- The paper introduces a unified discrete token framework that jointly optimizes world modeling and policy generation for autonomous driving.
- It employs a Transformer with VQ-VAE tokenization and grid-based soft interpolation to discretize continuous action trajectories efficiently.
- Empirical results on NAVSIM benchmarks demonstrate superior safety, comfort, and trajectory fidelity compared to prior modular or diffusion-model approaches.
Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Unified Discrete World-Policy Modeling
Discrete-WAM introduces a unified discrete vision-action world-policy framework for autonomous driving, integrating visual observations, future states, high-level decisions, and ego actions into a shared discrete token space. The core idea is to align representation and optimization domains across modalities, enabling efficient coupling between world dynamics prediction and hierarchical policy construction. The Transformer-based architecture leverages a VQ-VAE tokenizer for visual abstraction and a grid-based soft interpolation scheme for discretizing continuous action trajectories.
The framework supports three complementary training modes: (1) world modeling (action-conditioned future vision prediction), (2) world-policy modeling (joint prediction over future visual and action tokens), and (3) hierarchical policy modeling (decision-conditioned action generation). By structuring all learning over token-level sequence modeling, both world and policy learning are jointly optimized, bridging the typical disconnect seen in prior modular or loosely coupled approaches.
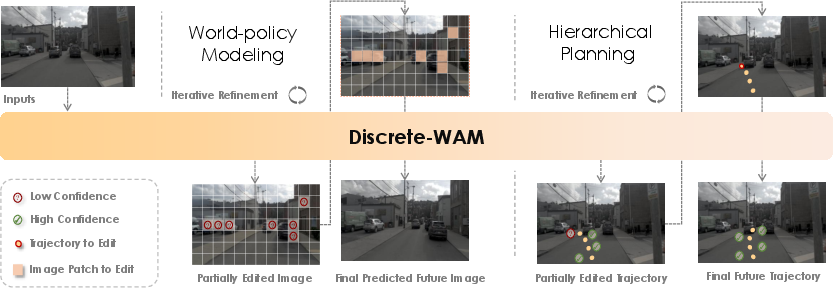
Figure 1: Discrete-WAM enables unified editing and planning via discrete vision/decision/action token spaces with multi-stage pretraining and post-training.
Model Architecture and Tokenization
The architecture comprises four core modules: a VQ tokenizer for projecting camera observations into a compact token space, a context encoder for providing ego-state and navigational context, a decoder-only Transformer (18 layers, 2048 hidden dim), and multi-head prediction modules for visual, action, and sequence token targets. Discretization for actions is designed using a cubic-spline fit to smooth raw continuous trajectories, which are then quantized over a 2D acceleration grid. A novel soft-label interpolation is applied during training, which eliminates deterministic quantization error and grounds action as a weighted distribution over grid prototypes, ensuring exact invertibility for acceleration values within each cell, under model capacity.
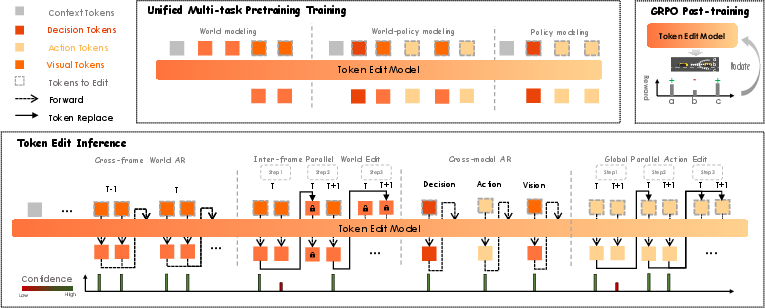
Figure 2: The Transformer-based unified architecture with shared token space for vision, high-level decision, and action prediction.
Unified Multi-Task Pretraining with Token Editing
Unlike classical mask-prediction or denoising autoencoders, Discrete-WAM pretraining formulates the objective as token-level masked editing across vision and action streams. Three attention-masking regimes are designed to precisely control token accessibility for each task:
- World modeling: Visual prediction is conditioned on context and actions, with only visual tokens edited.
- Policy modeling: Decision tokens are first predicted, then the future action block is edited in a bidirectional (blockwise) manner to allow parallel refinement, but with causal masking from context.
- World-policy modeling: Vision and action tokens are interleaved, with dual-path filling and editable blocks isolated from their clean targets, enforcing the desired information flow for joint predictive supervision.
Each editable token supervises both its classification and (for actions) auxiliary regression over reconstructed continuous accelerations and integrated low-level trajectories, minimizing both cross-entropy and regression errors.
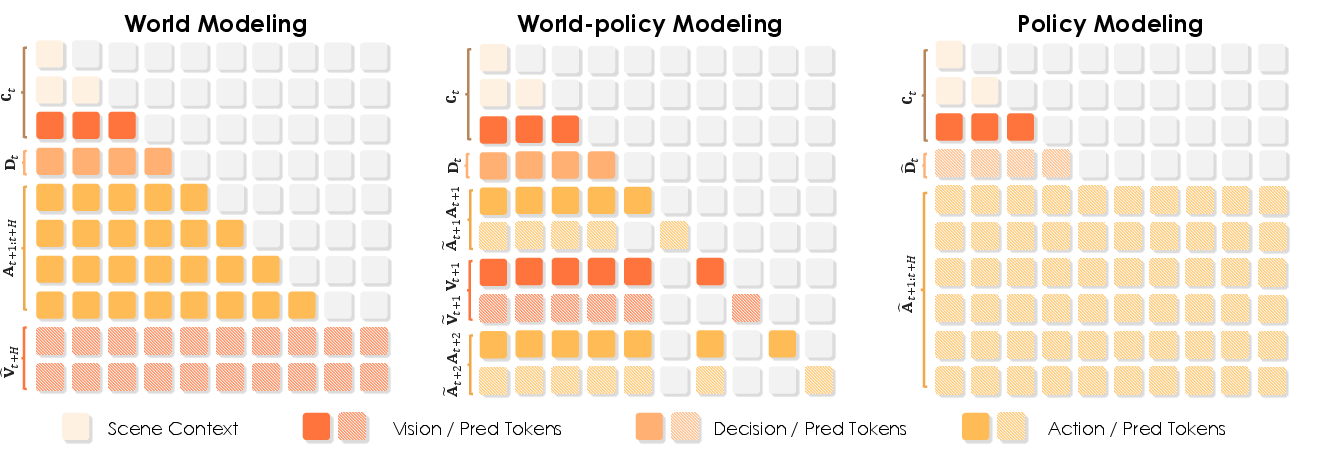
Figure 3: Attention-masking strategies implementing editing and isolation for token blocks in each training regime.
Hierarchical and Parallel Policy Generation
Policy generation is hierarchically structured: a decision skeleton token is predicted as a planning anchor, capturing coarse intent (e.g., maneuver type, speed profile). Conditioned on this, dense action tokens are refined in parallel during post-training through confidence-driven re-edit scheduling, such as only updating tokens exceeding an entropy/confidence threshold. This dramatically increases inference efficiency over autoregressive policies, maintaining trajectory quality while enabling tokens to be concurrently decoded and adjusted.
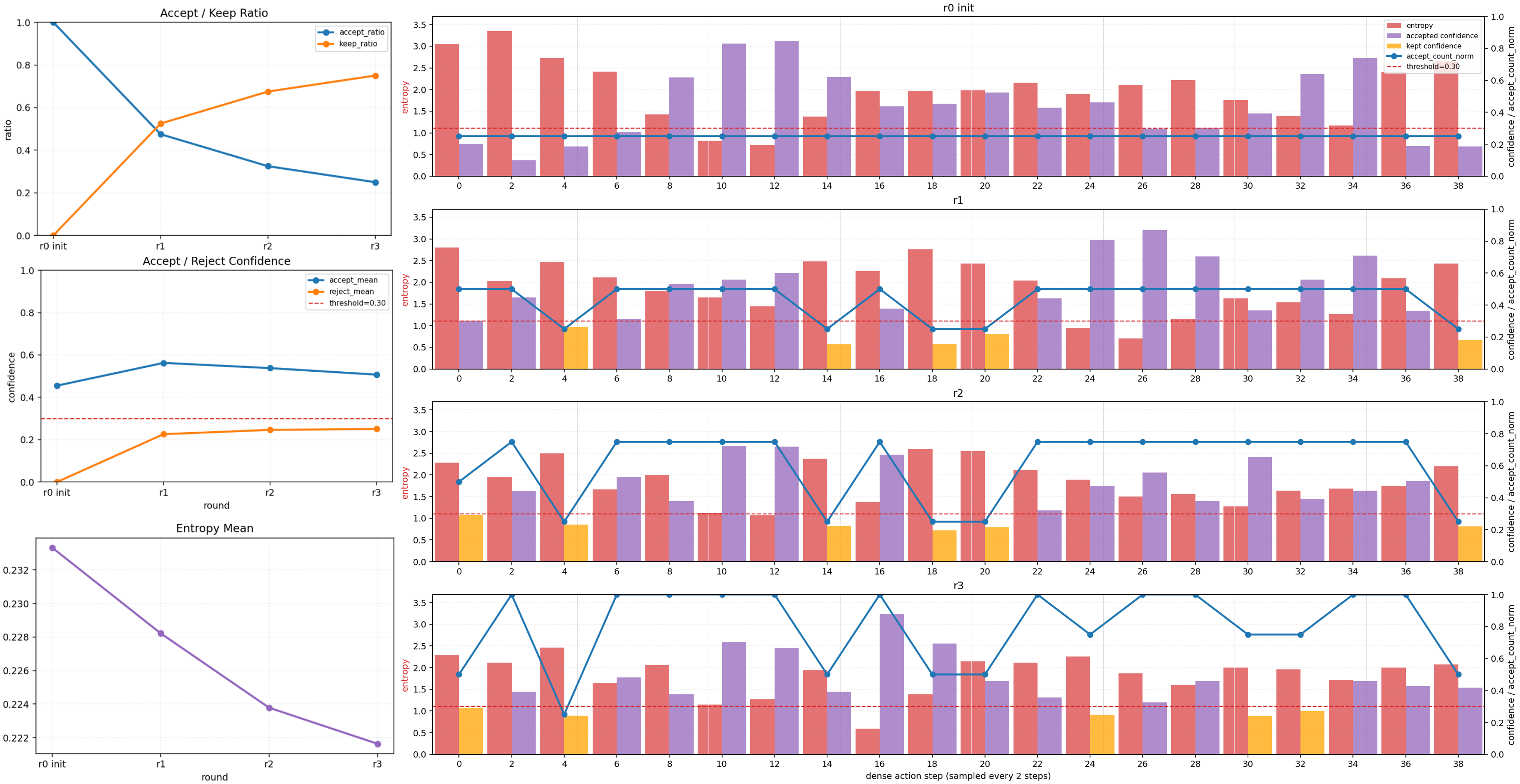
Figure 4: Visualization of multi-round, confidence-based parallel token editing dynamics and entropy reduction.
Theoretical analysis is provided to justify the reduction in residual token dependency and total correlation via upstream skeleton conditioning, bounding sequence-level KL divergence in terms of model errors, edit schedule, and skeleton prediction accuracy.
Empirical Results on Large-Scale Autonomous Driving
On the NAVSIM-v1 and NAVSIM-v2 planning benchmarks, Discrete-WAM outperforms prior world-model, diffusion-model, and cognitive policy baselines across all compositional metrics (EPDMS, NC, DAC, TTC, LK, etc.), achieving 90.4 EPDMS on NAVSIM-v2 and 92.2 PDMS on NAVSIM-v1. Gains are especially pronounced in safety and comfort sub-metrics, and ablation studies demonstrate consistent improvement from unified pretraining, decision-guided structure, and reinforcement learning post-training.
Discrete-WAM also sets state-of-the-art FID (6.6) and FVD (80.0) for short-horizon future generation, indicating superior visual fidelity and consistency in action-conditioned rollouts, even compared to models that specialize in long-range scene synthesis.
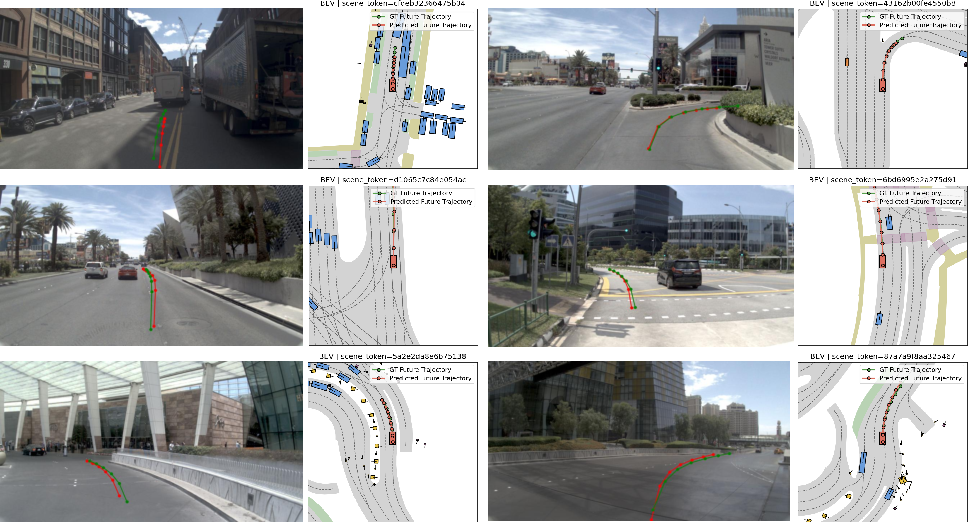
Figure 5: Qualitative planning results: trajectories are geometrically consistent and safety-compliant across nudging, lane changes, and other scenarios.

Figure 6: The learned world-policy model generates temporally coherent future world states under different driving contexts.
Visual Grounding, Causal Analysis, and Attention Diagnostics
Policy attention analysis reveals the model attends predominantly to driving-relevant semantics (lanes, vehicles, signals), with a nontrivial portion focused on stable sky regions—likely serving implicit global anchoring in the absence of explicit register tokens. Upper-region ablation studies confirm that, although upper sky attention provides useful context, lower image regions are essential for detailed and accurate policy realization.

Figure 7: Averaged Transformer policy attention shows focus on both local semantics and stable global (sky) regions.

Figure 8: Vertical-region ablation redistributes policy attention and affects trajectory accuracy, supporting the functional role of context tokens.
Counterfactual world-model evaluation via KL-based “surprise” metrics confirms that the model captures causal action-consequence relationships: surprise scores spike when counterfactual actions produce off-road or collisional futures, tightly correlating with safety-critical trajectory failures.
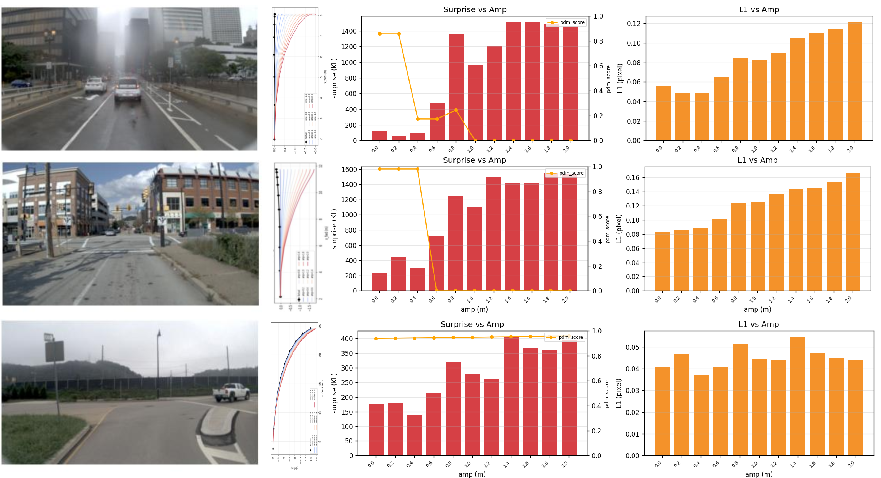
Figure 9: Surprise metrics expose causal understanding by correlating world-model uncertainty with safety and rule violations under counterfactual perturbations.
Practical and Theoretical Implications
Discrete-WAM demonstrates that true alignment between world modeling and autonomous policy generation is attainable when all modalities are represented and optimized within a joint discrete token editing paradigm. This supports data-efficient transfer, enables fast parallel decoding during inference, facilitates explicit uncertainty and causal analysis, and improves both safety-critical and comfort-critical driving behavior.
On the theoretical side, the framework’s hierarchical decomposition is proven to reduce action-token dependency and supports provably efficient decoding schedules that allocate computation adaptively according to model uncertainty—as motivated by recent work on confidence-based masked diffusion.
Moreover, the explicit, interpretable structure in Discrete-WAM provides natural hooks for future generalizations to hierarchical reasoning, closed-loop RL with intrinsic rewards, VLA (vision-language-action) integration for multi-modal tasks, and embedding of large-scale in-house datasets and field tests for scalable deployment.
Conclusion
Discrete-WAM sets a new paradigm in autonomous driving and physical AI by unifying visual, decision, and action streams in a discrete, edit-based latent space, supporting tightly coupled world-policy learning, efficient parallel policy decoding, and structured hierarchical decision making. This architecture establishes robust empirical and theoretical foundations, suggesting that discrete representation alignment and token-centric policy modeling offer substantial strategic advantages for the next generation of world-oriented, controllable, and safety-critical embodied agents.
(2606.05645)