Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
Abstract: This work introduces Falcon-H1R, a 7B-parameter reasoning-optimized model that establishes the feasibility of achieving competitive reasoning performance with small LLMs (SLMs). Falcon-H1R stands out for its parameter efficiency, consistently matching or outperforming SOTA reasoning models that are $2\times$ to $7\times$ larger across a variety of reasoning-intensive benchmarks. These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy. This unique blend makes Falcon-H1R-7B a practical backbone for scaling advanced reasoning systems, particularly in scenarios requiring extensive chain-of-thoughts generation and parallel test-time scaling. Leveraging the recently introduced DeepConf approach, Falcon-H1R achieves state-of-the-art test-time scaling efficiency, offering substantial improvements in both accuracy and computational cost. As a result, Falcon-H1R demonstrates that compact models, through targeted model training and architectural choices, can deliver robust and scalable reasoning performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Falcon-H1R, a small-but-smart AI LLM (7 billion parameters) designed to solve tricky problems by reasoning through them step by step. Its big idea: with the right training and design, you don’t need a huge model to get great results. Falcon-H1R thinks in parallel (like brainstorming multiple solutions at once) and knows when to stop wasting time on bad ideas, which makes it fast, accurate, and cheaper to run.
What questions were the researchers asking?
They focused on three simple questions:
- Can a compact model (only 7B parameters) reason as well as much larger models?
- How can we train it so it learns strong step-by-step thinking without making the model bigger?
- How can we make “test-time scaling” efficient—meaning, when the model tries many solution paths in parallel, can it keep the good ones and stop the bad ones early to save time and money?
How did they build and train the model?
The model’s design (hybrid architecture)
Think of two ways to read and understand a long text:
- Transformers are like readers with a superpower: they can “look at” all parts of the text at once to decide what matters (great for accuracy).
- State Space Models (like Mamba) are like note-takers who process text in order and keep a smart running summary (great for speed and memory).
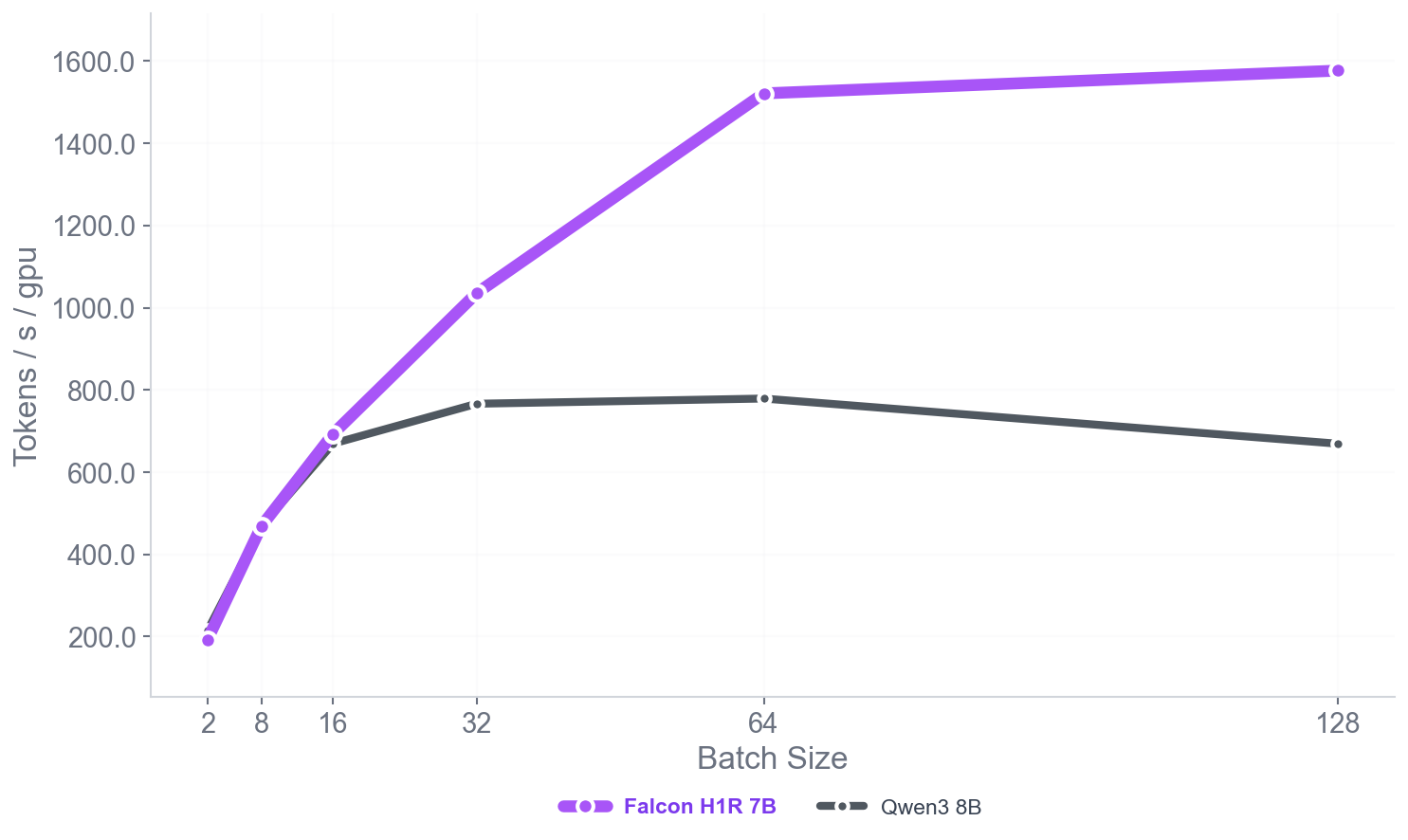
Falcon-H1R mixes both in a “hybrid” design to get the best of both worlds: fast and memory-friendly like Mamba, but precise like Transformers. This helps it handle:
- Long inputs (very long problems with many steps)
- Big batches (many solutions in parallel)
- Low latency (fast responses)
Training steps (teach first, then practice with rewards)
They used two main training stages:
- Supervised Fine-Tuning (SFT): The model studies lots of worked examples with step-by-step “chain-of-thought” solutions in math, coding, and science. This is like learning from a well-annotated textbook.
- Reinforcement Learning (RL): The model practices and gets points for correct answers. For example:
- Math: the final answer must match the correct one (checked with math tools).
- Code: the program must pass test cases (run in a secure sandbox).
- Science: an evaluator checks if the answer is correct when exact matching is hard.
Key training ideas that helped:
- Use many solution examples per problem (more “rollouts”) so the model sees multiple ways to solve tough questions.
- Focus on harder problems more than easy ones (difficulty-aware weighting).
- Prefer one consistent “teacher” style over mixing many (less confusion).
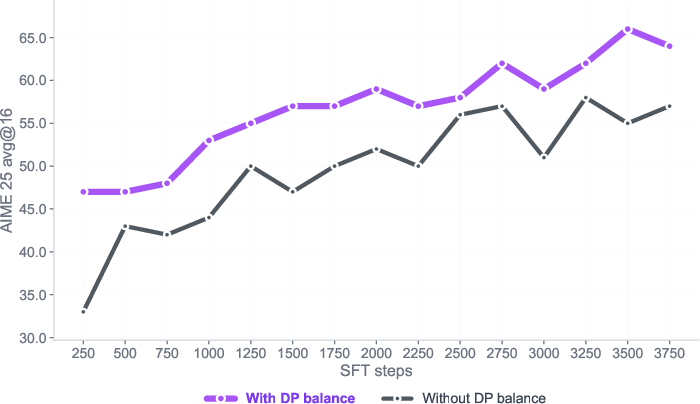
- Balance short and long examples so every token (word piece) contributes fairly to learning. Think of it like grading per sentence rather than per essay, so long essays don’t dominate.
Careful data curation (quality over quantity)
They filtered and verified data so the model mostly learns from correct, challenging solutions:
- Kept correct math answers (or high-quality hard traces even when not easily verifiable).
- For code, they used correct programs and ran tests to check them.
- Removed low-quality, empty, or broken examples.
Making parallel “test-time thinking” efficient
When solving a hard problem, Falcon-H1R can:
- Try many solution paths in parallel (like having many classmates brainstorm).
- Use a method called DeepConf to watch confidence and “prune” weak paths early. Imagine a teacher walking around and stopping students who are clearly off track so resources go to the most promising work.
This saves tokens (fewer generated words) and time while keeping or even improving accuracy.
What did they find?
Here are the standout results (using standardized reasoning benchmarks):
- Strong base accuracy for a small model:
- AIME24 (math): 88.1%
- AIME25 (math): 83.1%
- HMMT25 (math): 64.9%
- AMO-Bench (math): 36.3%
- LiveCodeBench v6 (code): 68.6%
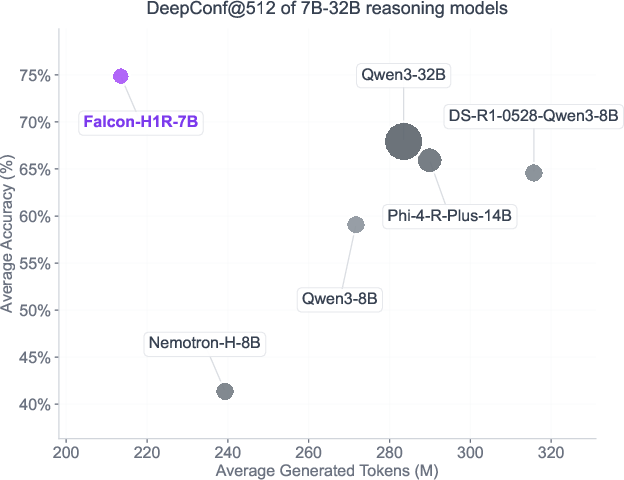
- Competes with or beats bigger models 2×–7× its size across several reasoning tests.
- With test-time scaling (DeepConf), it gets both higher accuracy and lower cost. For example, on AIME25 it reached 96.7% while using about 38% fewer tokens than a strong 8B baseline in the same setup.
Why this matters:
- It shows careful training and architecture can beat “just make it bigger.”
- It proves you can get top reasoning quality while spending less compute at inference time.
Why it matters and what could happen next
Falcon-H1R suggests a new, practical path for building smart AI:
- Smaller models can be powerful reasoners if you train them on the right kind of data and let them think in parallel efficiently.
- This lowers the cost of advanced reasoning (useful for education, coding help, science tasks, and more).
- The hybrid design plus smart test-time scaling (like DeepConf) makes it a strong backbone for systems that need to generate long, careful “chain-of-thought” answers quickly and cheaply.
In short, this work pushes the idea that “smart training + smart inference” can beat “bigger model,” opening the door to accessible, scalable reasoning AI that many people and organizations can actually use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects under-specified or unexplored that, if addressed, could strengthen claims and guide future work:
- Dataset transparency and reproducibility: The SFT/RL data mixtures are described qualitatively (domains, filtering, rollout counts), but the paper does not disclose dataset identities, sizes per source, licensing, provenance checks, or release plans. Without exact composition and versioning, results are hard to reproduce or audit for contamination.
- Benchmark contamination and leakage checks: Although RL data is stated to be disjoint from SFT data, there is no explicit contamination audit against evaluation sets (AIME24/25, HMMT25, AMO-Bench, GPQA-Diamond, LCB v6). A documented hash-based or semantic leakage analysis is needed.
- Generalization beyond math/code/science: Evaluation emphasizes math and code with modest coverage of scientific QA. There is no assessment on reasoning in commonsense (e.g., BigBench, StrategyQA), multi-step QA (e.g., HotpotQA), law, medicine, or real-world tasks requiring tool-use and retrieval.
- Multilingual reasoning and code language breadth: The format reward penalizes mixing languages, but the model’s multilingual performance (non-English math/code/science prompts) and support across programming languages beyond Python/C++ are not evaluated.
- Calibration and confidence quality: Claims of “well-calibrated confidence enabling early stopping” under DeepConf are not substantiated with calibration metrics (e.g., ECE, Brier score, AUROC/AUPRC of correctness vs. confidence) across domains and difficulty levels.
- TTS method diversity: Results rely on DeepConf@512; there is no comparison across other test-time scaling strategies (self-consistency, majority voting, Tree-of-Thoughts, ReAct, verifier-guided sampling, rejection sampling) or hybrid methods combining confidence pruning with verifiers.
- Failure modes in confidence pruning: The paper does not analyze cases where high-confidence but incorrect chains dominate early stopping, nor provide robustness strategies (e.g., adversarial examples, out-of-distribution tasks) to avoid catastrophic aggregation errors.
- Cost and throughput measurement rigor: “Fast inference” and “token efficiency” claims lack standardized cost reporting (wall-clock latency, energy, tokens generated per correct answer, throughput per GPU, memory footprint) with hardware/config detail and variance across batch sizes and context lengths.
- Hardware portability and scalability: Training and inference are reported on 256 H100 GPUs with specific parallelism (FSDP + CP=2 + Ulysses). It remains unclear how performance and efficiency transfer to more common hardware (A100, consumer GPUs) and smaller-scale deployments.
- Hybrid architecture attribution: The benefit of the Transformer–Mamba blocks for reasoning/TTS is asserted but not isolated via controlled baselines (pure Transformer with identical SFT/RL, ablations of SSM depth/placement, attention-SSM mixing ratios) to quantify architectural contribution vs. data/RL.
- Long-context behavior and degradation: While training uses 36K–48K tokens, there is no evaluation of reasoning accuracy vs. context length, memory use, and speed across long inputs, nor analysis of potential degradation or forgetting effects in multi-step contexts.
- Multi-turn tool-use effectiveness: The SFT strategy supervises only the final turn’s reasoning (except tool-calling). There is no evaluation on multi-turn tasks requiring state maintenance, iterative tool calls, or non-local dependencies, nor on the impact of excluding earlier turns’ CoT on performance.
- Safety, bias, and misuse: Safety appears only as a data category; there is no systematic safety evaluation (harmful content, bias, jailbreak robustness, code execution risks) or deployment mitigations. Long CoT exposure may exacerbate prompt injection or data exfiltration; no red-teaming results are provided.
- Science reward reliability: The LLM-as-judge for science tasks is reported ineffective but not analyzed (judge accuracy, inter-rater reliability, false positives/negatives). Alternatives (symbolic/verifiable pipelines, hybrid rules + LLM) and their impact remain unexplored.
- Reward hacking and robustness: The RLVR design (binary rewards; format penalties) could incentivize “answer-format gaming” or brittle correct-by-chance outputs. There is no audit for reward hacking, especially in code tasks (e.g., overfitting to sampled tests) or shortcut exploitation.
- RL stability and sensitivity: GRPO modifications (clip-high, no KL/entropy, TIS, CE on positives, cache/backfill) lack sensitivity analysis across seeds, hyperparameters, and datasets. Stability under different advantage distributions and the impact of removing regularizers are not quantified.
- Coverage under pass@k: The paper references pass@1 gains and literature on coverage but does not report pass@k (k>1) for the trained model across domains, leaving uncertainty about diversity and breadth of solvable problems post-RL.
- Domain mixing strategy generality: Findings that math-dominant mixtures transfer best are promising but limited; there is no exploration of adaptive curriculum (difficulty- or domain-aware schedules), nor validation on unseen domains to test the claimed transfer benefits.
- Aggregation decision policies: DeepConf thresholds and policies (e.g., pruning criteria, confidence aggregation, tie-breaking) are not detailed or auto-tuned per task. There is no method for learning aggregation policies jointly with the model or adapting them to task difficulty.
- Open-source artifacts and reproducibility: Custom codebase changes (Ulysses patches, balanced DP token normalization, Liger kernels, RL framework on verl, sandbox orchestration) are not confirmed as released, versioned, or documented. Without open artifacts, replication is constrained.
- Environmental and compute footprint: The training and TTS scaling compute/energy usage, carbon footprint, and cost per unit accuracy are not reported, limiting practical assessment of “efficiency” beyond relative token counts.
- Robustness to adversarial/distribution shifts: No stress tests are provided for adversarial prompts, noisy inputs, OOD math/code distributions, or degraded verification environments (e.g., partial tests, ambiguous ground truth).
- Practical deployment constraints: Memory fragmentation mitigations (torch.cuda.empty_cache) and training tricks are noted, but production inference considerations (context windowing, streaming, batching, caching strategies, failure recovery) and their effects on latency/accuracy are not studied.
- Licensing and model usage constraints: The paper links to a HF collection but does not specify licensing terms, CoT visibility settings, or constraints relevant for commercial/research use, nor discuss implications of releasing extensive reasoning traces.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the model’s demonstrated efficiency, training insights, and test-time scaling (TTS) capabilities. For each item, we note sectors, potential products/workflows, and dependencies/assumptions.
- Cost-efficient parallel reasoning backend for production LLM apps
- Sectors: software, education, research, enterprise AI platforms
- Tools/workflows: integrate Falcon-H1R-7B as the default “reasoning engine” behind a DeepConf-style confidence-pruned, multi-sample inference pipeline to maximize accuracy per token; expose dynamic budget knobs (number of chains, early stopping) per request
- Dependencies/assumptions: availability of GPU or high-memory CPU inference; well-calibrated confidence scores; latency/throughput budgets for parallel rollouts
- IDE coding copilot with verifier-in-the-loop
- Sectors: software engineering
- Tools/products: VS Code/JetBrains extension that samples multiple candidate patches/snippets, runs unit tests via a sandbox (e.g., Sandbox-Fusion) and returns the highest-confidence fix with minimal token cost
- Dependencies/assumptions: reliable, secure code execution sandbox; representative tests; organizational policy on generated code
- CI/CD auto-fix bot with TTS gating
- Sectors: software engineering, DevOps
- Tools/workflows: a PR-bot that proposes multiple patches, prunes low-confidence chains early, executes tests in parallel containers, and posts a single, verified patch candidate
- Dependencies/assumptions: robust test suites; containerization; compute budget for parallel candidates
- Math and STEM tutoring assistants with step-by-step solutions
- Sectors: education, edtech
- Tools/products: tutoring apps that adapt difficulty (difficulty-aware weighting), present concise answers by default, and optionally reveal > … reasoning for pedagogy or educator review
- Dependencies/assumptions: content and exam policies regarding chain-of-thought exposure; safeguards to avoid solution over-reliance by learners
- Long-document analysis and structured extraction with budgeted TTS
- Sectors: legal, enterprise knowledge management, compliance
- Tools/workflows: review contracts and reports (36k–48k context) by sampling and pruning reasoning chains to cross-check extracted clauses, risks, or inconsistencies
- Dependencies/assumptions: text within supported context window; latency acceptance for long inputs; need to audit CoT storage for privacy
- Financial spreadsheet and formula copilot with correctness checks
- Sectors: finance, accounting
- Tools/products: generate and verify complex formulas or transformation scripts on sample data; maintain multiple candidates and pick the majority-consistent output
- Dependencies/assumptions: representative sample data/tests; guardrails to prevent hallucinated assumptions; compliance with data privacy
- Operations and logistics planning with parallel plan evaluation
- Sectors: operations, supply chain, project management
- Tools/workflows: generate multiple candidate schedules/plans, prune weak chains by confidence/constraints, and present a shortlist for human approval
- Dependencies/assumptions: clear, verifiable constraints/objectives; acceptance of approximate solutions; computational budget for parallel sampling
- Private/on-prem reasoning for sensitive data
- Sectors: healthcare administration (non-clinical), defense, public sector, regulated industries
- Tools/products: deploy Falcon-H1R-7B on servers/workstations (with quantization if necessary) to keep data local while enabling high-accuracy reasoning at lower cost
- Dependencies/assumptions: local GPUs or optimized CPU inference; licensing and data governance; performance tuning for on-prem hardware
- Academic reproducibility kits for reasoning/TTS research
- Sectors: academia, ML systems research
- Tools/workflows: use DeepConf-style confidence pruning, Balanced DP Token Normalization, difficulty-aware data curation, and GRPO variants (clip-high, TIS, CE-on-positives) to replicate/extend studies
- Dependencies/assumptions: access to training/inference compute; availability of curation/verification tools (Math-Verify, sandbox runners); careful benchmark hygiene
- Cost-control policies for inference at scale
- Sectors: AI platform teams, MLOps/FinOps
- Tools/workflows: per-request or per-tenant policies that adjust number of chains, temperature, and early-stopping thresholds, targeting defined accuracy or cost ceilings
- Dependencies/assumptions: calibrated confidence signals; monitoring for drift across domains; user-acceptable latency
Long-Term Applications
The following use cases are feasible with additional research, scaling, tooling, or regulatory readiness.
- Verified-code generation stacks with formal methods
- Sectors: software, safety-critical systems, embedded
- Tools/products: combine multi-sample generation with automated test case generation, static analysis, and formal verification (SMT solvers, proof assistants) to produce patches with machine-checkable guarantees
- Dependencies/assumptions: robust verification harnesses; standardized code extraction; integration with proof tooling; significant engineering investment
- Safety-critical decision support with auditable reasoning
- Sectors: healthcare (clinical), aviation, autonomous systems
- Tools/workflows: ensemble plans with strict confidence pruning and domain verifiers; produce audit trails of reasoning and verification outcomes for regulatory review
- Dependencies/assumptions: domain-specific validators and gold standards; rigorous evaluation; regulatory approvals and monitoring; strong human oversight
- Enterprise “reasoning OS” with multi-tool orchestration
- Sectors: enterprise software, knowledge management
- Tools/products: centralized inference orchestrator that routes tasks to tools (retrieval, calculators, simulators, sandboxes), runs multiple chains, prunes by confidence, and auto-logs artifacts for governance
- Dependencies/assumptions: tool catalog and APIs; data privacy/lineage systems; model/tool calibration across departments
- Robotics and autonomous planning with long-horizon reasoning
- Sectors: robotics, industrial automation
- Tools/workflows: generate multiple high-level task plans, prune with constraint checkers/simulators, and hand off to low-level controllers; leverage hybrid Transformer–SSM efficiency for long plans and batches
- Dependencies/assumptions: accurate simulators; real-to-sim alignment; tooling to verify preconditions/effects; integration with control stacks
- Adaptive curriculum engines for education at scale
- Sectors: education, edtech platforms
- Tools/products: difficulty-aware content generation and evaluation tailored to a student model; curated exposure to multiple reasoning traces; calibrated confidence to guide feedback and hinting
- Dependencies/assumptions: reliable student proficiency estimates; guardrails against leakage of full solutions; efficacy studies in classrooms
- Government/policy analysis assistants for scenario planning
- Sectors: public policy, think tanks
- Tools/workflows: multi-scenario generation (e.g., budget, climate, mobility) with structured verifiers (models, datasets); confidence-pruned consensus to support deliberation
- Dependencies/assumptions: high-quality, transparent data sources; bias/impact audits; clear human-in-the-loop standards
- TTS-optimized inference schedulers and hardware-aware runtimes
- Sectors: AI infrastructure, cloud providers
- Tools/products: inference orchestrators that schedule and pack many concurrent chains (context parallelism, Ulysses) to minimize latency and cost; automatic early stopping across batches
- Dependencies/assumptions: integration into serving stacks (vLLM/DeepSpeed/TPU backends); workload-aware scheduling; robust telemetry
- Domain-specific RLVR alignment factories
- Sectors: specialized industries (law, biotech, energy)
- Tools/workflows: assemble verifiable reward pipelines (domain checkers, simulators) and run GRPO-style RL with online sampling and generation caching for domain-specialized small models
- Dependencies/assumptions: trustworthy verifiers and ground truth; separation of SFT/RL datasets; compute for domain RL; ongoing monitoring to avoid overfitting
- Legal document automation with ultra-long context
- Sectors: legal tech, compliance
- Tools/products: end-to-end contract drafting/redlining with multiple candidate clauses, cross-document consistency checks, and confidence-pruned outputs
- Dependencies/assumptions: longer reliable context windows and retrieval; legal expert review; model calibration for legal language
- Agentic scientific discovery with verifiable tools
- Sectors: R&D, pharmaceuticals, materials
- Tools/workflows: agents that propose hypotheses/experiments, use simulators or lab robots for verification, and iterate via confidence-pruned TTS
- Dependencies/assumptions: high-fidelity simulators or automated labs; safety and reproducibility standards; domain-specific constraints and ethics
Cross-cutting assumptions and dependencies
- Calibration matters: Confidence-based pruning (DeepConf) effectiveness depends on well-calibrated probabilities in the target domain; recalibrate when domain-shifting.
- Verification quality sets ceilings: Gains rely on strong verifiers (tests, math-checkers, symbolic tools). Weak or missing verifiers degrade reliability.
- Compute budgets: TTS improves accuracy but consumes parallel inference compute; budgets and latency SLAs guide chain counts and early-stopping thresholds.
- Data governance and CoT handling: Many use cases require suppressing or securing chain-of-thought traces (<think> tags) to protect IP, privacy, and to comply with policies.
- Hardware and serving stack: Best efficiency comes from hybrid-parallel serving (e.g., context/sequence parallelism, fused kernels); benefits vary by hardware and runtime.
- Domain generalization: Training emphasized math/code; performance in other domains may need additional SFT/RLVR with domain-verified data.
- Licensing and compliance: Adoption depends on licensing terms of the released model and any third-party tools (e.g., Sandbox-Fusion) integrated in the workflow.
Glossary
- Accuracy–Cost Frontier: The trade-off curve between achieving higher accuracy and the computational cost of inference. Example: "By shifting the accuracy–cost frontier, Falcon-H1R delivers state-of-the-art reasoning performance with substantially lower inference overhead"
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability. Example: "Optimizer & AdamW (default β1, β2)"
- AIME24: A benchmark derived from the 2024 American Invitational Mathematics Examination used to evaluate mathematical reasoning. Example: "DeepConf@512 average results over AIME24, AIME25, AMO-Bench, and GPQA-Diamond"
- AIME25: A benchmark derived from the 2025 American Invitational Mathematics Examination used to evaluate mathematical reasoning. Example: "DeepConf@512 average results over AIME24, AIME25, AMO-Bench, and GPQA-Diamond"
- AMO-Bench: A benchmark suite for advanced mathematical olympiad-style problems. Example: "DeepConf@512 average results over AIME24, AIME25, AMO-Bench, and GPQA-Diamond"
- AsyncIO: Python’s asynchronous I/O framework for concurrent, non-blocking operations. Example: "Reward computation is executed in a distributed manner using Ray with AsyncIO coordination"
- bfloat16: A 16-bit floating point format that preserves dynamic range similar to FP32, often used for efficient training. Example: "Precision & bfloat16"
- Chain-of-Thought (CoT): A prompting/annotation style where the model’s intermediate reasoning steps are written explicitly. Example: "the > CoT Answer structure"
- Controlled Exploration Zone: A temperature range during sampling that balances accuracy and diversity for exploration. Example: "within the Controlled Exploration Zone as described in \citep{polaris}"
- Context Parallelism (CP): A model parallelism technique that splits the sequence context across devices. Example: "Parallelism Strategy & FSDP + Context Parallelism (CP=2)"
- Cross-Entropy: A loss function measuring the difference between predicted and true distributions. Example: "Cross-Entropy operations"
- Data-Parallel Balanced Token Normalization: A training technique that normalizes loss across tokens globally to reduce gradient variance across ranks. Example: "Balanced Data-Parallel (DP) Token Normalization"
- DeepConf: A test-time scaling method that filters and aggregates reasoning chains based on model confidence. Example: "We evaluate Falcon-H1R using the DeepConf method"
- Fully Sharded Data Parallelism (FSDP): A training approach that shards model parameters across devices to reduce memory footprint. Example: "The SFT stage for Falcon-H1R-7B training was performed using Fully Sharded Data Parallelism (FSDP)"
- GPQA-Diamond: A challenging subset of the Graduate-Level Physics Questions and Answers benchmark focusing on hard scientific reasoning. Example: "DeepConf@512 average results over AIME24, AIME25, AMO-Bench, and GPQA-Diamond"
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm that normalizes rewards across multiple rollouts per prompt. Example: "reinforcement learning using the GRPO approach"
- HMMT25: A benchmark from the Harvard-MIT Mathematics Tournament (2025) for evaluating math reasoning. Example: "64.9% on HMMT25"
- KL divergence (KL-penalty): A regularization term that penalizes deviation from a reference policy. Example: "KL-penalty term defined as:"
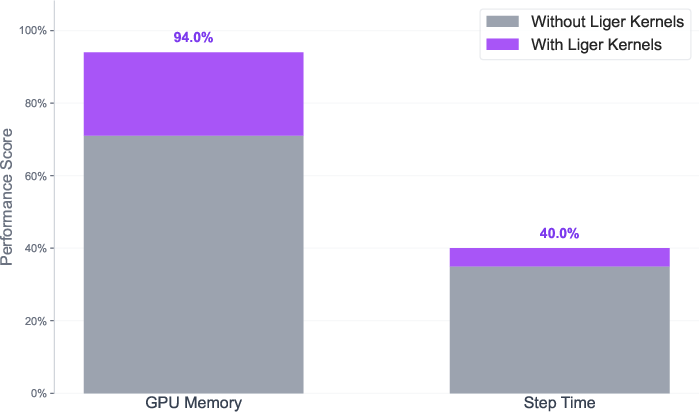
- Liger Kernels: Optimized CUDA kernels providing fused implementations for common transformer operations to improve throughput. Example: "Liger Kernels, which provide fused and memory-optimized implementations for Rotary Position Embedding (RoPE), RMSNorm, and Cross-Entropy operations"
- LiveCodeBench v6: A code generation benchmark with executable test cases to assess functional correctness. Example: "68.6% on LiveCodeBenchv6"
- LLM judge: An LLM-based evaluator that scores correctness when rule-based checks are insufficient. Example: "The LLM judge takes the prompt, extracted answer, and ground-truth solution as input and produces a single scalar value"
- Math-Verify: A toolkit for verifying mathematical answers via LaTeX parsing and symbolic checks. Example: "math-verify"
- Mamba: A state-space sequence model architecture used to improve efficiency in long-context reasoning. Example: "a parallel hybrid Transformer–Mamba (state-space) architecture"
- Majority voting: An aggregation method that selects the most common answer among multiple sampled solutions. Example: "such as through self-consistency or majority voting"
- μP (muP) scaling: A hyperparameter scaling framework that preserves training dynamics across model sizes. Example: "μP (\citep{falconH1}, Section 3.2.3) which notably ensures the transferability of the training hyper-parameters"
- Parallel thinking: Generating multiple concurrent reasoning chains during inference to improve accuracy. Example: "fast inference in the parallel thinking setting"
- pass@1: The probability that the top-1 sampled solution is correct. Example: "improve average accuracy (e.g., at pass@1)"
- pass@k: The probability that at least one of k sampled solutions is correct. Example: "measured by pass@k for large k"
- PPO: Proximal Policy Optimization, a reinforcement learning algorithm related to GRPO for policy updates. Example: "PPO batch size & 128"
- Ray: A distributed computing framework for scalable parallel processing. Example: "Reward computation is executed in a distributed manner using Ray with AsyncIO coordination"
- Reinforcement Learning (RL): A training paradigm that optimizes behavior via reward signals. Example: "followed by Reinforcement Learning (RL) (e.g., RLVR)"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL approach where rewards are computed via programmatic or external verification of correctness. Example: "we performed Reinforcement Learning with Verifiable Rewards (RLVR)"
- RMSNorm: Root Mean Square Layer Normalization used in transformer architectures. Example: "RMSNorm"
- RoPE (Rotary Position Embedding): A positional encoding technique that enables extrapolation to longer contexts. Example: "Rotary Position Embedding (RoPE)"
- Sandbox-Fusion: A secure code execution framework used to verify program outputs against test cases. Example: "The execution backend for the code reward system is based on Sandbox-Fusion"
- Self-consistency: A test-time method that samples multiple solutions and selects the consensus to improve reliability. Example: "such as through self-consistency or majority voting"
- State-space: A modeling framework representing sequences via latent dynamical states, enabling efficient long-range dependencies. Example: "Transformer–Mamba (state-space) architecture"
- Test-Time Scaling (TTS): Allocating extra inference-time compute to boost reasoning performance. Example: "This has motivated an emerging paradigm: Test-Time Scaling (TTS)"
- ThreadPoolExecutor: A Python concurrency primitive for parallelizing CPU-bound tasks. Example: "while ThreadPoolExecutor accelerates I/O CPU-bound workloads"
- Truncated Importance Sampling (TIS): A correction technique that caps importance weights to reduce variance and align training with sampling. Example: "Truncated Importance Sampling (TIS)"
- Ulysses sequence parallelism: A sequence-parallel approach that partitions tokens across devices to scale long-context models. Example: "To enable Ulysses sequence parallelism"
- vLLM: A high-throughput LLM inference engine optimized for serving and parallel generation. Example: "an LLM served through parallel vLLM instances"
- Confidence-based pruning: Filtering low-confidence reasoning chains during generation to save compute without hurting accuracy. Example: "scaling inference-time compute improves reliability and calibration through confidence-based pruning"
- State-of-the-art (SOTA): The best known performance level on a task at the time of reporting. Example: "consistently matching or outperforming SOTA reasoning models"
Collections
Sign up for free to add this paper to one or more collections.

