- The paper demonstrates that AI-detection warnings alter writer behavior, leading to a statistically significant bias in human judges favoring warned texts.
- It employs a controlled two-phase experiment comparing chatbot engagement and stylometric features between treatment and control groups.
- The study highlights the gap between feature-based AI detection and human intuition, emphasizing limitations in current detection methodologies.
Human Detection of AI-Assisted Writing Under Scrutiny: Experimental Evidence and Stylometric Limits
Experimental Setup and Methodological Design
The study systematically investigates whether the presence of an AI-detection warning alters behavioral patterns of AI-assisted writers, and if humans can detect the difference in resulting texts. The research employs a two-phase between-subjects experiment involving 21 participants, split equally between a control (no warning) and a treatment group (warned of AI-detection), tasked to compose paired opinion pieces on remote work. Interaction and writing sessions leverage the Claude chatbot via a custom Streamlit app architecture, with explicit counterbalancing and deterministic condition assignment to mitigate ordering and assignment biases.
The treatment’s design is notable: it provides a conceptual prime regarding AI-detection, avoiding prescriptive behavioral instructions or consequence-laden framing. This mirrors realistic institutional warnings but maintains ambiguity about AI-detection criteria, encouraging naturalistic responses without inducing direct “gaming” of the detection system. Demand characteristics and baseline observer effects are addressed via survey structure, cover stories, and post-experiment hypothesis probes.

Figure 1: The treatment group briefing includes a yellow-tinted warning label for AI detection; control group receives no such label.
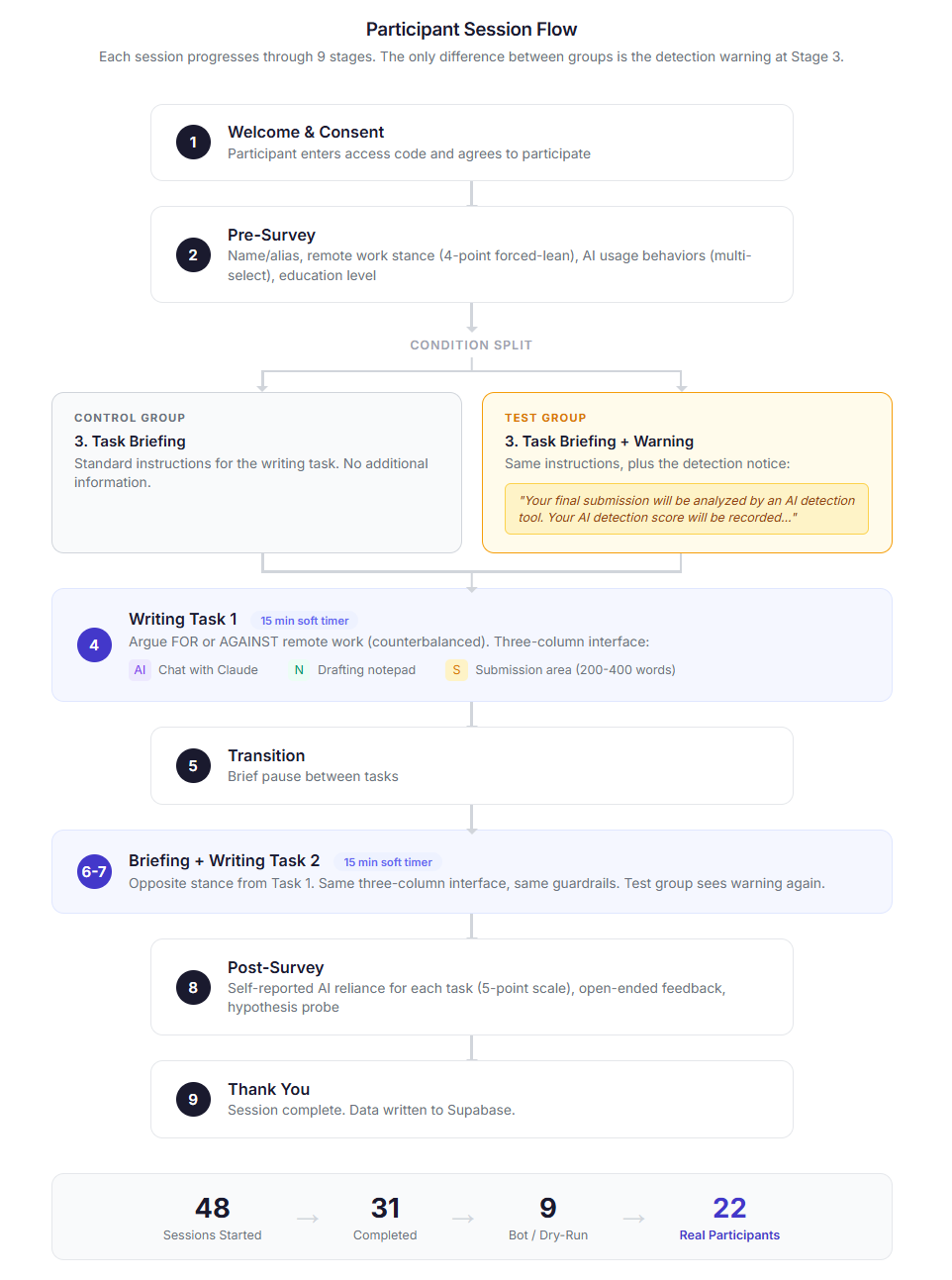
Figure 2: Participant session flow, depicting nine stages; only Stage 3 differs by inclusion of the detection warning in the treatment group.
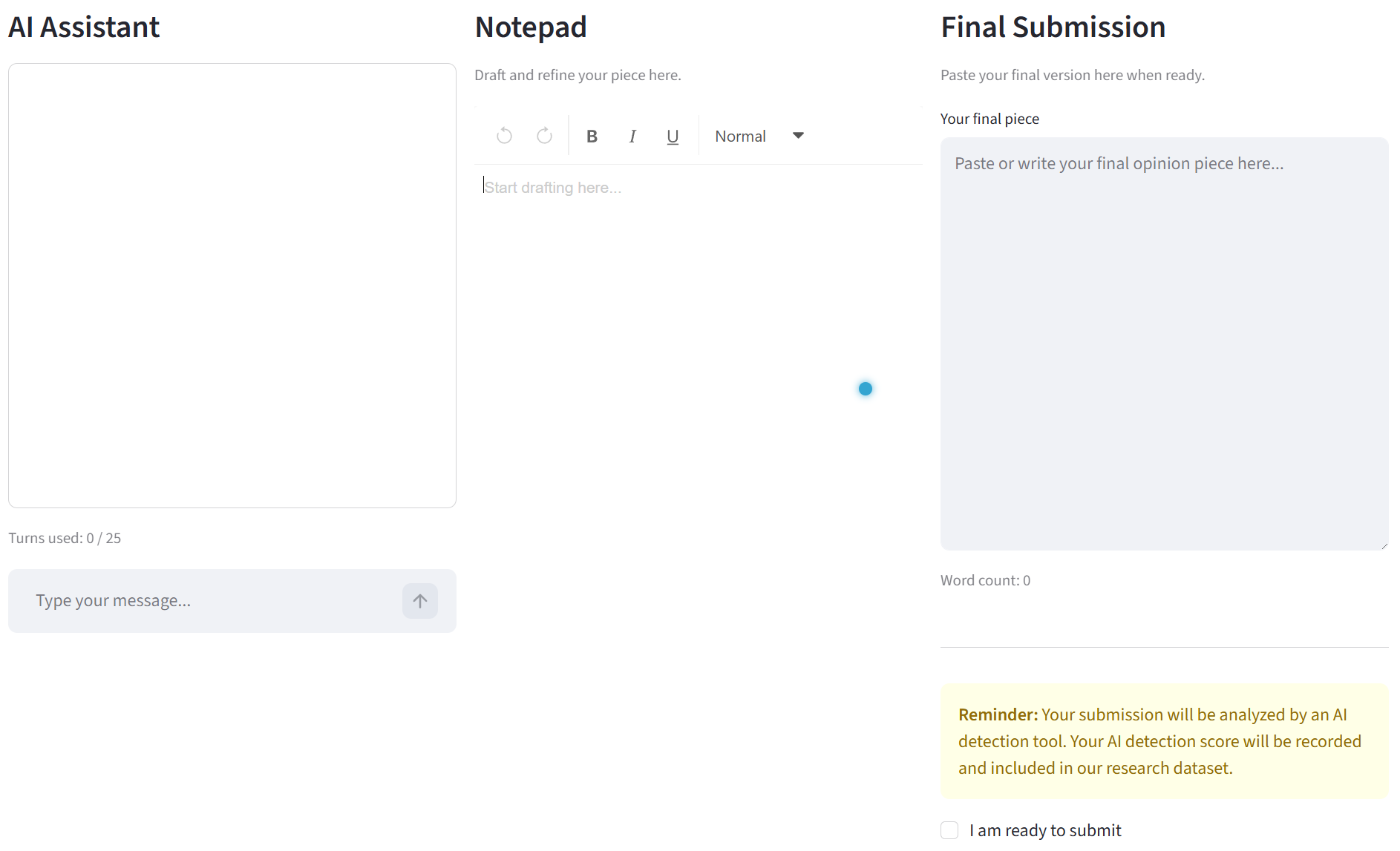
Figure 3: Both groups interact with a three-panel interface—AI chatbot, notepad, and submission screen—only the treatment group has the AI detection label.
Phase 1: Writer Behavioral Metrics and Stylometric Analysis
Writers in the treatment group exhibit increased engagement with the AI chatbot, taking more turns, spending longer per task, and consuming more tokens. Qualitatively, treatment participants range from abandoning the chatbot entirely to iterating extensively, but quantitative analysis demonstrates nearly identical AI textual overlap scores between groups. The AI overlap score, a composite of phrase-matching, longest substring, and total overlap across available chatbot outputs, yields median scores of 0.978 (control) and 0.953 (treatment), highlighting heavy AI usage in both cohorts.
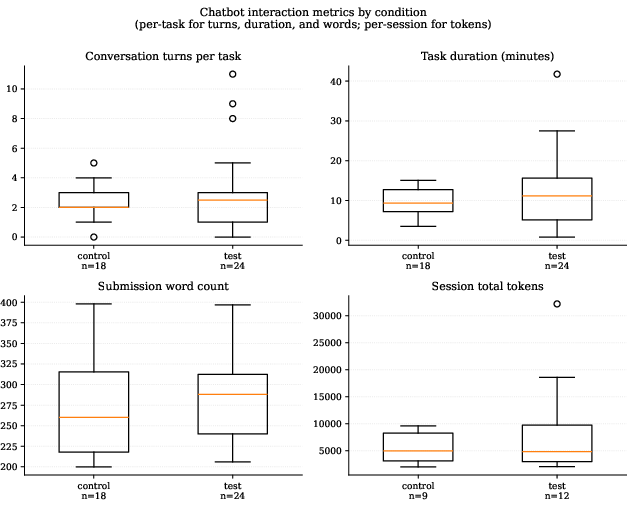
Figure 4: Chatbot interaction metrics by condition reveal treatment group more intensively utilized chatbot (turns, duration, tokens).
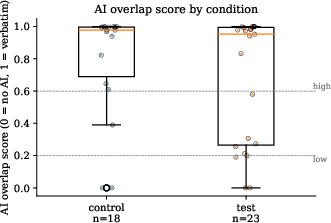
Figure 5: AI overlap scores by condition; test group writers display more cases of infrequent or no AI use, but medians are nearly identical.
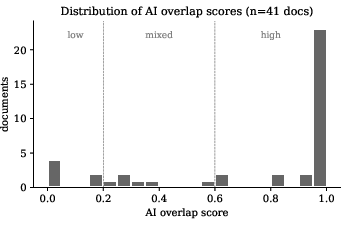
Figure 6: Distribution of AI overlap scores; majority of documents show high AI overlap, minority involve substantial human rewriting.
Stylometric analysis encompasses lexical diversity (TTR), sentence-length metrics, first-person and contraction rates, and hedging, all benchmarked against established stylometric and AI-detection literature. Distributions of these features overlap significantly between groups, indicating the warning’s effect does not manifest in detectable stylometric signals.
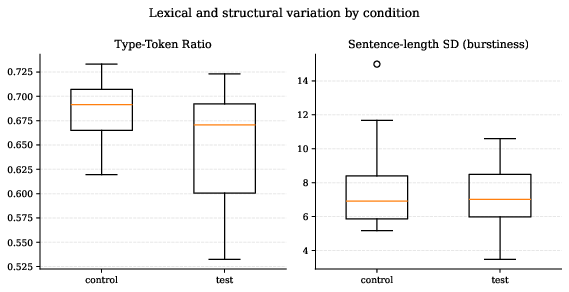
Figure 7: Lexical and structural variation (TTR, sentence-length SD) demonstrate heavy distributional overlap between control and treatment.
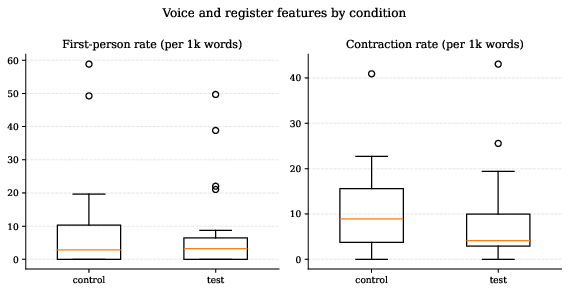
Figure 8: Voice and register features (first-person, contraction rates) show no statistically significant difference across conditions.
Phase 2: Human Judge Detection Efficacy
The second phase assesses whether independent human judges can reliably detect AI reliance, using paired comparisons of documents from both groups. 251 judges evaluated 1,999 document pairs under a deceptive prompt (“which was written by a human”), unaware both had AI access. Judges selected the treatment document as “human” 54.13% of the time versus 45.87% for control—a small but statistically significant deviation from chance (p=0.000243), consistent across writing stances.
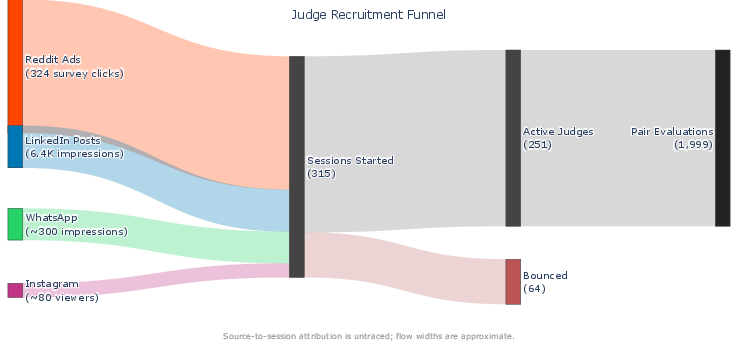
Figure 9: Recruitment funnel for judge participants, illustrating contribution breakdown across outreach channels.
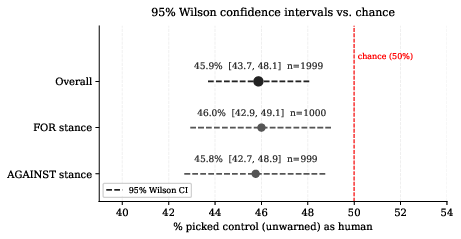
Figure 10: Wilson confidence intervals for control-as-human selection; all intervals fall below 50%, statistically favoring treatment documents.
Analysis reveals that judge confidence, reading time, and selective document expansion amplify the selection bias for treatment documents. Higher-confidence judges and slower readers favor treatment documents as human, and selective expansion of a single document further increases the chance of choosing the treatment submission.
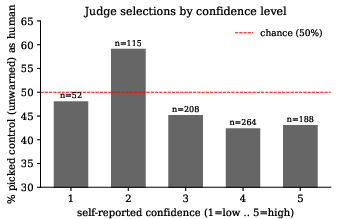
Figure 11: Control-as-human rate declines as judge confidence increases, reflecting stronger selection bias toward treatment documents among confident judges.
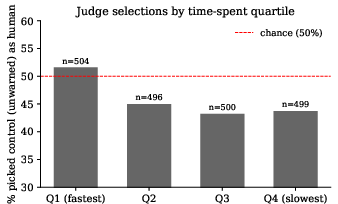
Figure 12: Control-as-human rate by time-spent quartile; slower responses correlate with more frequent selection of treatment documents as human.
Importantly, the effect is distributed across documents rather than driven by isolated outliers. Removal of high-performing treatment submissions only marginally diminishes the effect, with the majority of treatment documents above the 50% selection threshold and control documents below.
Theoretical and Practical Implications
The empirical disconnect between stylometric and feature-driven analyses versus human detection points to limitations in current feature-based AI-detection paradigms. AI-detection warnings do not reduce general AI reliance but polarize behavioral engagement, with some writers entirely forgoing AI and others intensifying interaction. Despite indistinguishable stylometric profiles, human judges consistently perceive warned-writer submissions as more human.
This suggests that human evaluators detect subtle, non-quantifiable signals—possibly involving prose rhythm, editorial choices, or contextual idiosyncrasies—beyond the reach of engineered features. It challenges the premise that current AI-detection tools, reliant on stylometric, overlap, and surface-level textual signals, are sufficient for nuanced detection in high-scrutiny contexts. The findings have implications for institutional policy and forensic linguistics, positing that conceptual primes may cascade into editorial decision-making sufficiently nuanced to escape analytic capture but not human intuition.
Future research should scale sample sizes, diversify writing domains, and deploy mixed-effects models to better disambiguate judge/document clustering. More consequential warnings and longitudinal designs are needed to gauge real-world behavioral shifts and avoidance strategies.
Conclusion
This work demonstrates that an AI-detection warning alters writer behavior in ways that are perceptible to human judges but are invisible to stylometric and overlap-based AI-detection features. Statistical evidence supports a small but robust “human-like” selection bias toward warned writers, irrespective of text-level analytic signals. The results challenge both theoretical and operational assumptions in current AI-detection methodologies, advocating for renewed scrutiny on the limits of feature-based systems and highlighting the nuanced capabilities of human evaluation in distinguishing AI-assisted writing under threat of detection.