- The paper presents rStar2-Agent-14B, a 14B-parameter math reasoning model using agentic reinforcement learning to achieve state-of-the-art performance on math benchmarks.
- It introduces the GRPO-RoC algorithm and a scalable RL infrastructure that minimizes tool errors and supports up to 45K concurrent code executions per step.
- The model demonstrates strong generalization beyond mathematics through multi-turn rollouts, code-based verification, and self-reflection on execution feedback.
rStar2-Agent: Agentic Reasoning via Scalable Reinforcement Learning in Code Environments
Introduction
The rStar2-Agent technical report presents a 14B-parameter math reasoning model trained with agentic reinforcement learning (RL) in a Python code environment. The model demonstrates advanced cognitive behaviors, including judicious tool invocation, code-based verification, and self-reflection on execution feedback. The work addresses the limitations of long Chain-of-Thought (CoT) reasoning, which often fails to detect or correct subtle intermediate errors, by incentivizing models to "think smarter" through interaction with external tools and adaptive reasoning. The report details three core innovations: a scalable RL infrastructure, the GRPO-RoC algorithm for robust agentic RL, and a compute-efficient training recipe. The resulting model achieves state-of-the-art performance on competitive math benchmarks, surpassing much larger models with significantly shorter responses and strong generalization to other reasoning domains.
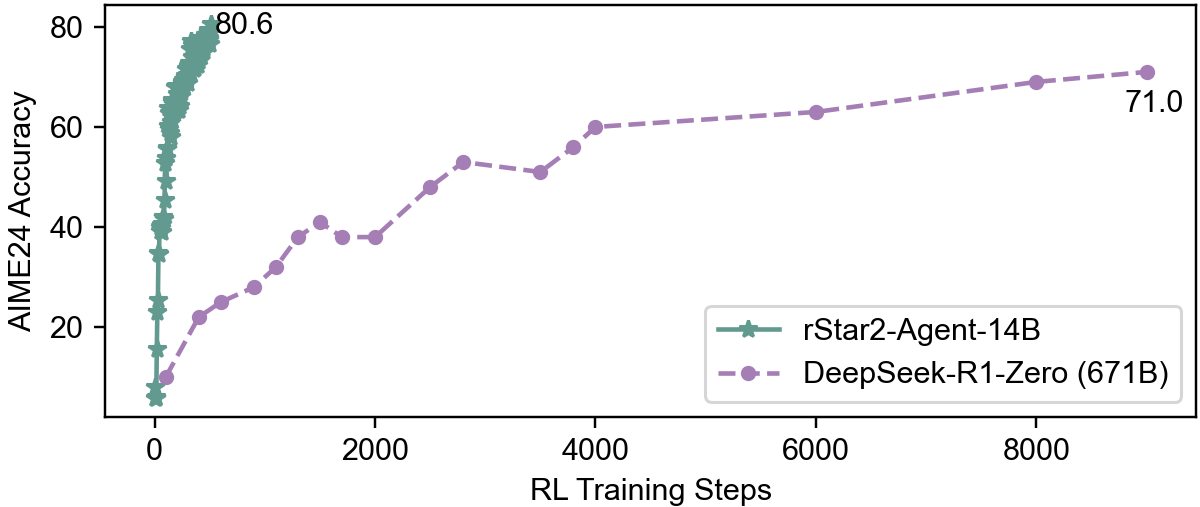
Figure 1: rStar2-Agent architecture, illustrating agentic reasoning with tool use and self-reflection in a code environment.
Agentic Reinforcement Learning in Code Environments
rStar2-Agent leverages a multi-turn rollout mechanism, where the model interacts with a Python code execution environment. Each reasoning trajectory consists of alternating assistant and user turns, with the model generating reasoning steps, invoking tools via structured JSON function calls, and receiving execution feedback. The prompt template (Figure 2) enforces separation between reasoning, answer, and tool usage, facilitating clean extraction and verification.

Figure 2: Prompt template specifying reasoning, answer, and tool call format for agentic RL training.
The tool call interface is standardized, supporting extensibility and alignment with LLM APIs. Execution feedback is wrapped in dedicated tags and includes successful outputs, errors, or timeouts, enabling the model to adapt its reasoning based on environment responses.
GRPO-RoC: Robust Agentic RL under Noisy Environments
The core RL algorithm is Group Relative Policy Optimization with Resample-on-Correct (GRPO-RoC). Standard outcome-only reward schemes, which assign binary rewards based on final answer correctness, are susceptible to environment-induced noise: trajectories with intermediate tool errors may still receive positive rewards, leading to lengthy, low-quality reasoning. GRPO-RoC addresses this by oversampling rollouts and asymmetrically filtering them: negative samples are preserved for diversity, while positive samples are downsampled to prioritize those with minimal tool errors and formatting violations. This strategy avoids reward hacking and stabilizes training without explicit step-level penalties.
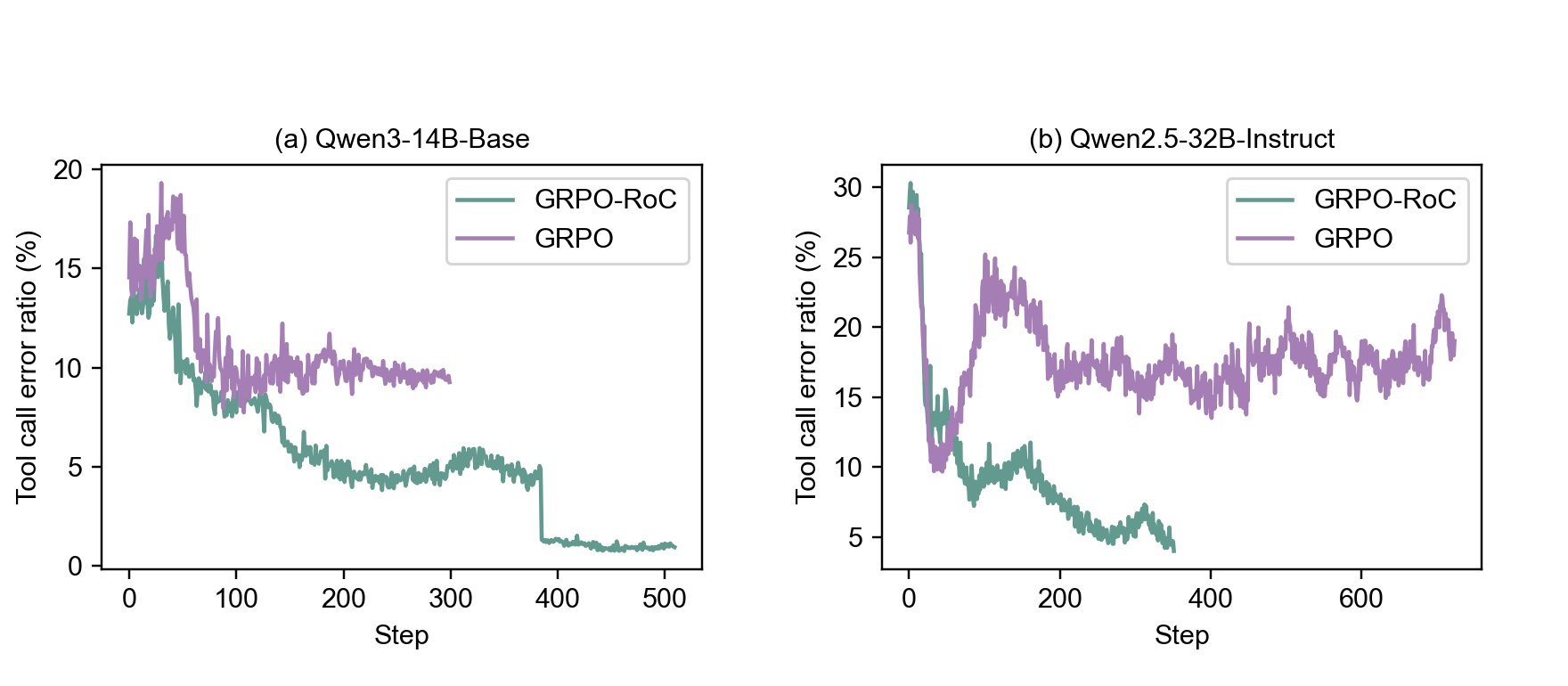
Figure 3: GRPO-RoC reduces tool call errors in positively rewarded trajectories compared to naive GRPO, improving reasoning quality.
Scalable RL Infrastructure
High-Throughput Code Execution Environment
Agentic RL requires infrastructure capable of handling tens of thousands of concurrent tool calls per training step. rStar2-Agent implements an isolated, distributed code execution service, with centralized task queues and batched dispatch across CPU cores. This design achieves reliable execution of up to 45K tool calls per step with sub-second latency, preventing rollout bottlenecks and ensuring safety against unpredictable LLM-generated code.
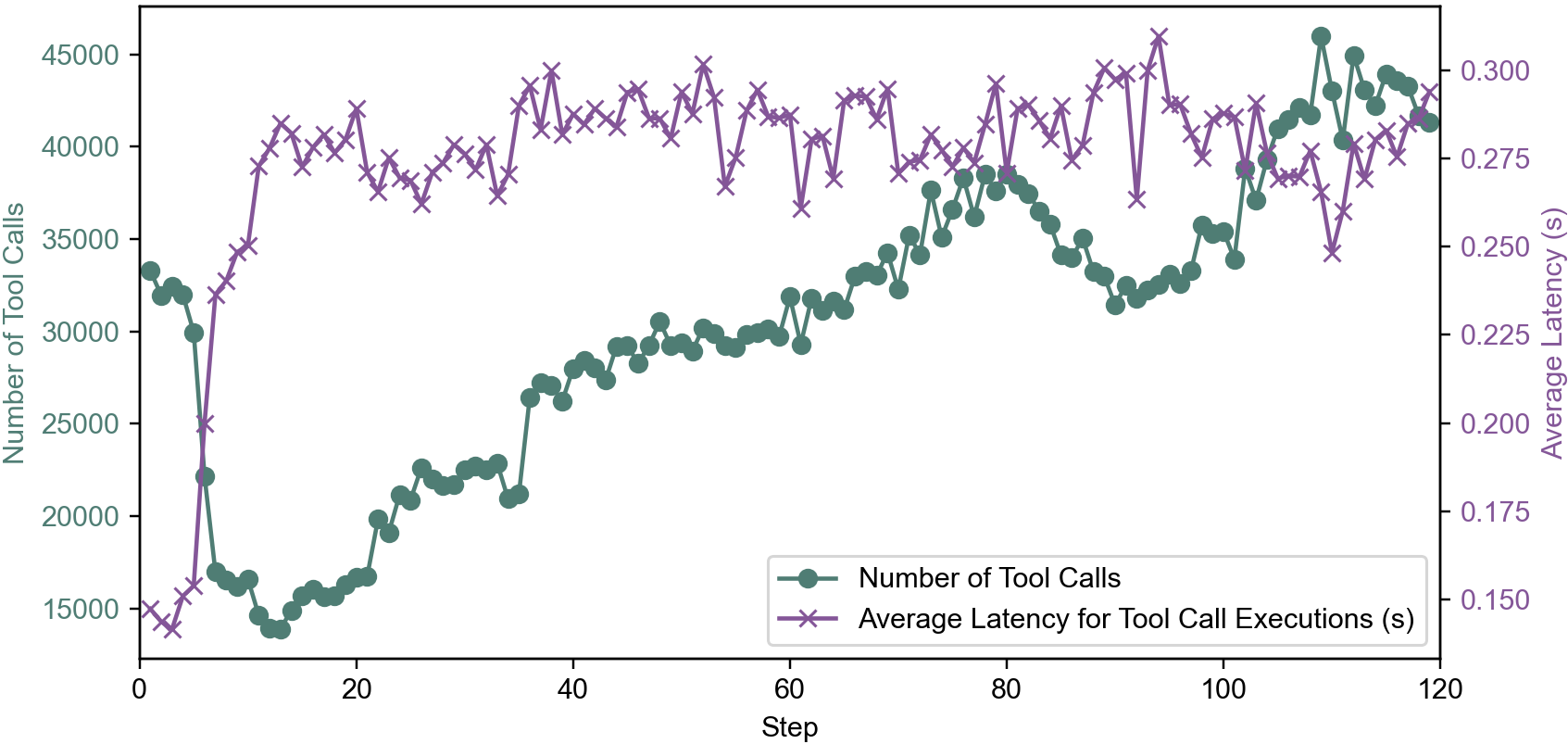
Figure 4: Code environment scalability, supporting 45K concurrent tool calls per step with low latency.
Dynamic Load-Balanced Rollout Scheduling
Static rollout allocation leads to severe GPU idle time and KV cache overflow due to variable response lengths and multi-turn interactions. rStar2-Agent introduces a dynamic scheduler that assigns rollouts based on available KV cache, dispatches tool calls asynchronously, and balances computation across GPUs. This maximizes resource utilization and eliminates wasted computation.
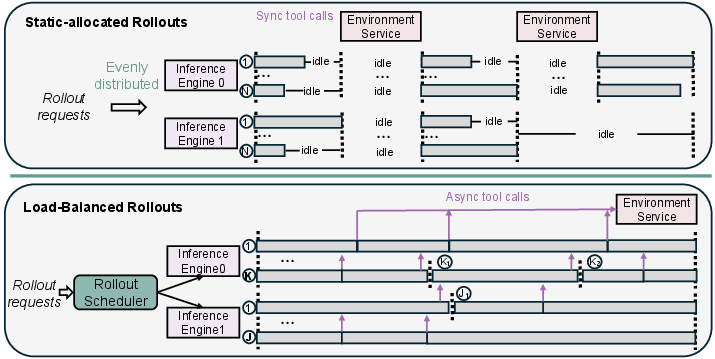
Figure 5: Dynamic load-balanced scheduler improves GPU utilization and rollout efficiency compared to static allocation.
Training Recipe and Data Curation
The training pipeline begins with a non-reasoning SFT stage, focusing on instruction-following, tool formatting, and basic code usage, avoiding reasoning-heavy SFT to prevent overfitting and maintain concise initial responses. RL data is curated to include only high-quality, integer-answer math problems, ensuring reliable reward verification. Multi-stage RL training gradually increases response length and data difficulty, with GRPO-RoC enabling strong performance even at shorter lengths (8K→12K tokens). The final model is trained in only 510 RL steps on 64 MI300X GPUs.
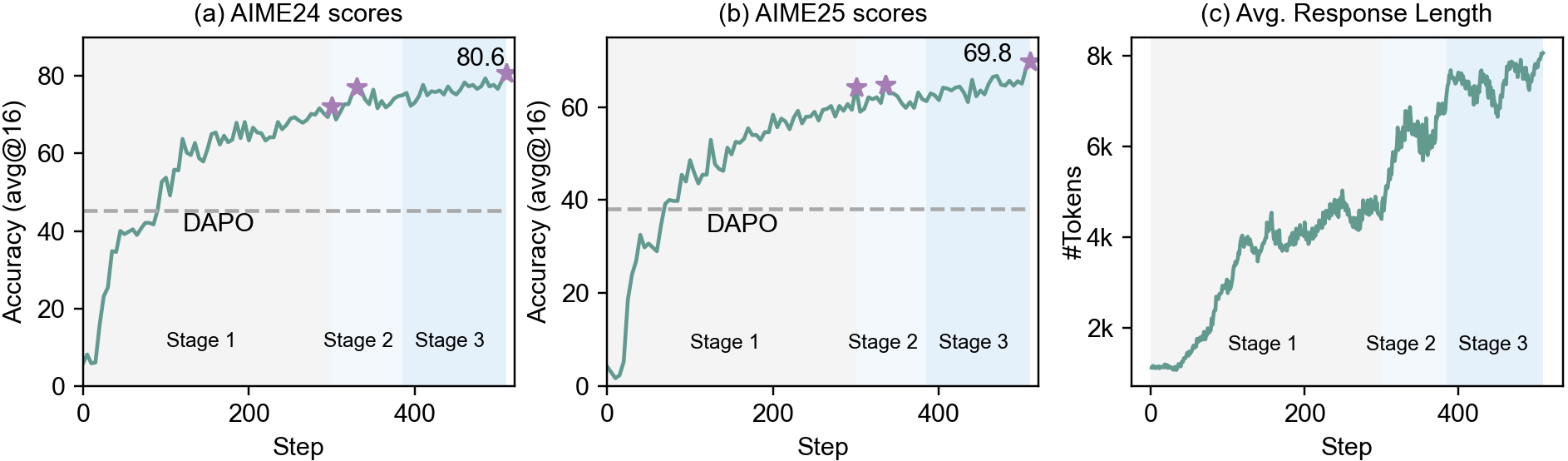
Figure 6: AIME24/AIME25 accuracy and average response length across multi-stage RL training.
Experimental Results
Frontier-Level Math Reasoning
rStar2-Agent-14B achieves 80.6% pass@1 on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) and other leading models, while generating significantly shorter responses (Table below). The model demonstrates efficient reasoning, with GRPO-RoC yielding concise, high-quality trajectories.
| Model |
AIME24 |
AIME25 |
Avg. Response Length (AIME24) |
| DeepSeek-R1-Zero |
71.0 |
53.3 |
14,246.8 |
| QWQ-32B |
79.5 |
65.8 |
11,868.4 |
| Qwen3-14B |
79.3 |
70.4 |
14,747.6 |
| rStar2-Agent-14B |
80.6 |
69.8 |
9,339.7 |
Generalization Beyond Mathematics
Despite math-only RL training, rStar2-Agent-14B generalizes to science reasoning (GPQA-Diamond), agentic tool use (BFCL v3), and alignment tasks (IFEval, Arena-Hard), outperforming DeepSeek-V3 on most benchmarks. This suggests that agentic RL in code environments induces transferable reasoning patterns.
Ablation and Comparative Analysis
Ablation studies confirm the superiority of GRPO-RoC over vanilla agentic RL and CoT-only RL (DAPO), with consistent gains in accuracy and response efficiency (Figure 7). The model's performance saturates at the base model's reasoning capacity, with further RL leading to collapse, highlighting the importance of efficient RL to reach the capacity ceiling.
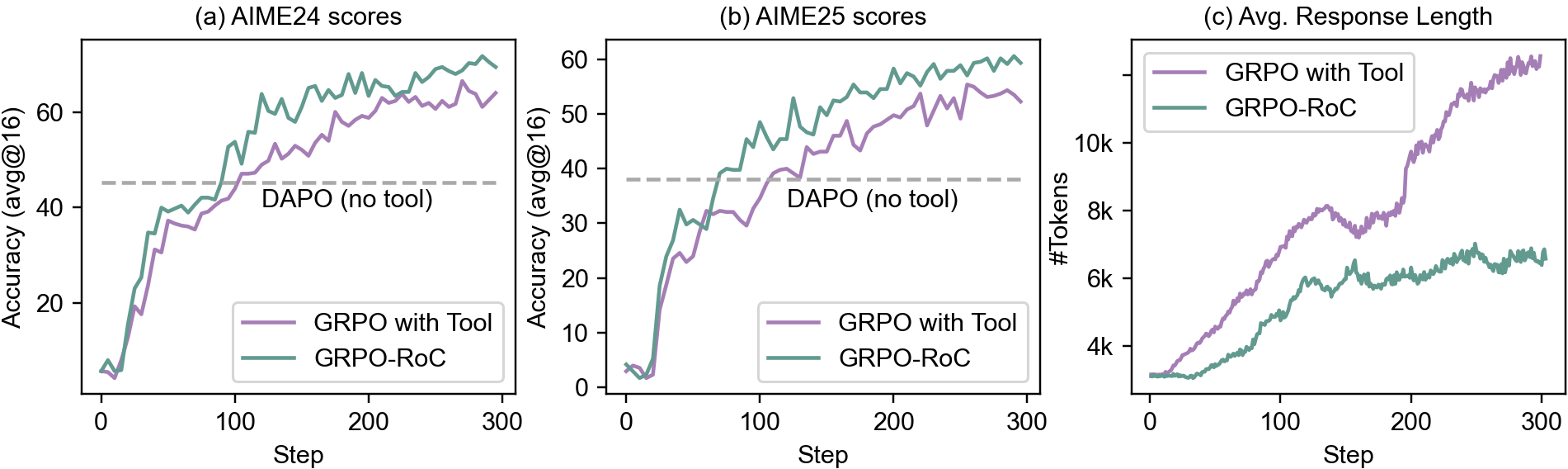
Figure 7: GRPO-RoC ablation: higher accuracy and shorter responses compared to baselines throughout training.
Analysis of Agentic Reasoning Behaviors
Token entropy analysis reveals that rStar2-Agent-14B produces high-entropy tokens during forking (exploration, self-reflection) and in response to tool feedback, driving error correction and adaptive reasoning. Coding tool call tokens are typically low-entropy, reflecting strong pretraining on code corpora. The emergence of reflection tokens on environment feedback is a distinctive feature of agentic RL, enabling more advanced cognitive behaviors than conventional long CoT.

Figure 8: Example agentic RL trace with coding tool use and self-reflection; high-entropy tokens (green) correspond to exploration and reflection.

Figure 9: Agentic RL trace showing error handling, code correction, and verification; high-entropy tokens mark adaptive reasoning steps.
Practical and Theoretical Implications
rStar2-Agent demonstrates that agentic RL in code environments can efficiently induce advanced reasoning capabilities in relatively small models, rivaling much larger counterparts. The GRPO-RoC algorithm provides a robust solution to environment-induced noise, enabling stable and effective training under outcome-only reward regimes. The scalable infrastructure and training recipe offer a blueprint for cost-effective development of reasoning agents. The observed generalization suggests that agentic RL may be a promising paradigm for broader cognitive tasks, contingent on the availability of valuable, verifiable environments.
Conclusion
rStar2-Agent establishes a new standard for agentic reasoning in LLMs, achieving state-of-the-art math performance with minimal compute and strong generalization. The work highlights the importance of scalable infrastructure, robust RL algorithms, and efficient training strategies. Future directions include extending agentic RL to diverse environments and reasoning domains, investigating the limits of model capacity, and refining reward and sampling strategies for even more effective cognitive behaviors. The public release of code and recipes will facilitate further research and practical deployment of agentic reasoning systems.

