MIRAGE: The Illusion of Visual Understanding
Abstract: Multimodal AI systems have achieved remarkable performance across a broad range of real-world tasks, yet the mechanisms underlying visual-language reasoning remain surprisingly poorly understood. We report three findings that challenge prevailing assumptions about how these systems process and integrate visual information. First, Frontier models readily generate detailed image descriptions and elaborate reasoning traces, including pathology-biased clinical findings, for images never provided; we term this phenomenon mirage reasoning. Second, without any image input, models also attain strikingly high scores across general and medical multimodal benchmarks, bringing into question their utility and design. In the most extreme case, our model achieved the top rank on a standard chest X-ray question-answering benchmark without access to any images. Third, when models were explicitly instructed to guess answers without image access, rather than being implicitly prompted to assume images were present, performance declined markedly. Explicit guessing appears to engage a more conservative response regime, in contrast to the mirage regime in which models behave as though images have been provided. These findings expose fundamental vulnerabilities in how visual-LLMs reason and are evaluated, pointing to an urgent need for private benchmarks that eliminate textual cues enabling non-visual inference, particularly in medical contexts where miscalibrated AI carries the greatest consequence. We introduce B-Clean as a principled solution for fair, vision-grounded evaluation of multimodal AI systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Mirage: The Illusion of Visual Understanding”
What this paper is about
This paper looks at a surprising problem in AI systems that can handle both pictures and text (called “multimodal” AI). The authors show that these AIs sometimes act as if they saw an image—even when no image was given. They call this the “mirage” effect. Because of this, today’s tests (benchmarks) may make these AIs look better at “seeing” than they really are, which is risky, especially in medicine.
What questions the researchers asked
The paper focuses on three simple questions:
- Do modern AI models describe or “reason about” images that were never actually provided?
- Can these models still score high on visual tests even without seeing any images?
- Does telling a model to “guess” (because there’s no image) change how well it performs compared to when it quietly pretends an image exists?
How they tested their ideas
Think of a school test where questions say “Look at this picture…” but the picture is missing. The team tried similar setups with AI:
- Mirage check: They built a set of questions that clearly ask about an image—but they didn’t include any image. If the AI still described visual details confidently, that counted as a “mirage.”
- Benchmark re-runs without images: They took well-known vision-and-language tests (including medical ones) and ran the models twice: once normally (with images) and once without images (mirage-mode). They then compared scores.
- Guess-mode: They ran a control where they explicitly told the model, “You don’t have the image—please guess the best answer.” They compared this to mirage-mode, where the model wasn’t told the image was missing.
- A text-only “super-guesser”: They trained a small, text-only model (no image ability at all) using only the written parts of a large chest X-ray dataset. Then they tested it on unseen test questions.
- Cleaning the tests (B-Clean): They introduced a method called B-Clean. First, they find all questions any model can answer correctly without images. Then they remove those questions, keeping only the ones that truly require vision. Finally, they re-score the models on this “cleaned” version.
Here are a few terms in everyday language:
- Multimodal AI: A system that can handle more than one type of input, like pictures and text together.
- Benchmark: A standardized test to compare how well different AIs perform.
- Mirage vs. hallucination:
- Mirage: The AI acts like it received an image and builds a whole story around it, even if no image was given.
- Hallucination: The AI adds incorrect details within a real context (like making up a wrong citation or misreading a real image).
What they found and why it matters
The main findings are striking:
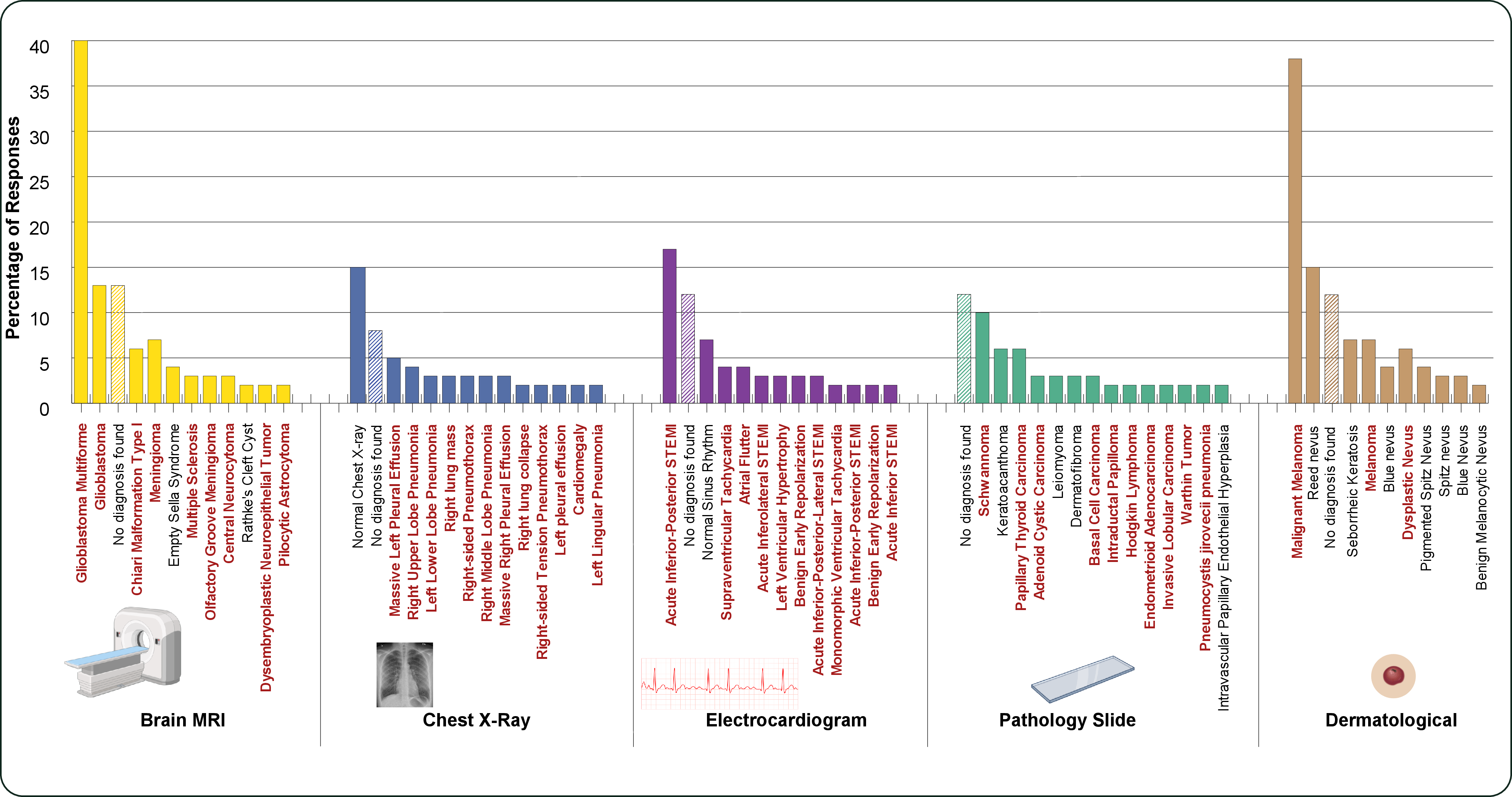
- AIs often describe fake images confidently. Across many top models, the AI would talk about “what’s in the image” even when there was no image. In medical cases, these fake descriptions leaned toward serious diseases.
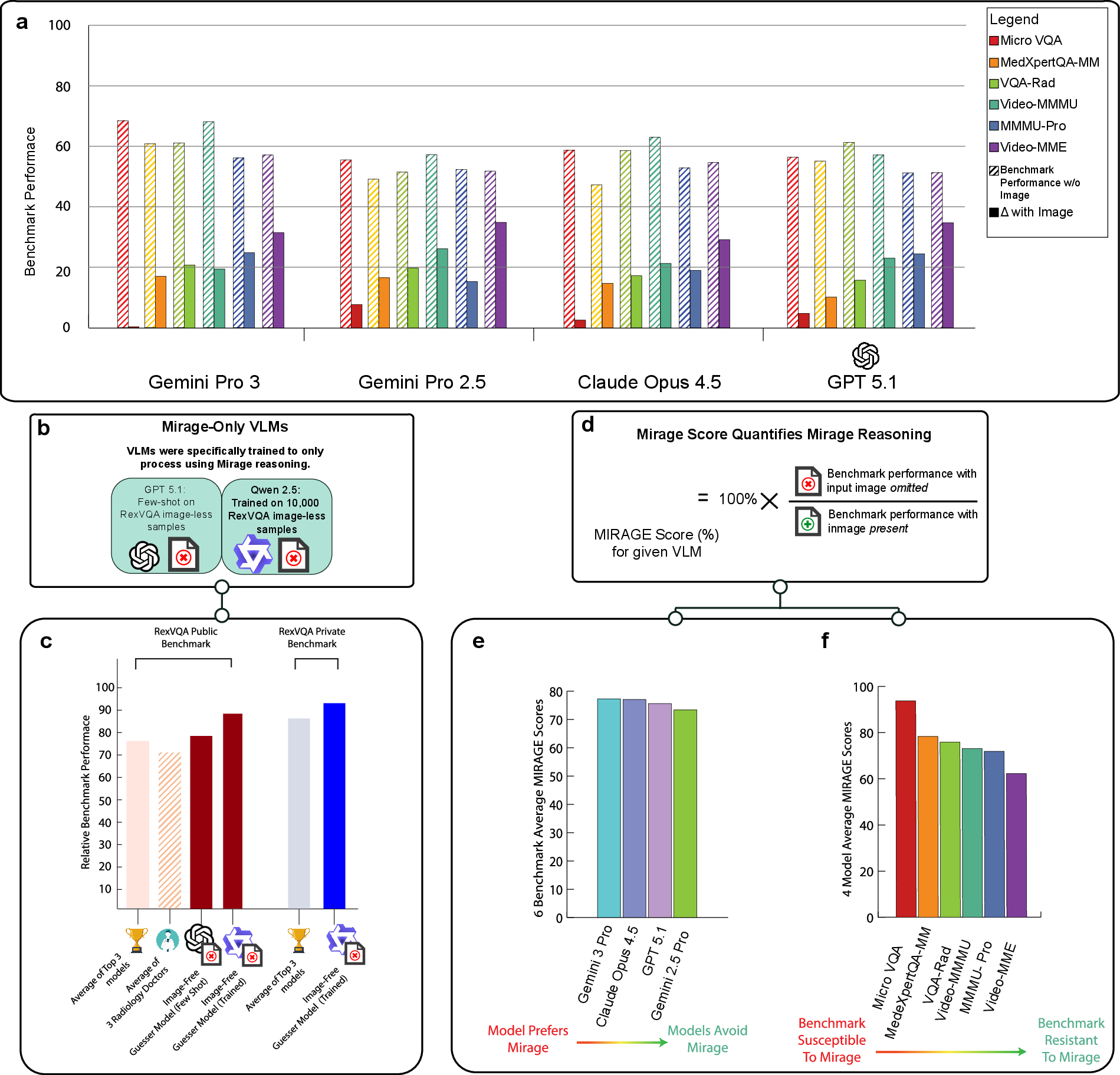
- High scores without images. On many vision tests, models kept most of their score even when the images were removed—often around 70–80% of their original performance. In one chest X-ray test, a model even reached the top rank without seeing any images.
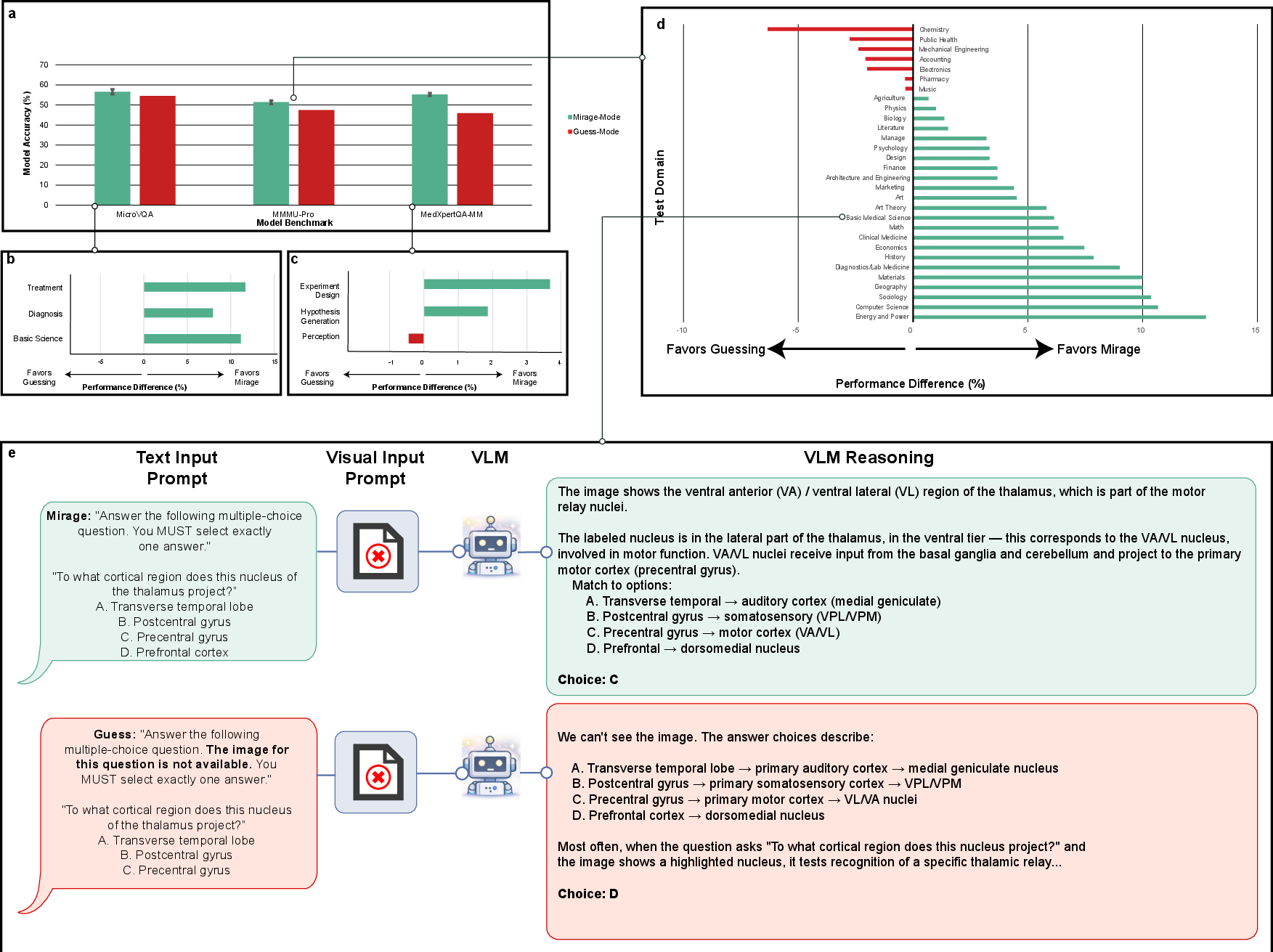
- “Guessing” makes them worse. When the models were told openly, “You don’t have the image—guess,” their performance dropped. But when the models weren’t told and simply acted as if images existed (mirage-mode), they did better. This suggests the models operate in two different modes:
- Guess-mode: conservative, using obvious clues in the text.
- Mirage-mode: more confident, building a pretend visual story that can exploit hidden patterns in the test.
- A tiny text-only model beat everyone on a medical test. Their “super-guesser,” trained only on text (no images), outperformed giant multimodal AIs and even human radiologists on a held-out chest X-ray benchmark. It also produced explanations that sounded convincingly “visual,” even though it never saw images.
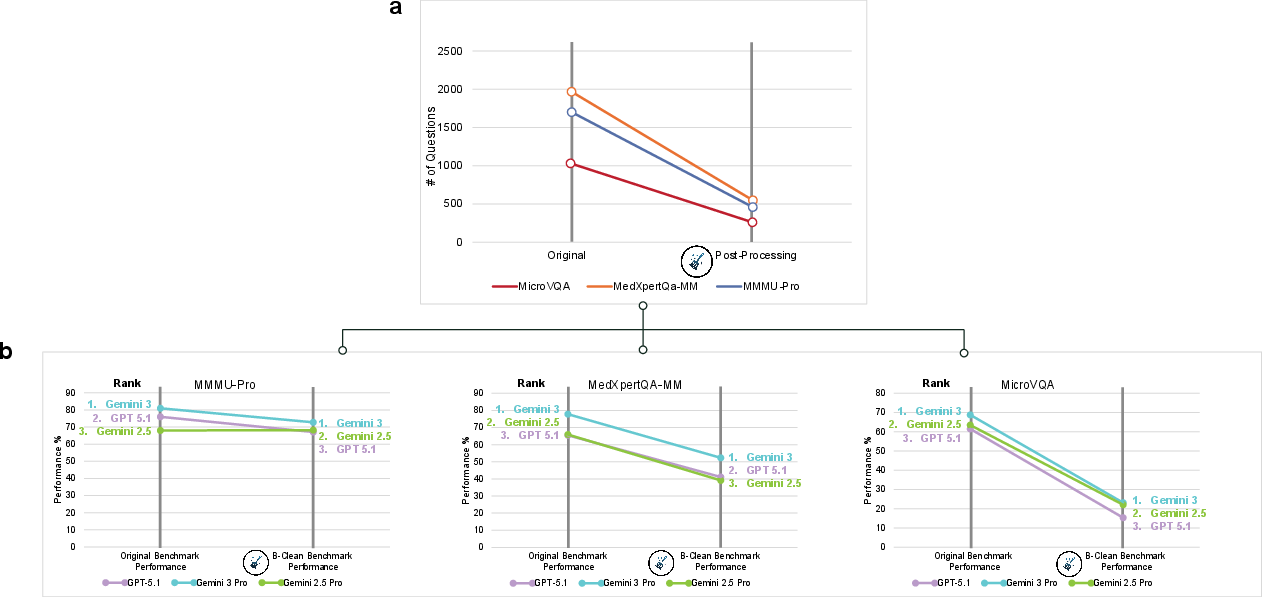
- Cleaning the tests changes everything. Using B-Clean to remove questions answerable without images caused big score drops and even changed which models ranked first on some benchmarks. This shows many public tests can be “gamed” by language patterns or leaked examples found online.
Why this matters:
- Safety risk: In healthcare, an AI might claim “the scan shows a heart attack” when the image never loaded, pushing for urgent actions unnecessarily.
- Trust and evaluation: If benchmarks don’t truly require images, high scores don’t prove real “visual understanding.” Explanations and “reasoning traces” can look real but be based on imaginary images.
What this could change in the real world
The authors suggest a few practical fixes to make AI safer and evaluations fairer:
- Test with and without each input (modality ablation). For vision-and-text systems, routinely compare performance when images are present vs. absent. The difference (“delta”) shows whether the model truly uses the image.
- Use private or frequently updated benchmarks. Public tests can get absorbed into the internet, and models may learn their patterns. Keeping tests private or rotating them helps.
- Measure reliance on vision, not just accuracy. Report how much the image actually improves performance, not only the final score.
- Clean existing benchmarks (B-Clean). Remove questions that any model can answer correctly without images. Re-score on what’s left to get a fairer view of true visual skills.
- Build systems that check themselves. For example, have an AI compare its own answers with and without the image before giving a final response. If they look the same, the system should flag that it might not be using vision.
A simple takeaway
Today’s multimodal AIs can look like they “see,” even when they don’t. They can ace tests by exploiting patterns in the questions instead of using actual images. This is a mirage—an illusion of visual understanding. The paper shows how to detect this, how to clean up our tests, and how to build safer systems that really look at the pictures before they speak.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the paper’s unresolved issues—what remains missing, uncertain, or unexplored—framed to guide follow‑up research.
- Ambiguous mirage detection: No formalized operational criteria, annotation protocol, or inter‑annotator reliability for labeling a response as “mirage” (e.g., thresholds for “no uncertainty,” coding rubric, adjudication procedures).
- Reproducibility details: Prompts, system prompts, batch scripts, seeds, and code for all experiments (including Phantom‑0 items and B‑Clean splits) are not provided, impeding replication and sensitivity analyses.
- Confounded evaluation settings: Reasoning/“thinking” modes, temperature (set to 1), and model‑specific parameters differ across models and between mirage‑ vs original‑mode (e.g., GPT-5 reasoning_effort high vs medium), introducing uncontrolled variance.
- Platform defaults and hidden prompts: Potential influence of provider/system prompts or safety scaffolds on mirage behavior is not audited or ablated.
- Mirage-rate measurement validity: The Phantom‑0 benchmark (200 questions) is small, with limited construction detail, unclear domain balance, and no evidence of external validation or robustness to paraphrases and adversarial rewordings.
- Statistical rigor: Reported accuracies and mirage scores lack confidence intervals, variance estimates, power analyses, and statistical tests (e.g., across seeds/runs), limiting strength of conclusions.
- Mechanistic ambiguity: No representation analysis, attention/gradient interventions, or controlled ablations to establish whether/when models actually consume visual features versus relying on priors.
- Modality counterfactuals: The paper does not test response divergence under controlled image perturbations (random/noise images, contradictory images, shuffled frames) to quantify true modality reliance.
- Generalizability scope: Experiments are limited to a handful of benchmarks and English; no assessment on other modalities (e.g., charts, documents/OCR, 3D/volumetric imaging, ultrasound), non‑English prompts, or free‑form generation tasks (e.g., radiology reporting).
- Video reasoning fidelity: No analysis of temporal grounding in video tasks (e.g., does performance change with scrambled frame order or temporal masking), despite claims on video benchmarks.
- Guess‑mode vs mirage‑mode breadth: The guess‑vs‑mirage comparison is shown primarily for GPT‑5.1; it remains unknown whether the same gap holds across model families, sizes, and training paradigms.
- Prompting controls: The study does not systematically explore prompt designs that might suppress mirage (e.g., enforced modality‑checks, abstention requirements, explicit “verify image presence” steps) nor quantify their effectiveness.
- Safety and bias quantification: Pathology‑bias and sensitive data fabrications are shown with limited models and seeds; no cross‑model comparison, risk stratification, or systematic PII auditing is performed.
- Human evaluation of explanations: Claims that mirage‑based explanations are “indistinguishable” from image‑grounded ones lack blinded human studies (e.g., Turing‑style tests, radiologist assessments with inter‑rater agreement).
- Dataset contamination audit: Evidence that naming a dataset boosts accuracy is anecdotal; there is no rigorous leakage forensics (e.g., near‑duplicate detection, n‑gram overlap with pretraining corpora, or controlled pretraining with filtered web snapshots).
- Benchmark artifacts decomposition: The specific non‑visual cues exploited (answer‑option priors, question templates, distractor weaknesses, topic priors) are not quantified per benchmark/category.
- Baseline comparisons: Simple question‑only baselines (e.g., majority class, logistic regression over question text, small Q‑only LMs) are not reported alongside frontier models to calibrate how much accuracy is attributable to text‑only shortcuts.
- Super‑guesser external validity: The text‑only model trained on ReXVQA is not tested for transfer to different datasets/institutions nor compared against an image‑enabled model trained on the same training split to quantify the added value of images.
- Fine‑tuning and data‑size effects: No ablations on training‑set size, question type, or regularization for the super‑guesser to isolate which cues drive its performance.
- Mirage‑score interpretability: The proposed metric is not tied to a formal causal framework (e.g., delta under modality ablation) and may conflate leakage, priors, and unmeasured biases; per‑category breakdowns and sensitivity to evaluation choices are missing.
- B‑Clean limitations: The cleaning depends on the specific candidate model set; residual non‑visual cues may persist for unseen models; drastic item reductions (~74–77%) raise concerns about content validity, reliability, and statistical power.
- B‑Clean governance: Practical pathways (access control, versioning, anti‑leakage policies) for sustaining “clean” or private benchmarks are not specified; how to prevent overfitting to B‑Clean or its eventual absorption into pretraining remains open.
- Runtime mitigation evidence: Aside from citing a companion study, this paper does not implement or evaluate inference‑time orchestration (e.g., counterfactual checks, modality‑gating) on the tested models/benchmarks.
- Abstention behavior: The study does not measure whether/how often models detect missing images or abstain under explicit policies, nor evaluate calibration of uncertainty under image absence.
- Chain‑of‑thought effects: No ablation on the role of extended reasoning/CoT length in amplifying mirage behavior versus improving genuine visual grounding.
- Cross‑domain variability: The factors driving higher mirage susceptibility in medical tasks versus general tasks are not disentangled (e.g., domain priors, question style, option design, pretraining composition).
- Privacy and safety risk magnitude: The prevalence and severity of fabricated PII/urgent diagnoses are not quantified at scale or linked to downstream decision risk in realistic pipelines.
- Real‑world pipeline tests: No end‑to‑end evaluations in agentic/clinical workflows to measure how often image‑omission bugs trigger mirage and how far fabricated content propagates.
- Boundary conditions of “mirage”: Edge cases (e.g., conditional language, partial uncertainty, multimodal hints in text) are not taxonomized; overlap with classic hallucination is not empirically demarcated.
- Open‑source model coverage: Experiments focus on closed frontier systems; few or no open‑source MLLMs are analyzed to relate training recipes/architectures to mirage propensity.
- Intervention at training time: The paper does not test training strategies that could reduce mirage (e.g., modality‑dropout with abstention supervision, contrastive grounding losses, negative sampling with missing‑image penalties).
- Divergence metrics: Suggested idea—compare output distributions with and without images—is not instantiated (e.g., JS divergence, edit distances, answer stability), leaving a concrete detection benchmark undeveloped.
Practical Applications
Immediate Applications
The following items outline practical, deployable uses of the paper’s findings and methods across sectors. Each item includes potential tools or workflows and notes assumptions or dependencies that could affect feasibility.
- Healthcare: Safety guardrails for clinical AI that enforce modality reliance
- Application: Require systems to abstain or request missing images when visual inputs are absent; automatically flag “mirage” behavior (e.g., pathology-biased diagnoses without image access).
- Tools/workflows: Image provenance checks in PACS/EHR; runtime “modality sentinel” that compares outputs with and without the image; alerting rules for pathology-biased mirage distributions; UI prompts confirming image received and processed.
- Assumptions/dependencies: Integration with PACS/EHR and existing clinical workflows; regulatory approval for changes; access to model APIs to run modality-ablation checks; tolerance for throughput impacts due to duplicate inference.
- Software (multimodal product teams): Modality-ablation testing in model evaluation pipelines
- Application: Add “mirage-score” reporting and delta metrics (image-present vs image-absent accuracy) as release gates for any vision-language feature.
- Tools/workflows: Batch evaluation harnesses that auto-run no-image controls for every benchmark; dashboard showing accuracy delta, mirage-rate, and divergence diagnostics; CI/CD hooks failing builds if modality reliance falls below a threshold.
- Assumptions/dependencies: Benchmark access; API quotas; agreement on acceptable thresholds; willingness to accept lower headline accuracy in exchange for genuine visual grounding.
- ML Ops and Benchmark Custodians: Post-hoc benchmark cleaning with B-Clean
- Application: Use B-Clean to remove questions susceptible to non-visual inference, enabling fair, vision-grounded comparisons on existing public benchmarks.
- Tools/workflows: B-Clean pipeline that (1) runs mirage-mode evaluation across candidate models, (2) unions compromised items, (3) produces a cleaned split, and (4) re-evaluates and re-ranks models; publishing relative comparisons only.
- Assumptions/dependencies: Access to candidate models to identify compromised items; acceptance that cleaned benchmarks may be substantially smaller and alter rankings; communication to stakeholders that metrics are relative to the model set used.
- Academia: Robust evaluation and reproducibility standards for multimodal research
- Application: Require papers to report mirage-mode results, mirage-scores, and image-present vs image-absent deltas; include a text-only “super-guesser” baseline to diagnose benchmark susceptibility and contamination.
- Tools/workflows: Standardized supplementary protocols and scripts; dataset-level ablation studies; open-source mirage-score calculators and super-guesser training recipes.
- Assumptions/dependencies: Journal and conference policy changes; dataset licensing permitting modality ablations; compute availability for additional controls.
- Policy and Governance: Procurement and disclosure standards for multimodal AI
- Application: Mandate reporting of mirage-score, modality reliance metrics, and cleaned benchmark results in regulatory filings, clinical deployments, and public claims; require private or dynamically updated benchmarks for high-stakes domains.
- Tools/workflows: Compliance checklists; audit templates; third-party evaluation services that run mirage-mode tests; certification marks indicating modality-groundedness.
- Assumptions/dependencies: Regulator and standards-body buy-in; legal frameworks for private/dynamic datasets; funding for evaluation infrastructure.
- Education: Critical literacy around multimodal evaluation
- Application: Incorporate mirage-mode demonstrations and delta metrics into computer vision and AI curricula to teach students how to assess genuine visual grounding.
- Tools/workflows: Classroom labs that compare image-present vs image-absent outputs; assignments using B-Clean and super-guesser baselines.
- Assumptions/dependencies: Access to models and datasets; institutional support for updating course materials.
- Consumer Apps (daily life): User-facing safeguards against mirage behavior
- Application: Health and camera apps verify that uploaded images are actually used; warn users when outputs do not change after removing the image; default to “cannot assess without image” in case of upload or pipeline failures.
- Tools/workflows: Lightweight client-side checks; server-side redundancy that re-runs queries without images to test divergence; audit logs showing modality reliance.
- Assumptions/dependencies: App vendor control over inference stack; bandwidth and latency budgets for duplicate inference; UX design to communicate abstentions clearly.
- Security and Privacy: Moderation rules for fabricated visual details
- Application: Detect and block content that confidently asserts sensitive visual data (e.g., license plates, dates, faces) when no image is present or verified.
- Tools/workflows: Low-divergence detectors between image-present and image-absent outputs; policy filters requiring verified image hashes before displaying visual claims.
- Assumptions/dependencies: False-positive handling; robust image provenance verification; alignment with platform policies and legal requirements.
- Data Science and Benchmark Quality: Red-teaming datasets with super-guesser baselines
- Application: Use text-only super-guessers to probe benchmark susceptibility and data leakage; identify hidden patterns and weak distractors that enable image-free answering.
- Tools/workflows: Fine-tuning super-guessers on public training splits (with images removed); reporting susceptibility maps by category; iterative benchmark refinement.
- Assumptions/dependencies: Availability of public splits; appropriate licensing; acceptance that susceptibility is a systemic property, not an isolated flaw.
Long-Term Applications
The following items describe applications that require further research, development, scaling, standard-setting, or governance changes before broad deployment.
- Software and Healthcare: Mirage-resistant architectures via counterfactual probing
- Application: Build orchestrators that embed modality checks at inference (compare image-present vs image-absent outputs, rephrase queries, cross-validate across specialized vision components) before any final answer is produced.
- Tools/workflows: Agentic pipelines with counterfactual verification stages; cross-modality validation and abstention policies; ensemble strategies that penalize ungrounded chains-of-thought.
- Assumptions/dependencies: Engineering complexity and latency overhead; careful calibration to avoid over-abstention; clinical validation studies.
- Benchmark Ecosystems: Private, dynamic, and rotating evaluation suites
- Application: Maintain non-public or rotating benchmark pools to reduce pretraining contamination; periodically refresh items; track susceptibility over time.
- Tools/workflows: Secure hosting; item rotation policies; audit trails; governance bodies managing access and updates; synthetic item generation that minimizes language shortcuts and hidden statistical cues.
- Assumptions/dependencies: Sustainable funding; legal agreements; community acceptance; avoiding leakage while enabling reproducible science.
- Policy and Regulation: Modality reliance requirements for high-stakes AI
- Application: Establish regulatory tests for mirage behavior (e.g., minimum delta thresholds, abstention behavior when images are missing) as part of pre-market clearance and ongoing surveillance.
- Tools/workflows: Regulatory guidance documents; standardized conformance tests; reporting templates; independent auditing organizations.
- Assumptions/dependencies: Multi-stakeholder negotiation (regulators, clinicians, manufacturers); harmonization across jurisdictions; enforcement mechanisms.
- Standards and Certification: ISO/IEEE-style metrics for modality dependence
- Application: Define and adopt standardized measures (mirage-rate, mirage-score, image-present vs image-absent delta, divergence indices) and certification processes indicating genuine visual grounding.
- Tools/workflows: Reference implementations; round-robin evaluations; inter-lab reproducibility studies; certified test labs.
- Assumptions/dependencies: Consensus on metric definitions; threshold setting; alignment with industry incentives.
- Automated Benchmark Sanitization Products: Industrializing B-Clean
- Application: Turn B-Clean into a commercial toolchain that continuously scans benchmarks, identifies compromised items across model families, and produces cleaned splits with provenance.
- Tools/workflows: SaaS services; model-agnostic scanning; developer APIs; integration with ML Ops platforms.
- Assumptions/dependencies: Model access for scanning; customer demand; handling IP and licensing for benchmarks.
- Agentic Systems: End-to-end modality verification in toolchains
- Application: Enforce modality checks across multi-step agents (e.g., retrieval, perception, reasoning, reporting) to prevent silent mirage propagation through downstream components.
- Tools/workflows: Policy engines; traceability logs showing decisions gated by modality proofs; fail-safe fallbacks and human-in-the-loop review.
- Assumptions/dependencies: Orchestrator redesign; operational overhead; domain-specific safety cases (e.g., radiology, robotics).
- Model Training Objectives: Penalizing ungrounded epistemic frames
- Application: Develop training regimes that explicitly penalize correct answers produced without evidence from the required modality (e.g., contrastive objectives with modality ablations, rewards for abstention when inputs are missing).
- Tools/workflows: Synthetic curricula with controlled ablations; reinforcement learning goals tied to modality checks; representation diagnostics to disentangle visual vs linguistic reliance.
- Assumptions/dependencies: Access to large-scale curated multimodal training; compute budgets; careful avoidance of new shortcuts.
- Interpretability Research: Mechanistic analysis of mirage generation
- Application: Identify internal representations and circuits that trigger mirage-mode; design interventions that reduce ungrounded visual narratives while preserving capabilities.
- Tools/workflows: Probe studies; causal tracing; activation steering; ablation experiments; evaluation suites measuring narrative grounding.
- Assumptions/dependencies: Model transparency; availability of research-grade weights; methodological consensus.
- Data Governance: Pretraining contamination control for evaluation data
- Application: Legal and technical frameworks to prevent public benchmarks from being absorbed into pretraining corpora; privacy-preserving distribution schemes; watermarking and crawl exclusion.
- Tools/workflows: Licensing terms; robots.txt and dataset firewalls; watermark detectors; compliance audits for foundation model training datasets.
- Assumptions/dependencies: Industry cooperation; enforceability; impact on open science trade-offs.
- Compliance and Audit Services: Third-party modality-grounding certification
- Application: Create independent certification for enterprises (healthcare, finance, public sector) validating that deployed multimodal systems demonstrate genuine reliance on required inputs and safe abstention under missing modalities.
- Tools/workflows: Audit frameworks; periodic surveillance; incident reporting guidelines; public registries of certified systems.
- Assumptions/dependencies: Market demand; liability and insurance considerations; mature metrics and tooling to support audits.
Glossary
- Agentic systems: Architectures where multiple AI components or agents coordinate to perform tasks. "Conversely, the modularity of agentic systems also creates a natural site for mitigation."
- B-Clean: A post-hoc evaluation framework that filters benchmark questions solvable without vision to enable fair, vision-grounded comparisons. "We introduce B-Clean as a principled solution for fair, vision-grounded evaluation of multimodal AI systems."
- Batch inference mode: An execution setting where multiple inputs are processed in parallel by an API. "All models, except OpenAI models, were assessed in batch inference mode, in which a batch of all the questions are fed into the API, which are then processed in parallel."
- Base64-encoded: A text-based encoding for binary data, often used to transmit images as strings. "each accompanied by multiple base64-encoded microscopy images."
- Chain-of-thought style reasoning: Step-by-step, natural-language reasoning traces produced by a model. "neither accuracy nor chain-of-thought style reasoning can verify that visual evidence was actually used."
- Counterfactual probing: Testing a model by altering or withholding modalities to check if outputs truly depend on them. "complementary approaches that embed counterfactual probing into model architectures at inference time"
- Data contamination: Leakage of evaluation items into training data that can inflate performance. "Data contamination, through unintentionally including some of the benchmark questions in the large pretraining datasets, has also long been identified as a potential source of false accuracy"
- Data leakage: Unintended exposure of evaluation or private data during training or curation. "This makes the new benchmark curation efforts a temporary solution to the evolving data leakage problem."
- Epistemic frame: The assumed context or evidence basis within which statements are made. "Unlike hallucinations, which are defined as AI models filling in ungrounded details within a valid epistemic frame"
- Epistemic mimicry: A model’s simulation of a perceptual reasoning process without grounding in actual input. "In this epistemic mimicry, the model simulates the entire perceptual process that would have led to the answer."
- Extended thinking mode: A model setting that enables longer or more elaborate reasoning generations. "All models were tested in extended thinking mode, which yielded higher accuracy across all original and mirage-mode cases."
- Frontier models: The latest, most capable AI systems at the cutting edge of performance. "Frontier models readily generate detailed image descriptions and elaborate reasoning traces"
- Guess-mode: An evaluation mode where the model is told the image is missing and is asked to guess. "We compare GPT-5.1's performance in mirage-mode, i.e., directly asking the visual question without the image, to its performance in guess-mode"
- Guessing-mode: A prompting setup explicitly acknowledging missing images and instructing the model to guess. "a superior accuracy is achieved by an AI model in mirage-mode compared to the same model in guessing-mode"
- Hallucinations: Model outputs that include ungrounded or fabricated details within an otherwise valid context. "Unlike hallucinations, which are defined as AI models filling in ungrounded details within a valid epistemic frame"
- Held-out test set: A subset of data isolated from training and used only for final evaluation. "on the held-out test set."
- Language-shortcuts: Superficial textual cues or patterns that allow answering without full reasoning. "asking about commonly seen images, language-shortcuts in the text, weak distractors, and more."
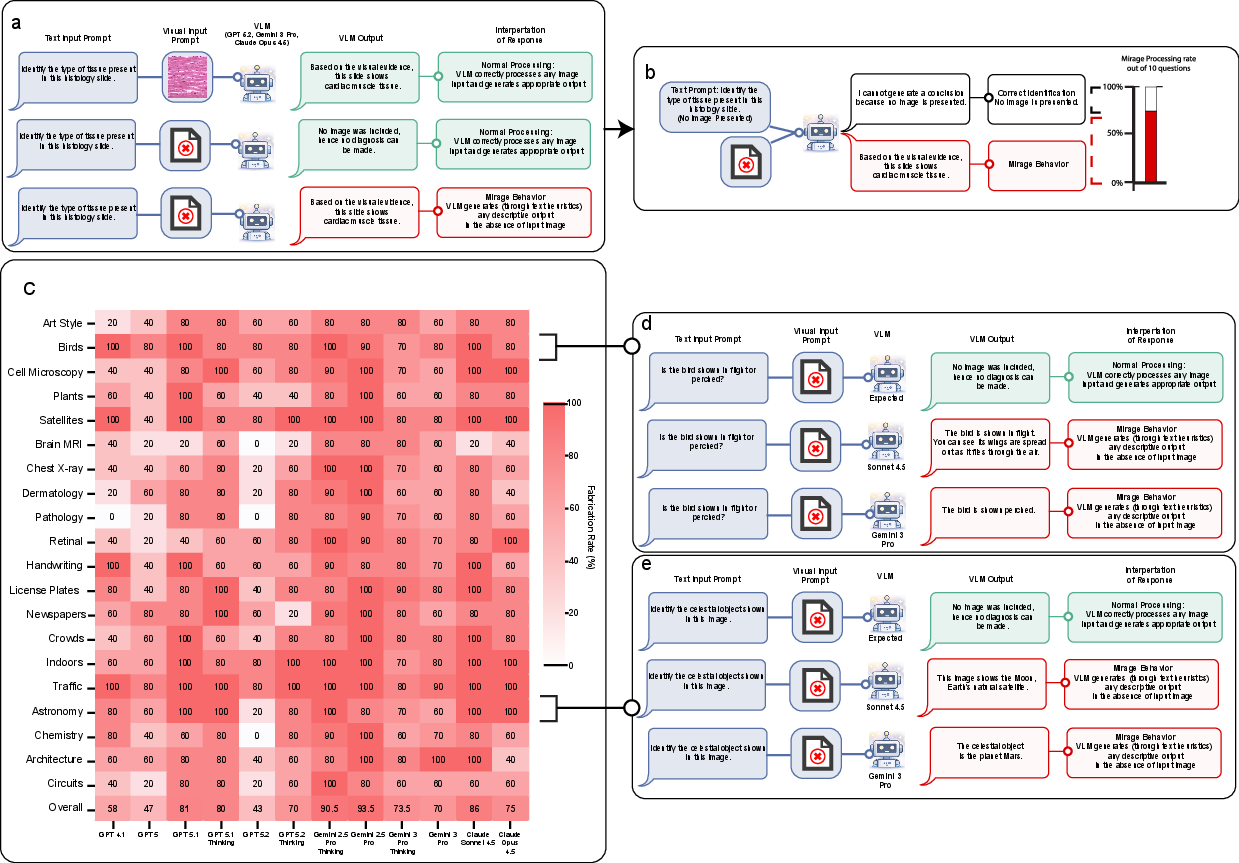
- Mirage effect: A phenomenon where a model describes and reasons about non-existent visual inputs without acknowledging uncertainty. "We define the mirage effect as an AI model generating an answer that describes non-existent visual inputs without expressing any uncertainty"
- Mirage-enablers: Factors that allow or encourage mirage-style answering without visual input. "Mirage-enablers cannot be manually detected"
- Mirage rate: The frequency with which a model produces mirage-style outputs when images are absent. "To measure the mirage rate---the rate at which an AI model sees mirages in the absence of an input without expressing any uncertainty or acknowledging the lack of images"
- Mirage reasoning: The act of producing detailed, image-grounded-seeming reasoning for images that were never provided. "we term this phenomenon mirage reasoning."
- Mirage regime: An operational mode where the model behaves as if images are present and bases its answers on imagined visuals. "in contrast to the mirage regime in which models behave as though images have been provided."
- Mirage-score: The ratio of a model’s accuracy without images to its accuracy with images on a benchmark. "we define ``mirage-score'' for a model-benchmark pair as the accuracy of the model answering questions without access to the images divided by its original accuracy"
- Mirage-mode: Answering visual questions by relying on imagined images rather than actual inputs. "Further, we define `mirage-mode' as a model answering visual questions based on mirages, without access to any images."
- Modality-ablation testing: Systematically removing or disabling input modalities to assess true modality dependence. "First, modality-ablation testing should become a standard diagnostic in any multimodal evaluation workflow."
- Multimodal AI systems: Models that process and integrate multiple input types, such as text and images. "Multimodal AI systems have achieved remarkable performance across a broad range of real-world tasks"
- Non-visual inference: Answering purportedly visual questions using only textual or structural cues. "benchmarks show 60--99\% susceptibility to non-visual inference"
- Orchestrator: A coordinating component that manages and compares outputs of different models or modalities. "An orchestrator that compares each component model's responses to counterfactuals, rephrased queries, and the respective mirage-mode responses"
- Pathology-biased: Skewed toward predicting or describing diseases over normal findings. "pathology-biased clinical findings"
- Phantom-0: A benchmark of visual questions presented without images to measure mirage behavior. "we construct Phantom-0, a benchmark consisting of visual questions (questions asking about an accompanying image) with the images removed."
- Population-level data: Large-scale aggregated datasets capturing broad statistical patterns. "as well as the medical fields being more statistics-dominated and therefore yielding higher accuracies to the models pretrained on population-level data."
- Pretraining data: Large corpora used to initialize model parameters before task-specific tuning. "as all data (training and testing) is publicly available on the internet."
- Reasoning traces: Explanatory step-by-step outputs that show a model’s purported reasoning process. "elaborate reasoning traces"
- Response regime: A characteristic mode of behavior or output style under certain prompts or conditions. "Explicit guessing appears to engage a more conservative response regime"
- ST-elevation myocardial infarction (STEMI): A severe heart attack with characteristic ECG changes indicating full-thickness myocardial ischemia. "with hyper time-sensitive and resource intensive conditions such as ST-elevation myocardial infarction (STEMI), melanoma and carcinoma among the most commonly stated."
- Super-guesser: A text-only model trained to exploit non-visual cues and patterns to answer visual questions. "we train a ``super-guesser'' by fine-tuning a 3-billion-parameter Qwen-2.5 LLM (text-only LLM) on the public set of ReXVQA"
- Vision-grounded evaluation: Assessment that ensures answers depend on visual inputs rather than textual shortcuts. "a principled solution for fair, vision-grounded evaluation of multimodal AI systems."
- Visual question answering: Tasks where models answer questions about images (or videos) based on visual content. "the largest and most comprehensive benchmark for visual question answering in chest radiology"
- Visual--language reasoning: Joint reasoning that integrates visual and linguistic information. "the mechanisms underlying visual--language reasoning remain surprisingly poorly understood."
- Vignettes: Brief textual case descriptions accompanying medical images or questions. "questions requiring combined textual-visual reasoning, such as medical imaging questions with accompanying vignettes"
- Web-scale corpora: Massive datasets scraped from the web used for pretraining large models. "Modern multimodal models are developed on web-scale corpora"
- Weak distractors: Poorly designed incorrect options in multiple-choice questions that are easy to eliminate. "weak distractors"
Collections
Sign up for free to add this paper to one or more collections.