targeted pretraining/continued pretraining; retrieval-augmented reasoning with verified sources; knowledge-aware reward models.
- Assumptions/dependencies:
- High-quality corpora; retrieval pipelines; careful alignment to avoid hallucinations.
Cross-cutting assumptions and dependencies
- The strongest immediate gains are in domains with reliable, automated verifiers (math/code). Moving beyond these requires domain-specific validation protocols and richer reward models.
- MGPO effectiveness depends on accurate uncertainty estimation (sufficient group rollouts) and stable RL optimization under entropy-based weighting.
- SSP’s benefits rely on robust domain partitioning, diversity probing, and model merging that avoids degradation; merging may need weight tuning rather than uniform averaging in some domains.
- Long-context inference and multi-sample generation must be supported efficiently on target hardware; quantization and memory optimizations are key for edge deployment.
- Safety, security, and governance layers are necessary for real-world products, particularly in high-stakes sectors (healthcare, finance, robotics).
- The authors note the model is released to demonstrate capability rather than as a turnkey product; productization requires additional engineering, UX, guardrails, and ongoing evaluation.
Glossary
- 10-gram matching: An n-gram-based text similarity technique used to detect overlap between datasets for decontamination. "We employed 10-gram matching to identify and exclude training samples potentially overlapping semantically with evaluation sets."
- Advantage estimation: In policy-gradient RL, the computation of how much better an action is than a baseline, guiding gradient updates. "replacing the critic-based advantage estimation with a group-relative mechanism."
- Autoregressive conditional distribution: A sequence model distribution that predicts each token conditioned on previous tokens. "The model defines an autoregressive conditional distribution over response sequences."
- Binary rewards: Reward signals that take only two values (e.g., correct or incorrect) for evaluation or training. "using strictly binary rewards."
- Chain-of-thought (CoT): A reasoning technique where models generate intermediate steps to solve complex problems. "extended chain-of-thought processes."
- Clipped surrogate loss: A PPO-style objective that limits policy updates to stabilize training. "The optimization objective is formulated as a clipped surrogate loss, averaged over tokens and responses within the group."
- Context window: The maximum number of tokens a model can consider during inference. "beginning with mathematical reasoning within a 16K context window, expanding to 32K"
- Cross-entropy loss: A standard supervised learning objective measuring discrepancy between predicted and target distributions. "The training objective is to minimize the cross-entropy loss:"
- Curriculum learning mechanism: A training strategy that orders examples by difficulty to improve learning efficiency. "This creates an implicit curriculum learning mechanism where the model is automatically steered towards focusing its gradient updates on questions for which its current performance is most ambiguous."
- Data decontamination: Procedures to remove training-test overlap to ensure fair evaluation. "we implemented rigorous data decontamination procedures on the training data during both the Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) stages."
- Domain-Aware Diversity Probing: A method to identify subdomain-specific checkpoints that maximize solution diversity. "Initially, 'Domain-Aware Diversity Probing' is conducted to analyze broad domains (e.g., mathematics, code) and identify sub-domains."
- Diversity-Exploring Distillation: A distillation approach that explicitly encourages diverse solutions rather than single-answer accuracy. "we employ a 'Diversity-Exploring Distillation' methodology to cultivate a broad spectrum of diverse solutions"
- Entropy Deviation Regularization: A weighting scheme that penalizes deviation from maximum-entropy uncertainty to prioritize valuable training examples. "We term this 'Entropy Deviation Regularization'."
- Expert Model Fusion: Combining specialist model checkpoints into a single model to aggregate capabilities. "Subsequently, 'Expert Model Fusion' consolidates these optimal checkpoints using techniques like model merging."
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages relative to a group of sampled responses, removing the need for a critic. "Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm that extends Proximal Policy Optimization (PPO) by replacing the critic-based advantage estimation with a group-relative mechanism."
- Information leakage: Unintended inclusion of evaluation content in training data, inflating measured performance. "thereby preventing assessment biases caused by data contamination" / "information leakage risks"
- Kullback-Leibler (KL) divergence: A measure of difference between probability distributions, used as a regularizer or distance. "We define the 'Max-Entropy Deviation Distance', , as the Kullback-Leibler (KL) divergence"
- Large Reasoning Model (LRM): A paradigm for models specialized in logical reasoning, often trained with RL and CoT. "OpenAI o1 pioneered the Large Reasoning Model (LRM) paradigm"
- Long-CoT: Long-form chain-of-thought capabilities that enable extended reasoning sequences. "Advanced reasoning models featuring Long-CoT capabilities are developed by both proprietary and open-source communities."
- Max-Entropy Deviation Distance: A KL-based metric measuring deviation from ideal 50% correctness to gauge uncertainty. "We define the 'Max-Entropy Deviation Distance', "
- MaxEnt-Guided Policy Optimization (MGPO): An RL framework that prioritizes training on high-uncertainty problems via entropy-based weighting. "We propose 'MaxEnt-Guided Policy Optimization (MGPO)', a novel framework that leverages information-theoretic principles"
- Maximum entropy: The state of highest uncertainty in a distribution, used to identify optimal exploration points. "According to the principle of maximum entropy, this distribution is most 'uninformed' or uncertain when its entropy is maximized."
- Model merging: Parameter-level combination of multiple model checkpoints to integrate diverse skills. "using techniques like model merging."
- Model-task alignment: The degree of match between a model’s innate capabilities and the target task requirements. "it emphasizes the critical role of model-task alignment—defined as the congruence between a model's inherent capabilities and the requirements of a task."
- Multi-path exploration: Exploring multiple solution trajectories during training/inference to improve accuracy. "guided by refined reward models and multi-path exploration"
- Nucleus sampling: A decoding strategy that samples from the smallest probability mass whose cumulative sum exceeds top_p. "nucleus sampling with top_p = 0.95"
- On-policy learning: RL training using data sampled from the current policy, enabling adaptive curricula. "prioritize the most pedagogically valuable problems for on-policy learning."
- Pass@1: The probability a single sampled solution is correct; a single-shot accuracy metric. "maximize single-shot accuracy (Pass@1)"
- Pass@K: The probability that at least one of K independently generated solutions is correct; a diversity-sensitive metric. "Current research commonly adopts the Pass@K metric as a key indicator for assessing the diversity of outputs"
- Proximal Policy Optimization (PPO): A popular policy-gradient RL algorithm using clipped objectives for stability. "extends Proximal Policy Optimization (PPO)"
- Reference policy: A baseline policy distribution used to regularize updates (e.g., via KL penalties). "a KL-divergence penalty relative to a reference policy is often added as a regularizer."
- Reinforcement Learning (RL): A training paradigm where models learn behaviors by maximizing rewards. "Reinforcement Learning (RL)"
- Reinforcement learning from human feedback (RLHF): RL framework using human-provided signals to shape model behavior. "In reinforcement learning from human feedback (RLHF), particularly for complex reasoning tasks, the selection of training data is paramount."
- Reinforcement learning with verifiable rewards (RLVR): RL setup where rewards come from automatic verification of outputs. "reinforcement learning with verifiable rewards (RLVR) stages"
- Reward models: Learned functions estimating the quality of model outputs, guiding RL training. "guided by refined reward models"
- RL Scaling: Increasing compute or training intensity in RL to improve model performance. "These efforts established both RL Scaling and test-time scaling as key optimization strategies."
- Rollouts: Sampled trajectories or outputs generated by a policy during RL for training or evaluation. "low-probability yet correct reasoning traces sampled during rollouts."
- Scaling laws: Empirical relationships describing how performance scales with model size or compute. "The LRM paradigm has thus redefined scaling laws for reasoning-centric training"
- Shannon entropy: An information-theoretic measure of uncertainty used to weight training examples. "While directly using the Shannon entropy is an intuitive approach"
- Signal Phase: The RL stage that amplifies correct answers from the diverse spectrum produced by SFT. "The RL stage, designated as the 'Signal Phase', is guided by the 'MaxEnt-Guided Policy Optimization (MGPO)' framework."
- Spectrum Phase: The SFT stage focused on generating a diverse set of plausible solutions. "The SFT stage, designated as the 'Spectrum Phase', implements this principle through a 'Two-Stage Diversity-Exploring Distillation' methodology."
- Spectrum-to-Signal Principle (SSP): A training framework that separates diversity creation (SFT) from signal amplification (RL). "we introduce the 'Spectrum-to-Signal Principle (SSP)', a theoretical framework that redefines the roles of and the synergy between SFT and RL."
- Test-time scaling: Allocating more compute during inference (e.g., more samples) to boost accuracy. "These efforts established both RL Scaling and test-time scaling as key optimization strategies."
- Token-level probability ratio: The per-token ratio of new vs. old policy probabilities used in PPO-style updates. "where $r_{i,t}(\theta) = \frac{\pi_\theta(y_{i,t}|q, y_{i,<t})}{\pi_{\theta_{\text{old}}(y_{i,t}|q, y_{i,<t})}$ is the token-level probability ratio"
- vLLM: An efficient inference engine/backend for LLMs. "We use vLLM as the inference backend"
Collections
Sign up for free to add this paper to one or more collections.