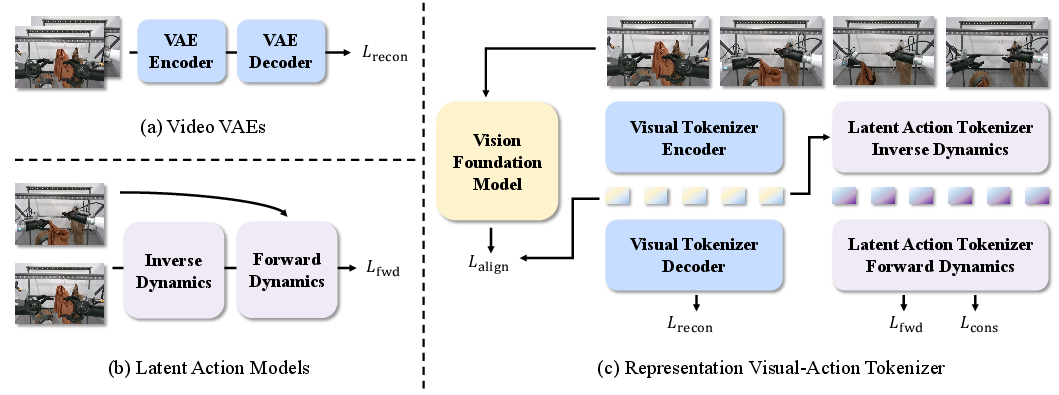
- The paper presents RepWAM, a model that semantically aligns visual latents with action tokens to enhance precision in robot control.
- It introduces RepViTok, a visual-action tokenizer combining a vision transformer autoencoder with dynamics models for task-relevant tokenization.
- Empirical evaluations on dual-arm manipulation and RoboTwin simulations demonstrate superior performance, data efficiency, and robust long-horizon planning.
Summary of "RepWAM: World Action Modeling with Representation Visual-Action Tokenizers"
Introduction and Motivation
The paper introduces RepWAM, a representation-centric World Action Model (WAM) that addresses critical limitations in existing latent representations for vision-based robot control. Prior WAMs have adopted video tokenizers oriented towards pixel-level reconstruction, resulting in visual latents dominated by appearance attributes rather than semantics critical for manipulation, and a suboptimal decoupling of visual latents from action representations. RepWAM proposes a unified representation aligning both visual latents and action abstractions in a semantically meaningful space, thereby improving grounding for both perceptual and motoric inference.
Representation Visual-Action Tokenizer (RepViTok)
The core innovation is the Representation Visual-Action Tokenizer (RepViTok), which semantically aligns visual latents with a frozen visual foundation model. RepViTok's architecture separates visual tokenization and latent action extraction:
Causal World Action Model Architecture
RepWAM employs a causal diffusion transformer that autoregressively predicts future visual and action token sequences conditioned on both initial observations and textual instructions. The model unifies the world model and action expert streams with shared attention layers and modality-specific feed-forwards, using a chunk-based attention mask for effective long-horizon modeling. Training objectives rely on a joint conditional flow-matching loss, separately regularizing visual and action streams.
Empirical Evaluation
Real-World Robotic Manipulation
RepWAM is evaluated on a dual-arm Franka platform across three increasingly difficult manipulation tasks (cluttered pick-and-place, articulated drawer operation, and precision tube insertion). Data efficiency in real-world adaptation is demonstrated via fine-tuning on just 50 demos. The 5B parameter variant outperforms strong baselines (π0.5, Lingbot-VA), achieving the highest success rates, especially on tasks involving long-horizon planning and fine spatial reasoning.
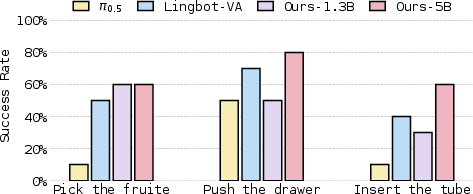
Figure 2: Real-world task success rate (10 rollouts per task), RepWAM-$5$B consistently outperforms π0.5 and Lingbot-VA, with largest gains on complex articulated and fine-grained manipulation.
Successes are visualized in sequence, demonstrating stable approaches, precise manipulation, and minimal corrective oscillations, indicating improved semantic grounding and generative coherence in control.

Figure 3: Qualitative rollouts for three real tasks, illustrating composed, precise, and goal-directed behaviors supported by the learned visual-action space.
Simulation: RoboTwin 2.0
On the RoboTwin 2.0 suite, RepWAM-$5$B sets a new state-of-the-art for models trained from scratch (i.e., without reliance on video generator pretraining), achieving 89.3 (Easy) and 88.4 (Hard) average success rates across 50 dual-arm tasks. This demonstrates the effect of semantically aligned visual-action spaces for robust generalization under heavy domain randomization.
Ablation Studies
A series of ablations confirm the critical role of each design decision:
- Tokenizer comparison: RepViTok outperforms pixel reconstruction-driven tokenizers (WAN2.2 VAE, ViTok) across video prediction metrics, open-loop action accuracy, and closed-loop task execution. The introduction of feature alignment loss is shown to be essential for meaningful, instruction-following closed-loop behavior.
- Latent action modeling: Two-stage latent action training (pretraining on visual-action tokens, then robot action adaptation) achieves higher transferability and better downstream control compared to direct or joint prediction approaches. RepViTok’s latent actions are shown to concentrate on manipulation-induced change, contrasting with previous entangled latent codes.
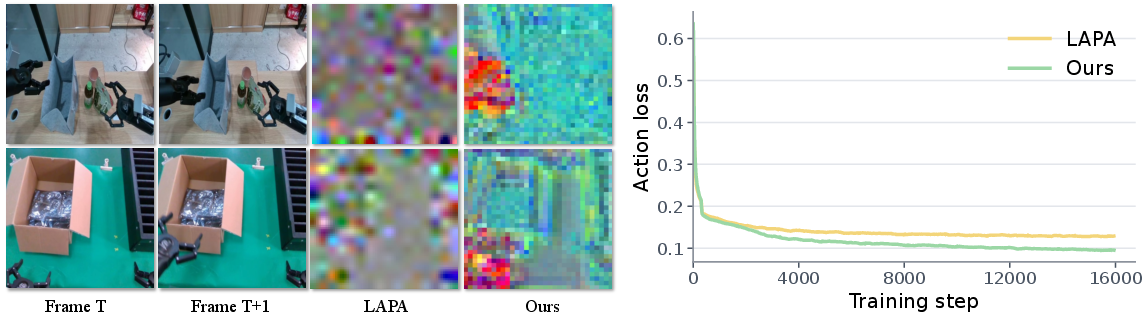
Figure 4: Action-latent visualization and transfer—RepViTok’s latents are more focused and yield lower inverse dynamics loss, thus more readily mappable to real control streams.
- Classifier-free guidance: Unlike video-generation-pretrained models, RepWAM’s visual-action alignment reduces reliance on classifier-free guidance for robust performance during inference, allowing for more efficient and less brittle deployment.
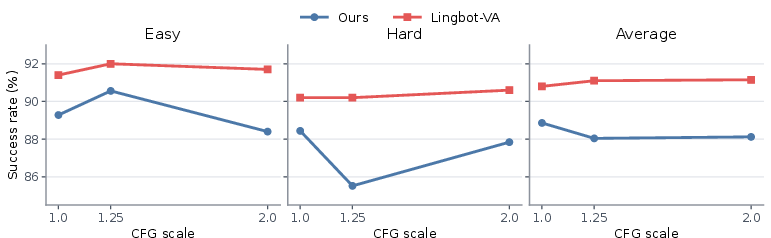
Figure 5: Effect of video classifier-free guidance; RepViTok-based RepWAM achieves optimal success rate at guidance scale 1.0, exhibiting less dependence on CFG than WAN-pretrained methods.
Tokenizer Reconstruction Quality
RepViTok maintains competitive image and video reconstruction fidelity despite its semantic alignment objective, preserving both low-level detail and high-level semantic consistency.

Figure 6: Example reconstructions on ImageNet and UCF101—semantic fidelity and temporal consistency are preserved.
Implications and Future Directions
RepWAM’s architecture demonstrates that explicit, semantics-centric alignment of visual and action latent spaces can dramatically improve robot world modeling—yielding interpretable, transferable, and compositionally stronger policies. The results validate that minimizing the topology gap between visual and action representations is critical for scaling WAMs to complex, embodied tasks under language guidance. This is especially impactful in model scaling, data efficiency, and real-world transfer.
The methodology signifies a shift from inheritance-heavy reliance on generative pretraining toward more modular and semantically motivated architectural choices. It also offers a clearer strategy for incorporating large-scale, uncurated internet video data for WAM pretraining, provided the alignment objective remains central.
Conclusion
RepWAM establishes a blueprint for semantically aligned latent spaces in WAMs, advancing embodied action modeling in both precision and robustness. The findings suggest that future work should focus on integrating cross-domain video data and human-centric trajectories, leveraging the architectural decoupling and alignment presented here to broaden skill generalization and deployment flexibility.