- The paper introduces a tactile-based framework that leverages distributed sensors and explicit force regulation to improve humanoid manipulation success rates.
- It employs a force-conditioned target-pose correction network and a transformer-based planner for accurate prediction of pose and contact force trajectories.
- Empirical evaluations on five tasks show significant improvements in task success, contact stability, and motion smoothness.
Tactile-Driven Whole-Body Humanoid Manipulation with WT-UMI
Introduction and Context
WT-UMI ("Tactile-based Whole-Body Manipulation via Force-Supervised Contact-Aware Planning") addresses the persistent challenge of bridging the gap between human and humanoid robot whole-body manipulation in contact-rich environments (2606.13232). Robust manipulation of deformable, bulky, or collaboratively carried objects requires distributed contact sensing and explicit force regulation across the robot's body—a capability largely neglected in prior imitation learning, which typically relies on visual and proprioceptive inputs or restricts tactile sensing to the fingertips. WT-UMI proposes a unified tactile hardware and learning framework, equipping both human operators and robots with dense whole-body tactile sensors, and introducing a force-aware planning pipeline to explicitly model and regulate contact forces during manipulation.
Figure 1: WT-UMI provides a hardware and data interface for cross-embodiment whole-body tactile data collection and execution of manipulation tasks under force supervision.
WT-UMI comprises modular tactile sensors instrumenting the palms (GripTac end-effectors), forearms, and chest, employing thin-film piezoresistive arrays to record dense 2D tactile images and calibrated contact forces.
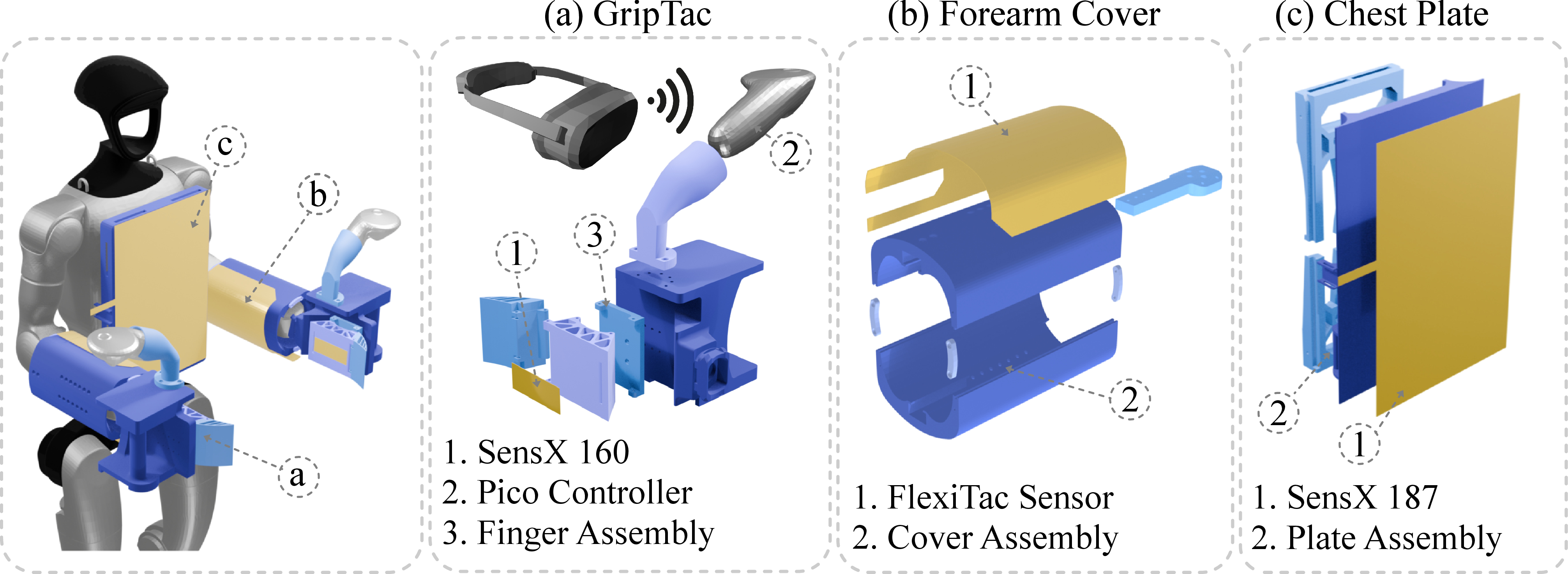
Figure 2: WT-UMI consists of hand-held GripTac instruments, forearm covers, and a chest plate, each equipped with high-resolution tactile sensors.
The platform supports (i) human demonstration—where a human operator collects natural contact-rich demonstrations by wearing the sensorized interfaces—and (ii) teleoperation—where the same hardware is used for whole-body humanoid robot control via VR. This hardware symmetry minimizes the human–robot embodiment gap in tactile perception and action space, a notable limitation in prior approaches.
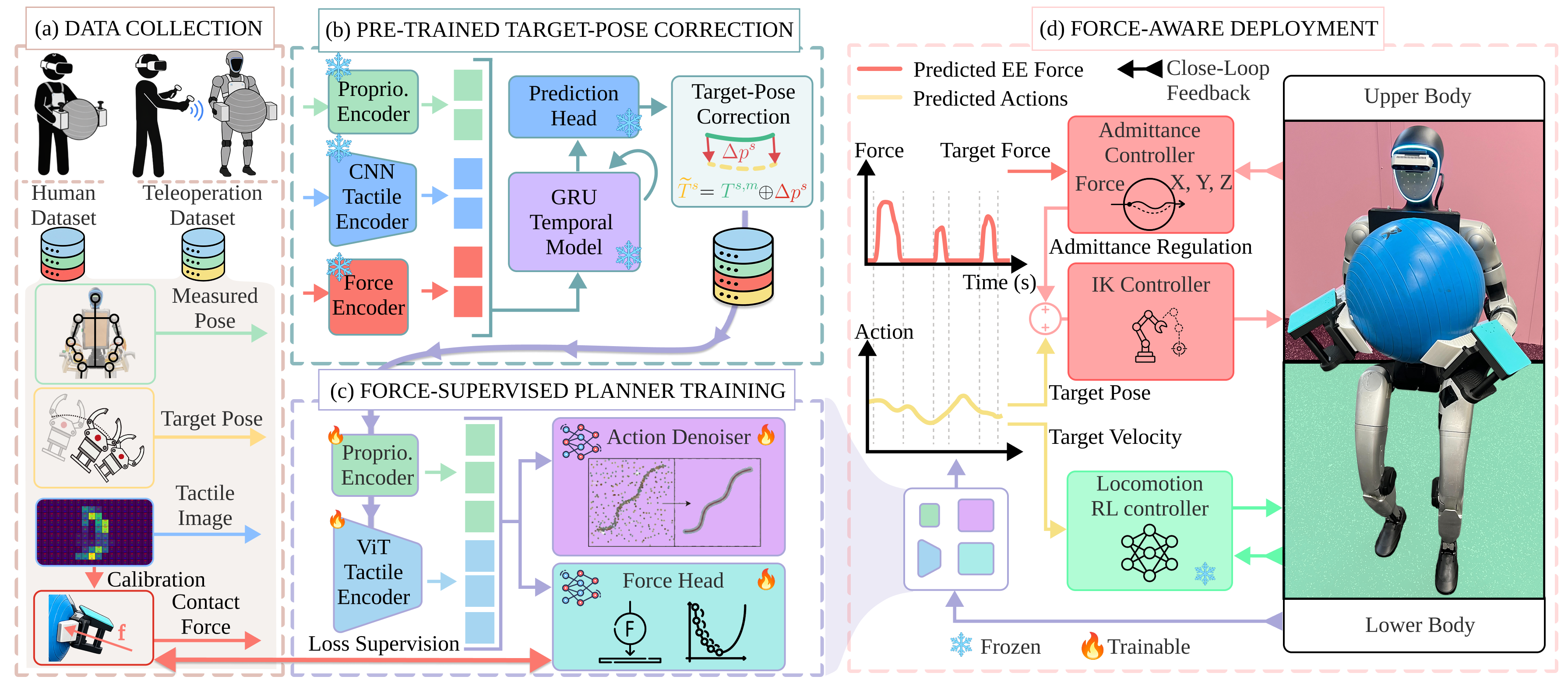
Figure 3: System architecture: A force-conditioned target-pose correction module generates robot-executable action labels from human data, which then supervise a planner that predicts both pose and force trajectories.
Learning and Control Pipeline
Force-Conditioned Target-Pose Correction
Human demonstrations carry natural contact interactions but lack robot-executable labels due to embodiment and action space mismatch. WT-UMI deploys a force-conditioned correction network: contact-mode-aligned demonstration segments from human and teleoperation are paired, and a lightweight CNN-GRU predicts translation offsets for human-hand poses, gated by tactile and contact information, to align them with feasible robot targets.
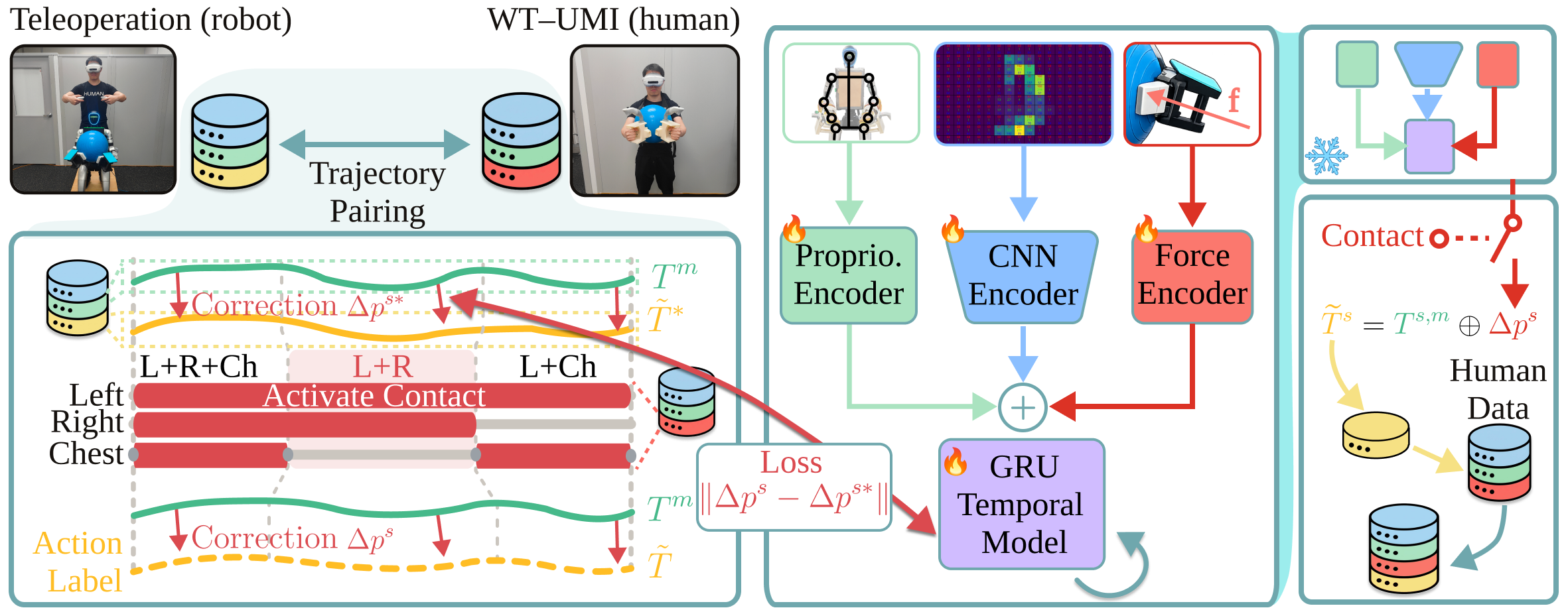
Figure 4: Training pipeline for target-pose correction, leveraging contact-mode alignment between teleoperation and human demonstrations to supervise pose translation offsets.
This mechanism leverages only a small amount of paired robot teleoperation for training, scaling up the available action-labeled dataset efficiently.
Force-Supervised Planning
A transformer-based denoising planner ingests sequences of tactile images and end-effector poses, predicting both a future end-effector pose sequence and a contact-force trajectory using a cross-attention force head. The predicted force trajectory conditions a tactile-based admittance controller, closing the loop between high-level force planning and low-level compliance.
Evaluation on Whole-Body Manipulation Tasks
WT-UMI was validated across five challenging whole-body manipulation tasks, including deformable object reorientation (i.e., yoga ball, pillow), large object handling (bucket), and human–humanoid collaborative transport (beam, table). Quantitative metrics include task success rate, contact-centroid drift, mean contact force, and motion smoothness (acceleration measures).

Figure 5: WT-UMI-enabled policy deployments on three representative whole-body manipulation tasks: soft object, large rigid object, and object transport.
Strong empirical results include a 20% absolute improvement in success rate (from 60% to 80% on 'bucket' tasks) and consistent reductions in contact centroid drift and pose accelerations when augmenting robot teleoperation data with pose-corrected human demonstrations. The combined data regime yields increased mean contact force—demonstrating the system’s ability to better achieve and regulate stable contact. Across all tasks, activation of the tactile-based admittance controller further reduces both translational and rotational accelerations while increasing centeredness and firmness of contact, with an average decrease of 10.9% in contact drift and a 2.7% force increase.
WT-UMI's force head, when trained on human demonstration data, achieves a force prediction RMSE of 1.05 N (compared to 5.56 N force RMS) and a more than two-fold reduction in lag and force rate changes compared to teleoperation data alone, reflecting superior tactile data quality from natural human interactions.
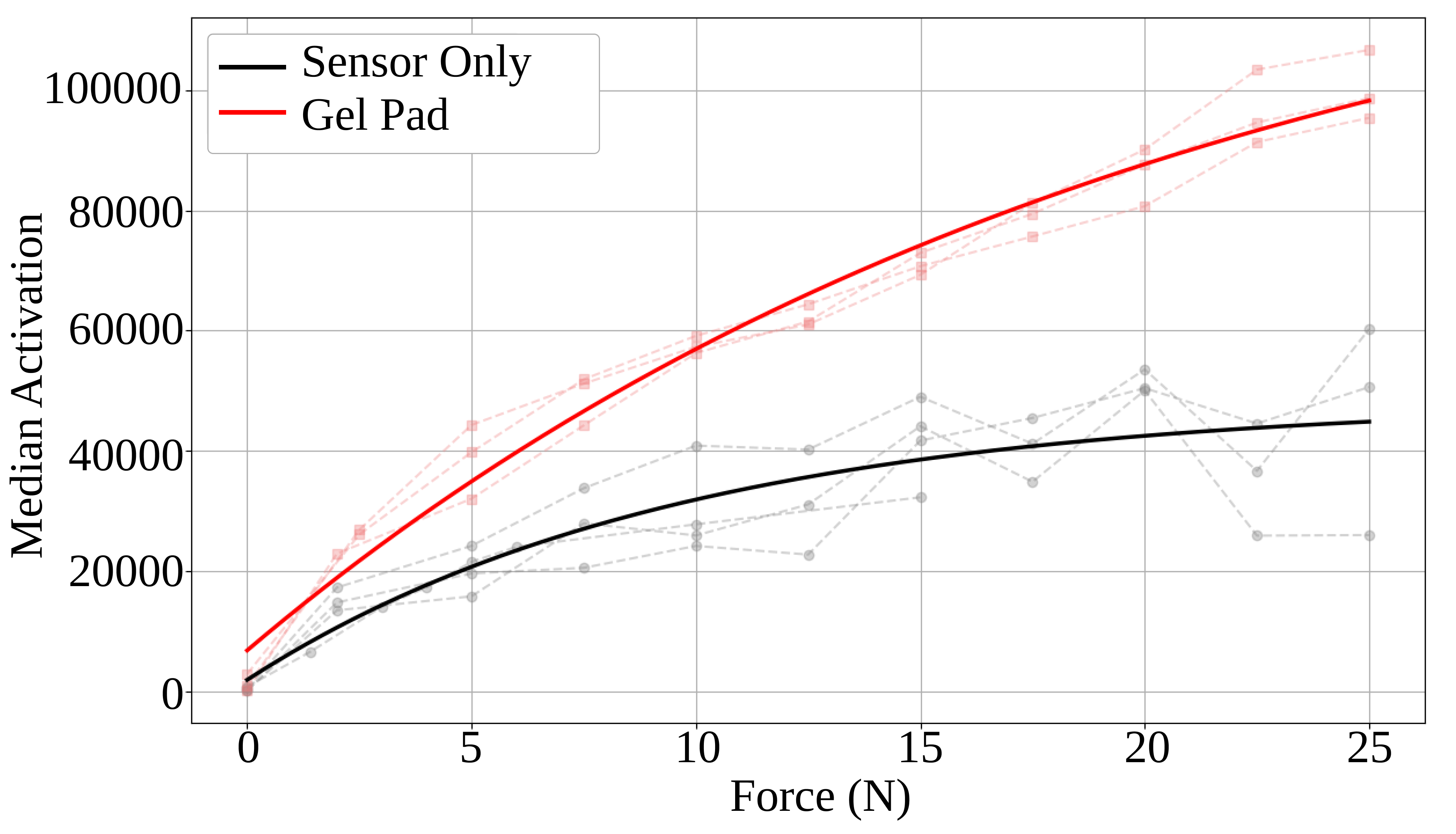
Figure 6: Calibration of palm tactile sensor responses, with gel padding used to linearize force readouts and expand usable range.
Human-Humanoid Collaborative Manipulation
WT-UMI also uniquely supports physical human–humanoid cooperation in shared-load transport (e.g., beams, tables). Tactile feedback allows real-time inference and co-adaptation to a human partner's intent during collaborative manipulation—an area where vision and end-effector force sensors alone are typically insufficient.
Figure 7: Human–humanoid collaborative tasks; WT-UMI supports data collection and policy deployment for beam and table transport involving physical intent inference and synchronized whole-body contact.
Architectural and Theoretical Considerations
The WT-UMI pipeline introduces several notable architectural innovations for the field:
- Hardware-Software Loop Closure: Tactile coverage at the body scale, not just the hand or wrist, drives the entire data-to-control cycle, from demonstration through low-level adherent force regulation.
- Separation of Data Acquisition, Correction, and Planning: Explicit pose correction based on force and contact gating efficiently overcomes human–robot matching barriers, enabling scalable data aggregation.
- Learning Explicit Force Trajectories: Direct regression of contact force via cross-attention in transformer architectures avoids the ambiguities of implicit force modeling.
These design choices collectively enable direct, contact-and-force-aware behavior cloning, moving beyond the limitations of kinesthetic learning-in-the-loop (UMI-style) approaches or VR teleoperation pipelines that lack distributed tactile context.
Implications and Future Directions
Practically, this framework facilitates robust policy learning and deployment for a continuum of contact-rich, multi-region manipulation tasks relevant to both autonomous service robots and human–robot teams in manufacturing, logistics, or assistive contexts. The architecture is agnostic to policy backbone (ViT-FMT, ViT-DiT, foundation models like π0.5/Ψ0), supporting integration with strong vision-language-action models and facilitating comparative policy optimization.
Theoretically, WT-UMI demonstrates that dense, body-scale tactile feedback, paired with explicit force trajectory prediction, is essential to whole-body manipulation generalization. Future advances likely include:
- Extension to denser sensor arrays covering additional body regions (dextrous hands, legs, back), unlocking richer affordances.
- Multi-axis force/wrench prediction, replacing uniaxial normal force, to enable compliant regulation in arbitrary contact configurations.
- Unified processing of vision and tactile signals for anticipatory contact planning and recognition beyond occlusions—a necessary step for generalized embodied AI foundation models [diffusion_policy, open_x_embodiment_rt_x_2023].
- Transfer to other morphology classes (e.g., quadrupeds, mobile manipulators) and direct integration with world modeling and simulation pipelines for policy validation and zero-shot deployment [hansen2024worldmodelsvisual, wu2022daydreamer].
Conclusion
WT-UMI establishes a robust paradigm for force-aware, whole-body, contact-rich humanoid manipulation by unifying wearably collected human demonstrations with robot teleoperation and explicit contact-force planning. The architecture achieves strong performance gains over position-only or vision-dominant baselines and highlights the pivotal role of tactile sensing and force-supervised learning in next-generation humanoid manipulation—diversifying the avenues for safe, skillful, and collaborative robot deployment across real-world domains.
(2606.13232)