Mirage Probes: How Vision Models Fake Visual Understanding
Abstract: Vision-LLMs (VLMs) can answer image-based questions confidently, and often correctly, even when no image is provided. This mirage behavior inflates benchmark scores without reflecting visual grounding. Prior work treats this as a single failure mode. We argue it is two. Using Mirage Probes, a contrastive probing framework that pairs paraphrased question variants with matched mirage and non-mirage labels on the same image, we show that mirage behavior is linearly decodable from internal activations across residual stream, MLP, post-attention, and attention-head sites in two open-source VLMs. We demonstrate that a Naive Bayes text baseline cannot recover this signal, ruling out surface lexical confounds. Cross-benchmark separability patterns, together with a novel Prior Harnessing Index (PHI) measuring how much a model can answer from text alone, expose two distinct regimes: textual biases, where the model answers from language priors without engaging visual representations, and spurious images, where it constructs false visual content in latent space and answers as if grounded. The distinction has direct mitigation consequences: text-distribution cleaning can address the first regime but cannot reach the second, since spurious-image mirages live in the model's visual representations rather than its text. Faithful visual grounding will require interventions at the representational level.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a strange behavior in vision-LLMs (VLMs)—AI systems that read text and look at images. The authors show that these models can sometimes answer image-based questions confidently even when no image is given. They call this a “mirage,” like thinking you see water in a desert when it’s not really there. The paper explains that there are actually two kinds of mirages and introduces a new way, called Mirage Probes, to detect and study them inside the model.
The big questions the paper asks
- When a VLM gives a confident answer, is it truly using the picture, or is it guessing based on patterns in the text?
- Are all “mirages” the same, or are there different types?
- Can we find signs of these mirages inside the model’s “brain” (its internal activations) while it’s answering?
- If there are different types, how should we fix them?
How the researchers studied it (in simple terms)
To understand the model’s behavior, the authors used three main ideas:
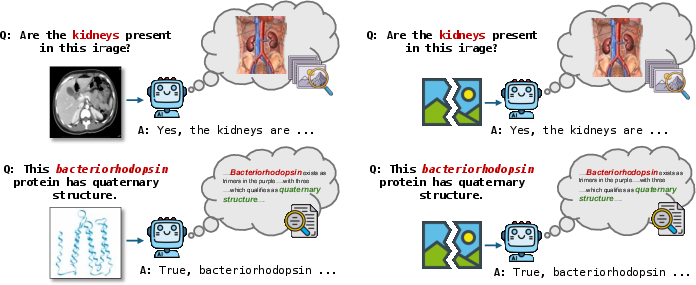
- Mirage behavior: They asked the model a question with an image and then asked the same question without the image. If the model gave basically the same answer both times, they treated it as a “mirage”—the model didn’t really need the image to answer.
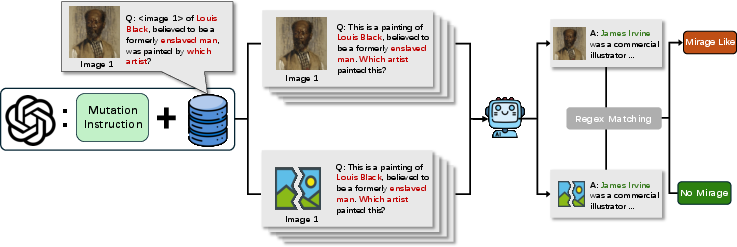
- Contrastive pairs: For each question, they made small rewordings (like saying “What color is the car?” vs. “What’s the car’s color?”). Some versions triggered a mirage, others didn’t. By comparing these nearly identical versions, they reduced “text tricks” and focused on the real cause.
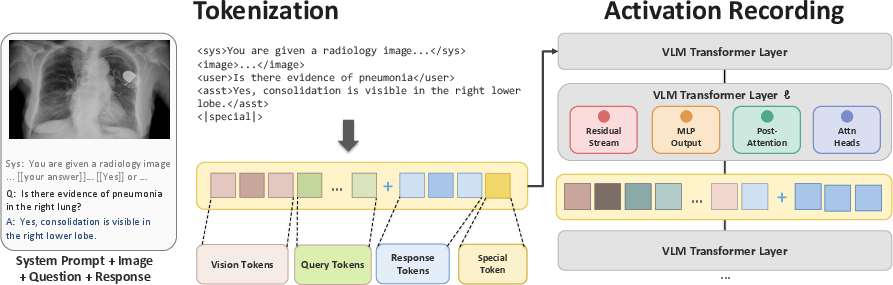
- Probing inside the model: Think of the model as a layered machine. At each layer, the model forms internal signals (like thoughts). The authors “peeked” at these signals and trained simple detectors (called probes) to predict whether the model was about to produce a mirage. If a very simple detector can do this well, it means the mirage signal is clearly present inside the model.
Key terms explained with analogies:
- Linear probe: Imagine plotting two kinds of dots on paper (mirage vs. non-mirage). If a straight line can separate them, that’s “linear.” A linear probe checks if a straight-line rule can tell the two apart from the model’s internal signals.
- Difference probe: Compare the model’s internal “thoughts” when it has the image vs. when it doesn’t. Subtract one from the other. If that difference clearly tells mirages apart, it means the way the image changes the model’s thoughts relates to mirages.
- Residual stream, MLP, attention heads: These are parts of the model’s internal pipeline—like different rooms in a factory. The authors checked many rooms to see where the mirage signal shows up.
- Naive Bayes text baseline: A simple text-only classifier used as a sanity check. If this weaker baseline does worse than the probes, it suggests the probes found something deeper than just surface words.
They also introduced a simple score called Prior Harnessing Index (PHI): it measures how much the model can guess the correct answer from the question text alone (without the image). Higher PHI means the question text itself gives away the answer; lower PHI means you really need the image.
What they discovered and why it matters
The authors found four main things:
- The mirage signal is inside the model’s “brain” when the image is present
- Even with the image, the model sometimes behaves as if it didn’t need it.
- Simple, straight-line probes could reliably spot mirage patterns in many parts of the model (residual stream, MLP layers, attention heads). This means the model’s internal signals carry a clear “mirage” fingerprint.
- The best detector compared image-vs-no-image internal signals
- “Difference probes” (subtracting with-image and without-image activations) worked especially well.
- This suggests mirages are closely tied to how the image changes the model’s internal state.
- It’s not just about surface words
- A simple text-only baseline (Naive Bayes) usually did worse than the probes (especially in the careful, contrastive setup). That means the probes aren’t just picking up on obvious words—they’re detecting deeper internal behavior.
- There are two different kinds of mirages
- Textual biases: The model guesses the answer from common patterns in the question text (like test-taking tricks) and basically ignores the image.
- Spurious images: The model “imagines” visual details that aren’t in the picture and answers as if those details were real.
- Which type shows up depends on the dataset and how informative the text is. In a medical set (VQA-RAD) where you really need the image, the model showed more signs of “spurious images.” In general or multiple-choice sets, where text clues are stronger, “textual bias” mirages were more common.
Why this matters:
- If we only clean up text patterns (like removing obvious shortcuts), we might fix textual-bias mirages but not the spurious-image ones—because those live inside the model’s visual representations.
- To truly ground answers in images, we’ll need methods that change or monitor the model’s internal visual representations, not just its training text.
What this could change going forward
- Better testing: Benchmarks should check whether a model truly uses the image, not just whether it gets the right answer.
- Smarter fixes: Cleaning up text shortcuts helps, but it’s not enough. We also need “representational” fixes—tools that alter or constrain what the model encodes about the image so it doesn’t “imagine” things.
- Safer use in sensitive areas: In medicine or science, making sure answers are actually grounded in the image is crucial. Mirage Probes give a way to diagnose when models are faking visual understanding.
In short
- The paper shows that VLMs can look like they understand images even when they don’t, and this “mirage” lives inside their internal signals.
- There are two flavors: guessing from text and imagining fake visuals.
- The authors’ Mirage Probes can detect these behaviors inside the model, and their results suggest we need deeper changes—beyond text cleanup—to ensure models truly look at and reason about images.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a consolidated list of specific gaps and questions the paper leaves open, prioritized to enable actionable follow-up work:
- Causal validation of probe directions: Do the linear directions identified actually cause mirage behavior? Test via activation patching, steering, causal scrubbing, or head ablations to flip mirage↔non-mirage outcomes.
- Mechanistic localization: Which layers, MLPs, heads, and pathways encode mirage features? Map circuits (e.g., per-head attribution, path patching) rather than reporting only best-layer accuracies.
- Vision-encoder null result: Why was no mirage signal found in the vision encoder/projection layers? Revisit with finer-grained patch-level activations, position-wise analysis, and alternative pooling to determine if this is a methodological artifact or genuine.
- Temporal dynamics: When during decoding does the mirage signal emerge? Replace pooled-token averages with time-resolved analyses (per-token, early vs late layers, first-token logits).
- Labeling reliability: Quantify and reduce label noise from the heuristic scheme (cosine threshold 0.7, regex detection, ambiguity handling). Provide sensitivity analyses over thresholds, and add human validation.
- Ambiguous class handling: The “ambiguous” category is introduced but not deeply analyzed; assess its prevalence, characteristics, and impact on probe training, or develop principled strategies to utilize/resolve it.
- Paraphrase integrity: Verify that GPT-generated question mutations preserve semantics and do not introduce stylistic artifacts. Add semantic similarity checks, adversarial paraphrases, controlled templates, and human audits.
- Stronger text-only baselines: Go beyond Naive Bayes (e.g., TF-IDF logistic regression, transformer classifiers, prompt-tuned LMs) to more rigorously rule out residual textual confounds.
- Vision-only and hybrid baselines: Include image-only classifiers and multi-modal text+image baselines to quantify the unique contribution of internal representations vs surface-level signals.
- Difference-probe interpretation: High accuracy on Δ-activations may reflect “image-present vs image-absent” artifacts. Control with counterfactual images, randomized vision tokens, or masked image content to isolate mechanism-relevant deltas.
- Cross-model transfer: Do probes trained on one model (e.g., Ovis) generalize to another (e.g., Qwen)? Assess invariance of mirage directions across architectures/scales and to closed-source VLMs.
- Cross-benchmark generalization: Train on one benchmark and test on others to quantify dataset-specific vs mechanism-general signals.
- PHI metric robustness: Formalize how probabilities are computed (especially for free-form answers), calibrate scores, provide CIs, test alternate text-only answerability measures (e.g., conditional MI), and report PHI for all models, not only Ovis.
- Human vs model image reliance: Replace LLM-based “human” annotations with expert human labels; measure agreement with PHI and explain divergences.
- Mechanism disentanglement: Develop instance-level classifiers or latent-variable models to assign examples to “spurious-image” vs “textual-bias” mechanisms; validate with targeted causal interventions.
- Mitigation interventions: Implement and evaluate concrete methods for spurious-image mirages (e.g., grounding losses, contrastive representational regularizers, head-level constraints) versus text-distribution cleaning for textual-bias mirages.
- Data limitations and imbalance: Address small, skewed datasets (e.g., few non-mirage examples on GLM/MicroVQA) by collecting balanced data, reporting power analyses, and testing robustness to sample size.
- Pooling choices: Systematically compare pooling schemes (attention-weighted, CLS-like tokens, per-head pooling) and report how they affect decodability, especially in vision/projection layers.
- Prompting and tokenization confounds: Test sensitivity to system prompts, chat templates, and tokenizers; ensure probe signals are robust to these choices.
- Per-question-type granularity: Analyze mirage prevalence and separability by question type (yes/no, counting, attributes), domain, and answer correctness.
- Evaluation completeness: Report ROC/AUPRC, calibration metrics, per-layer distributions, and uncertainty estimates to contextualize probe performance and threshold selection for deployment.
- Real-world utility: Assess whether probe-based mirage detection improves safety or accuracy in downstream tasks (e.g., filtering ungrounded medical responses) without undue false positives.
- Counterfactual visual tests: Use occlusions, image scrambling, and semantically similar distractors to separate textual-bias from spurious-image mechanisms under controlled visual perturbations.
- Training provenance effects: Analyze how pretraining corpora, SFT, and RLHF stages influence mirage mechanisms; run controlled training ablations on small models to establish causation.
- Unsupervised/online detection: Explore low-latency, unsupervised or self-diagnostic signals for mirage detection at inference time, minimizing compute overhead.
- Dataset and code completeness: Release full annotated datasets (including paraphrases), labeling scripts, and detailed configs; document licenses and reproducibility steps.
- Correctness-conditioned analysis: Distinguish correct vs incorrect mirages; determine whether probes can detect ungrounded-but-correct answers and how this interacts with mechanism type.
- Alternative contrastive constructions: Create pairs by swapping images (real vs distractor) with fixed text, or vice versa, to orthogonalize text and vision contributions to the mirage label.
- Head-level causal edits: Identify and test low-rank head edits or steering vectors that suppress mirages while preserving grounded performance.
- Long-context and multi-turn effects: Examine whether longer histories or dialogue structure amplify mirages and how probe signals evolve with context length.
- Broader modality coverage: Extend analyses beyond VQA to documents, charts, diagrams, and videos to test mechanism generality.
Practical Applications
Below is a distilled set of practical applications derived from the paper’s findings, methods, and innovations. Each item specifies where it applies, what tools/workflows could look like, and feasibility notes.
Immediate Applications
- Visual grounding audit during model release (“Mirage Audit”)
- Sectors: Software/AI, Healthcare, Robotics, Finance (document KYC), Education.
- Tools/workflows: Add Mirage Probes (linear and difference-of-activations probes) plus PHI computation to CI/CD; run dual-pass inference (with- and without-image) on task-specific holdouts; flag models with high mirage rates before deployment.
- Assumptions/dependencies: Requires access to internal activations for best results (white-box or open-source VLMs); for closed APIs, fallback to output-only dual-pass checks and PHI approximations; compute overhead for dual-pass runs.
- Deployment-time “visual grounding confidence” meter in user interfaces
- Sectors: Healthcare image viewers, Document AI apps, Consumer camera assistants, Accessibility tools for visually impaired.
- Tools/workflows: Run a lightweight linear probe on cached activations and/or compare with-vs-without-image outputs; display a grounding score and add guardrails (e.g., “I’m not confident this used the image”).
- Assumptions/dependencies: Requires batching or caching activations and a calibrated threshold; may need UI/UX adjustments to communicate uncertainty.
- Guardrails that trigger “ask for evidence” or “defer to human” on suspected mirages
- Sectors: Clinical decision support, Document processing in finance/insurance, Industrial inspection, Robotics (operator-in-the-loop).
- Tools/workflows: If the mirage probe fires or the with/without-image shift is small, require the model to highlight image regions supporting the answer or route to a human checker; in robots, inhibit actions and request a new observation.
- Assumptions/dependencies: Needs integration with attention/region-highlighting or evidence-generation modules; latency budget for guardrail logic.
- Data curation to reduce textual-bias mirages
- Sectors: Benchmarking providers, Model training teams, Education/assessment creators.
- Tools/workflows: Use PHI and dual-pass analysis to identify questions solvable from text-only priors; rewrite or filter such items; include contrastive paraphrase variants that hold semantics constant but reduce shortcut cues.
- Assumptions/dependencies: PHI is easiest in multiple-choice; free-form tasks need careful probability estimation; domain experts may be required for high-stakes datasets.
- Model selection and task routing based on PHI and mirage scores
- Sectors: MLOps platforms, Large enterprises with model catalogs, Healthcare IT.
- Tools/workflows: Maintain per-task PHI distributions and mirage probe scores; select models with lower mirage propensity for visual-evidence-heavy tasks; route cases with high mirage risk to conservative workflows.
- Assumptions/dependencies: Requires per-domain calibration; mirage tendencies are dataset- and model-specific.
- Red teaming and compliance reporting for multimodal systems
- Sectors: Healthcare compliance (e.g., hospital QA), Automotive (autonomy safety), Government/Defense procurement.
- Tools/workflows: Include “Mirage Probes” and PHI metrics in audit reports; run stress tests with paraphrased question variants; quantify rates of textual-bias vs spurious-image regimes.
- Assumptions/dependencies: Current labels are heuristic; reports should communicate uncertainty and confidence intervals.
- Benchmark improvement and challenge set construction
- Sectors: Academia, Evaluation vendors, Public benchmarks (e.g., VQA, DocVQA).
- Tools/workflows: Assess benchmark items for high PHI (text-only solvable) and augment with low-PHI, visually grounded items; publish mirage-aware splits and contrastive paraphrase pairs.
- Assumptions/dependencies: Benchmark revisions require community coordination; mirage tendencies can evolve with new model families.
- Lightweight runtime mirage screening for document workflows
- Sectors: Finance (KYC/AML), Insurance claims, Enterprise OCR-free pipelines.
- Tools/workflows: For every extracted field/answer, run a quick with/without-image check; if unchanged or flagged by a linear probe, require the model to cite coordinates/regions or reject the answer.
- Assumptions/dependencies: Works best with models that expose token-level or region-level evidence; performance depends on document variability.
Long-Term Applications
- Representational interventions to suppress spurious-image mirages
- Sectors: Foundation model labs, Safety research groups, Robotics.
- Tools/workflows: Identify linearly decodable “mirage directions” and penalize them during fine-tuning; apply activation steering, representation surgery, or contrastive losses that reward true visual grounding.
- Assumptions/dependencies: Requires stable identification of causal directions and careful evaluation to avoid harming genuine visual reasoning.
- Training-time reward shaping for grounding
- Sectors: Model training, RLHF/RLAIF practitioners.
- Tools/workflows: Incorporate mirage probe signals, with/without-image differences, and PHI into rewards; penalize correct answers achieved without visual engagement; encourage evidence alignment (e.g., pointing to supporting pixels).
- Assumptions/dependencies: RL signal design must avoid trivial solutions (e.g., always claiming uncertainty); needs human oversight on false positives.
- Architectural changes to enforce modality dependence
- Sectors: Vision-LLM developers, Robotics platforms.
- Tools/workflows: Cross-modal gating, routing, or attention constraints that condition language on vision tokens; “image-ablation adversaries” during training to ensure output shifts when images change.
- Assumptions/dependencies: May reduce model flexibility; careful design needed to balance robustness and performance.
- Standardization of visual grounding metrics (PHI + mirage rates)
- Sectors: Standards bodies, Regulators, Industry consortia.
- Tools/workflows: Define reporting requirements for PHI distributions, with/without-image consistency, and mirage probe performance as part of model cards and safety disclosures.
- Assumptions/dependencies: Consensus-building across vendors; metrics must be resilient to gaming and cover multiple task formats.
- Certification frameworks for safety-critical multimodal AI
- Sectors: Healthcare (FDA/CE), Automotive (ISO 26262 extensions), Aviation.
- Tools/workflows: Include mirage detection and grounding stress tests in pre-certification; require evidence-backed answers or conservative fallbacks in clinical/operational settings.
- Assumptions/dependencies: Regulatory acceptance; demonstration that tests correlate with real-world safety.
- Black-box mirage proxies for closed APIs
- Sectors: Enterprises using proprietary VLMs, SaaS integrators.
- Tools/workflows: Develop statistically robust black-box tests using dual-pass outputs, paraphrase contrast sets, and response-similarity thresholds to approximate mirage risk; optionally integrate calibration and abstention policies.
- Assumptions/dependencies: Less sensitive than activation-level probes; may need larger test suites and careful thresholding.
- Robust perception for embodied AI and autonomy
- Sectors: Robotics, Drones, ADAS/Autonomous vehicles.
- Tools/workflows: Real-time mirage monitors gating action policies; when mirage risk is high, defer to traditional perception stacks or request additional sensing.
- Assumptions/dependencies: Tight latency constraints; multi-sensor fusion complicates attribution of “visual grounding.”
- Instructional and assessment tools that enforce image-based reasoning
- Sectors: EdTech, Scientific training platforms.
- Tools/workflows: Tutors that verify visual grounding before scoring responses; require students—and models—to highlight supporting visual regions, discouraging text-only shortcuts.
- Assumptions/dependencies: Requires reliable evidence-localization features and content authoring pipelines.
- Data engine feedback loops using mirage detection
- Sectors: Model builders, Data platforms.
- Tools/workflows: Use mirage probes to prioritize data collection where models over-rely on priors; auto-generate counterexamples that break textual shortcuts or contradict spurious visual priors.
- Assumptions/dependencies: Synthetic counterexamples must be high-quality and diverse to avoid overfitting.
- Privacy-preserving mirage analytics
- Sectors: Healthcare/Finance (sensitive data environments).
- Tools/workflows: Explore on-device or federated computation of mirage probes and PHI; store only aggregate metrics to reduce leakage risk.
- Assumptions/dependencies: Requires efficient, low-leakage instrumentation and governance processes.
- Evidence-first product features (“show your evidence”)
- Sectors: Consumer assistants, Enterprise AI copilots, Medical imaging viewers.
- Tools/workflows: Couple grounding metrics with mandatory evidence visualization (cropped regions, heatmaps); down-rank or block answers lacking visual support.
- Assumptions/dependencies: Evidence maps must be faithful; potential UX complexity and user trust considerations.
Notes on feasibility and adoption
- The paper’s strongest immediate lever is detection: simple linear and difference-of-activation probes plus dual-pass output checks provide practical, deployable safeguards today. Long-term efficacy hinges on developing causal, representational mitigations—an active research frontier.
- Results were shown on two open-source VLMs and specific VQA-style datasets; organizations should validate calibrations on their own models, domains, and latency budgets before enforcing hard gates.
Glossary
- Activation patching: A mechanistic interpretability intervention that replaces internal activations to test causal roles of features or directions. "validating it will require interventions such as steering, ablations, or activation patching."
- Attention head: A sub-module in a Transformer layer that computes attention with its own parameters, often probed individually. "and individual attention head outputs at every layer."
- B-Clean criterion: A labeling rule where questions deemed unanswerable without the image are treated as safe non-mirage cases. "labeling non-mirage examples with the B-Clean criterion described by \citet{asadi2026mirage}"
- Contrastive difference probe: A probe trained on the elementwise difference between with-image and without-image activations to detect image-induced representational shifts. "contrastive difference probes recover the signal most cleanly."
- Contrastive pairs: Matched example pairs that differ only in the target property, reducing surface confounds for probes. "Linear probes benefit substantially from training on contrastive pairs, where positive and negative examples differ only in the property of interest"
- Decoder-only pass: A forward pass through a decoder-only LLM over the tokenized conversation (including image tokens). "the model conducts an LLM decoder-only pass over the full conversation"
- GELU activation function: A smooth nonlinearity (Gaussian Error Linear Unit) commonly used in Transformer MLPs. "a hidden dimension of 512, and a GELU activation function."
- Linear probe: A simple linear classifier applied to intermediate activations to test decodability of a property. "Linear probes distinguish mirage-associated from non-mirage-associated image-conditioned generations across multiple activation sites"
- Mirage Probes: The paper’s proposed contrastive, representation-level probing framework for diagnosing mirage behavior in VLMs. "we introduce Mirage Probes, a contrastive probing framework for mirage behavior."
- Modality bypass: A failure mode where a multimodal model ignores one modality (e.g., the image) and answers from another (e.g., text). "Image-absent generation and modality bypass."
- Naive Bayes textual baseline: A text-only classifier baseline used to check whether probe signals reduce to surface lexical patterns. "A Naive Bayes textual baseline trained on response text is consistently weaker than our contrastive probes"
- Post-attention output: The activation vector after the attention sublayer in a Transformer block, before or after residuals. "post-attention outputs, and individual attention head outputs at every layer."
- Prior Harnessing Index (PHI): A metric quantifying how much a model can infer the correct answer from text alone (vs. a null prompt). "which represents the amount of information a model is able to glean regarding a correct final answer from a purely textual input distribution."
- Projection layer: The learned mapping that projects vision encoder features into the LM’s embedding space as tokens. "we initially included the vision encoder and the projection layers but found their representations carried no detectable mirage signal"
- Residual stream: The running hidden representation in Transformer blocks that carries information across layers via residual connections. "residual stream states, MLP outputs, post-attention outputs, and individual attention head outputs"
- Reward hacking: Exploiting a training objective or reward signal to achieve high scores via unintended strategies. "We hypothesize that these two distinct mechanisms are natural consequences of VLM reward hacking~\citep{skalse2025defining}"
- Spurious images: Internally constructed, unsupported visual content in latent space that the model treats as if grounded. "spurious images, where it constructs false visual content in latent space and answers as if grounded."
- Steering (causal steering): An intervention that nudges internal activations along hypothesized causal directions to test effects on behavior. "we cannot use causal steering to verify that our probes have truly picked up on a mirage representation."
- Textual biases: Answering driven by language priors or dataset regularities without engaging visual representations. "textual biases, where the model answers from language priors without engaging visual representations"
- Vision encoder: The component that converts images into feature representations before projection into tokens. "Any images are first processed by the model's vision encoder and then projected into vision tokens"
- Vision tokens: Tokenized representations of image features inserted into the LM’s sequence. "then projected into vision tokens"
- Vision-LLM (VLM): A multimodal model jointly processing visual and textual inputs. "Vision-LLMs (VLMs) are increasingly used for tasks that require faithful visual understanding"
- Visual grounding: Ensuring that model outputs are supported by evidence in the visual input. "Faithful visual grounding will require interventions at the representational level."
Collections
Sign up for free to add this paper to one or more collections.