- The paper introduces an event-grounded approach that replaces fixed-length chunks with temporally coherent, executable behavior segments to enhance multimodal alignment.
- It integrates multi-view video and action transformers with cross-view attention and geometric masking to ensure spatial-temporal consistency and physical plausibility.
- Event-centric pretraining yields superior video generation and real-robot performance, demonstrating robust generalization over traditional embodied manipulation methods.
Event-Grounded World Action Modeling with WALL-WM
Motivation: Challenging Granularity Mismatch in Vision-Language-Action Learning
The "WALL-WM: Carving World Action Modeling at the Event Joints" (2606.01955) addresses a core limitation in the design of Vision-Language-Action (VLA) and World Action Models (WAMs): the persistent granularity mismatch between language, video, and action streams in embodied settings. Standard approaches adapt video foundation model priors by predicting actions over fixed-length chunks, conditioned on the current observation and instruction. This paradigm conflates the different semantic and temporal structures of each modality: language encodes event-level goals, vision observes continuous scene evolution, and actions operate on fine-grained control horizons sensitive to contact and state transitions.
This mismatch results in brittle semantic alignment and diminished long-horizon generalization, with shared representations regressing to short-horizon correlation fitting that can overwrite valuable pretrained priors. Consequently, the core question is reframed not as one of simple multimodal fusion, but as geometry-preserving and temporally-grounded alignment: where, and how, should one define the atomic unit of learning to bridge vision, language, and action in a compositional and executable manner.
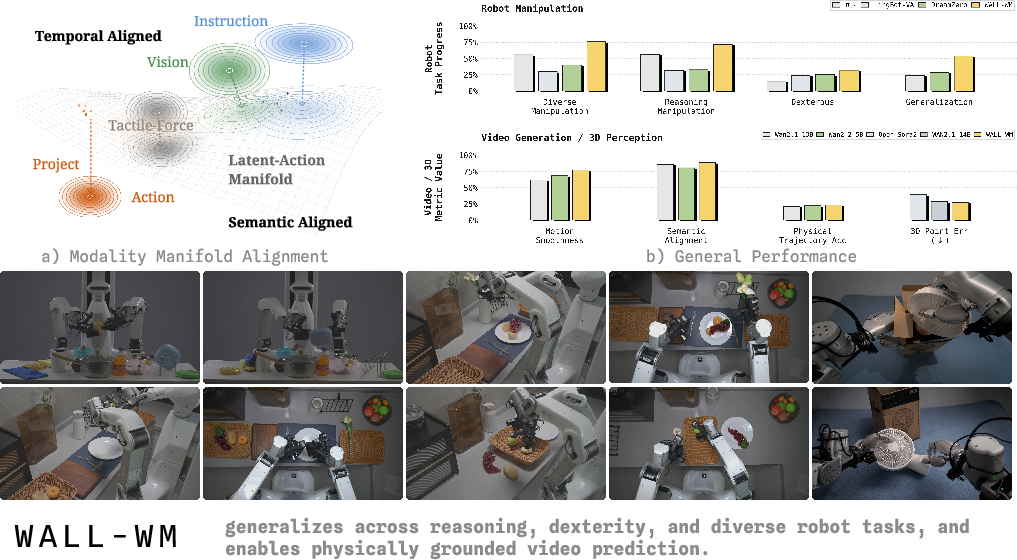
Figure 1: WALL-WM conceptualizes the modality hierarchy—text provides semantic alignment, vision grounds spatiotemporal context, and action demands fine contact-sensitivity. Event-grounded pretraining robustly improves manipulation and video generation metrics.
Event-Centric Modeling: Architecture and Training Protocol
WALL-WM replaces the conventional fixed-length chunk with the action-grounded semantic event: a temporally coherent and executable behavioral segment that is describable in language, observable in video, and realized through action. Instead of carving learning windows by arbitrary clocks, event boundaries are synchronized to transitions in underlying behavior, aligning all modalities on segments with clear semantic, visual, and physical support.
The architecture integrates an inherited Wan video DiT backbone augmented for multi-view, multi-embodiment video generation and a randomly initialized action DiT. Layer-wise coupling enables the action tower to access per-layer visual features, promoting direct conditioning on spatial-temporal video evidence without perturbing the pretrained visual prior. Pretraining is organized around event-aligned triplets: video, action, and caption for each semantic interval. The denoising objectives for both video and action streams employ flow matching, with event-centric segmentation ensuring clean temporal support.
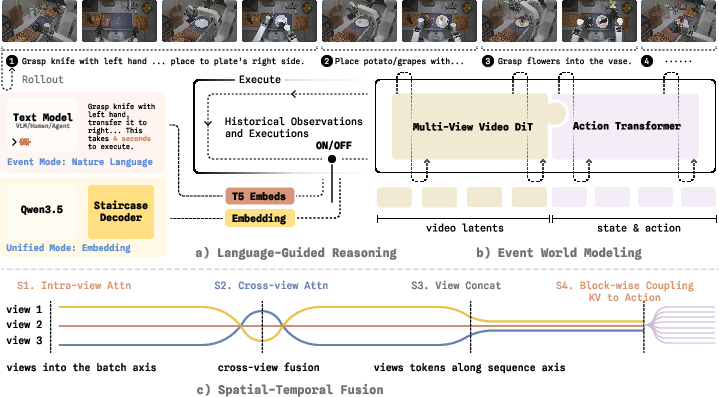
Figure 2: The WALL-WM framework—an event-centric denoiser with multi-view video DiT and action transformer, leveraging event captions and observations to jointly model future trajectories.
A critical aspect is the cross-view attention and geometric masking which, at training time, enforce information flow exclusively across physically co-visible regions (using sight-cone and tube masking). These strategies eliminate attention across semantically irrelevant geometry and force the action module to leverage robust multi-view correspondences.
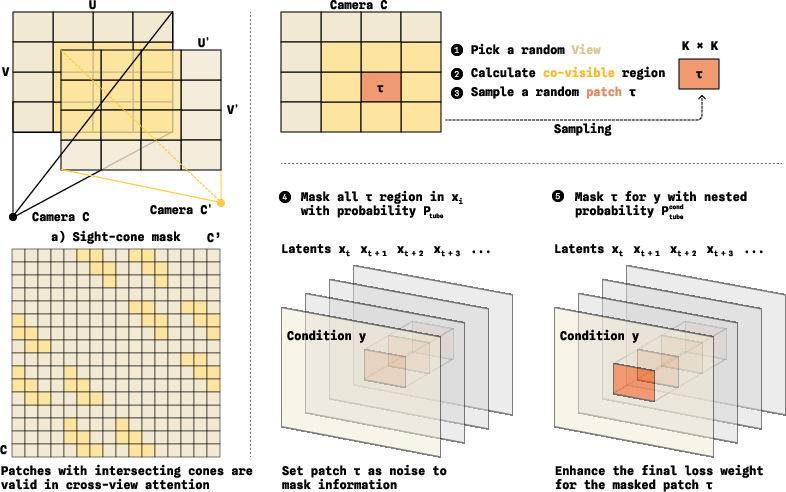
Figure 3: Cross-view masking mechanism: sight-cone ensures only geometrically plausible token interactions, tube masking enforces information recovery strictly through cross-view dependencies.
A staircase latent chain-of-thought (CoT) decoder accelerates high-level reasoning. It parallelizes the generation of continuous latent reasoning tokens, reducing inference latency relative to standard autoregressive CoT mechanisms, while maintaining differentiability and semantic abstraction throughout the reasoning process.
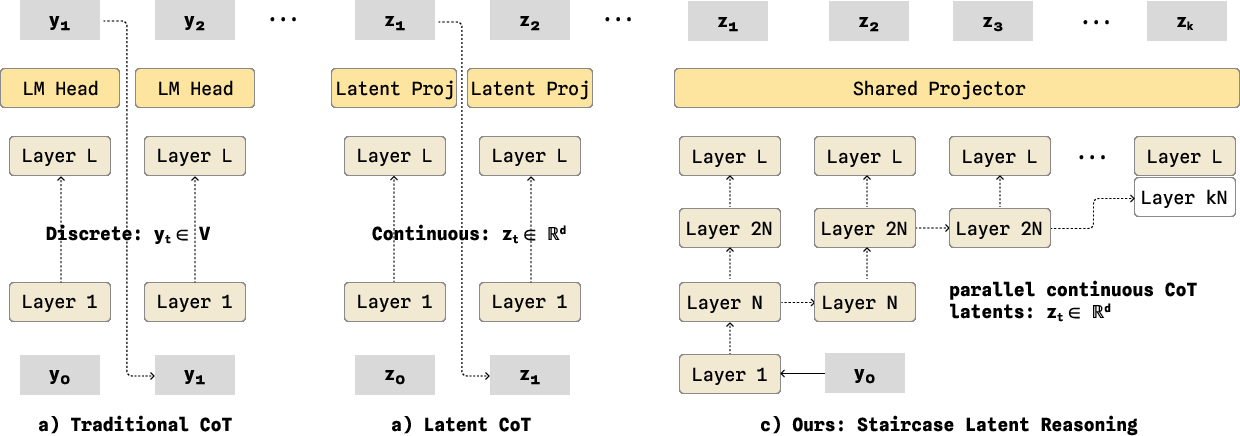
Figure 4: Comparison of CoT schedules—traditional autoregression, latent CoT, and WALL-WM’s efficient staircase latent rollout with depth-parallelization.
Event-Aligned Data and Cluster-Balanced Sampling
The data ecosystem comprises internet-scale video, egocentric and robot teleoperation streams, and robot-free UMI (universal manipulation interface) recordings, each temporally synchronized and annotated with multi-level captions (Task, Subtask, Action, Segment). Temporal synchronization is ensured at the episode level through motion-based alignment, enhancing sample fidelity for contact-sensitive domains.
A unique aspect is cluster-balanced sampling, which mitigates the intrinsic long-tailed distribution of embodied demonstration datasets. Vision-language and action clustering on event-aligned windows enables targeted sampling of rare but critical behaviors, ensuring comprehensive representation of both nominal and correctional action trajectories during training.

Figure 5: Sample episode annotated with hierarchical caption tracks—Task, Subtask, Action, and Segment—supporting event-aligned modeling.
Infrastructure and Deployment
Efficient training and deployment are achieved via the Muon optimizer with custom distributed scheduling and fused operation kernels, reducing optimizer and communication overheads. Multi-event sequence packing and fine-grained attention parallelism further increase GPU utilization. To address inference costs of diffusion-based world models, the framework applies distribution-matching distillation (DMD) to compress denoising steps and FP8 quantization with per-block scaling to reduce memory and compute footprints. This stack delivers real-time performance at 10Hz for deployed robotic control.
Experimental Results
Embodied Video Generation
On challenging embodied video prediction tasks, WALL-WM exhibits enhanced performance relative to Wan-series baselines. While preserving competitive visual quality, WALL-WM delivers stronger scores on embodied-relevant metrics, including motion quality, semantic consistency, and, critically, physical plausibility—demonstrating event-centric pretraining’s role in bridging the gap from perceptual priors to executable physical prediction.

Figure 6: Qualitative video generation—WALL-WM (left) aligns with physical law while baselines exhibit contact failures and object hallucinations.
Multi-view consistency and 3D-awareness benchmarks confirm the preservation of spatial structure—a necessity for robust, view-consistent manipulation skills.

Figure 7: Tri-view PCA analysis: intermediate features achieve near-perfect cross-view semantic alignment regardless of minimal pixel overlap.
Real-Robot Evaluation
Four real-robot suites target distinct capacity axes: diverse manipulation, instruction-grounded reasoning, dexterous manipulation, and generalization. Evaluated via dense Task Progress, event-mode WALL-WM outperforms both unified-mode (without event pretraining) and strong baselines (DreamZero, LingBot-VA, π0.5 (Intelligence et al., 22 Apr 2025)). Gains are pronounced in instruction-conditioned reasoning, scene generalization, and tasks demanding robust partial execution under variable context.
(Figures 13–16)
Figure 8: Diverse Manipulation—WALL-WM achieves leading Task Progress across grasping, placing, pouring, and spatial relocation tasks.
Figure 9: Reasoning Manipulation—event-mode yields substantial gains in category and sequence grounding.
Figure 10: Dexterous Manipulation—WALL-WM maintains a competitive edge in fine contact tasks.
Figure 11: Generalization—robust instruction-conditioned transfer in cluttered, multi-object scenes.
Ablation studies show that event-centric alignment and cross-view interaction are essential for robust reasoning and instructional grounding; pretrained backbones alone are insufficient for high Task Progress under complex conditions.
Theoretical and Practical Implications
The event-centric, geometry-preserving modeling strategy reconceptualizes the alignment unit of embodied foundation models. The approach directly addresses the collapse of compositional structure seen in chunk-centric protocols and yields empirically stronger and more generalizable policies. Practically, the demonstrated deployment at closed-loop speeds verifies that large-scale, event-grounded WAMs can be scaled and compressed for real-world robotics without loss of embodied competence.
Theoretically, this event-centric learning protocol may serve as a substrate for the next generation of agentic control systems, where VLMs conduct high-level reasoning and task decomposition, with WAMs executing grounded plans over variable-length, executable events. The modular and scalable infrastructure design elucidates a path for further scaling—including self-supervised event discovery, tighter integration with agentic reasoning, and robust hierarchical transfer across embodiments.
Conclusion
WALL-WM (2606.01955) advances the paradigm of event-grounded World Action Modeling, replacing clocked chunk-centric training with semantically and physically aligned event segmentation, supported by balanced sampling over diverse instructional, visual, and action spaces. The resultant architecture generalizes across tasks, scenes, instructions, and embodiment, and establishes a reproducible methodology and implementation stack for the next phase of scalable embodied foundation models. The implications span both improved sample efficiency for physical robot policies and the theoretical foundation for modular, compositional, agentic architectures in vision-language-action domains.