Seeing but Not Believing: Probing the Disconnect Between Visual Attention and Answer Correctness in VLMs
Abstract: Vision-LLMs (VLMs) achieve strong results on multimodal tasks such as visual question answering, yet they can still fail even when the correct visual evidence is present. In this work, we systematically investigate whether these failures arise from not perceiving the evidence or from not leveraging it effectively. By examining layer-wise attention dynamics, we find that shallow layers focus primarily on text, while deeper layers sparsely but reliably attend to localized evidence regions. Surprisingly, VLMs often perceive the visual evidence when outputting incorrect answers, a phenomenon we term ``seeing but not believing'' that widely exists in major VLM families. Building on this, we introduce an inference-time intervention that highlights deep-layer evidence regions through selective attention-based masking. It requires no training and consistently improves accuracy across multiple families, including LLaVA, Qwen, Gemma, and InternVL. These results show that VLMs encode reliable evidence internally but under-utilize it, making such signals explicit can bridge the gap between perception and reasoning, advancing the diagnostic understanding and reliability of VLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how vision-LLMs (VLMs) answer questions about pictures. These are AI systems that read a question, look at an image, and try to give the right answer. The surprising problem the authors found is that even when the model “sees” the correct part of the image, it often still gives a wrong answer. They call this “seeing but not believing.”
What questions did the paper ask?
The authors wanted to understand and fix the gap between what a model looks at and the answer it gives. In simple terms, they asked:
- How does the model switch focus between the words in the question and the picture as it thinks?
- Which parts of the model are best at finding the important spots in the image?
- Do models still look at the right visual evidence even when they answer incorrectly?
- Why do models fail to use what they’ve already “seen” to produce correct answers?
How did they study it?
Think of a VLM like a person reading a question and scanning a picture step by step. Inside the model, there are layers that act like different stages of thinking. The authors examined these layers to see where the model focuses its “attention” — attention is like a spotlight that shows which text words or image patches the model is paying most attention to.
Here’s their approach, explained with everyday ideas:
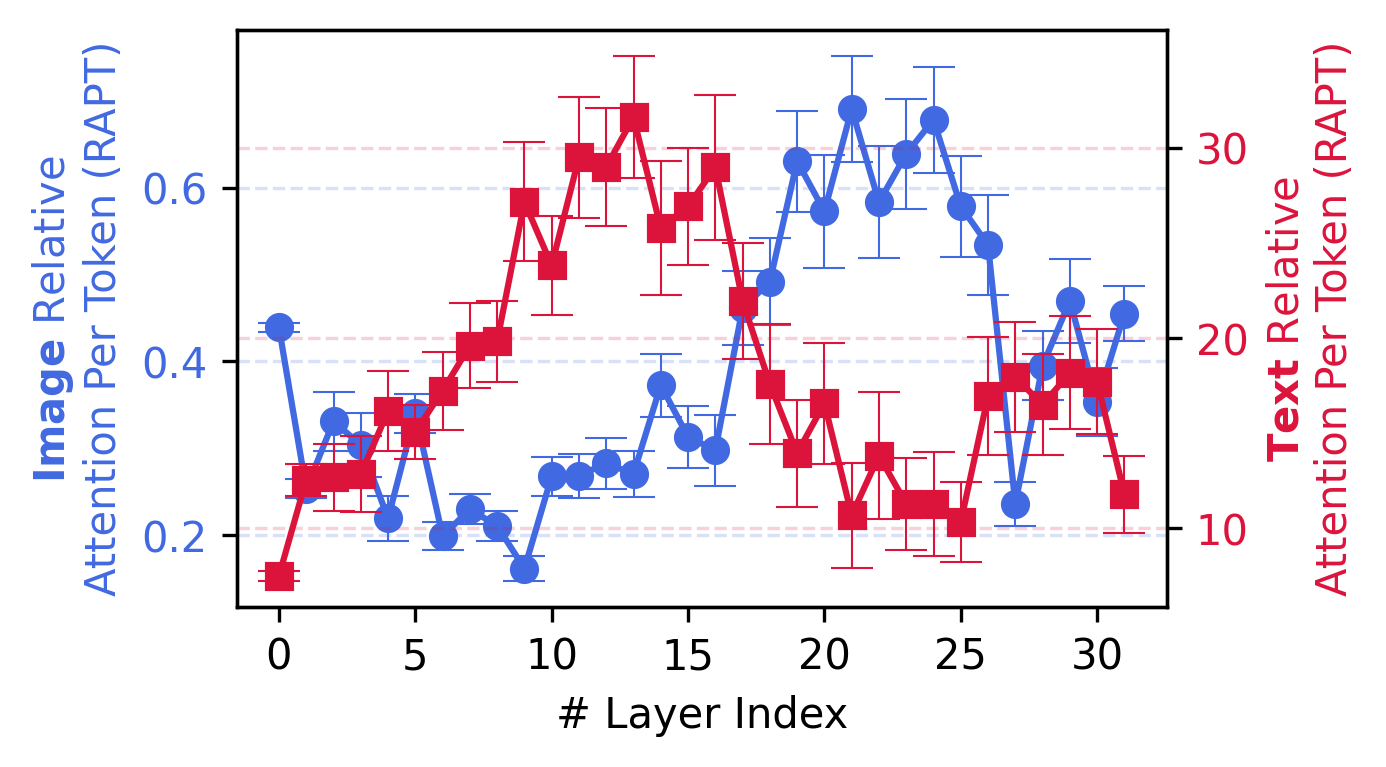
- Layer attention tracking: They measured, layer by layer, how much the model looks at the question text versus the image. Early layers act like “reading the question,” and later layers act like “looking closely at the picture.”
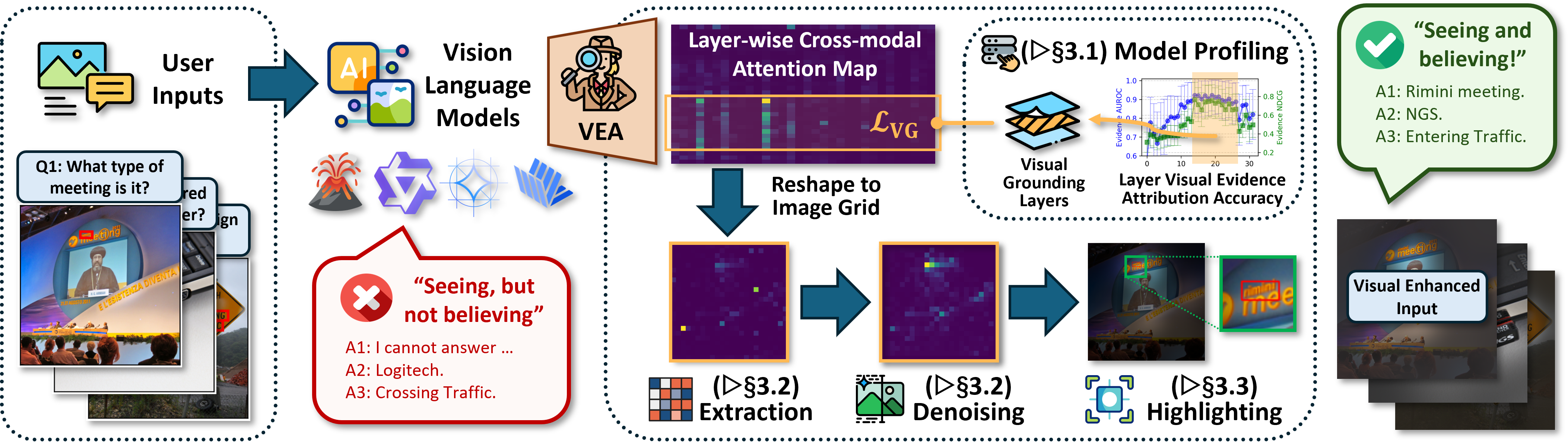
- Visual evidence checking: They used datasets where humans had marked the exact regions in images that contain the needed information (like drawing boxes around a price on a receipt or a sign in a photo). They then checked if the model’s attention matched these evidence regions.
- A simple fix called Vea: They built a training-free method that works during inference (when the model answers). Vea finds the deep layers that are best at spotting evidence, creates a soft mask that gently highlights those regions in the original image (like using a highlighter), and feeds that highlighted image back to the model. This helps the model not just “see” the right spot but also “use” it while answering.
To make the highlighting clean and helpful:
- They remove random noisy spots by comparing each patch to its neighbors (like ignoring a bright speck that doesn’t match the area around it).
- They smooth the mask so highlighted regions look natural, not blocky (like softly blending your highlighter instead of drawing pixelated squares).
- They adjust brightness so important areas stay clear while less-important areas get slightly dimmer.
They tested this on multiple models (LLaVA, Qwen, Gemma, InternVL) and tasks that require finding fine details, such as reading text in images (e.g., InfoVQA, DocVQA, SROIE, TextVQA).
What did they find and why it matters
The authors found several important things:
- Attention shifts over layers: Early layers focus mostly on the question text. As the model goes deeper, it looks more at the image and concentrates on the specific regions that matter — like a spotlight narrowing in on the clue.
- Deep layers find the right evidence: Later layers don’t spread attention everywhere. They lock onto the correct parts of the image that contain the answer.
- “Seeing but not believing”: Even when the model looks at the right evidence, it often still answers wrong. So the problem isn’t always that the model fails to see — sometimes it fails to use what it sees when generating its final answer.
- The Vea method helps: Without any extra training, highlighting the evidence regions improved accuracy across many models and tasks. In simple terms, making the important parts of the image more obvious helped the models give better answers. The improvements were consistent and sometimes large, especially for smaller models.
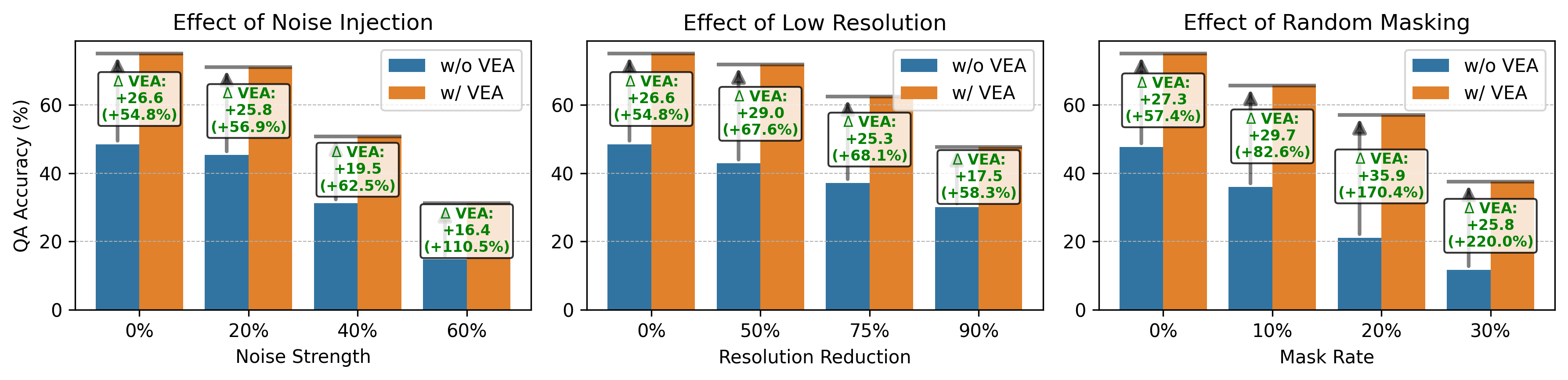
- Robustness: Vea made models more resilient to bad image conditions like noise, low resolution, or missing patches. Even when images were damaged or blurry, guided highlighting helped the model stay on track.
Why does “seeing but not believing” happen?
The authors suggest two simple reasons:
- Text dominates: These systems are built on powerful LLMs, so they sometimes trust patterns in text too much. If a common word association appears (like brand names often paired with certain product parts), the model may “hallucinate” details that aren’t in the image, despite seeing the correct visual evidence.
- Under-using context: Just like a student who has the textbook open but still doesn’t use the relevant paragraph to answer a question, models sometimes don’t make full use of the useful information right in front of them.
What’s the impact?
This research shows that VLMs already have a lot of the right visual signals inside them — they often know where to look — but they need help bringing that into the final answer. The Vea method is a simple, training-free way to make that evidence clearer during answering, improving accuracy and reliability across different model families. In the future, this could lead to:
- More trustworthy AI systems for reading and understanding documents, signs, and scenes.
- Better tools for medical images, receipts, forms, and other tasks that depend on precise visual details.
- New designs that balance text and vision more fairly, helping models use what they see instead of over-trusting language patterns.
In short, the paper helps bridge the gap between “perception” and “reasoning”: not just seeing the evidence, but believing it enough to answer correctly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored, based on the paper’s methods, analyses, and claims.
- Causal faithfulness of attention as evidence: The study equates deep-layer attention with “perception,” but does not establish causal necessity/sufficiency (e.g., via targeted patch ablation, counterfactual swaps, or causal mediation) to show that attended regions actually drive answers.
- Reliance on attention-only attribution: No comparison to a broader set of attribution methods (e.g., Integrated Gradients, Layer-wise Relevance Propagation, Attention Rollout, occlusion sensitivity) to test whether “seeing but not believing” and Vea’s benefits persist across attribution paradigms.
- Dataset scope bias (text-centric tasks): Experiments focus on VisualCoT subsets (InfoVQA, DocVQA, SROIE, TextVQA), which are OCR-heavy and rely on localized textual cues; it remains unclear whether findings and Vea transfer to general VQA (counting, spatial relations, compositional reasoning, commonsense), charts/diagrams, medical images, scientific figures, or embodied/egocentric settings.
- Missing large-scale, diverse benchmarks: No evaluation on established broad VQA benchmarks (e.g., GQA, VQAv2, A-OKVQA, VizWiz, MM-Vet) or structured reasoning datasets to test generality beyond text-in-image settings.
- Evidence multiplicity and composition: The method averages across attended patches and assumes localized, contiguous evidence; tasks requiring multiple disjoint evidence regions, relational/global cues, or multi-hop visual reasoning remain underexplored.
- Head-level specialization is unexamined: Analyses average attention over heads; whether specific heads ground evidence (and could be selectively amplified) is not investigated.
- Stability of layer profiling across domains: The “top 10%” grounding layers are selected using a small VisualCoT diagnostic subset; robustness of this selection across datasets, domains, image encoders, prompts, and question types is untested.
- Per-instance adaptivity of layer selection: The approach uses a fixed set of layers per model; whether dynamic, input-specific layer/weight selection improves evidence attribution remains open.
- Cross-model “delegate” masking confound: For models where attention extraction caused memory leakage, a different model (Qwen2.5-VL) generates masks; whether cross-model attributions faithfully reflect each target model’s internal evidence and the performance penalty/benefit of this proxy remains unquantified.
- Post-augmentation attention dynamics: The paper does not measure whether Vea actually increases visual attention mass in later decoding steps or reduces text dominance after augmentation.
- Error-type taxonomy and mitigation: “Seeing but not believing” is illustrated qualitatively, but there is no quantitative error taxonomy (e.g., hallucination, refusal, partial grounding) nor analysis of how Vea shifts the distribution of error types.
- Decoding strategy dependence: All results use greedy decoding; the impact of sampling temperature, nucleus/beam search, self-consistency, or iterative re-attention/verification on “seeing vs believing” and Vea’s gains is unknown.
- Calibration, reliability, and abstention: No evaluation of calibration (e.g., ECE), selective prediction, or refusal quality; whether Vea improves or harms confidence alignment and safe abstention is untested.
- Robustness beyond synthetic corruptions: Robustness tests cover Gaussian noise, downsampling, and random masking; real-world corruptions (motion blur, JPEG/compression artifacts, color shifts, lens flare, occlusions), structured distractors, and adversarial patches are not evaluated.
- Necessity checks via targeted occlusion: While noise/masking are tested, there is no targeted occlusion of evidence regions to quantify necessity (performance drop when evidence is removed) versus resilience to non-evidence removal.
- Global-context risks: Highlighting can suppress non-evidence regions; tasks requiring global context or background cues may be harmed. The work lacks diagnostics for when highlighting over-prunes useful context and strategies to adaptively preserve it.
- Adaptive parameterization: Vea uses fixed highlight/smoothing strengths (α, σ); no per-instance or learned tuning (e.g., optimizing α, σ via inner-loop search or confidence-based policies) is explored.
- Computational and systems costs: The latency, memory, scalability, and engineering constraints of extracting deep-layer attention (and the reported memory leakage) are not quantified, especially for high-resolution inputs, long multimodal contexts, or multi-image inputs.
- Closed-box applicability: The method requires access to internal attention weights; practical alternatives for closed-source VLMs (e.g., GPT-4V, Gemini) and black-box approximations to obtain evidence masks remain unaddressed.
- Multilingual and cross-script generalization: Evidence and questions are English-centric; whether findings and Vea generalize to multilingual prompts and images with diverse scripts (Arabic, Devanagari, Chinese, mixed fonts) is unknown.
- Video and temporal grounding: The approach is image-only; extending to video (temporal evidence, motion) and multi-image reasoning is unexplored.
- Interaction with RAG and tool use: Although parallels to context under-utilization in RAG are drawn, combining Vea with OCR tools, retrieval, or verifier modules (and comparing against strong OCR+LLM pipelines) is not studied.
- Competing baselines and controls: There is no control for purely image-processing effects (e.g., brightness/contrast normalization, non-attention-guided vignettes) to rule out that gains stem from generic visibility enhancement rather than attention guidance.
- Grounding metrics breadth: Evidence alignment is measured with token-level AUROC/NDCG; region-level metrics (IoU with boxes, pointing game), click-based human evaluation, and exhaustiveness/precision of rationales are not reported.
- Theoretical mechanism for belief failure: The work hypothesizes textual dominance and context under-utilization but does not analyze internal mechanisms (e.g., KV-cache composition, cross-modal gating, gradient flow) that cause evidence to be dropped during generation; formal models or diagnostics are absent.
- Training-time remedies: Only inference-time augmentation is proposed; training-time strategies (losses that enforce evidence usage, contrastive grounding objectives, RL from human-annotated rationales, debiasing to reduce text priors) are not explored.
- Transfer across image encoders and patchizations: Effects of different vision backbones (e.g., CLIP ViT variants vs EVA/ConvNeXt), patch sizes, and tokenization schemes on attention profiling and Vea’s efficacy are not characterized.
- Safety impacts: Whether evidence highlighting reduces harmful hallucinations without increasing leakage of sensitive text in images (PII, account numbers) or bypassing safety filters is unmeasured.
- Long-context and multi-turn interactions: Persistence of evidence across turns and long multimodal contexts (and whether Vea helps maintain visual grounding over dialogue) is untested.
- Sensitivity to question phrasing: Prior work shows phrasing can mislead VLMs; how paraphrases or adversarial phrasings alter deep-layer evidence attention and Vea’s benefits remains unquantified.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s inference-time Visual Evidence Augmentation (Vea) and attention diagnostics into existing Vision-LLM (VLM) systems and workflows.
- Attention-guided document intelligence for forms and receipts (finance, insurance, logistics, enterprise RPA)
- Use case: Boost accuracy in extraction and VQA on invoices, receipts, shipping labels, contracts, and ID documents (aligned with InfoVQA, DocVQA, SROIE).
- Tool/product/workflow: A “Vea preprocessor” plugin that profiles each model once, generates evidence masks at inference, augments images, and logs mask-to-answer alignment. Integrates with OCR and form parsers.
- Assumptions/dependencies: Access to model attention tensors or equivalent attribution; images contain localized evidence; patch-level mapping from encoder; minimal latency overhead is acceptable; privacy-safe processing for sensitive documents.
- Mobile OCR QA improvements in consumer apps (daily life, retail, personal finance)
- Use case: Receipt scanning, bill parsing, product label Q&A, menu reading and translation on smartphones.
- Tool/product/workflow: SDK for iOS/Android embedding Vea to highlight key fields before answering; optional on-device mode for privacy; robust to noise and low-resolution captures.
- Assumptions/dependencies: Sufficient on-device compute or efficient attention extraction; consistent gains for text-in-image tasks; masking does not degrade user experience.
- Visual grounding audits and compliance logging (enterprise risk, policy/governance)
- Use case: Produce audit trails showing whether answers were grounded in the attended evidence regions; flag “seeing but not believing” cases for review.
- Tool/product/workflow: Evidence alignment report (AUROC/NDCG) per decision; gating rules to escalate misalignments to human review; storage of masks and metadata.
- Assumptions/dependencies: Defined thresholds for acceptable evidence alignment; governance processes and human-in-the-loop; secure evidence logs to meet regulatory requirements.
- Reliability layer for multimodal customer support and educational assistants (software, education)
- Use case: Reduce hallucinations in product troubleshooting via image Q&A or grading/feedback for visual assignments (e.g., lab setups, diagrams).
- Tool/product/workflow: A “grounding-first” inference path—run Vea, then trigger a second-pass reasoning step when evidence-attention and answer diverge (e.g., CGR-style).
- Assumptions/dependencies: Access to internal attention or substitute attribution; domain-tuned prompts; tolerable latency for two-step inference.
- Accessibility assistance for low-vision users (healthcare, accessibility tech)
- Use case: Highlight and read out salient textual evidence in scenes (signage, medication labels, appliance controls).
- Tool/product/workflow: Visual overlay and voice output driven by evidence masks; configurable highlight strength and smoothing to prevent obscuring context.
- Assumptions/dependencies: Accurate attention in cluttered scenes; careful UI/UX to balance emphasis vs. overall context.
- Content moderation and multimodal fact-checking (platforms, media)
- Use case: Pre-publish checks verifying whether claims about an image are supported by the model’s attended regions.
- Tool/product/workflow: Evidence-claim consistency checks; automatic deferral or human review when attention focuses on non-evidence areas.
- Assumptions/dependencies: Reliable attention-to-evidence mapping for diverse image types; minimal false positives; platform policies accommodating automated gating.
- Robustness booster for field operations (warehousing, manufacturing, public safety)
- Use case: Maintain VQA performance under noise, occlusion, low-resolution, and random masking in body cams, handheld scanners, or industrial cameras.
- Tool/product/workflow: Vea preprocessor deployed at the edge; configurable parameters (highlight strength α, smoothness σ) based on capture conditions.
- Assumptions/dependencies: Edge compute capacity; validated resilience in specific camera pipelines; operational acceptance of slight latency overhead.
- Research tooling for evidence alignment metrics and layer profiling (academia, ML engineering)
- Use case: Systematic evaluation of VLMs’ grounding using AUROC/NDCG and identification of visual-grounding layers.
- Tool/product/workflow: Open-source scripts to profile top evidence-attributing layers (top 10%), generate per-sample masks, and benchmark “seeing but not believing.”
- Assumptions/dependencies: Small diagnostic set with evidence annotations (VisualCOT-like) for each model; attention access; reproducible evaluation pipeline.
Long-Term Applications
These opportunities require further research, scaling, vendor support, domain validation, or regulatory development to realize at production scale.
- Evidence-aligned training objectives and architectures (core ML, software)
- Use case: Architectures and training losses that explicitly align deep-layer visual evidence with generation, reducing “seeing but not believing.”
- Tool/product/workflow: Multi-objective training with evidence-consistency loss; balanced vision-language backbones; reinforcement learning for grounded outputs.
- Assumptions/dependencies: Large-scale datasets with evidence annotations; training-time access to attention; compute for retraining major VLMs.
- Sector standards for evidence-grounded AI decisions (policy, healthcare, finance, public sector)
- Use case: Regulatory frameworks requiring systems to demonstrate visual grounding for decisions involving images (claims adjudication, medical documentation, KYC).
- Tool/product/workflow: Certification protocols based on evidence-alignment metrics; audit APIs; compliance dashboards.
- Assumptions/dependencies: Cross-industry consensus on metrics and thresholds; verified interpretability reliability; privacy-preserving logging.
- Multimodal evidence highlighting across video and 3D (robotics, autonomous systems)
- Use case: Extend attention-guided evidence highlighting to spatiotemporal streams (video) and 3D sensors (LiDAR), improving task-level reasoning and safety.
- Tool/product/workflow: Spatiotemporal Vea for streaming attention; 3D mask projection; integration with perception-planning stacks.
- Assumptions/dependencies: Access to temporal attention; efficient real-time attribution; rigorous safety validation.
- Clinical decision support and medical imaging QA (healthcare)
- Use case: Assist radiologists/pathologists by highlighting regions used to answer visual queries; enforce grounded reporting.
- Tool/product/workflow: Evidence-aware imaging viewers; audit trails showing alignment between highlighted regions and textual conclusions.
- Assumptions/dependencies: Extensive clinical validation; regulatory approvals (e.g., FDA/EMA); domain-specific fine-tuning and risk management.
- Vendor-level “evidence channel” APIs (AI platforms)
- Use case: Standardized APIs exposing robust evidence signals (attention or derived masks) without full internal state access.
- Tool/product/workflow: Model-agnostic evidence endpoints; latency-optimized attribution; privacy-aware abstractions.
- Assumptions/dependencies: Vendor adoption; alignment across architectures; stability of exposed signals across versions.
- Evidence-aware multimodal RAG (enterprise knowledge systems)
- Use case: Combine Vea-like highlighting with retrieval-augmented generation to focus on salient visual/text context in cluttered inputs.
- Tool/product/workflow: Reranking and filtering guided by evidence masks; joint visual-text saliency scoring; grounded synthesis.
- Assumptions/dependencies: Unified evidence scoring across modalities; robust fusion strategies; domain-specific evaluation.
- On-device hardware acceleration for evidence attribution (edge AI, energy)
- Use case: Dedicated kernels or accelerators to compute attention-derived masks efficiently on cameras, AR headsets, and mobile devices.
- Tool/product/workflow: Firmware-level optimizations for patch-level attribution; low-power smoothing/denoising pipelines.
- Assumptions/dependencies: Hardware-software co-design; standardized interfaces to VLM encoders; energy and latency constraints.
- Legal and financial large-scale document analytics with evidence governance (finance, legal tech)
- Use case: End-to-end systems that scale evidence-grounded extraction, answering, and compliance across millions of documents.
- Tool/product/workflow: Evidence-aware ETL; batch profiling of models; robust audit and remediation pipelines.
- Assumptions/dependencies: Strong privacy and data governance; scalability of attention extraction; organizational change management.
Notes on cross-cutting feasibility:
- Access to attention or equivalent attribution is a key dependency; many hosted models/APIs do not currently expose these signals.
- One-time per-model profiling requires a small, evidence-annotated diagnostic set; generalization quality depends on domain similarity.
- Vea is most effective when tasks have localized evidence; tasks demanding global scene understanding may need tuned parameters or hybrid approaches.
- Memory and latency constraints may arise when extracting attention on large models; engineering optimizations or vendor support can mitigate this.
Glossary
- Additive Gaussian noise: Randomly distributed noise added to images, following a Gaussian distribution, used to test robustness. "Noise Injection: additive Gaussian noise with varying strength, where 100\% corresponds to pure noise."
- Attention-based masking: An inference-time technique that uses attention scores to mask or emphasize regions in the input. "an inference-time intervention that highlights deep-layer evidence regions through selective attention-based masking."
- Attention-Guided Visual Evidence Highlighting: A procedure that uses attention maps to highlight important visual regions during inference. "Attention-Guided Visual Evidence Highlighting"
- Attention Mask Denoising: A process to reduce spurious high-value patches in attention masks by suppressing isolated outliers. "Attention Mask Denoising."
- AUROC: Area Under the Receiver Operating Characteristic curve; a metric for evaluating ranking or attribution quality. "compute the AUROC against the ground-truth labels, measuring the attribution quality of that layer."
- Decoder-only Transformer: A Transformer architecture that generates tokens by attending only to previous tokens (causal attention). "A decoder-only Transformer processes an input of tokens (text and image) and generates each new token by attending to all preceding tokens."
- Downsampling: Reducing image resolution by decreasing the number of pixels. "Low Resolution: downsampling the image by number of pixels, e.g., a 90\% reduction results in 10\% of the original pixels."
- Exact Match: A strict QA metric that counts a prediction as correct only if it exactly matches the reference answer. "reporting Exact Match and Token-level F1 as QA metrics"
- Gaussian smoothing: Blurring an attention mask using a Gaussian kernel to improve spatial coherence. "we apply a Gaussian smoothing step."
- GradCAM: Gradient-weighted Class Activation Mapping; an attribution technique that highlights input regions influencing model outputs. "AGLA adopts a GradCAM-based approach that masks irrelevant regions and ensembles outputs from the original and masked images to strengthen visual grounding."
- Layer-wise attention dynamics: The pattern of how attention distribution changes across model layers. "By examining layer-wise attention dynamics, we find that shallow layers focus primarily on text, while deeper layers sparsely but reliably attend to localized evidence regions."
- Layer-wise Modality Attention Transition: The progressive shift of attention from text tokens to image tokens across layers. "Layer-wise Modality Attention Transition."
- Multimodal hallucinations: Fluent but incorrect outputs where language dominates and ignores visual evidence. "This textual bias has also been linked to multimodal hallucinations: as generation unfolds, the reliance on visual inputs diminishes and language priors increasingly dominate, producing outputs that are linguistically fluent but visually ungrounded"
- NDCG@all: Normalized Discounted Cumulative Gain computed over all items; evaluates ranking quality of attributed evidence. "AUROC and NDCG@all as evidence attribution metrics."
- Neighborhood filtering: A local averaging method to suppress isolated high-score patches in an attention mask. "we further adopt a neighborhood filtering strategy."
- Random Masking: Robustness perturbation that randomly hides a percentage of image patches. "Random Masking: randomly masking out of visual patches."
- Relative Attention per Token (RAPT): A per-token attention normalization metric relative to the input average. "Relative Attention per Token (RAPT), defined as the ratio of section-average attention mass per token to the input-average value."
- Retrieval-Augmented Generation (RAG): Generation that incorporates external retrieved context (e.g., images as context in VQA). "context under-utilization in retrieval-augmented generation (RAG), where the image in VQA can be viewed as a form of context."
- Token-level F1: A QA metric computing the F1 score over tokens in the predicted and reference answers. "reporting Exact Match and Token-level F1 as QA metrics"
- Visual encoder: The component that converts images into visual tokens for multimodal models. "a LLM backbone is paired with a relatively small visual encoder"
- Visual evidence attribution: Identifying which image regions constitute the evidence supporting an answer. "Inference-time Visual Evidence Attribution"
- Visual Evidence Augmentation (Vea): The proposed method that highlights evidence regions using deep-layer attention without training. "Vea (Visual Evidence Augmentation) extracts attention from visual grounding layers, applies denoising and smoothing to form a highlighting mask"
- Visual grounding: Aligning answers or textual content with specific visual regions in an image. "showing a sequential transition from linguistic parsing to visual grounding within a single-token inference."
- Visual-grounding layers: Model layers that concentrate attention on image regions corresponding to evidence. "the set of visual-grounding layers "
- VisualCOT dataset: A benchmark with human-annotated visual evidence for VQA tasks. "we leverage the VisualCOT dataset"
- Visual Question Answering (VQA): A multimodal task where models answer questions about images. "Visual Question Answering (VQA) has been a central task for evaluating VLMs’ ability to integrate and reason over visual and linguistic information"
- Vision-LLMs (VLMs): Multimodal models that process and reason over both images and text. "Vision-LLMs (VLMs) achieve strong results on multimodal tasks such as visual question answering"
Collections
Sign up for free to add this paper to one or more collections.