Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Abstract: World Action Models (WAMs) have emerged as a promising alternative to Vision-Language-Action (VLA) models for embodied control because they explicitly model how visual observations may evolve under action. Most existing WAMs follow an imagine-then-execute paradigm, incurring substantial test-time latency from iterative video denoising, yet it remains unclear whether explicit future imagination is actually necessary for strong action performance. In this paper, we ask whether WAMs need explicit future imagination at test time, or whether their benefit comes primarily from video modeling during training. We disentangle the role of video modeling during training from explicit future generation during inference by proposing \textbf{Fast-WAM}, a WAM architecture that retains video co-training during training but skips future prediction at test time. We further instantiate several Fast-WAM variants to enable a controlled comparison of these two factors. Across these variants, we find that Fast-WAM remains competitive with imagine-then-execute variants, while removing video co-training causes a much larger performance drop. Empirically, Fast-WAM achieves competitive results with state-of-the-art methods both on simulation benchmarks (LIBERO and RoboTwin) and real-world tasks, without embodied pretraining. It runs in real time with 190ms latency, over 4$\times$ faster than existing imagine-then-execute WAMs. These results suggest that the main value of video prediction in WAMs may lie in improving world representations during training rather than generating future observations at test time. Project page: https://yuantianyuan01.github.io/FastWAM/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question about teaching robots: Do robots really need to “imagine the future” while they’re acting, or is it enough that they practiced imagining during training? The authors introduce a faster robot controller called Fast-WAM that learns from future video prediction while training, but skips making future videos during real use. They show it stays strong at tasks while being much faster.
What did the researchers want to find out?
They focused on World Action Models (WAMs), which try to predict what the camera will see next and what actions the robot should take. Most WAMs work like this: first imagine future video frames, then choose actions based on that imagined future. That can be slow.
Their two main questions were:
- Is the benefit of WAMs mainly from practicing video prediction during training?
- Or do robots also need to explicitly generate future videos at test time to act well?
How did they approach the problem?
Think of two phases:
- Training time = practice time
- Test time (inference) = game time
In practice, many WAMs imagine several future frames during game time, which takes extra time. The authors built Fast-WAM to keep the benefits of practice (learning from video prediction) but remove the slow step of imagining future frames during game time.
Here’s the idea in everyday terms:
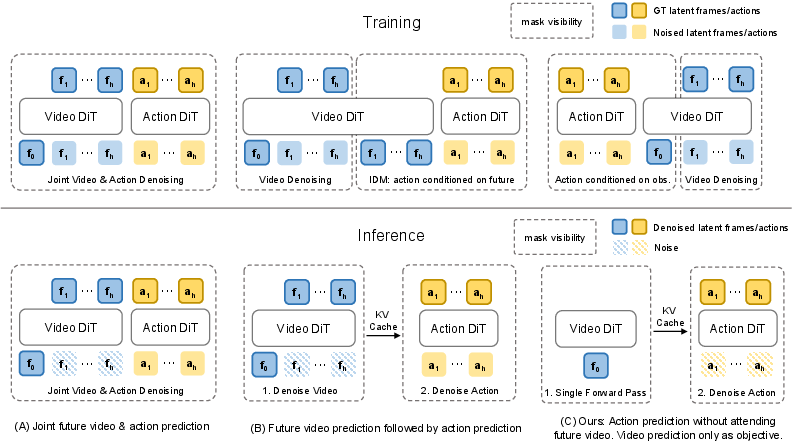
- During training, the model learns two things at once: how videos of the world change (video prediction) and how to pick good actions (action prediction). This “co-training” helps it build a better understanding of physics and motion.
- During test time, instead of generating future videos, the model looks at the current image and instruction once and directly outputs actions. No extra future “imagination” needed.
To make this work, they used:
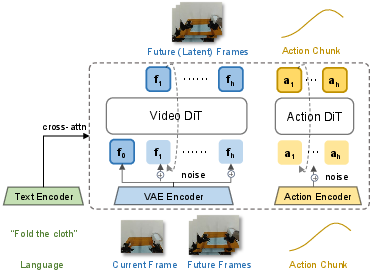
- A video Diffusion Transformer (DiT): a model originally trained to create or clean up videos by starting with noisy frames and step-by-step “denoising” them. You can think of diffusion as starting with a blurry, noisy picture and gradually making it clear.
- In Fast-WAM, this powerful video model is repurposed as a fast “world encoder” that extracts useful features from the current frame. Then a separate “action expert” predicts the next chunk of actions.
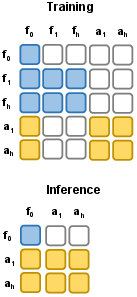
- A “structured attention mask” controls who can “see” what inside the model so that, during training, future information doesn’t leak into action predictions in a cheating way.
They trained both the video part and the action part with a technique called flow matching. In simple terms, flow matching teaches the model how to move a noisy sample toward a clean, correct sample—like guiding a messy sketch into a crisp drawing.
To fairly test their question, they built controlled variants:
- Fast-WAM-Joint: imagines future video and actions together at test time.
- Fast-WAM-IDM: first imagines future video, then predicts actions from it at test time.
- Fast-WAM without video co-training: removes the video-prediction practice during training to see how important that practice is.
They evaluated on:
- Two simulator benchmarks (LIBERO and RoboTwin), which include many different robot tasks.
- A real-world towel-folding task, which is long and tricky because towels are floppy and change shape.
They measured both success rate and speed (how long each decision takes, called latency).
What did they find?
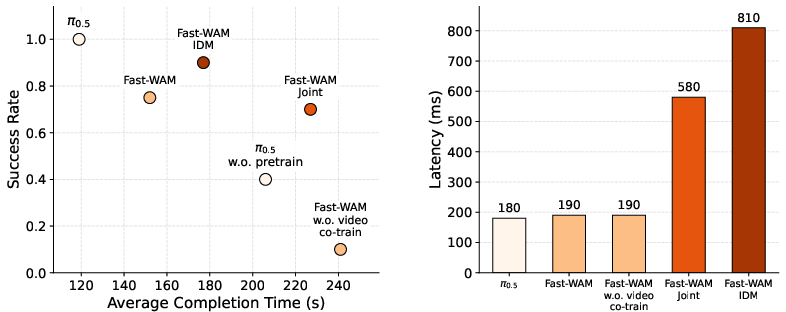
- Fast without imagination at test time: Fast-WAM performed about as well as the versions that imagine the future during test time.
- Practice matters more than test-time imagination: When they removed video co-training during training, performance dropped much more than when they removed test-time future generation. In other words, the “practice” of predicting future video during training is crucial.
- Much faster in real time: Fast-WAM ran in real time with about 190 ms latency—over 4× faster than models that generate future videos at test time.
- Strong across tasks without special pretraining: On both simulation suites (LIBERO and RoboTwin) and the real towel-folding task, Fast-WAM was competitive with state-of-the-art methods, even without extra “embodied pretraining” (massive robot datasets for pretraining).
- In the real world: All versions that used video co-training did well; the version without video co-training struggled badly. Fast-WAM also completed tasks faster than the imagine-then-execute versions.
Why is this important?
- Faster robots: Skipping test-time future-video generation keeps performance high while making decisions much faster, which is essential for responsive, safe, real-world robots.
- Simpler, more efficient design: You can get the benefits of world modeling by learning from video prediction during training, without paying the cost of “imagining the future” every time the robot acts.
- Better use of training: The results suggest the main advantage of WAMs is that video prediction shapes better internal “world” representations during training, not that robots need to produce future videos at test time.
What’s the takeaway?
The paper shows that robots don’t need to actively “imagine” future videos while they’re working to perform well. Instead, what really helps is practicing that skill during training to build a good sense of how the world behaves. This leads to real-time, strong performance without the extra slowdown. In the future, scaling up training data and model size could make this approach even better.
Knowledge Gaps
Unresolved limitations, knowledge gaps, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain after this work. Each point is phrased to be actionable for future researchers.
- Inference-time temporal context: Fast-WAM retains only the clean latent tokens of the first observation frame at test time. It remains unknown how performance changes if the inference encoder ingests multiple recent frames (i.e., short temporal windows) or maintains a recurrent latent state to better handle dynamics and partial observability.
- Omitted outer auto-regressive control loop: The study intentionally removes the outer rollout loop and analyzes single-chunk generation. The effects of reintroducing receding-horizon action generation (multiple chunks with feedback) on long-horizon tasks, compounding error, and stability are not evaluated.
- When does imagination help? The benchmarks may not strongly require far-sighted foresight. There is no targeted evaluation on tasks where future prediction should be critical (e.g., occlusions, delayed consequences, non-myopic constraints, multi-step tool-use). A principled suite to stress-test scenarios where explicit imagination should help is missing.
- Video co-training objective design: Only a flow-matching objective on future video latents is explored. The impact of alternative world-modeling signals (e.g., masked video modeling, predictive coding, contrastive dynamics, autoregressive modeling, latent-state models) and hybrids on action performance is unstudied.
- Training weight and horizon sensitivity: There is no ablation on the co-training weight λ, the video prediction horizon T, or the action horizon H. How these hyperparameters trade off between representation quality, stability, and downstream control remains unclear.
- Noise schedule and sampler choices: The paper fixes a logit-normal schedule and 10 denoising steps for action sampling. The effect of different schedules, step counts, samplers, and classifier-free guidance scales on both performance and latency is not quantified.
- Diffusion-to-one-step distillation: Although test-time video denoising is removed, action generation still requires iterative denoising. Whether policy distillation (to 1-step or few-step predictors) can further reduce latency without degrading performance is not explored.
- Architecture choices and attention masks: The Mixture-of-Transformer with shared attention and the specific masking strategy are not ablated. It is unknown whether different cross-branch connectivity, gating, or routing strategies (e.g., more experts, router learned vs fixed masks) would improve performance or stability.
- Representation freezing vs fine-tuning: The extent of freezing vs fine-tuning for the pretrained video DiT, VAE, and text encoder is not detailed or ablated. The relative contributions of backbone scaling, adaptation depth, and domain shift from internet videos to robotics remain uncertain.
- Quality of learned world representations: There is no probing or interpretability analysis (e.g., dynamics identification, latent rollouts, linear probes, CKA) to verify that co-training actually encodes physically meaningful state transitions, nor how representation quality correlates with control success.
- Correlation between video prediction quality and control: The work does not measure future prediction accuracy or fidelity versus policy performance, leaving unanswered whether better video modeling directly yields better actions or if benefits plateau.
- Partial observability and memory: The method does not maintain a persistent latent state across time in inference (stateless per-chunk), and the impact of incorporating memory (RNNs, transformers over history, latent state-space models) on tasks with hidden state is not studied.
- Real-world scope: Real-world evaluation is limited to a single (albeit challenging) towel-folding task on one platform. Generality across multiple manipulation tasks, objects, embodiments, sensors, and environments (lighting, clutter) is untested.
- Language robustness: The paper uses a pretrained text encoder but does not test instruction generalization (paraphrases, unseen verbs/nouns, compositional instructions) or robustness to ambiguous or noisy language.
- Multimodality beyond vision: The approach is vision-centric; integration of force/torque, tactile, audio, or richer proprioception and their synergy with video co-training remains unexplored.
- Mobile manipulation and locomotion: The evaluation focuses on stationary arm manipulation. It is unknown how the approach extends to mobile platforms, navigation + manipulation tasks, and dynamics-rich domains (e.g., locomotion).
- Data efficiency and scaling laws: Claims of data efficiency lack learning curves or systematic scaling studies versus number of demonstrations, video-only data, or model size. How co-training benefits change with data and compute scale remains open.
- Fairness and compute comparability: Baselines vary in parameter count, pretraining, and training budgets. A compute- and parameter-matched comparison (including training steps, GPUs, wall-clock) is not provided, leaving room for confounding factors.
- Robustness to dynamics and visual shifts: Beyond LIBERO and randomization in RoboTwin, robustness to nonstationary dynamics (e.g., friction changes), heavy occlusions, domain shifts (camera intrinsics/extrinsics), and adversarial perturbations is not assessed.
- Multi-camera encoding strategy: Cameras are concatenated into a single image. Whether per-camera tokenization with camera-aware positional encodings, cross-view attention, or calibration-aware fusion would improve generalization or robustness is untested.
- Autonomy and safety: Failure modes, unsafe behaviors, and safety constraints (e.g., joint limits, collision avoidance) are not analyzed. No metrics for smoothness, energy, or safety compliance are reported.
- Latency and deployment on-edge: Latency is reported on a single high-end GPU. Performance on embedded/edge compute typical of robots, end-to-end control loop timing (including perception and actuation), and throughput under multi-camera high-resolution inputs are not evaluated.
- Open-loop execution within a chunk: Action chunks are sampled then executed; the effect of chunk length on responsiveness and closed-loop corrections mid-chunk is not analyzed. Methods for intra-chunk feedback or adaptive horizon are not studied.
- Hybrid conditional imagination: A dynamic policy that enables explicit future generation only when uncertainty or myopic risk is high (e.g., via a gating mechanism) is not explored. When and how to turn on imagination remains an open design question.
- Pretraining with video-only corpora: Whether large-scale video-only pretraining (without actions) followed by action fine-tuning rivals or exceeds the proposed co-training remains unknown. The potential of leveraging vast unlabeled video is not assessed.
- Sim-to-real transfer: The study combines separate sim and real experiments but does not analyze sim-to-real transfer (e.g., train in sim → deploy on real), nor how video co-training influences transferability.
- Action tokenization and embodiment diversity: The action representation (dimensionality, discretization/continuous, controllers) is not fully specified, and generality across robot types with different kinematics and action spaces is untested.
- Uncertainty estimation and risk-aware control: The method does not quantify or propagate uncertainty from world representations to actions. Approaches for calibrated uncertainty, risk-sensitive objectives, or safe exploration are not investigated.
- Task diversity and metrics: Beyond success rate and completion time, other metrics (trajectory smoothness, force regulation, precision, failure taxonomy) are omitted, limiting diagnostic insight into where Fast-WAM helps or struggles.
- Reproducibility artifacts: While a project page is provided, details on dataset release (e.g., real-world demonstrations), full training scripts, and exact hyperparameters for all ablations are not fully specified, impeding independent replication.
- Theoretical understanding: The hypothesis that video co-training improves action-grounded representations lacks formal analysis. Theory or controlled synthetic studies to explain why and when co-training helps (e.g., via information-theoretic or generalization bounds) are absent.
Practical Applications
Practical Applications of Fast-WAM
Below are actionable, real-world applications derived from the paper’s findings and methods. They are grouped by deployment horizon and annotated with sector links, potential tools/products, and key assumptions or dependencies.
Immediate Applications
- Low-latency robot manipulation in production cells
- Sector: Robotics, Manufacturing, Logistics
- Use case: Replace “imagine-then-execute” WAMs with Fast-WAM to cut inference latency from ~0.8–1.0 s to ~0.19 s for tasks such as pick-place, insertion, screwing, bin sorting, palletization, and dual-arm coordination (RoboTwin-like).
- Tools/workflows: ROS2-compatible Fast-WAM control node; action-chunk planner (H=32) with 10-step flow-matching sampler; deployment on an edge GPU (e.g., RTX 40-series) with multi-camera ingestion via VAE.
- Assumptions/dependencies: Availability of a pretrained video DiT (e.g., Wan2.2-5B) and its VAE/T5 encoders; task demonstrations with future-frame supervision for video co-training; safety interlocks for industrial settings.
- Household service robots with real-time response
- Sector: Consumer Robotics, Retail Automation
- Use case: Laundry folding, general tidying, opening/closing containers, and simple tool-use where sub-200 ms control loops improve safety and human cohabitation.
- Tools/products: “Imagination-free” inference mode in home robots; onboard Fast-WAM inference module with camera streams concatenated into a single VAE input; skill library trained with joint action/video flow-matching.
- Assumptions/dependencies: High-quality language instructions and demonstrations; robust camera placement and calibration; compliance and force control layers.
- Teleoperation assistance and shared autonomy
- Sector: Healthcare (non-invasive assistive robotics), Field Robotics
- Use case: Leverage Fast-WAM’s world-grounded latent encoder for predictive stabilization of teleop inputs (e.g., smoothing noisy operator signals, suggesting action chunks).
- Tools/workflows: Teleop UI that previews action chunks without generating future frames; confidence-estimation from latent features for assist modes.
- Assumptions/dependencies: Stable network latency; integration with haptic devices and safety supervisors; task demonstrations that cover typical operator maneuvers.
- Data-efficient robot learning for small labs and startups
- Sector: Academia, Startups, Education
- Use case: Achieve competitive performance on LIBERO/RoboTwin-like tasks without embodied pretraining, lowering the barrier to entry for research groups with moderate compute.
- Tools/workflows: Open-source training scripts using Fast-WAM’s joint video/action flow-matching; curriculum that adds video co-training to existing VLA fine-tuning pipelines; structured attention masks to prevent future-token leakage.
- Assumptions/dependencies: Access to benchmark-style demos (500–27,500 per suite, as in LIBERO/RoboTwin); GPU with 24–48 GB memory for 6B-parameter training.
- Retrofitting existing VLA policies with video co-training
- Sector: Robotics, Software
- Use case: Maintain a direct-policy interface at inference while augmenting training with a video prediction objective to improve physical priors and temporal reasoning.
- Tools/workflows: Plug-in video co-training head on top of existing VLAs; shared attention or MoT bridge to couple world encoder and action expert.
- Assumptions/dependencies: Access to future-frame labels for co-training; alignment between tokenizers (action/video) and task instruction encoders.
- Privacy-preserving on-device control
- Sector: Healthcare (assistive), Consumer Robotics, Government
- Use case: Real-time, on-device vision-to-action without streaming video to the cloud, reducing privacy risk while retaining high responsiveness.
- Tools/products: Edge inference stack with Fast-WAM world encoder; locally stored latent features; configurable CFG=1.0 flow-matching inference for deterministic behavior.
- Assumptions/dependencies: Sufficient on-device compute; thermal and power management; local logging for safety audits.
- Benchmarking and ablation methodology for embodied AI
- Sector: Academia, Standards/Policy
- Use case: Adopt the paper’s controlled variants (Joint, IDM, no video co-training) as a template to disentangle training-time representation benefits from inference-time imagination across new benchmarks.
- Tools/workflows: Reusable ablation harness with shared backbones/tokenization; latency and completion-time metrics beyond binary success.
- Assumptions/dependencies: Community availability of controlled baselines; standardized metrics including latency and efficiency, not just success rate.
Long-Term Applications
- Generalist embodied agents with scalable world-co-training
- Sector: Robotics (home, industrial, service), Software Platforms
- Use case: Standardize the “co-train video + direct control” design pattern across fleets of robots—one encoder, many action experts fine-tuned for embodiment or task families.
- Tools/products: Robot OS integrating MoT world encoder with per-embodiment action experts; skill marketplace where new skills attach to a shared world backbone.
- Assumptions/dependencies: Larger cross-embodiment video-action datasets; robust transfer learning and calibration tools; versioned safety layers.
- Energy- and carbon-efficient AI policy and procurement
- Sector: Policy, Sustainability, Enterprise IT
- Use case: Favor inference-efficient architectures (skip test-time video generation) in public procurement and corporate sustainability plans for robotics deployments.
- Tools/workflows: Compliance checklists that include inference latency and energy per task; LCA (life-cycle assessment) for AI-enabled automation.
- Assumptions/dependencies: Standardized measurement protocols for energy/latency; reporting requirements from regulators or buyers.
- Surgical and rehabilitation robots with faster inner loops
- Sector: Healthcare
- Use case: Use world co-trained encoders for precise, low-latency control in non-critical subroutines (e.g., instrument positioning, physical therapy assist), reserving safety-critical layers for certified controllers.
- Tools/products: Hybrid control stack where Fast-WAM proposes action chunks under strict constraints; safety-certified overrides and monitoring.
- Assumptions/dependencies: Regulatory approval; extensive validation datasets; fail-safe hardware and formal verification for critical paths.
- Aerial and mobile robots with on-device perception-control
- Sector: Drones, Autonomous Mobile Robots (AMRs), Agriculture
- Use case: Replace heavy test-time imagination with direct-policy inference to meet tight control loop budgets for navigation/manipulation (e.g., crop handling, inventory scanning).
- Tools/workflows: Compressed Fast-WAM variants (distillation/quantization) for embedded GPUs; multi-sensor (RGB-D, event cameras) latents into the world encoder.
- Assumptions/dependencies: Demonstrations with diverse dynamics; robust sensor fusion; reliable obstacle avoidance and fallback planners.
- Cloud-to-edge training-deployment platforms for robots
- Sector: Software, Cloud/Edge Infrastructure
- Use case: Train large world encoders with video co-training in the cloud and deploy only the direct-policy inference modules on edge devices to reduce bandwidth and latency.
- Tools/products: MLOps pipelines for versioning world encoders/action experts; telemetry dashboards tracking success rate, completion time, and latency.
- Assumptions/dependencies: Model portability across hardware; secure update channels; dataset governance and licensing for video pretraining.
- Safer human-robot interaction through latency budgeting
- Sector: Policy, Workplace Safety, Manufacturing
- Use case: Incorporate latency ceilings (e.g., ≤200 ms) into safety standards for collaborative robots, leveraging architectures like Fast-WAM to comply without sacrificing performance.
- Tools/workflows: Conformance tests that pair success metrics with completion time and latency; certification guides recommending imagination-free inference for certain classes of tasks.
- Assumptions/dependencies: Consensus from standards bodies; reproducible measurement across vendors and tasks.
- Cross-domain embodied agents in AR/VR and gaming
- Sector: Entertainment, Education
- Use case: Use video-co-trained world encoders with direct control for responsive embodied avatars and NPCs that interact physically with environments without costly future video synthesis.
- Tools/products: Game engine plugins that feed latent scene tokens to an action expert; training kits for physics-rich curricula.
- Assumptions/dependencies: Synthetic-to-real transfer for physics; domain-adapted action tokenization; engine integration for fast I/O.
- Compact, low-power variants for consumer devices
- Sector: Consumer Electronics, Smart Home
- Use case: Distill the 6B Fast-WAM into sub-1B models for appliances or micro-mobility devices that need simple physical interactions (e.g., smart drawers, robot grippers).
- Tools/workflows: Knowledge distillation from the video DiT encoder to lighter encoders; mixed-precision and sparsity; on-device autotuning.
- Assumptions/dependencies: Acceptable performance after compression; efficient VAEs for low-res inputs; thermal constraints.
Notes on feasibility across applications:
- The paper’s gains depend strongly on video co-training during training; removing it caused large drops. Any deployment should prioritize collecting or synthesizing future-frame visual supervision.
- The approach relies on access to pretrained video diffusion backbones and their encoders/VAEs (licensing and redistribution may limit commercial use).
- Reported results cover manipulation in simulation and a real-world towel-folding task; extensions to locomotion, aerial robotics, or surgical domains require new datasets and safety validation.
- Real-time performance was measured on a high-end GPU; embedded deployment will need model compression and engineering.
Glossary
- action chunk: A contiguous sequence of actions predicted as a block over a fixed horizon. "for simplicity, we focus on single action chunk generation and omit the outer auto-regressive loop."
- bimanual manipulation: Robotic tasks that require coordinated control of two arms simultaneously. "RoboTwin 2.0 is a challenging bimanual manipulation benchmark featuring more than 50 tasks that require coordinated dual-arm control."
- classifier-free guidance (CFG): A sampling technique in diffusion models that balances conditional and unconditional predictions to control generation strength. "During inference, we use 10 denoising steps with classifier-free guidance (CFG) scale set to 1.0."
- co-training: Jointly optimizing multiple objectives (here, action prediction and video modeling) so that one task shapes representations helpful for another. "Fast-WAM retains video co-training during training but removes explicit future generation at inference time, directly predicting actions from latent world representations in a single forward pass."
- cross-attention: An attention mechanism where one set of tokens attends to another (e.g., language) to incorporate conditioning information. "All token groups attend to the language embeddings through cross-attention."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion-based generative modeling of sequences like video. "Fast-WAM is built on top of the video Diffusion Transformer (DiT) from Wan2.2-5B, which serves as the world modeling backbone."
- embodied pretraining: Pretraining models on large-scale robotics or embodied interaction data before task-specific training. "Fast-WAM achieves competitive results with state-of-the-art methods both on simulation benchmarks (LIBERO and RoboTwin) and real-world tasks, without embodied pretraining."
- flow matching objective: A generative training objective that learns velocity fields to transport noise samples toward data samples over a continuous time variable. "The model is trained to predict the corresponding velocity field with a standard flow matching objective"
- imagine-then-execute paradigm: A control approach where future observations are generated first and actions are then chosen based on the imagined future. "Most existing WAMs follow an imagine-then-execute paradigm: they first generate future observations, then predict actions conditioned on the imagined future."
- inverse dynamics: Predicting actions that cause a transition from a current state to a desired future state. "then feeding it to an inverse dynamics or action prediction module."
- latent tokens: Compressed representations (tokens) in a learned latent space (e.g., from a VAE) used for efficient modeling of high-dimensional data like video. "We organize the input tokens into three groups: clean latent tokens of the first observation frame, which serve as the shared visual anchor; noisy latent tokens of future video frames"
- latent world representations: Compact, learned features capturing the environment’s dynamics and structure for downstream action generation. "provides latent world representations for action denoising, avoiding explicit future video denoising and enabling efficient real-time control."
- logit-normal distribution: A probability distribution used here to sample the diffusion time variable t for noise interpolation. "we adopt a logit-normal distribution over as the noise schedule during both training and inference."
- Mixture-of-Transformer (MoT): An architecture combining multiple transformer experts (e.g., video and action) with shared attention to handle different modalities or tasks. "Concretely, we build Fast-WAM with a Mixture-of-Transformer (MoT) architecture with shared attention, consisting of a video DiT and an action expert DiT"
- noise schedule: The schedule governing how noise levels (or time steps) are sampled and applied during diffusion training and inference. "we adopt a logit-normal distribution over as the noise schedule during both training and inference."
- outer auto-regressive loop: A higher-level iterative process where action or prediction chunks are generated sequentially over time, conditioning on previous outputs. "for simplicity, we focus on single action chunk generation and omit the outer auto-regressive loop."
- structured attention mask: A designed masking scheme controlling which token groups can attend to others to regulate information flow. "A structured attention mask controls the information flow between these groups."
- teleoperated demonstrations: Human-operated robot demonstrations collected to provide supervised data for learning policies. "We collect 60 hours of teleoperated demonstrations on the Galaxea R1 Lite platform."
- velocity field: In flow matching, the vector field that guides noisy samples toward data samples across time. "The model is trained to predict the corresponding velocity field with a standard flow matching objective"
- video denoising: The iterative process in diffusion models of transforming noisy video latents into clean future frames. "incurring substantial test-time latency from iterative video denoising"
- video VAE: A variational autoencoder specialized for video that encodes frames into latent tokens and decodes them back. "We also reuse its pretrained text encoder and video VAE"
- Vision-Language-Action (VLA) policies: Models that map visual inputs and language instructions directly to robot actions. "Recent progress in embodied foundation models has been driven by Vision-Language-Action (VLA) policies, which directly map visual observations and language instructions to robot actions"
- World Action Models (WAMs): Models that combine future visual prediction (“world modeling”) with action prediction in a unified framework. "World Action Models (WAMs) have emerged as a promising alternative to Vision-Language-Action (VLA) models for embodied control because they explicitly model how visual observations may evolve under action."
- world modeling: Predicting how the environment (e.g., future visual states) will evolve, used to inform action decisions. "We follow~\cite{ye2026worldactionmodelszeroshot} to refer to these models as World Action Models (WAMs), since they leverage world modeling, i.e., predicting future visual states, to support downstream action prediction."
Collections
Sign up for free to add this paper to one or more collections.