- The paper introduces RealDexUMI, a wearable interface that maps human finger motions directly to a robotic hand, eliminating retargeting errors.
- It synchronizes multi-modal data—tactile, vision, hand state, and glove commands—to capture deployable action–state correspondence during complex tasks.
- Experimental results demonstrate high success rates and robust cross-embodiment policy transfer, outperforming state-only supervision methods.
RealDexUMI: A Wearable Universal Manipulation Interface for Dexterous Robot Learning
Motivation and Problem Statement
Dexterous manipulation with robots poses significant challenges due to the gap between human-performed demonstrations and executable robot actions. Most demonstration interfaces either require extensive retargeting—introducing errors in critical hand/object contact and observation alignment—or rely on robot-specific teleoperation hardware, impeding scalability and cross-embodiment policy transfer. Crucially, data collection pipelines often fail to guarantee that the captured dexterity remains deployable in an end-to-end sense, i.e., with strict preservation of hand actions, contacts, tactile signals, and end-effector observations between collection and deployment.
System Architecture and Methodology
RealDexUMI addresses the deployable dexterity gap by design. The central insight is to leverage a shared dexterous end-effector module as both the wearable demonstration interface and the robot’s deployed hand. This module comprises a lightweight, servo-actuated multi-DoF hand, integrated fingertip tactile sensing, and an in-hand camera. A palm-side isomorphic teleoperation glove enables real-time, retargeting-free mapping of operator finger motions directly into the hand’s command space, eschewing kinematic retargeting entirely.
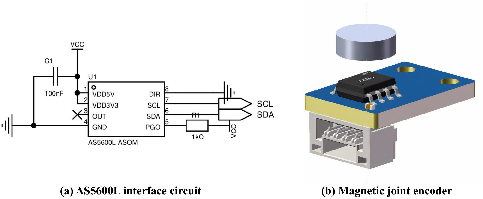
Figure 2: Single-joint magnetic encoder in the glove: (a) interface circuit using AS5600L communicating over I2C, (b) diametric magnet physically aligned with the joint rotation axis for absolute angular measurement.
This hardware configuration ensures that all data streams—RGB vision, tactile arrays, hand state, and hand command—are generated by the same physical hand that will execute policies at deployment. Absolute magnetic encoders within the glove, as shown in (Figure 1), capture joint commands with high fidelity, supporting drift-free, high-frequency, multi-axis measurement.
Action-State Correspondence and Data Collection
A core challenge in dexterous robot learning lies in consistent action–state correspondence, especially under contact constraints. RealDexUMI uniquely records not just the measured hand state (as realized after interacting with objects), but also the actual glove command issued at each timestep, capturing the operator’s intended corrective actions—even when underactuated due to contact. This enables policies to learn robust, contact-aware corrections, rather than relying on state-only supervision which cannot disambiguate between intended and achieved motion under environmental interaction.
Collected episodes contain time-aligned streams: in-hand RGB, 5×10×4 tactile arrays, 6-D hand joint state, glove command vector, and 6-DoF tracker pose. These are synchronized using a latest-sample protocol anchored on RGB timestamps. Over 100 hours of demonstrations across eight complex tasks—including long-horizon, contact-rich, and bimanual scenarios—were gathered.
Learning and Policy Architecture
Policy learning is performed in the end-effector reference frame using a chunked prediction interface. For each observation, the policy predicts a temporally coherent sequence comprising local (hand-frame) relative translation, rotation, and the subsequent executable glove command. This representation is invariant to the robot body and does not require global pose or workspace alignment, simplifying cross-embodiment and cross-setup generalization.
The network backbone is predominantly ACT with ResNet-18 vision encoder, and policies are trained from 200 demonstrations per task. A parallel evaluation using Diffusion Policy confirms the generality of the RealDexUMI interface with respect to policy backend.
Experimental Results
Empirical evaluation on a real-world Franka FR3 equipped with the RealDexUMI hand demonstrates an overall average full-task success rate of 88.75% on eight diverse manipulation benchmarks. These include cube pick-and-place, plug insertion, precision tool use, long-horizon drawer opening/closing, and bimanual coordination.
Initial-pose robustness experiments show zero failures under significant robot pose variation, substantiating the claim that the hand-frame action parameterization yields intrinsic robustness to deployment configuration.
Ablation Analysis
Removing tactile feedback reduces average performance to 70.00%, with largest impact on tasks where contact sensing is nontrivial for vision alone. Substituting state-only action supervision further degrades success to 51.25%, highlighting the necessity of paired (command, state) action annotations for contact-aware skill acquisition.
Cross-Embodiment Policy Transfer
A key result is cross-embodiment deployment: the same dexterous policy checkpoint is directly deployable on three distinct robot arms (Franka FR3, RealMan RM65, and PND Adam-U), achieving consistently high success without retraining. Only the base robot’s IK and low-level controller are swapped, leveraging the decoupled, hand-centric action interface.
Operator Usability and Teleoperation Complexity
Control efficiency during demonstration collection was benchmarked against AVP-based arm–hand teleoperation and motion-capture glove retargeting methods. RealDexUMI exhibited the highest success and lowest completion times, especially in tasks sensitive to contact precision (e.g., tweezer-based tea picking). This advantage stems from direct, command-space teleoperation—rather than high-DOF but non-isomorphic human-to-robot mappings prone to loss of tactile and action alignment.
Figure 4: Survey instrument used in perceived teleoperation complexity evaluation; interfaces are rated by ease of setup, wearing, and operation.
Perceived teleoperation complexity, as formally surveyed in (Figure 3), was rated as 'Low' for RealDexUMI, reinforcing its usability and scalability for broad data collection.
Practical and Theoretical Implications
The RealDexUMI system establishes a precedent for zero-gap dexterous data collection, facilitating deployable dexterous skill learning without the retargeting or post-processing barriers typical in existing approaches. The system robustly addresses the practical necessity of matching data collection and deployment interfaces at the physical and informational level—tactile, observable, and actionable—thus maximizing data utility for imitation learning frameworks.
From a theoretical standpoint, the action–state-coupled data paradigm, realized via the isomorphic glove, could generalize to other domains where tight environment–controller feedback under constraints is essential, potentially impacting haptics, shared autonomy, and nonprehensile interaction policies.
Limitations and Future Directions
The current system prioritizes end-effector alignment; as such, global or egocentric sensing for high-level planning, search, or progress estimation is constrained. Extending the interface to higher-DoF hands, or integrating additional global sensing in a manner consistent with collection–deployment alignment, is an open challenge. Furthermore, while tactile and vision streams are tightly coupled, certain long-horizon, cognitive task elements remain underexplored in this actuation-rich, observation-local regime.
Conclusion
RealDexUMI demonstrates a scalable, practical, and technically rigorous approach for deployable dexterous data collection and policy transfer. By unifying the collection and deployment end-effector modules—and instrumenting the command interface—the system enables robust, intuitive demonstration, preserves critical hand–object contact modalities, and supports cross-embodiment generalization in robot learning pipelines. The methodology is expected to inform future work on universal, robot-agnostic dexterous manipulation interfaces, and may catalyze advances in scalable robot learning from human demonstrations.