- The paper introduces a migration-based upgrade using hybrid Lightning Attention and MoE to achieve improved token efficiency and throughput.
- The methodology employs a four-stage pipeline with QK Norm absorption, partial RoPE adaptation, and extended context up to 256K tokens.
- The report demonstrates enhanced agentic RL via KPop and ARouter, yielding higher model efficiency and robust performance across benchmarks.
Ling and Ring 2.6: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Model Motivation and Overview
The Ling-2.6 and Ring-2.6 model family is built to address a critical efficiency-capability tradeoff in agentic LLMs at trillion-parameter scale. Ling-2.6 targets rapid response and high capability per token, serving latency-sensitive workloads; Ring-2.6 is optimized for deep reasoning and robust agent-environment integration. The design leverages architectural migration rather than retraining from scratch, inheriting Ling-2.0's pretrained weights and retrofitting hybrid linear attention combined with advanced MoE. This approach is guided by unified co-design across architecture, data, optimization, and agentic RL environments, which is shown to yield improvements in both model expressivity and deployment efficiency.
Architectural Innovations
Hybrid Linear Attention and MoE Design
Ling-2.6 models adopt a hybrid attention stack with a 7:1 ratio (Lightning Attention:MLA), achieving scaling law optimality and linear complexity for long-context inference. Lightning Attention provides a linear FLOPs profile, MLA compresses KV cache into a low-rank latent, and the hybrid allows context windows up to 262K tokens. MoE in feed-forward layers is fine-grained: 256 routed experts per layer, 8 experts activated per token, with bias-enabled routers and a group routing design with normalized probabilities.
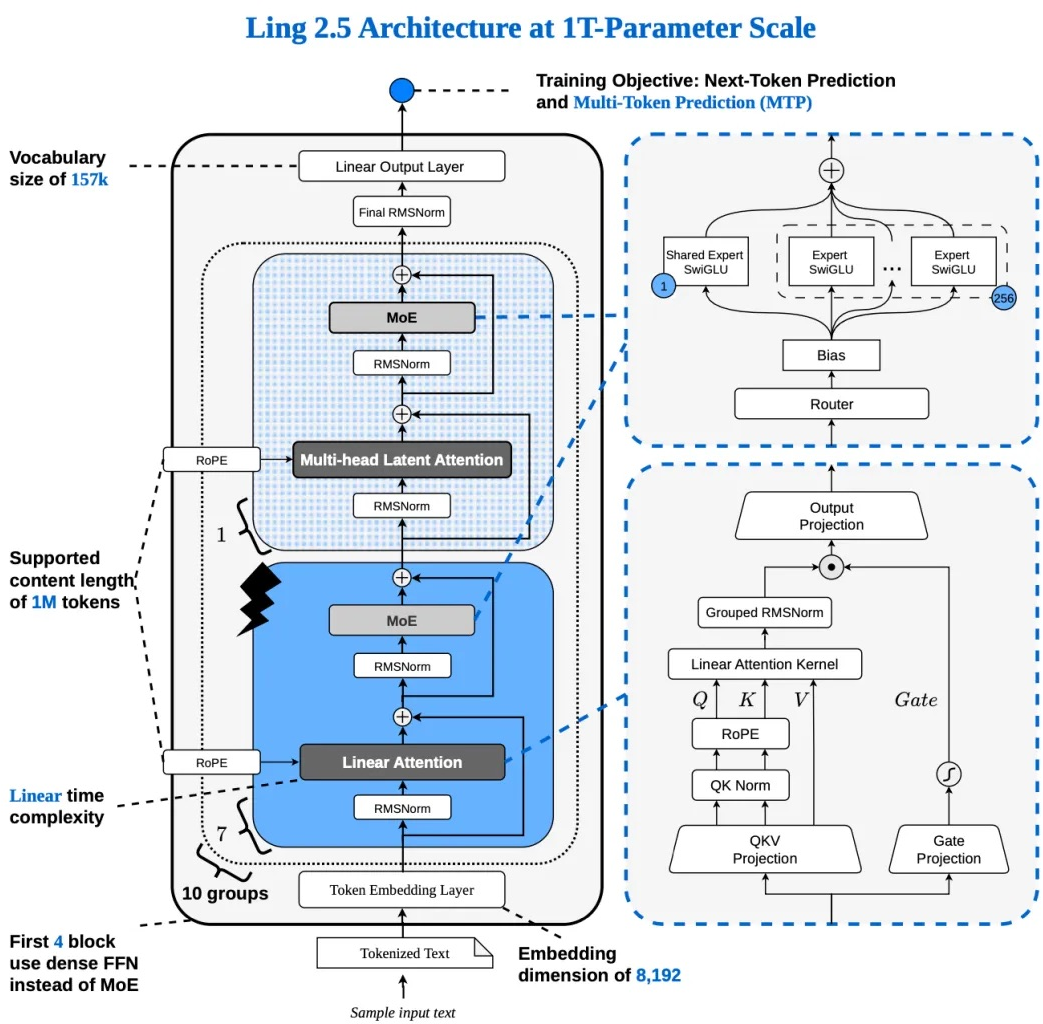
Figure 1: Architecture of Ling-2.6-1T-base, showing hybrid Lightning Attention/MLA and sparse MoE.
Scaling law experiments confirm that the 7:1 hybrid ratio yields best tradeoff between loss and compute, outperforming more aggressive (16:1) or conservative (1:1) ratios.
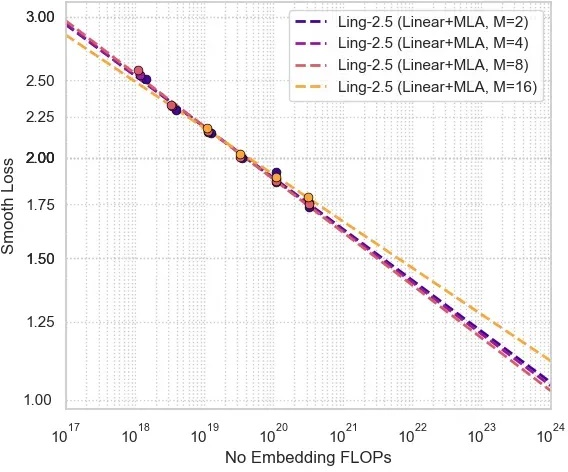
Figure 2: Scaling law curves for varying hybrid ratios, illustrating optimal loss per FLOPs for 7:1 Lightning:MLA.
Migration Pipeline and Compatibility Handling
The Ling-2.6 migration from Ling-2.0-to-2.6 involves a four-stage pipeline: Lightning Attention conversion with QK Norm absorption, partial RoPE adaptation, MLA conversion, and warmup. To resolve QK Norm/MLA incompatibility, QK Norm is absorbed into Wq, Wk weights via calibration-based fusion, and RoPE is decoupled for partial application.
Pre-training Data and Recipe
Agentic, Domain-specific, and Long-Context Corpus
Pre-training leverages extensive agentic corpora spanning tool use, MCP environments, coding, bash, QA, and repository traces. Long-context corpus is constructed via targeted retrieval, synthesis, and deep rule/model-based defect removal. STEM, web, atomic fact, math, code, and multilingual data are stratified in the mixture.
Multi-Stage Training and Context Extension
Three-phase training: migration, continue, and mid-training. The migration stage retrofits attention while minimizing loss, continue pre-training aggressively switches to high-quality data, and mid-training extends context to 256K tokens.
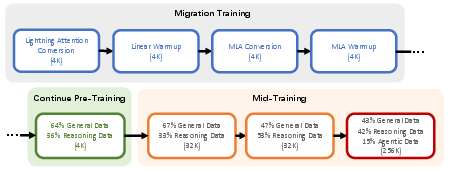
Figure 3: Multi-stage pre-training pipeline, from migration to mid-training and context window extension.
Post-training Specialization
Token Efficiency and Expert Distillation
Ling-2.6 pursues token efficiency via evolutionary Chain-of-Thought (Evo-CoT), Linguistic Unit Policy Optimization (LPO), shortest-correct-response distillation, and bidirectional preference alignment. These yield significant improvement: Ling-2.6-1T achieves Artificial Analysis Intelligence Index score of 34 using just 16M output tokens (4× better token efficiency than Ling-2.0-1T).
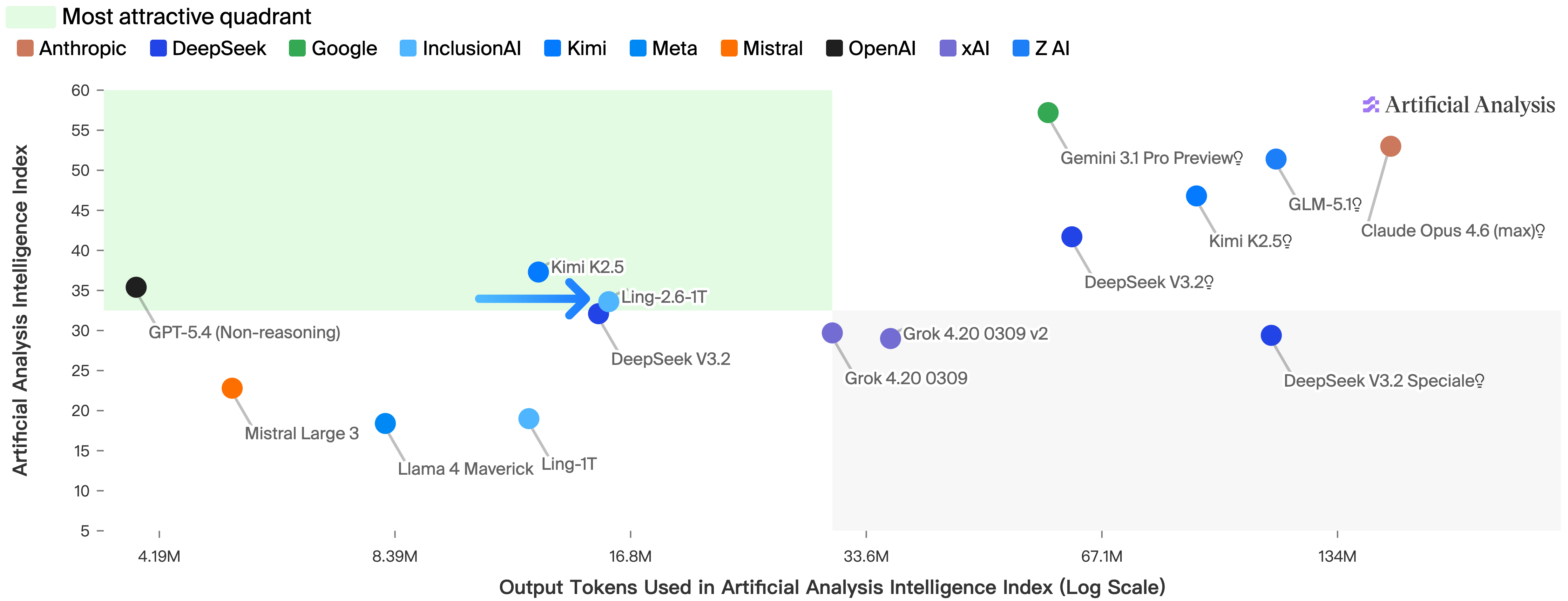
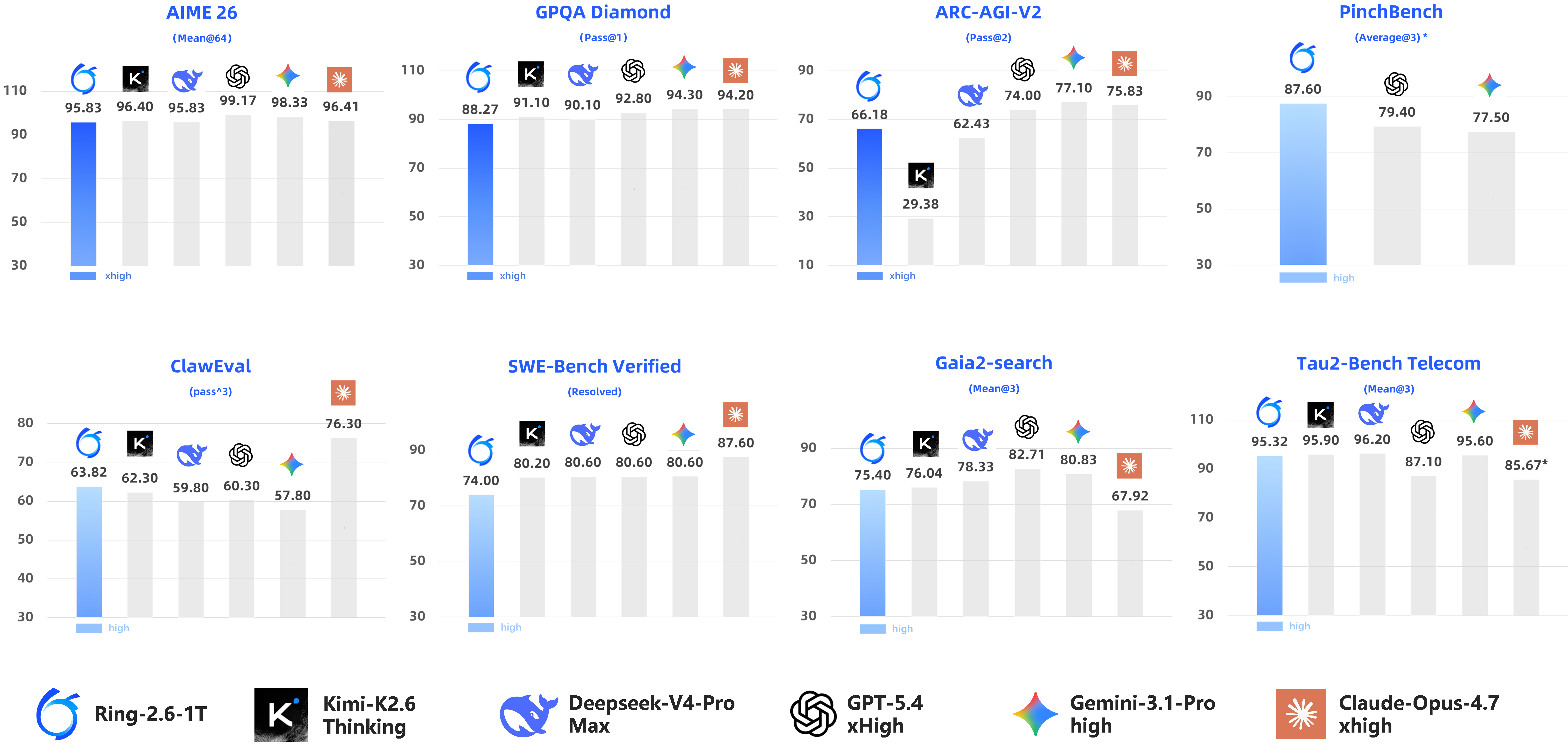
Figure 4: Ling-2.6-1T AAI Index—strong token efficiency; Ring-2.6-1T benchmark comparison.
Specialist and Reinforcement Learning Pipelines
Post-training splits into SFT cold start, specialist SFT, RL, and distillation. Reinforcement learning leverages GSPO and dynamic pass rating (DPR) curriculum. For Ring-2.6, KPop replaces IcePop with binary KL masking for mismatch bounding, yielding improved solve rates and reward stability in agentic RL.

Figure 5: Ling-2.6 post-training pipeline exploiting specialist distillation and efficiency rewards.

Figure 6: Ring-2.6 post-training pipeline, highlighting specialist sequencing and adaptive thinking modes.
Agentic RL: KPop and Asynchronous Optimization
KPop introduces symmetric binary KL masking for per-token adaptation instead of fixed global ratio constraint, improving agentic RL stability, especially for tools and coding environments.
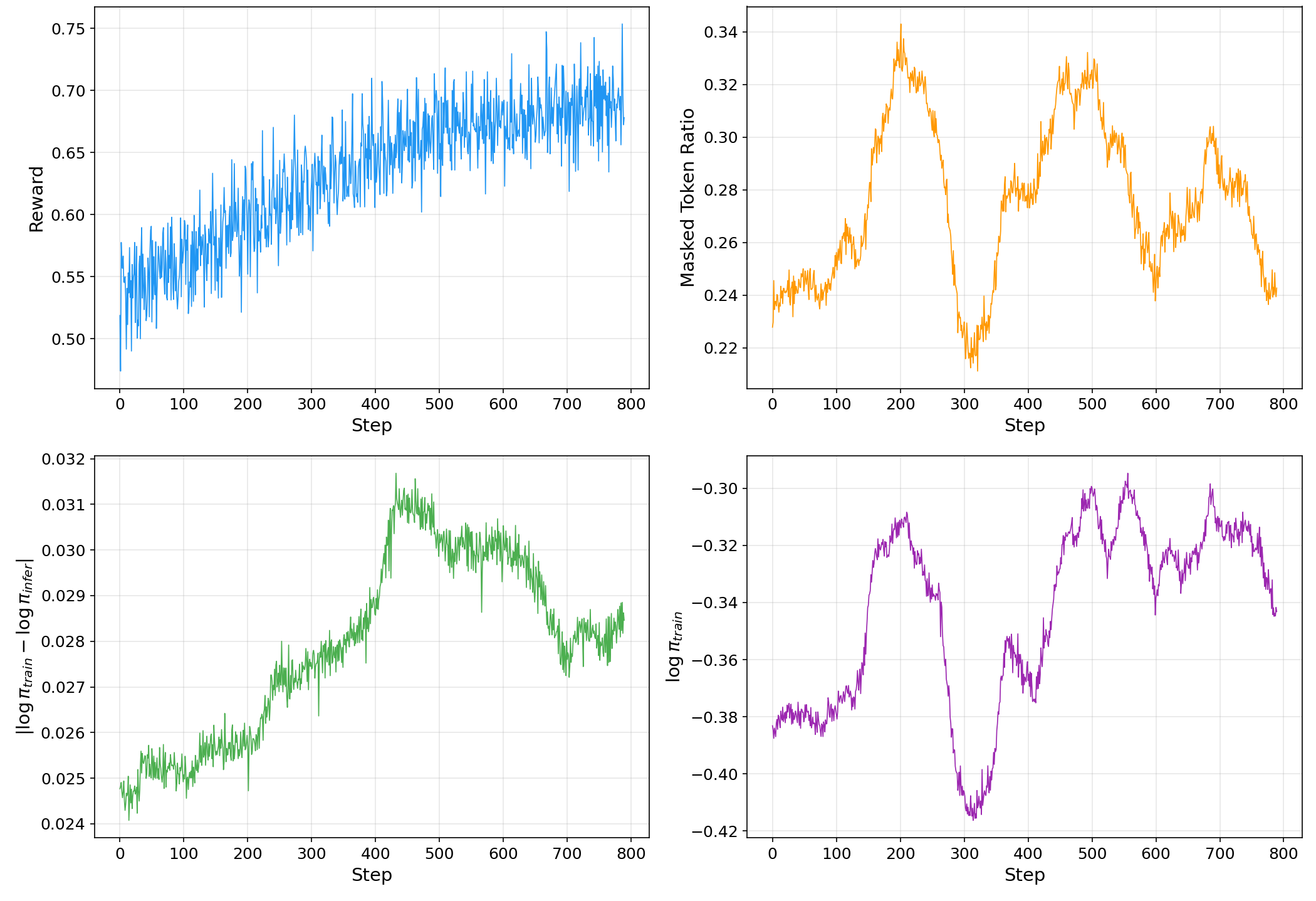
Figure 7: Training dynamics of agentic RL on coding task, exhibiting reward growth with KPop.
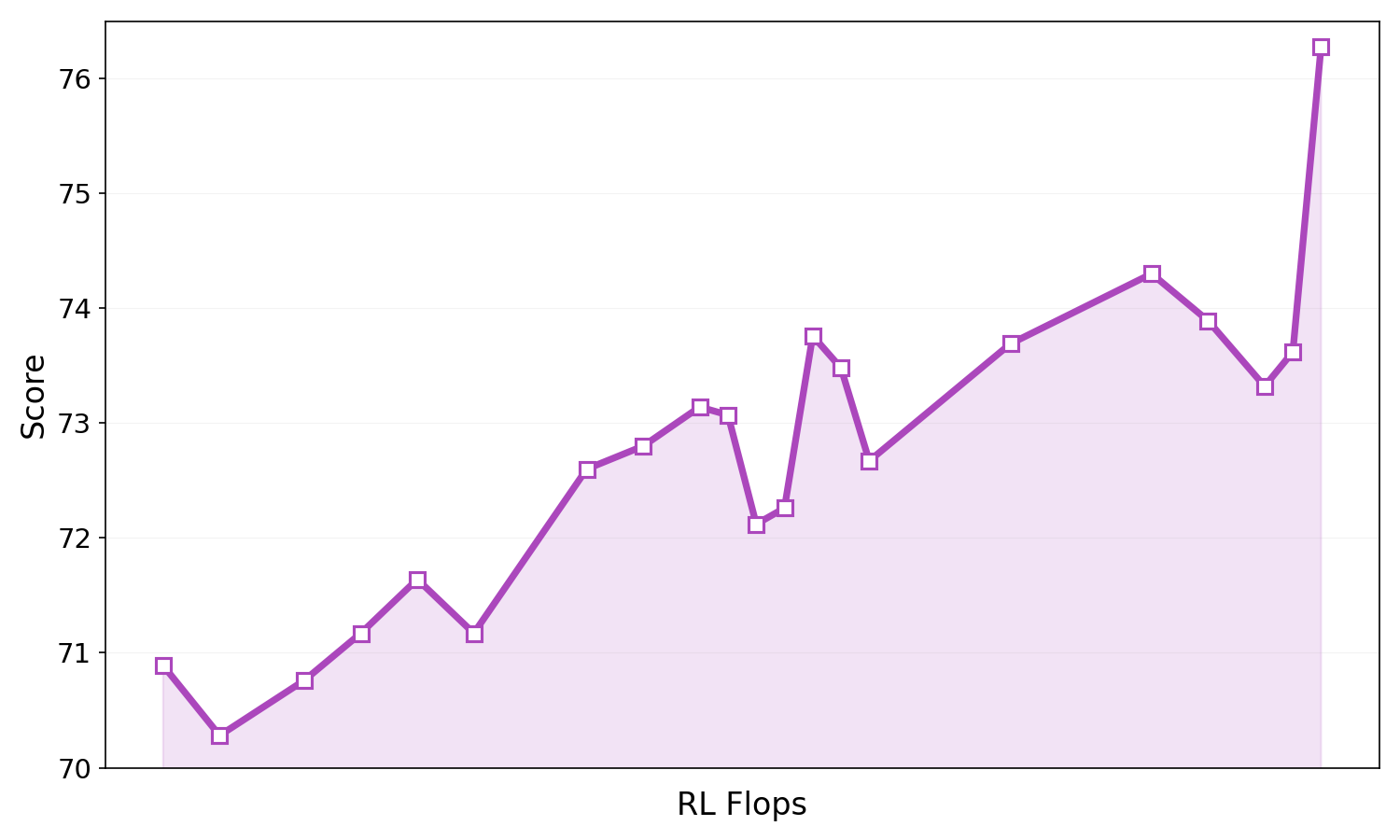
Figure 8: SWE-bench Verified evaluation, showing agentic RL scaling for Ring-2.6-1T.
RL rollout infrastructure uses ARouter for tail latency minimization, FP8/BF16 quantization with module-aware precision, and partial-rollout asynchronous pipelines. This decouples environment-bound tasks from GPU scheduling, maximizing throughput-stability.
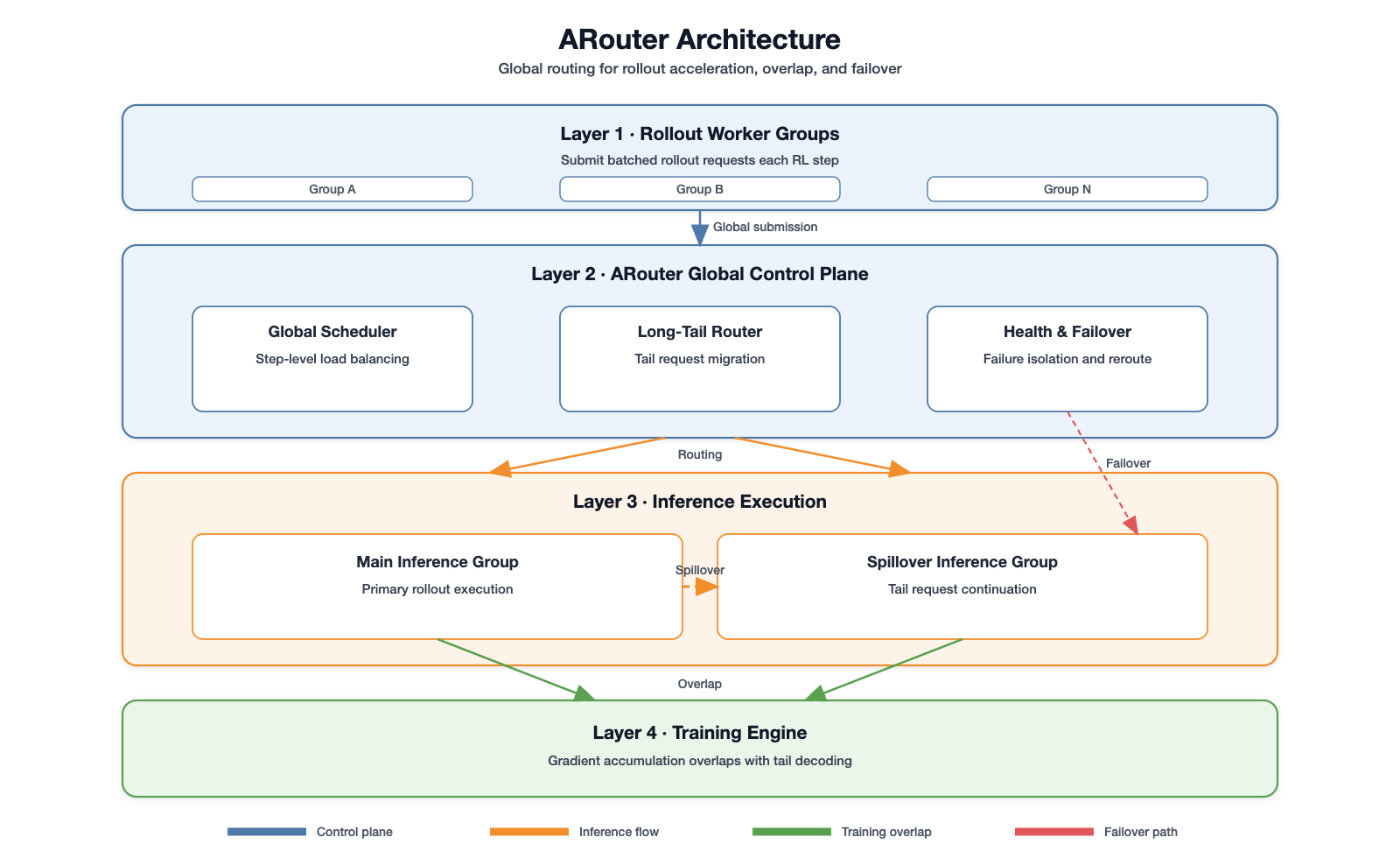
Figure 9: ARouter architecture for global rollout scheduling, optimizing inference/training overlap.
Evaluation and Numerical Results
Ling-2.6 outperforms most open and proprietary instant models across knowledge, reasoning, agentic tool use, instruction-following, and long-context domains. Ring-2.6-1T achieves leading scores on OpenClaw benchmarks (PinchBench 87.60, ClawEval 63.82), competitive on SWE-bench Verified (74.0), robust on GAIA-2 search, and maintains high function calling reliability.
Token efficiency is a primary highlight: Ling-2.6-1T attains AAI index 34 at 16M output tokens, competitive with GPT-5.4 non-reasoning, and 4× better than Ling-2.0-1T. Inference throughput is maximized via hybrid attention and sparse MoE, Ling-2.6-flash delivers up to 4× faster decode than state-of-the-art baselines.
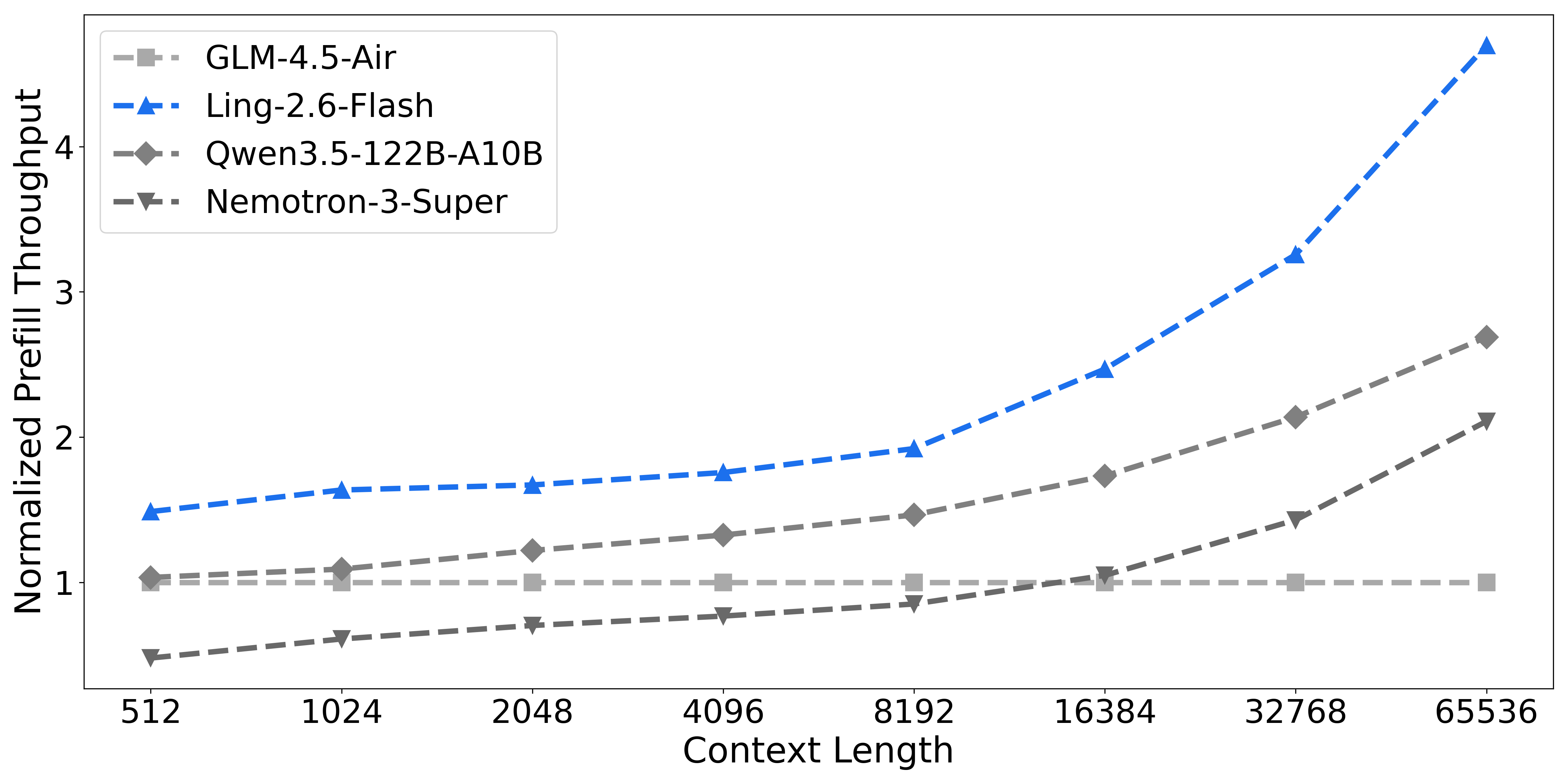
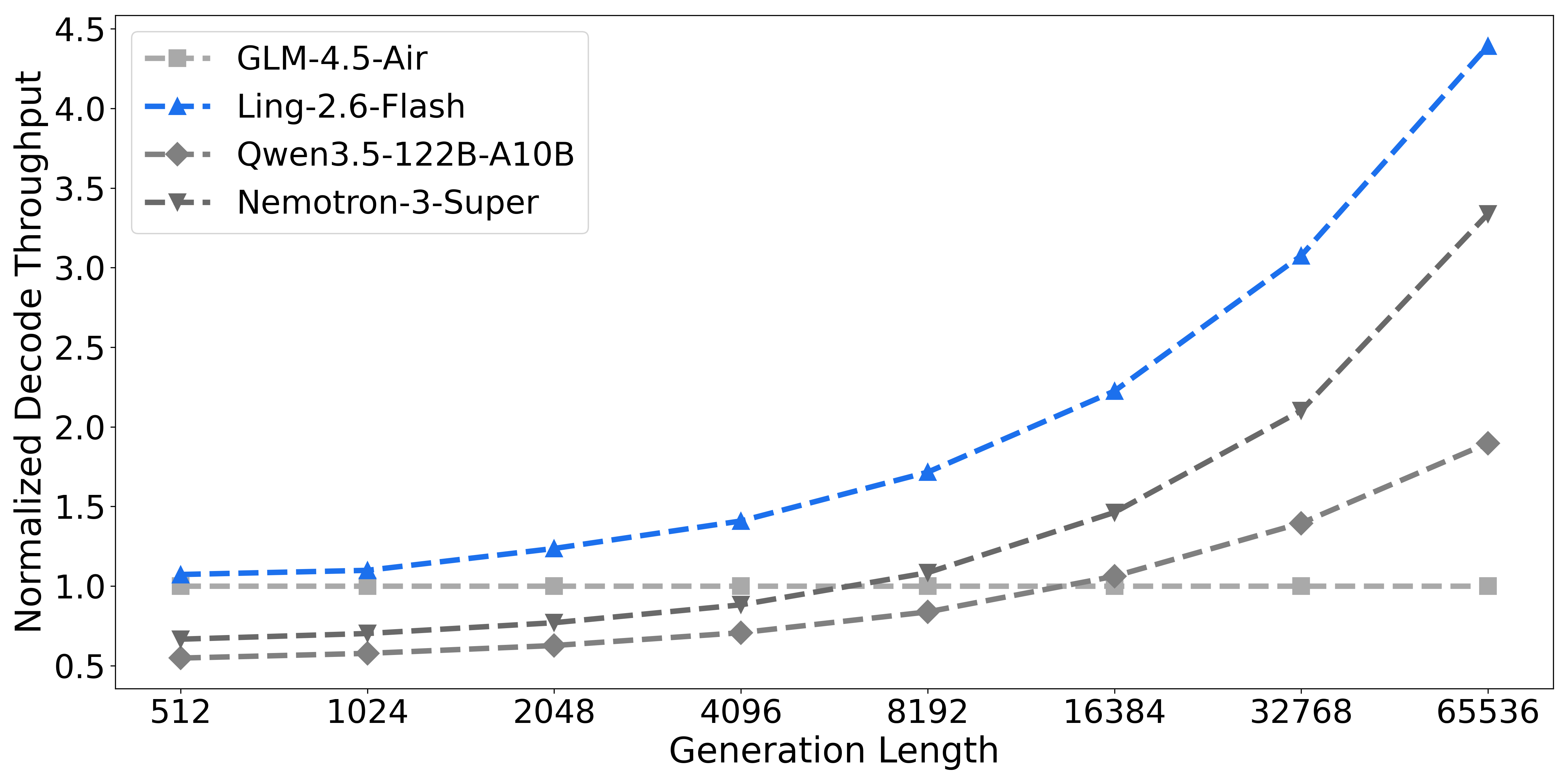
Figure 10: Prefill and decode throughput of Ling-2.6-flash, demonstrating high inference efficiency.
Infrastructure and System Co-Design
Long-context parallelism employs AllGather-based context parallel for Lightning Attention and fused kernels for varlen sequences, overcoming head-divisibility and kernel launch issues and delivering 68% speedup at 256K context. MoE kernels are updated for 64-bit token counts. Operator fusion and inference optimization (linghe) ensure training-inference alignment and maximize TPS.
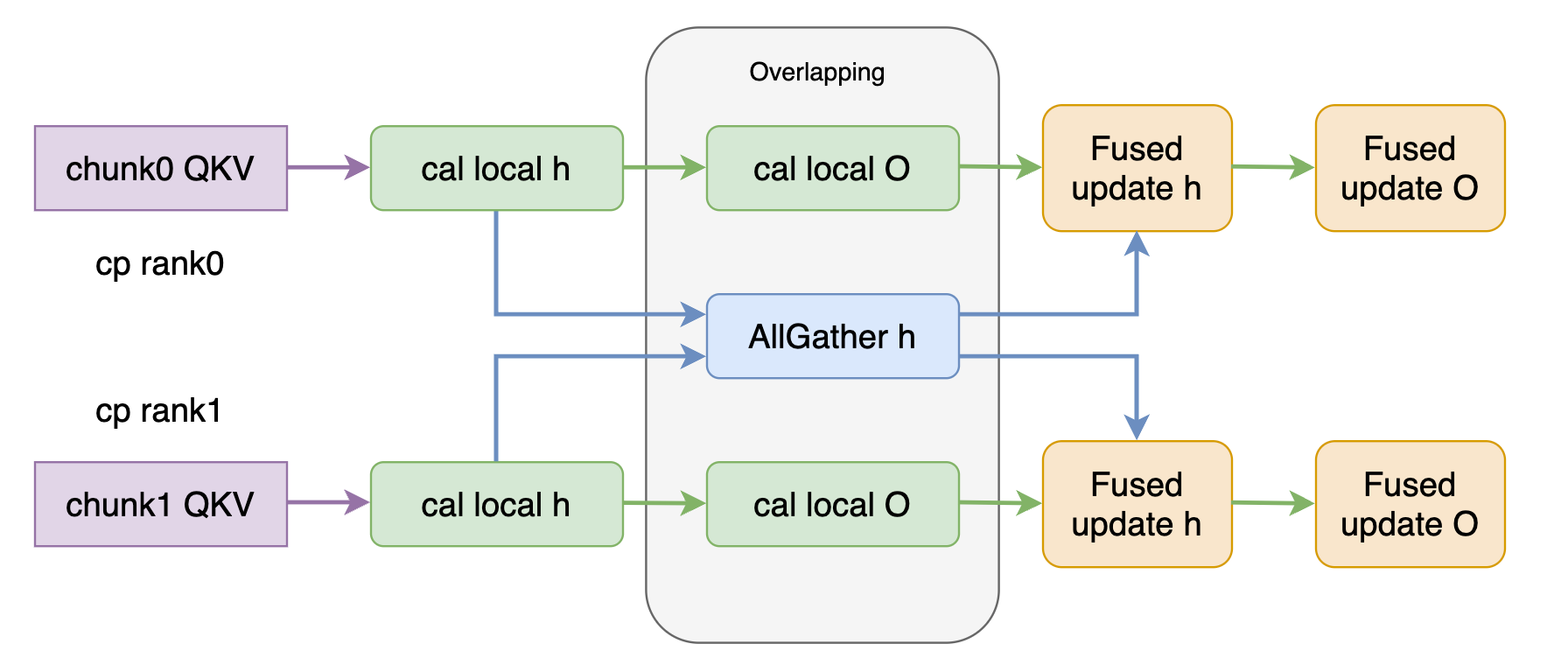
Figure 11: Lightning Attention CP optimization schematic.
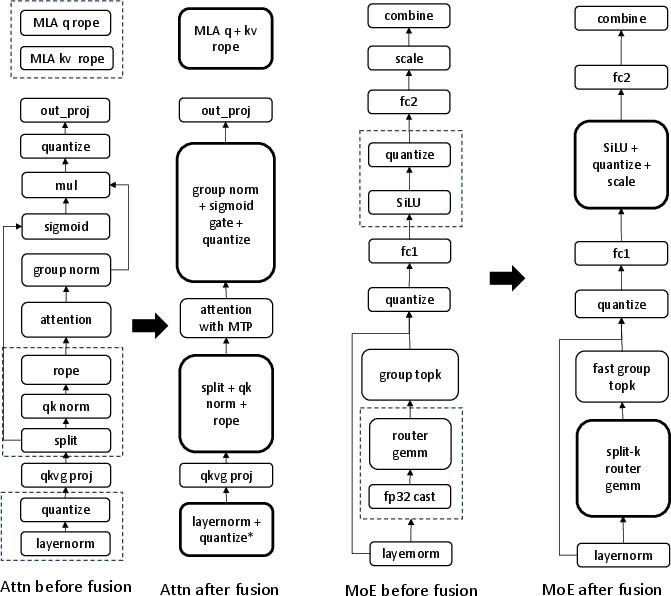
Figure 12: Linghe inference optimization, aligning fused kernel design for system throughput.
Agentic Coding Environment Construction
Docker environments are generated by conflating LLM-driven repository exploration with tool-restricted MCP scaffolds; this balances exploration with deterministic rule-based validation.
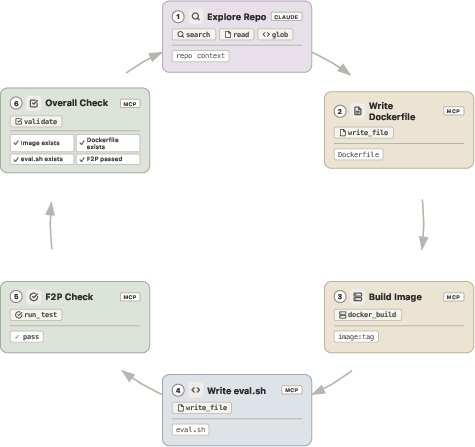
Figure 13: Coding environment construction pipeline—hybrid LLM/tool methodology for secure evaluation.
Conclusion
Ling-2.6 and Ring-2.6 represent a scalable, open model family for practical agentic intelligence, illustrating that architectural migration, hybrid attention, MoE specialization, token efficiency optimization, and infrastructure co-design converge to yield superior efficiency and capability at trillion parameter scale (2606.15079). The demonstrated gains in token efficiency, context scalability, real-environment robustness, and task throughput substantiate strong claims regarding practical agentic deployment. Persistent bottlenecks remain in high-complexity deliberation, factual/repetitive distinction, and long-horizon agentic robustness. Theoretical and practical implications emphasize the necessity for multimodal agentic extension and deeper stack co-design in subsequent generations.

