- The paper demonstrates that current AI-based peer review systems fail to maintain diverse reviewer perspectives, leading to excessive homogeneity.
- It uses quantitative analysis of 75,800 reviews and controlled simulations to show significant increases in semantic similarity metrics between AI-generated reviews compared to human reviews.
- It reveals that paper laundering can trivially inflate review scores and drive a convergence in scientific writing, risking an epistemic monoculture in academic publishing.
Stop Automating Peer Review Without Rigorous Evaluation
Introduction and Context
The paper “Stop Automating Peer Review Without Rigorous Evaluation” (2605.03202) presents a formal critique of the emerging practice of automating scientific peer review with LLMs. The authors assert that peer review automation is a high-stakes application and argue that, prior to any wide-scale deployment, AI automation must rigorously satisfy transparent and empirically validated criteria. The analysis uses both in-the-wild and controlled experimental data to demonstrate that current LLM reviewers fail two necessary conditions: (1) diversity of reviewer perspectives and (2) resistance to trivial gaming via automated rewriting, or “paper laundering.” The authors propose a science of peer-review automation, advancing systematic benchmarks and evaluation requirements as prerequisites for deployment.
Empirical Evidence for the AI Reviewer Hivemind Effect
The core empirical contribution is a two-pronged quantitative and qualitative analysis showing that AI-generated reviews are excessively homogeneous compared to human reviews, evidenced in both real conference data and LLM-agent simulations.
The authors leverage 75,800 reviews from ICLR 2026, using robust LLM-origin detection (Pangram) to partition reviews. They report that inter-review similarity (InterSim) between AI-generated reviews (μ=0.486) is significantly higher than for human or AI-assisted reviews (μ=0.467, t=3218, p<0.0001, d=0.29), as visualized in Figure 1.
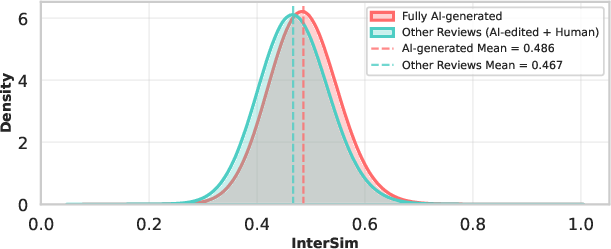
Figure 1: The AI reviewer hivemind effect: fully AI-generated reviews at ICLR 2026 cluster more tightly in semantic space than other reviews, indicating reduced diversity.
Controlled agentic review simulations with GPT-5.1 and Claude show an even larger gap, with AI intra-paper similarity (IntraSim) exceeding humans by 8.7%−9.8% (d=1.47−1.67) and cross-paper InterSim rising 17.6%−39.8% above human benchmarks (d=1.4−3.8).
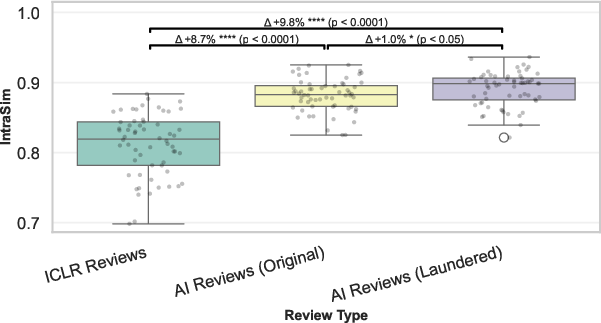
Figure 2: Simulated AI reviewers exhibit excessive agreement (IntraSim); AI reviewers are far more homogeneous than human reviewers for the same set of papers.
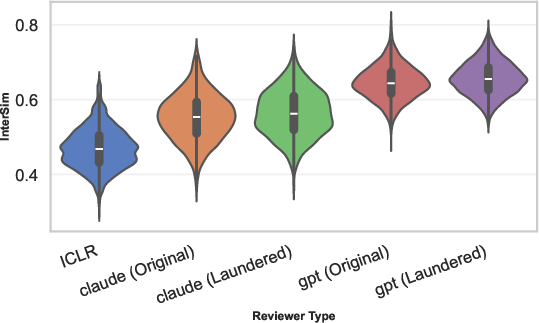
Figure 3: Inter-paper, intra-reviewer similarity (InterSim) shows that LLM agents reuse semantic and linguistic patterns across diverse papers at rates unobserved in humans.
Further analyses restricting text to review weaknesses and questions sections reinforce the claims. The effect is observed in all ICLR topical areas, ruling out confounding by scientific subfield. These findings extend prior observations about instruction-tuned LLM homogenization [jiang2025artificial, west2025base, zhang2025noveltybench] into the peer review context, with the critical implication that full AI reviewer deployment collapses the epistemic plurality on which the current peer review system relies.
Gameability via Paper Laundering
The authors introduce “paper laundering” to demonstrate that current AI reviewers can be trivially gamed: pass a manuscript through an LLM to rewrite for “maximum review score,” and resubmit. This process requires no targeted adversarial optimization or prompt injection and remains within conference guidelines. In a controlled sample, laundered versions receive a mean AI reviewer score increase of +0.45 (on a 10-point scale)—an unequivocally significant manipulation (Wilcoxon μ=0.4670).
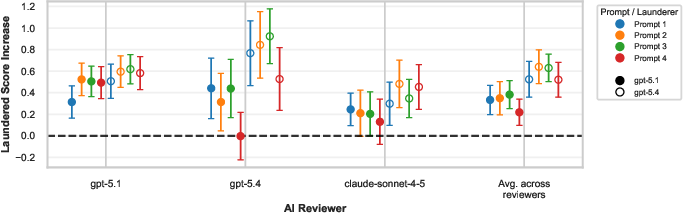
Figure 4: Paper laundering increases review scores for virtually all reviewer/launderer/prompt combinations—it is both robust and easy to effect.
The score inflation holds across LLMs and reviewer prompts and does not result from substantive scientific improvement. Manual and systematic analyses show that revisions are overwhelmingly stylistic; common additions are hedges, emphasis words, rhetorical connectives, or hallucinated “plausible-sounding” detail, ungrounded in actual results or methods.
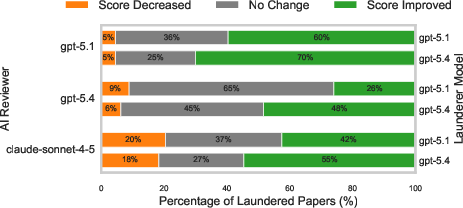
Figure 5: Score increases are ubiquitous and large when the launderer and reviewer models are similar (showing self-preference bias) or when using GPT-based reviewers.
Intellectual Monoculture: Homogenization of Scientific Communication
Beyond artificially inflating scores, laundering converges the writing style and content of papers, producing an intellectual monoculture. Embedding-based pairwise similarity between laundered manuscript abstracts and introductions increases by μ=0.4671 (Cohen’s μ=0.4672), with more than 6,000 cross-paper comparisons—demonstrating a shift toward homogeneity at corpus scale.
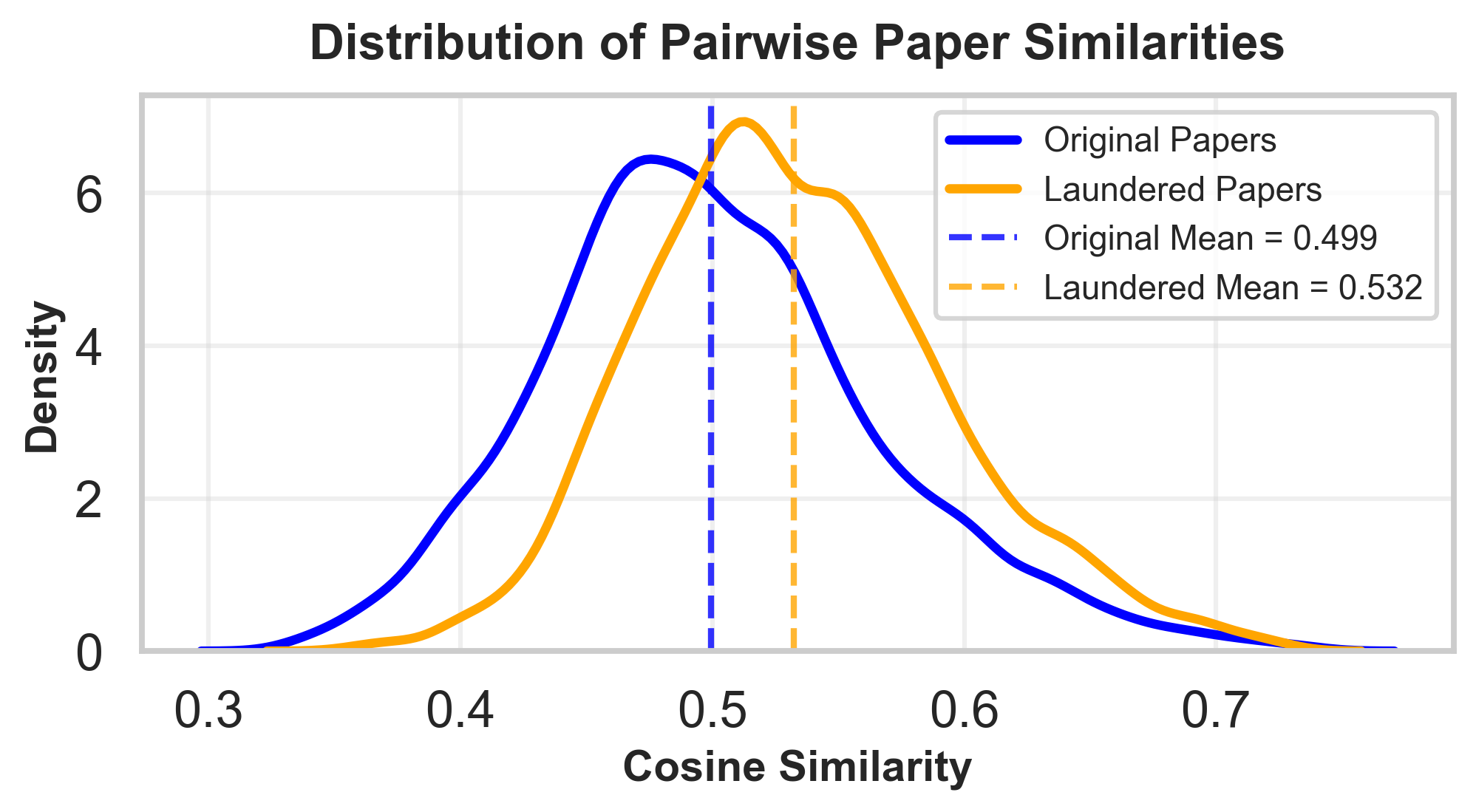
Figure 6: Paper laundering drives an increase in textual and semantic similarity between scientific papers, indicating convergence toward a single LLM-driven style.
This finding operationalizes risks articulated in the “algorithmic monoculture” literature [Kleinberg2021], where the centralization of evaluative power in a few models not only distorts acceptance criteria but feeds back into what gets written, thereby suppressing diversity of scientific communication and discovery pathways.
Critical Analysis and Theoretical Implications
The paper is careful to distinguish between the necessary and sufficient criteria for responsible peer-review automation. Even if AI reviews were not gameable and maintained diversity, unresolved concerns would remain, including accountability, transparency, incentive structure, and stakeholder alignment. The authors counter several objections, including the claim that increased consistency is beneficial (centralized errors are more damaging than distributed ones), and that AI reviewing is inevitable (“capable” AI must be proven robust, not trusted probabilistically).
The authors specifically delineate non-gameability and diversity as minimal requirements, which are empirically falsified for current systems. They further advocate a “science of peer review automation,” with transparent, adversarially tested, and empirically validated tools, open reporting of integration pipelines, empirical studies of stakeholder values, and human-AI review interaction studies to avoid overreliance [Bucinca2021, Lee2025]. These recommendations are mapped to concrete requirements and actionable directives.
Broader Implications and Future Research Directions
The empirical evidence and normative analysis in this paper underscore that LLM-based automation (as currently deployed) degrades the intended epistemic function of peer review. The practical cost of algorithmic monoculture is not hypothetical: LLM reviewer scores are less predictive of acceptance than human scores (AUC drop μ=0.4673). The authors’ findings directly challenge policy momentum toward LLM-absolutism in peer review (ICLR, AAAI, and some variants of NeurIPS) and call for systemic, transparent benchmarks.
The theoretical implications extend to any high-stakes decision pipeline where human disagreement is epistemically valuable but computational efficiency incentivizes homogenization via automation. Future research will need to (1) develop diversity-preserving and adversarially robust automated reviewer architectures, (2) produce metrics that separate stylistic from epistemic/argumentative diversity, and (3) benchmark community acceptability and behavioral impact of hybrid workflows.
Conclusion
This work establishes that current LLM-based peer review systems fail core necessary criteria: they neither preserve diversity of reviewer judgment nor resist score manipulation through trivial, fully automated rewrites. These failures are demonstrated empirically, including in large real-world deployment data, and carry nontrivial practical consequences for conference decision-making and the integrity of the scientific publication pipeline. The authors call for a rigorous, transparent, and scientifically grounded approach to AI-mediated peer review, warning against naive “automation-first” policies that risk both epistemic and behavioral monoculture. As peer review protocols evolve, these findings set a high standard for validation, red-teaming, and transparent community deliberation in future automation efforts.