- The paper demonstrates that VLM failures stem from arbitration errors rather than perceptual encoding deficits, as robust visual signals are present in early layers.
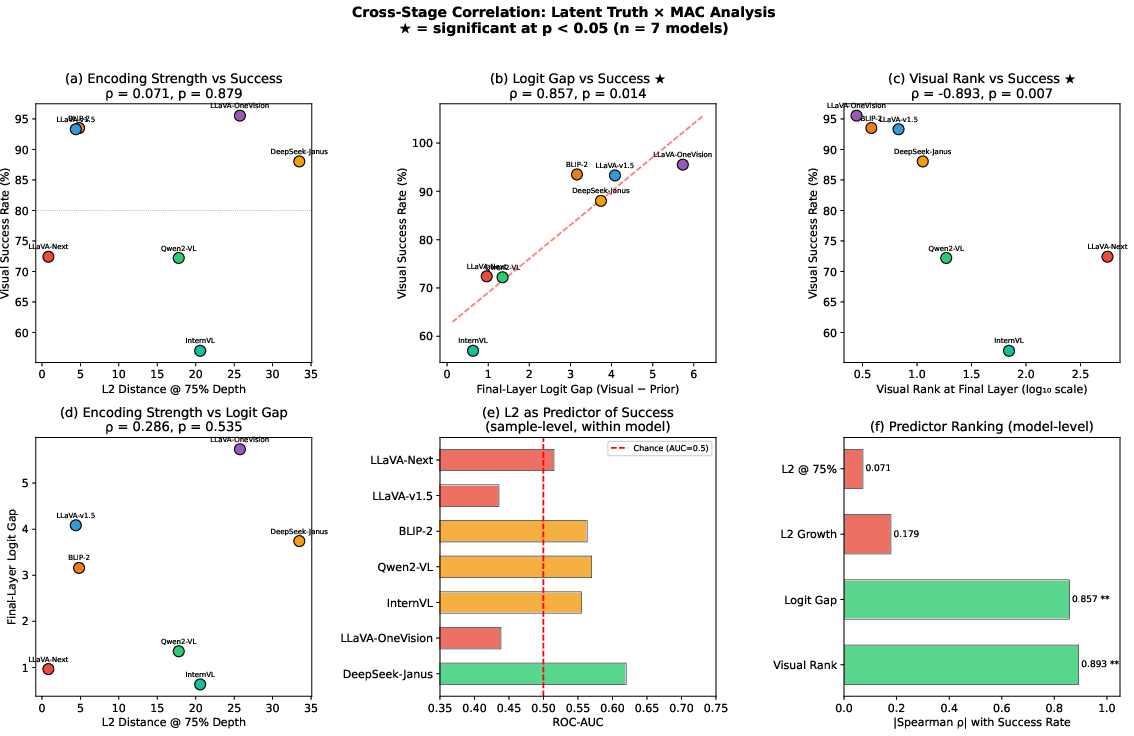
- MAC analysis and causal activation patching reveal that the final-layer logit gap, not the crossover depth, critically predicts visual grounding success across scales.
- Inference-time steering interventions improve visual grounding by up to 3.8% without retraining, highlighting the potential for lightweight, training-free fixes.
Arbitration Versus Perception in Vision-LLM Failures: Encoding-Grounding Dissociation
Introduction
The paper “Arbitration Failure, Not Perceptual Blindness: How Vision-LLMs Resolve Visual-Linguistic Conflicts” (2604.09364) presents a comprehensive mechanistic analysis of errors in vision-LLMs (VLMs) facing visual-linguistic conflicts. The central claim is that VLMs do not fail due to a lack of perceptual capability (“perceptual blindness”), but because the arbitration mechanisms downstream—where visual and linguistic signals compete—often default to prior linguistic knowledge even when visual evidence is correctly encoded. This encoding-grounding dissociation is demonstrated systematically across ten VLM architectures ranging in scale from 7B to 72B parameters.
The authors develop a diagnostic and intervention pipeline combining layerwise Logit Lens probing (Multimodal Arbitration Crossover, MAC), latent state analysis, causal activation patching, and training-free activation steering to separate and manipulate perception and arbitration processes in VLMs.

Figure 1: When presented with a counterfactual image (e.g., a blue banana), VLMs perceptually encode the visual evidence ("blue") internally but the downstream arbitration mechanism often outputs the linguistic prior ("yellow"), indicating an arbitration bottleneck.
MAC Analysis: Tracking Visual-Linguistic Arbitration
The Multimodal Arbitration Crossover (MAC) procedure systematically analyzes the competition between visual and linguistic priors using a conservative six-variant token-matching protocol applied to Logit Lens outputs at every transformer layer. For each layer, MAC records the maximum logit values for both the visually-grounded token (e.g., "blue") and the prior-consistent token (e.g., "yellow") and identifies the first stable crossover layer where the visual signal overtakes the prior.
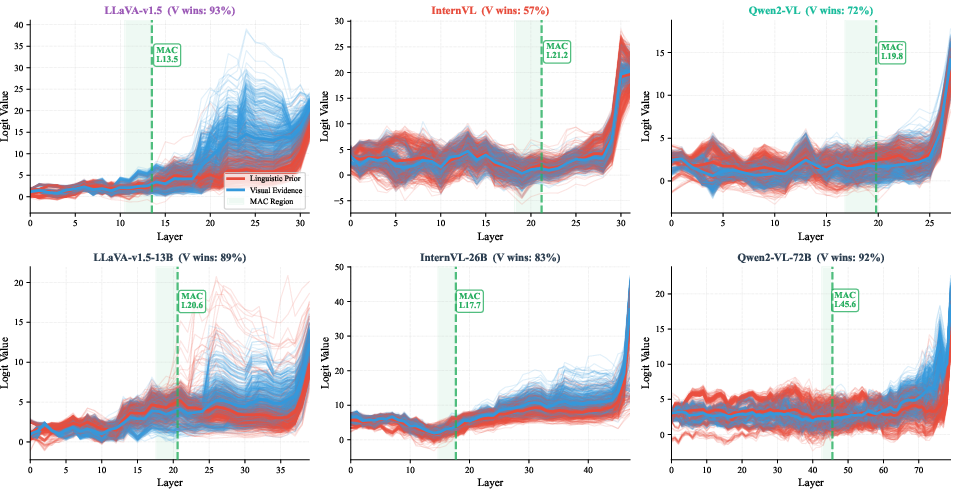
Figure 2: Left—a procedural illustration of MAC; Right—logit trajectories for typical models, showing where visual logits exceed priors and how this differs by architecture and scale.
Key findings from MAC analysis include:
- Crossover depth varies substantially across models (from 36% to 71% of layer depth), with larger models resolving conflicts earlier and with larger logit margins.
- Attribute type affects arbitration dynamics: crossover patterns differ between color and size attributes, indicating attribute-specific arbitration pathways.
- Scaling models increases visual win rates and shifts crossover points earlier, but the critical factor for success is the final-layer logit gap rather than the specific depth of crossover.
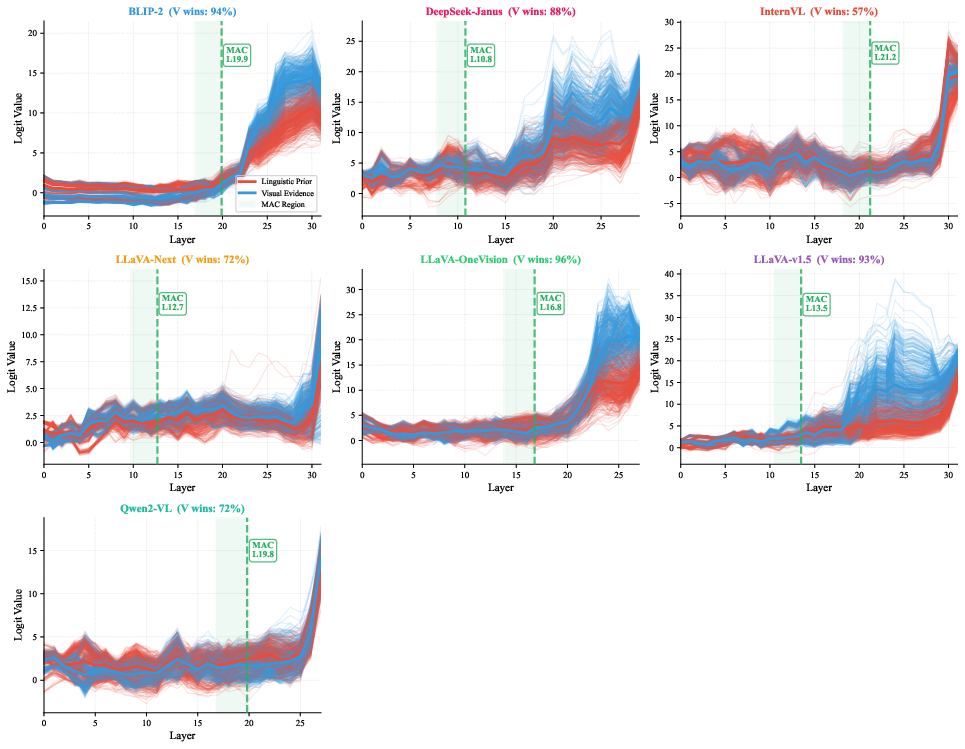
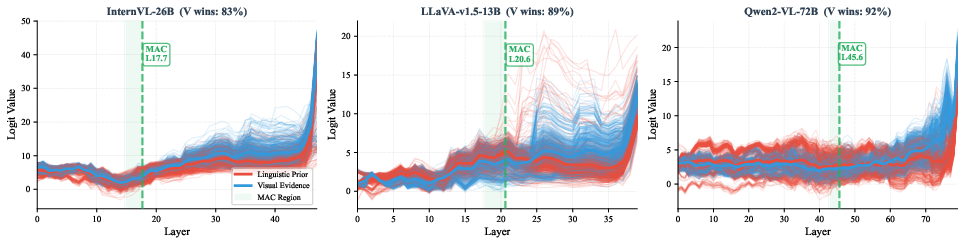
Figure 3: MAC logit trajectories for seven primary models and three scaled-up variants, visualizing per-layer evolution of visual versus prior token preferences and final success rates.
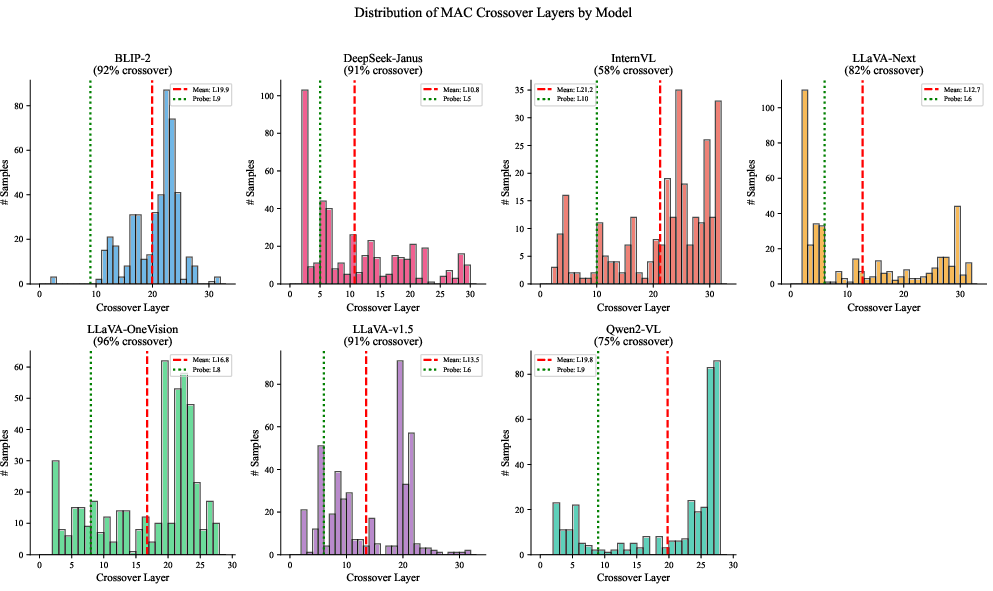
Figure 4: Distribution of per-sample MAC layers highlighting integrator speed and variance across models—fast integrators like DeepSeek-Janus and LLaVA-Next versus slow integrators such as Qwen2-VL and InternVL2.
Encoding-Grounding Dissociation
To test whether grounding failures derive from insufficient perceptual encoding, the authors systematically compare internal hidden state representations (using L2 distance metrics and linear probes) between successful (visually grounded) and failed (prior-dominated) cases, both within and across model architectures.
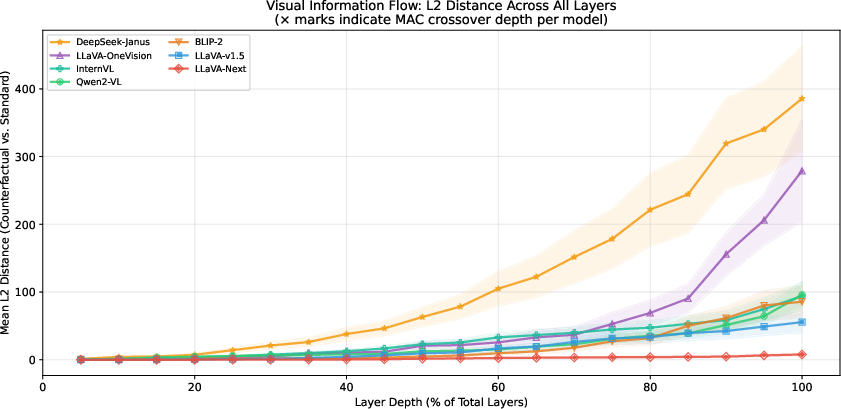
Figure 5: Fine-grained trajectory of visual encoding strength (L2 distance) across transformer depth, showing monotonically increasing and unsuppressed encoding up to the final layer, regardless of outcome.
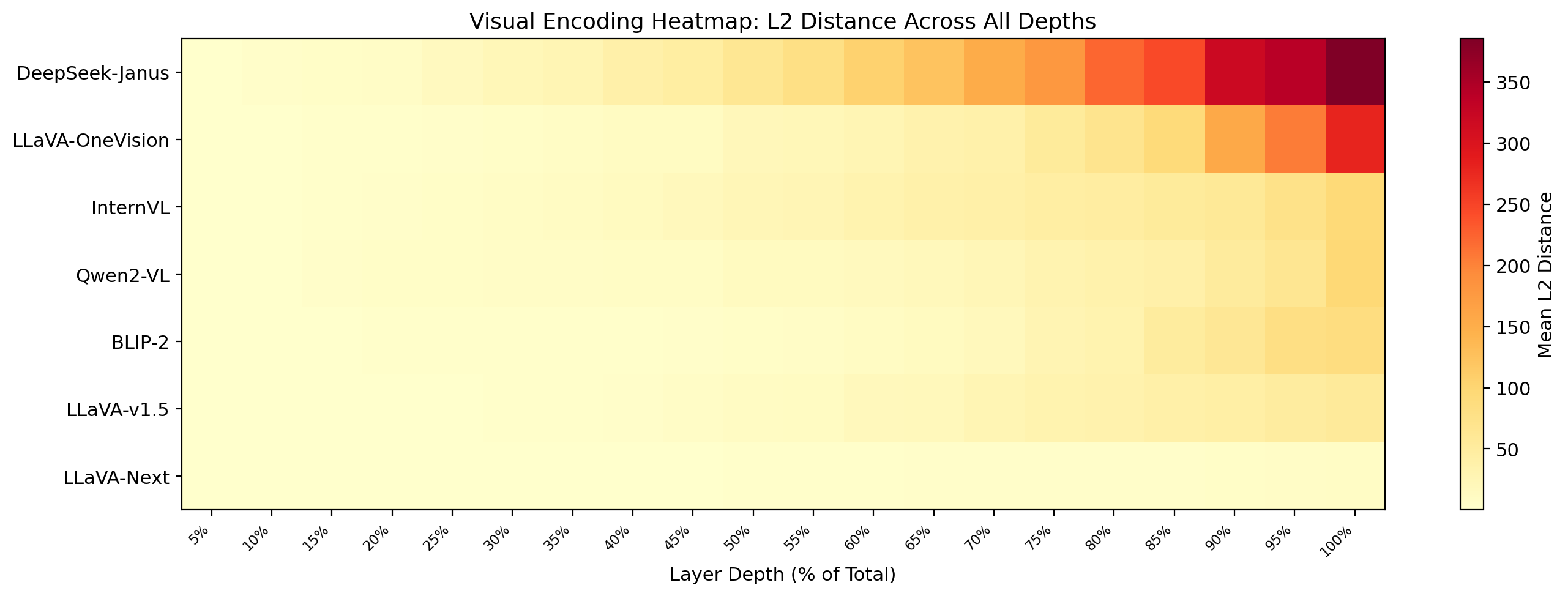
Figure 6: Cross-model heatmap of visual encoding strength across depth; models organize into strong, moderate, and weak tiers, but encoding persists for all.
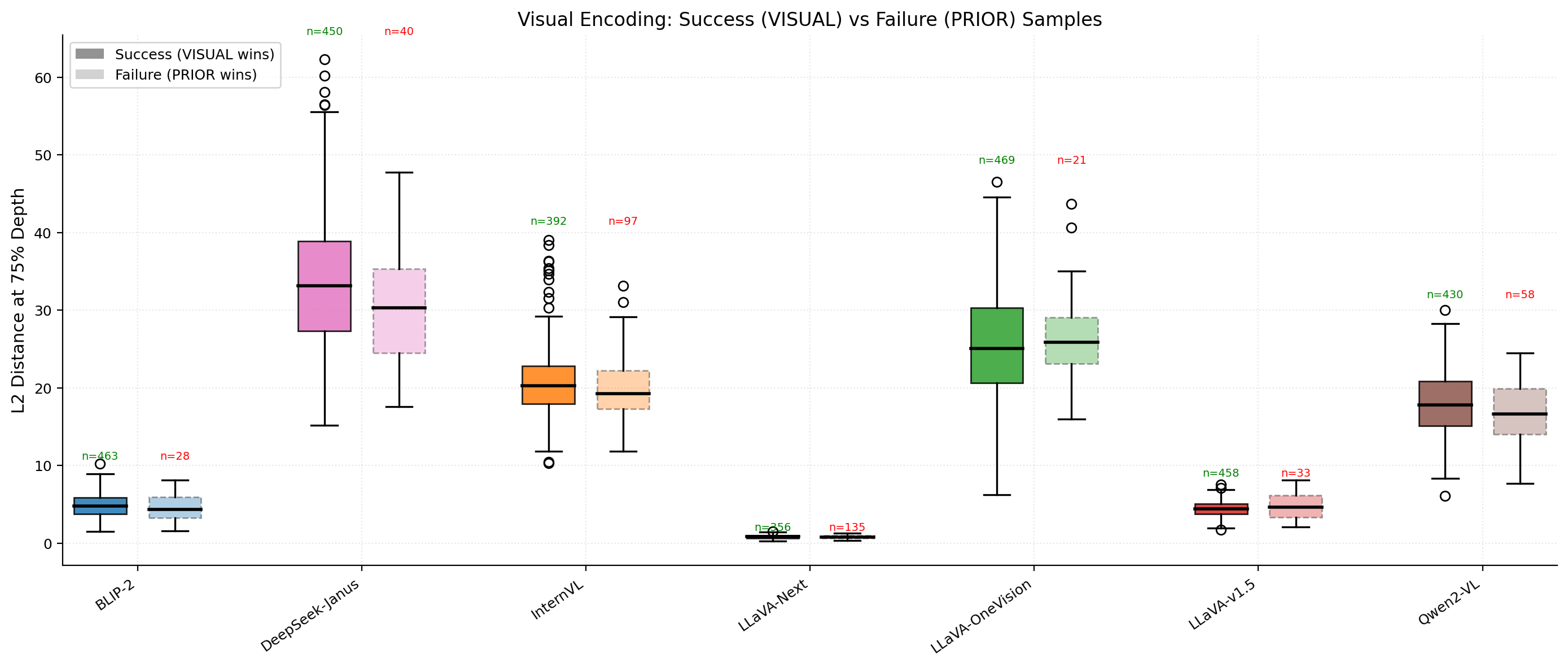
Figure 7: Distributional comparison of encoding strength in success versus failure cases; distributions overlap extensively, indicating no substantial difference regardless of grounding outcome.
Empirical findings:
Causal Validation via Full-Sequence Activation Patching
The strict correlational evidence is reinforced with causal intervention: activation patching is performed at the MAC-identified cross-over layers. Injecting hidden states from standard-image runs into counterfactual runs at these layers causally alters 60%–84% of model outputs, flipping answers from visual to prior completions. Critically, last-token patching—standard in text-only LLM manipulation—has almost no effect (<1% flip rate) due to distribution of visual information across the whole token sequence.

Figure 9: Schematic for full-sequence activation patching procedure, contrasting ineffectiveness of last-token patching (which targets only final position) with broad efficacy of patching the full token sequence.

Figure 10: Case studies of activation patching, demonstrating causal flipping of outputs from the visually grounded answer to the linguistic prior across different architectures.
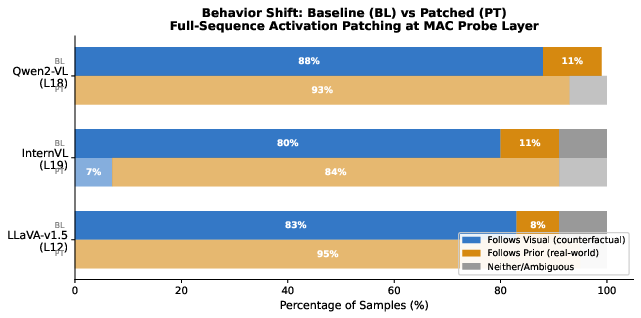
Figure 11: Behavioral output distributions pre- and post-patching, evidencing that patching reverses dominant model behavior across all tested models.
Token-type decomposition further reveals that the effect is carried nearly entirely by image tokens, with text tokens contributing negligibly except in certain smaller models, an effect which disappears at larger scales.
Training-Free Activation Steering Interventions
Translating diagnosis to remedy, the authors introduce inference-time steering interventions: (1) linear steering via contrastive activation addition, and (2) distributed sparse autoencoder (SAE)-guided steering via residual manipulation. Both methods are applied at early layers (well before MAC cross-over) and operate over full token sequences.
The interventions yield up to +3.8% improvement in visual grounding without regressing other behavior, and require no model retraining or fine-tuning. The SAE-based method achieves higher precision—improving more samples per degradation—by targeting multiple monosemantic visual/prior-aligned features.
Implications and Theoretical Significance
This work makes several strong and, in some cases, counterintuitive claims:
- Grounding failures in VLMs do not result from perceptual blindness. Instead, visual evidence is already encoded robustly at the hidden-state level, and the locus of failure is in arbitration, where model outputs are determined.
- Downstream arbitration mechanisms, not perceptual encoders, are the primary bottleneck for robust visual grounding in current connector-based VLM architectures. Scaling and architecture alter arbitration profiles but do not break encoding-grounding dissociation.
- Distributional properties of visual-linguistic conflict resolution (e.g., attribute specificity, integrator speed, and scaling behavior) suggest that arbitration is implemented structurally rather than as a simple function of model capacity.
Practical implications include:
- Primacy of model interpretability tools that probe arbitration (not just perception): Mechanistic frameworks must account for post-perceptual decision-making processes.
- Necessity of full-sequence or distributed intervention for effective guidance: Conventional token-selective editing (as in text-only LLM methods) is insufficient—visual information is distributed.
- Feasibility of lightweight, training-free behavioral interventions: Both linear and SAE-guided steering at early layers can systematically improve visual grounding.
This diagnostic and intervention methodology informs both future VLM development (e.g., inducing architectural inductive biases for arbitration fidelity) and the creation of mechanistically-motivated benchmarks and interpretability pipelines. The work parallels and complements causality- and steering-focused approaches for hallucination reduction in LLMs and VLMs [su-etal-2025-activation; wu-etal-2025-sharp].
Conclusion
This systematic study establishes—across ten diverse vision-LLMs and a comprehensive mechanistic pipeline—that failures in visual grounding during visual-linguistic conflicts are primarily arbitration failures, not perceptual deficits. Visual evidence is encoded reliably and equally in both correct and failed responses. Success is dictated by whether the model's arbitration mechanism prioritizes the visual signal at the output stage. Causal patching and distributed activation steering provide both the evidence and means to correct such failures, with early-layer interventions yielding measurable increases in visual grounding accuracy. These findings direct both the mechanistic interpretability community and VLM system designers toward arbitration as the central limiting component in robust, truth-guided multimodal reasoning.