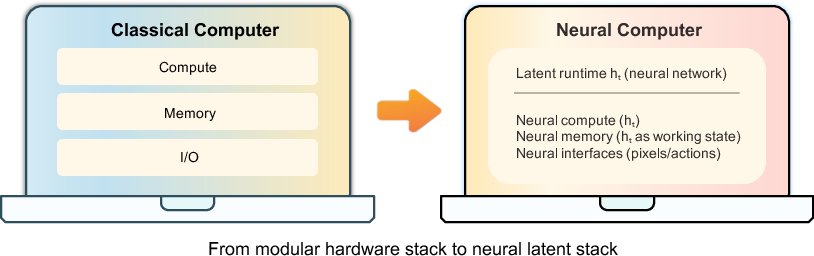
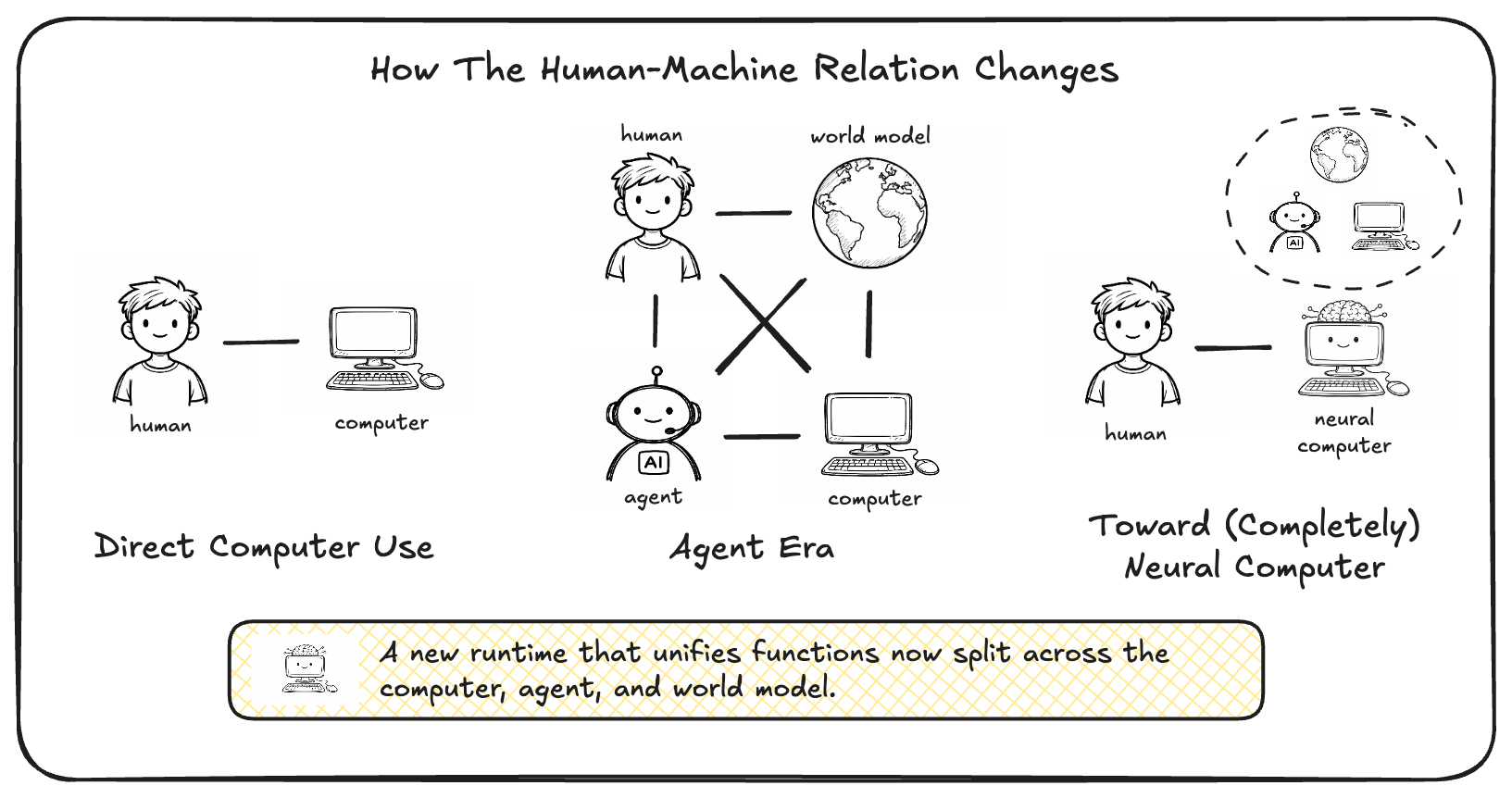
Neural Computers
Abstract: We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Neural Computers — A simple explanation
1) What is this paper about?
This paper asks a bold question: Can one neural network act like a whole computer by itself? The authors call this idea a Neural Computer (NC). Instead of having separate parts for thinking (compute), remembering (memory), and showing/receiving things (input/output), an NC tries to learn all of these inside one “brain” made of neural network weights. The long-term vision is a Completely Neural Computer (CNC) that works like a general-purpose computer, but is learned end-to-end.
2) What questions were the researchers trying to answer?
In plain terms, they explored:
- Can a neural network learn to “be” the running computer, not just a tool that uses one?
- Can it keep track of what’s on the screen, react to what the user types or clicks, and predict what the screen will look like next?
- Are early “computer-like” skills—such as aligning with what’s on the screen and responding correctly to short sequences of actions—learnable from real interface recordings?
- How far can it go with reasoning (like math) without extra tricks?
3) How did they test the idea? (Methods in everyday language)
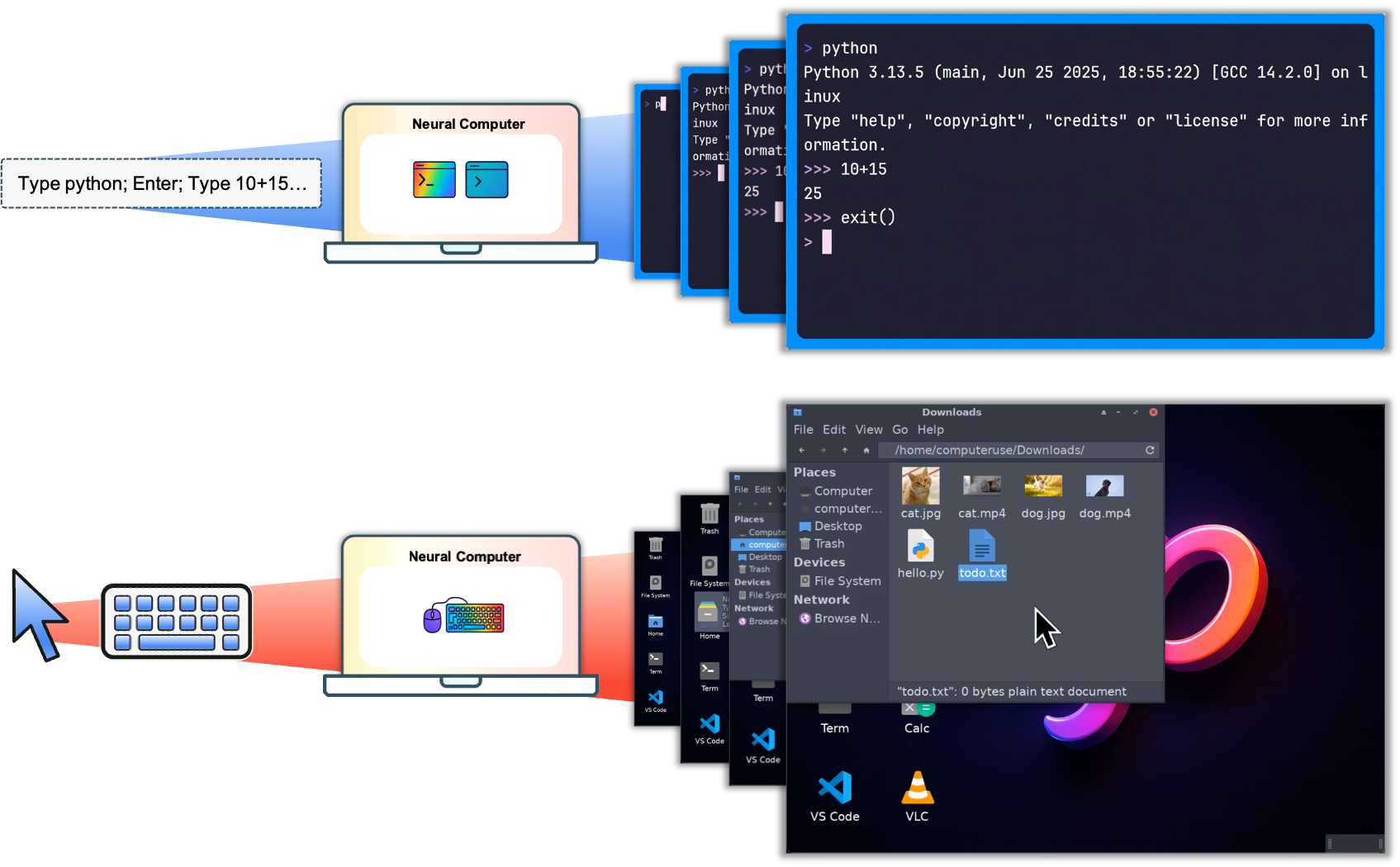
They turned the computer interface into a kind of “video world” the model could learn.
- Think of a computer screen like a movie. Each frame is a screenshot. When a user types or clicks, the screen changes. The model learns to predict the next screen based on the current screen and the user’s action—like a smart video game engine that knows what happens when you press keys or move the mouse.
- The model keeps an internal memory (they call it a “latent runtime state,” like a notebook in its head) so it remembers what’s going on across frames.
They built two prototypes:
- CLIGen (for terminals/command lines): It watches terminal videos and learns what happens when you type commands like “python” or “ls.”
- GUIWorld (for desktops/graphical apps): It watches desktop recordings with mouse and keyboard logs and learns how the interface responds to clicks, hovers, and menu actions.
How they trained it (simplified):
- They collected lots of recorded sessions:
- For CLIGen (General): public terminal recordings (asciinema) with text, timing, and frames.
- For CLIGen (Clean): scripted, repeatable terminal demos (so there’s less randomness).
- For GUIWorld: desktop screen videos aligned with mouse and keyboard actions.
- They used a strong video generator as the base (a diffusion video model; you can think of it as a careful painter that builds each frame step-by-step).
- A “VAE” compressed each frame into a short code (like zipping images), which the model used as its internal memory.
- “Conditioning” means giving the model extra guidance, like a caption describing the session, or the actual list of user actions (keys clicked). This helps it know what to draw next.
- They judged results with:
- Image similarity scores (PSNR/SSIM) for “does it look like the real thing?”
- OCR (text reading) to check if on-screen text is correct, letter by letter and line by line.
- Simple math tasks in the terminal to test basic reasoning.
4) What did they find, and why does it matter?
Key findings:
- Early “computer-like” skills are learnable:
- The model stayed aligned with what was on the screen and handled short action sequences well.
- In the terminal, it learned realistic details: scrolling, prompts, wrapping lines, resizing windows, and rendering readable text at normal font sizes.
- In the desktop GUI, it learned short-horizon control, like moving the pointer, hover and click feedback, and opening menus.
- Clearer instructions help a lot:
- Detailed, literal captions (prompts that say exactly what’s on the screen) improved how accurately the model rendered terminal content.
- Training improves fast at first, then levels off:
- Visual quality metrics rose quickly and then plateaued, suggesting that beyond a point, better or more informative data might matter more than just longer training.
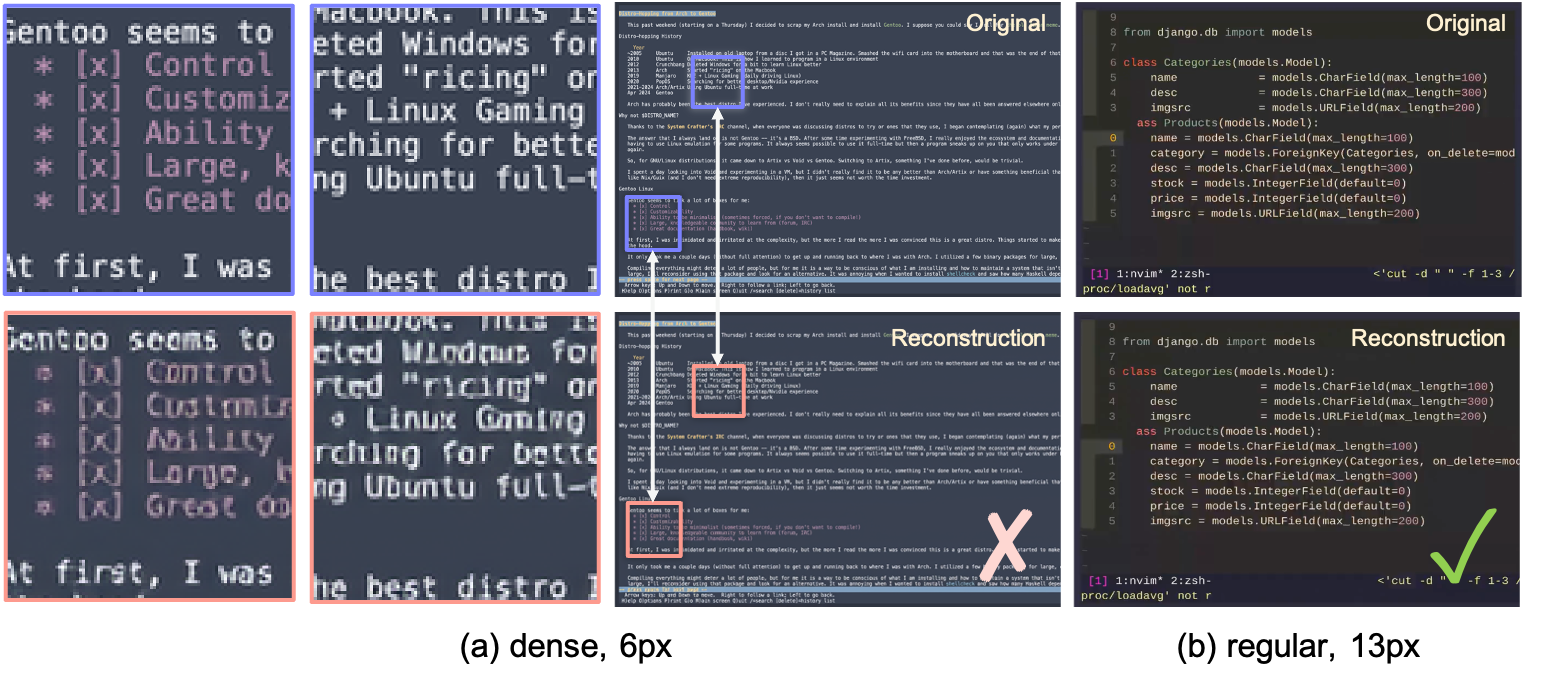
- It can produce correct on-screen text fairly well:
- Character-level accuracy (checked by OCR) climbed to roughly half of characters correct and about a third of lines exactly correct in controlled tests—good signs for usable, readable terminals.
- Reasoning (like math) is still weak without help:
- On math tasks shown through the terminal, the model did poorly (around 4% correct), unless it was given stronger hints or more specific prompts. With better prompts (reprompting), accuracy jumped to 83%—showing it’s very steerable by instructions, but not yet a reliable calculator on its own.
Why this matters:
- These are the first steps toward a computer that’s fully “in” a neural network—one that can hold state, react to actions, and render the next screen, all inside learned weights. That’s a new way of thinking about computers and could eventually simplify how systems are built and controlled (e.g., steer them with plain language and demonstrations).
5) What’s the big picture? (Implications and impact)
This work hints at a future where computers could be learned, not just engineered piece by piece. If the vision of a Completely Neural Computer (CNC) comes true, you might:
- Program and control a system through examples and language, rather than writing traditional code for every part.
- Have a unified “brain” that handles memory, computation, and the user interface seamlessly.
But there are big challenges ahead:
- Long, complex tasks (long-horizon reasoning) and reliable symbolic work (like math and logic) are still hard.
- Reusing capabilities safely and keeping behavior consistent over time needs careful design (runtime governance).
- New neural architectures may be needed to go beyond video-based prototypes.
In short, the paper shows that simple “runtime” skills—like keeping the screen consistent and responding to clicks/keys—can be learned today. That’s encouraging progress toward the bigger goal of fully neural computers, but solid reasoning and reliability will require more advances.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored based on the paper’s current scope and results:
- No closed-loop evaluation: all rollouts are open-loop from logged conditioning streams; there is no environment-in-the-loop test of interactive stability, error recovery, or task completion over long horizons.
- Unverified “executable state” semantics: the latent state
h_t(realized as video latentsz_t) is not shown to carry structured, addressable, or interpretable program state beyond correlational dynamics. - Absent evidence of Turing completeness or universal programmability: the prototypes do not demonstrate execution of arbitrary programs, conditional branching with reliable state, or general-purpose control flow.
- Determinism and behavior consistency are unproven: diffusion sampling introduces stochasticity; there is no method to guarantee repeatable behavior “unless explicitly reprogrammed.”
- No runtime governance mechanism: the paper highlights governance as a CNC criterion but does not propose concrete controls for inspection, auditing, interruption, sandboxing, or policy enforcement.
- Long-horizon reasoning and control remain untested: experiments focus on short-horizon I/O and local control (e.g., pointer hover/click); there is no quantitative study of multi-step planning, multi-window workflows, or extended sessions.
- Native symbolic computation is weak: arithmetic probes show near-zero to low accuracy without reprompting; it remains unclear how to endow stable, native symbolic operations within the NC backbone.
- Conditioning confounds “reasoning”: large gains on arithmetic (4%→83%) come from reprompting/recaptioning; evaluation does not disentangle answer-conditioned rendering from internal computation.
- RL vs. conditioning vs. architecture: the paper does not resolve whether reliable symbolic computation requires reinforcement learning, stronger conditioning, architectural changes (e.g., discrete memory), or their combination.
- Metrics are misaligned with interactivity: reliance on PSNR/SSIM and OCR accuracy does not capture control competence, task success, or state consistency; no standardized NC benchmarks are proposed.
- Early training plateaus suggest objective/data limits: reconstruction metrics saturate quickly; it is unknown which objectives (e.g., control-aware, consistency, or state-tracking losses) would push beyond early plateaus.
- GUIWorld lacks quantitative control metrics: while pointer dynamics look coherent qualitatively, there are no measurements of click accuracy, target acquisition latency, hit rates, or robustness to UI variability.
- Generalization across apps, themes, and resolutions is unproven: models are sensitive to font size and fixed rendering setups; robustness to unseen applications, DPI changes, color themes, and window geometries is not evaluated.
- Closed-loop safety and error handling are unaddressed: the NC’s response to unexpected system states, latency spikes, partial renders, or asynchronous events (e.g., network errors) is not studied.
- Memory capacity and retention properties are unknown: no experiments quantify working-memory length, catastrophic forgetting, state drift over long rollouts, or the benefits of explicit memory mechanisms.
- No explicit representation for structured buffers: the NC does not read/write terminal buffers or OS state as privileged inputs; the trade-off between pixel-only modeling and structured state access is unexplored.
- Scalability of the video-based substrate is unclear: costs, latency, and throughput for high-resolution desktops, multi-monitor setups, and low-latency interaction are not profiled or optimized.
- Ambiguity in action modeling: the paper explores action injection/encoding but does not isolate how action representations affect controllability, credit assignment, or generalization across devices.
- Lack of causal ablations: it is unclear which components (VAE choice, CLIP features, caption styles, action encoders) are necessary/sufficient for I/O alignment and control versus mere visual fidelity.
- Dataset biases and leakage risks: CLIGen (General) uses LLM-generated captions; CLIGen (Clean) includes correct answers in ~50% of arithmetic captions; these may bias results and blur the line between reasoning and conditioning.
- No comparison to agent baselines: there is no head-to-head evaluation against LLM-based OS agents or programmatic simulators on identical tasks, leaving unclear where NCs help or lag.
- Inadequate treatment of error accumulation: the stability of latent state through rollouts, compounding rendering errors, and cursor/geometry drift are not quantitatively analyzed.
- Programming model is unspecified: how users “program” an NC (languages, APIs, constraints), how to modularize skills, and how to perform upgrades without catastrophic behavior shifts remain open.
- Reprogramming vs. learning updates: mechanisms to patch behaviors, version models, and ensure backward-compatible “software updates” are not defined.
- Verification and debugging are unsolved: there is no pathway for formal verification, unit testing, or introspection of latent state to trace and fix failures.
- Security and privacy are unaddressed: risks of latent-state retention of secrets, prompt injection through UI pixels, or unsafe actions in a closed-loop desktop are not scoped or mitigated.
- No clear path to discrete, addressable memory: the prototypes do not integrate differentiable/external memory; whether latent-only dynamics can support robust algorithmic manipulation is an open question.
- Action-selection is not learned: the NC renders conditioned on provided actions; it does not generate actions or policies, leaving open how a CNC would decide and execute next steps autonomously.
- Handling asynchronous and concurrent processes is untested: interrupts, background tasks, and race conditions in real OS environments are not modeled or evaluated.
- Transfer and reuse of capabilities are unclear: how to compose skills across CLI and GUI domains, share parameters, or amortize learning across tasks is left for future work.
- Data release, reproducibility, and standardization: it is unclear whether datasets, prompts, and evaluation harnesses will be released to enable reproducible CNC benchmarking.
- Energy and hardware constraints: the prototypes require substantial GPU time; feasibility for real-time, low-latency “computing” on commodity hardware is not demonstrated.
- Alternative substrates and architectures: while the paper hints that video models are a stopgap, it does not explore or prototype architectures purpose-built for NC/CNC properties (e.g., hybrid neural-discrete systems).
Practical Applications
Overview
This paper introduces “Neural Computers” (NCs): neural systems that unify computation, memory, and I/O in a single learned runtime state and demonstrates two practical, video-model-based prototypes:
- CLIGen for command-line interfaces (terminal frames + text conditioning).
- GUIWorld for desktop GUIs (screen frames + synchronized mouse/keyboard).
The prototypes learn early runtime primitives—screen I/O alignment, coherent short-horizon control, and character-accurate rendering—from raw interface input/output without privileged access to program state. Below are actionable applications and what they depend on, grouped by time horizon.
Immediate Applications
Below are deployable-now use cases based on demonstrated capabilities (high-fidelity interface rendering, short-horizon action response, text-to-pixel alignment, synchronized data pipelines, and conditioning-driven control).
- Bold title: sector(s)
- Potential tools/workflows
- Assumptions/dependencies
- Bold Prompt-to-terminal screencast generation from natural language: software, education, content creation
- Potential tools/workflows: “Prompt-to-screencast” doc builder; product/tutorial video auto-generator; developer marketing assets; reproducible runbook visuals from captions.
- Assumptions/dependencies: Best on well-covered CLI patterns and sensible font sizes (≈13 px); limited long-horizon logic; open-loop generations (no live environment feedback).
- Bold Synthetic UI/CLI dataset generation for vision/OCR and UI parsers: AI/ML, software QA
- Potential tools/workflows: Large-scale terminal/GUI video corpora for training OCR, UI element detectors, layout parsers; controlled font/palette ablations to test robustness.
- Assumptions/dependencies: Data licensing/privacy; fidelity hinges on render consistency and timing; risk of domain shift outside trained themes/fonts.
- Bold Short-horizon UI automation prototyping (micro-automation): enterprise RPA, productivity software
- Potential tools/workflows: “Neural pilot” that simulates/validates hover/click menus, focus changes, and window transitions before deploying brittle RPA scripts; macro recording/rehearsal in a sandbox.
- Assumptions/dependencies: Works in controlled desktops with synchronized action traces; short-horizon only; open-loop (no guaranteed success criteria).
- Bold Sandboxed training substrates for agent research: AI/embodied agents
- Potential tools/workflows: Offline imitation pretraining on synchronized (frame, action) logs; action-conditioned rollouts for curriculum learning; ablations on action encodings.
- Assumptions/dependencies: Current prototypes are not closed-loop environments and have weak native symbolic reasoning; reward signals and evaluators must be externally defined.
- Bold CLI/GUI regression and rendering QA: software QA, DevOps
- Potential tools/workflows: Character-level accuracy and OCR-based diffs to detect rendering regressions; terminal “golden video” comparisons; palette/geometry change detectors.
- Assumptions/dependencies: Sensitive to font/themes; global metrics (PSNR/SSIM) plateau and can be misleading—prefer OCR/line-level metrics.
- Bold Documentation and runbook validation: DevOps/IT operations
- Potential tools/workflows: Turn runbooks into expected terminal rollouts and compare with recorded sessions; auto-flag misalignments (cursor position, line breaks, prompt wrapping).
- Assumptions/dependencies: Deterministic scripts (e.g., vhs/Docker) work best; actual program correctness is not verified—visual alignment only.
- Bold Safe, simulated REPL practice for learners: education, security
- Potential tools/workflows: “SafeShell” sandboxes that show likely terminal outputs without executing code; interactive labs for shell fundamentals; visual feedback on edits/cursor mechanics.
- Assumptions/dependencies: Outputs are approximations; not for teaching deep program semantics; must clearly disclose that results are simulated.
- Bold Conditioning-enhanced rendering for support workflows: customer support, CX
- Potential tools/workflows: Step-by-step troubleshooting videos generated from structured prompts; reprompting/LLM helps compute answers which the NC faithfully renders as UI/CLI outputs.
- Assumptions/dependencies: Heavily reliant on accurate conditioning (reprompts/LLM-planned steps); risk of hallucinated steps; compliance and liability considerations.
- Bold HCI/accessibility prototyping via pointer/interaction modeling: HCI, accessibility
- Potential tools/workflows: Assess hover/click responses, focus indicators, pointer dynamics; visualize impact of larger fonts/high-contrast themes on interaction flows.
- Assumptions/dependencies: Requires datasets with consistent themes and annotated interactions; currently focused on short-horizon transitions.
- Bold Evaluation methodology for “reasoning vs conditioning” in video models: academia
- Potential tools/workflows: Arithmetic probes, reprompting protocols, action-encoding ablations, and OCR-based metrics shared as a benchmark suite; reproducible data-engine recipes.
- Assumptions/dependencies: Compute-heavy (thousands of H100 hours reported); careful interpretation needed—conditioning can mask lack of native symbolic computation.
Long-Term Applications
These require further research and engineering—especially long-horizon reliability, native symbolic processing, stable capability reuse, closed-loop interaction, and runtime governance.
- Bold Completely Neural Computers (CNCs) as learned OS/runtimes: software, hardware
- Potential tools/workflows: “Neural OS” that unifies compute, memory, and I/O in a single learned substrate; applications as programs over latent runtime state; weight-level “reprogramming.”
- Assumptions/dependencies: Must achieve Turing completeness, universal programmability, behavior consistency, and clear advantages over conventional stacks; verifiability and debuggability are open challenges.
- Bold End-to-end desktop/RPA agents that are the interface: enterprise, finance, healthcare admin
- Potential tools/workflows: Agents that internally simulate and execute workflows across heterogeneous apps (billing, claims, back-office ops) with robust long-horizon control.
- Assumptions/dependencies: Closed-loop stability, error recovery, and explicit runtime governance; sector-specific compliance, audit, and data isolation.
- Bold Neural app development and “model-native” app stores: software industry
- Potential tools/workflows: Apps specified by prompts/programs over NC state; packaging, versioning, testing, and deployment pipelines for latent programs; differential updates to behaviors.
- Assumptions/dependencies: Toolchains for reproducibility, state introspection, and compatibility; licensing/IP around weights and datasets.
- Bold Secure, ephemeral “latent-state” sandboxes for malware detonation or safety-critical testing: security, policy
- Potential tools/workflows: High-fidelity neural simulations to observe potential effects of suspicious binaries/UI workflows without touching real systems.
- Assumptions/dependencies: Faithful causal modeling of side effects; determinism and observability guarantees; strong isolation and audit trails.
- Bold Universal UI simulators for training across ecosystems: education, enterprise L&D
- Potential tools/workflows: Broad coverage of productivity suites, EHRs, ERP/CRM, and bespoke tools for scalable onboarding and recurrent training; scenario-based assessments.
- Assumptions/dependencies: Massive, diverse, and licensed datasets; realistic timing/latency models; continual updates to match evolving software.
- Bold Safety-critical UI co-pilots (e.g., EHR, trading terminals): healthcare, finance
- Potential tools/workflows: Neural co-pilots that preview and validate UI actions, provide “dry-run” visualizations, and enforce guardrails by comparing expected vs actual frames before committing.
- Assumptions/dependencies: Verified alignment with domain policies; strict privacy; independent safety monitors; certification and post-hoc explainability.
- Bold Model-in-the-loop UX design and rapid A/B iteration: HCI, product management
- Potential tools/workflows: Generate plausible user-interface dynamics at scale, stress-test flows, and iterate on micro-interactions without live code; “design-to-simulation” pipelines.
- Assumptions/dependencies: Requires behavioral realism and user-model integration; correlations with real user metrics must be validated.
- Bold Device-free “neural desktop streaming”: consumer software, edge/cloud
- Potential tools/workflows: Deliver applications as streamed neural rollouts where the NC handles rendering and input mapping; thin clients with minimal local compute.
- Assumptions/dependencies: Low-latency inference, cost-efficient video diffusion or successor architectures, energy constraints, and robust input-to-state alignment.
- Bold LLM–NC co-processors for agentic systems: AI platforms
- Potential tools/workflows: LLMs do planning/symbolic reasoning; NCs execute and render UI effects; standardized interfaces for action injection, state introspection, and policy enforcement.
- Assumptions/dependencies: Reliable bridges between text plans and action-conditioning streams; monitoring for drift and inconsistent behaviors.
- Bold Regulatory and standards frameworks for neural runtimes: policy, governance
- Potential tools/workflows: Audit logging for latent-state transitions, conformance tests for behavior consistency, provenance and data lineage requirements, red-team protocols.
- Assumptions/dependencies: Methods to safely introspect and govern learned runtime state; consensus on safety and accountability for model-driven execution.
Cross-cutting dependencies and risks
- Compute and cost: Training and inference for high-capacity video models are resource-intensive; deployment hinges on more efficient architectures or hardware acceleration.
- Data and licensing: High-quality, synchronized frame/action/text logs are essential; privacy and IP constraints must be addressed.
- Generalization and reliability: Current strength is short-horizon control and rendering; long-horizon consistency, error recovery, and native symbolic reasoning remain open.
- Evaluation clarity: Conditioning (e.g., reprompting/LLM assistance) can inflate apparent “reasoning.” Benchmarks must distinguish native computation vs conditioning-assisted performance.
- Environment control: Fidelity depends on fonts, palettes, timing, and deterministic rendering; variability across real-world setups degrades performance.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve training stability. "Optimization uses AdamW (learning rate , weight decay ), bfloat16 precision, and gradient clipping at 1.0."
- Action-conditioned rendering: Generating future frames conditioned on actions so the visuals reflect user inputs. "GUIWorld captures desktop RGB with synchronized mouse/keyboard traces to validate action-conditioned rendering and control on GUIs."
- Action injection: The design choice of how to feed action signals into a model’s inputs to influence predictions. "we evaluate standard world-model designs across action injection, action encoding, and data quality."
- ANSI-faithful decoding: Accurate interpretation of terminal control sequences following ANSI standards during replay or rendering. "The asciinema stack records and replays terminal sessions with synchronized timing and ANSI-faithful decoding."
- Auxiliary heads: Additional model branches used to encode or decode side information (e.g., prompts or actions) alongside the main output. "Auxiliary heads can encode and decode prompts, buffers, or action traces, shifting functionality that would traditionally live in OS queues, device drivers, and UI toolkits into latent-state dynamics."
- bfloat16: A 16-bit floating-point format with a wider exponent than IEEE FP16, often used to save memory while maintaining dynamic range. "Optimization uses AdamW (learning rate , weight decay ), bfloat16 precision, and gradient clipping at 1.0."
- CLIP image encoder: A vision encoder from CLIP that maps images to embeddings aligned with text semantics. "a CLIP image encoder~\citep{radford2021learning} extracts visual features from the same frame"
- Completely Neural Computer (CNC): The mature form of a neural computer that is fully learned and meets strong computational and programming criteria. "The long-term target is a Completely Neural Computer (CNC), the mature, general-purpose realization of this machine form"
- Conditioning stream: A time-indexed sequence of inputs (e.g., actions, prompts) provided to a model to steer predictions. "the input sequence is referred to as a conditioning stream."
- Decoupled cross-attention: A cross-attention mechanism that separately injects conditioning context (e.g., text and image features) into the model. "Decoupled cross-attention injects the joint caption and first-frame context derived from the CLIP and text features."
- Diffusion noise: The noise injected into the diffusion process during training or sampling in diffusion models. "these conditioning features are concatenated with diffusion noise"
- Diffusion-style video models: Generative video models based on diffusion processes operating in latent or pixel space. "z for VAE/video latents used in diffusion-style video models (e.g., \Cref{section:impl-guiworld})."
- Diffusion transformer: A transformer architecture used within diffusion models to iteratively denoise latent representations. "the diffusion transformer acts as the state-update map"
- Differentiable Neural Computer: A neural architecture with differentiable external memory enabling learned algorithmic behavior. "Neural Turing Machine / Differentiable Neural Computer line~\citep{graves2014neural,graves2016hybrid}"
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation to train larger models. "Training uses gradient checkpointing and applies dropout 0.1 to the prompt encoder, CLIP, and VAE modules."
- Gradient clipping: A stabilization method that limits the norm or value of gradients to prevent exploding updates. "Optimization uses AdamW (learning rate , weight decay ), bfloat16 precision, and gradient clipping at 1.0."
- Image-to-video (I2V): Generating future video frames from a starting image (and possibly text) as conditioning. "Following the Wan2.1 image-to-video (I2V) design, these conditioning features are concatenated with diffusion noise, projected through a zero-initialized linear layer, and processed by a DiT stack."
- I/O alignment: Maintaining consistency between a model’s internal state and its observable inputs/outputs over time. "most notably I/O alignment and short-horizon control."
- I2V sampling schedule: The prescribed sequence of denoising steps used when sampling from an image-to-video diffusion model. "under the original Wan2.1 I2V sampling schedule, without additional binary masks or periodic reseeding."
- Instruction set architecture: The abstract interface (instructions, registers, etc.) between software and hardware for a computer. "they are commonly abstracted as random-access machines with an instruction set architecture"
- Levenshtein distance: An edit distance metric measuring the minimum number of insertions, deletions, or substitutions to transform one string into another. "Character accuracy uses the Levenshtein distance between concatenated ground-truth and generated texts."
- Monotonic clock: A time source that only moves forward, used for consistent timing and synchronization. "Frames, text buffers, and keyboard-event logs share a single monotonic clock."
- Neural Computer (NC): A neural system whose single learned state unifies computation, memory, and I/O as a running computer. "We term this abstraction a Neural Computer (NC): a neural system that unifies computation, memory, and I/O in a learned runtime state."
- Neural Turing Machine: A neural architecture that augments a controller with differentiable memory addressing to mimic algorithmic behavior. "Neural Turing Machine / Differentiable Neural Computer line~\citep{graves2014neural,graves2016hybrid}"
- OCR: Optical Character Recognition; extracting text from images. "OCR accuracy versus training."
- Open-loop evaluation: Assessing a model by feeding pre-recorded inputs without interactive feedback from the environment. "evaluation remains open-loop rather than closed-loop interaction with a live environment."
- PSNR: Peak Signal-to-Noise Ratio; a perceptual metric for reconstruction fidelity between images or frames. "PSNR/SSIM plateau around 25k steps (Figure~\ref{fig:cligen-long-train})"
- Random-access machine: An abstract computational model assuming constant-time memory access used in algorithmic analysis. "they are commonly abstracted as random-access machines with an instruction set architecture"
- REPL: Read–Eval–Print Loop; an interactive programming environment that reads inputs, evaluates them, and prints results. "interactive REPL usage"
- Reprompting: Modifying or strengthening prompts to steer a model toward better performance on a task. "reprompting improves symbolic probes (4\%83\%; Figure~\ref{fig:cligen-exp6})"
- Short-horizon control: Control over immediate, near-future actions or responses rather than long-range planning. "most notably I/O alignment and short-horizon control."
- T5: A transformer-based text encoder/decoder model used for embedding or generation tasks. "a text encoder (e.g., T5~\citep{raffel2020exploring}) embeds the caption."
- Turing complete: Capable of performing any computation given enough time and memory. "(i) Turing complete, (ii) universally programmable, (iii) behavior-consistent unless explicitly reprogrammed,"
- Universally programmable: Able to be programmed to implement any desired behavior within its computational limits. "(i) Turing complete, (ii) universally programmable, (iii) behavior-consistent unless explicitly reprogrammed,"
- Update-and-render loop: A pattern where a system updates its internal state from inputs and then renders the next observable output. "folds these roles into an update-and-render loop."
- Variational Autoencoder (VAE): A probabilistic latent-variable model that encodes inputs into a latent distribution and decodes samples back to data space. "The VAE encodes and decodes terminal frames."
- World models: Learned models of environment dynamics used for prediction, planning, or imagination. "World models~\citep{ha2018world} show that neural networks can internalize environment dynamics and support predictive imagination"
- Zero-initialized linear layer: A linear layer whose weights are initialized to zero, often to control early training behavior. "projected through a zero-initialized linear layer"
Collections
Sign up for free to add this paper to one or more collections.

