On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
Abstract: With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “On the limits and opportunities of AI reviewers”
What is this paper about?
This paper asks a big question: Can AI help review scientific papers the way human experts do? The authors tested several advanced AI systems to see what they do well, what they do poorly, and how they might fit into the peer-review process (the system scientists use to check each other’s work before publication).
What questions were the researchers trying to answer?
They focused on clear, practical questions:
- Do AI reviewers point out real, important problems in papers?
- Are their comments correct and backed up by good evidence?
- How do AI reviewers compare with human reviewers—especially the best and the weakest humans?
- Do AI reviewers bring new ideas, or do they just repeat what others say?
- Where do AI reviewers tend to make mistakes?
How did they study this?
The team ran a large, careful study:
- They collected 82 published papers from Nature and related journals (these had public peer reviews available).
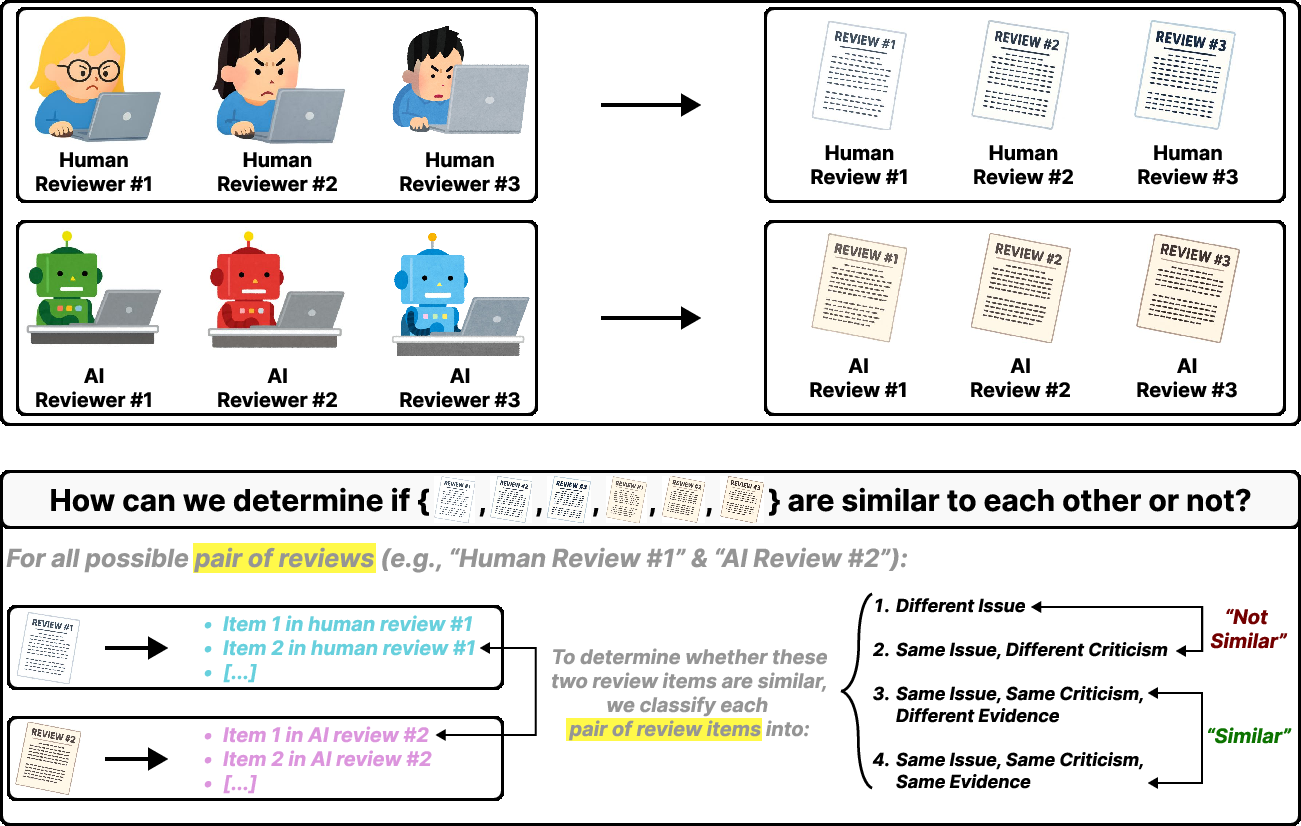
- They looked at “review items,” which means single, specific points a reviewer makes (like one complaint or suggestion). Think of a long review as a list of separate bullet points; each bullet is a “review item.”
- They gathered review items from both humans and AIs. The AIs (GPT-5.2, Claude Opus 4.5, and Gemini 3.0 Pro) were asked to read the paper files (main text, figures, supplementary materials, and sometimes code) and produce up to five focused review items each, including evidence (quotes, code snippets, or references).
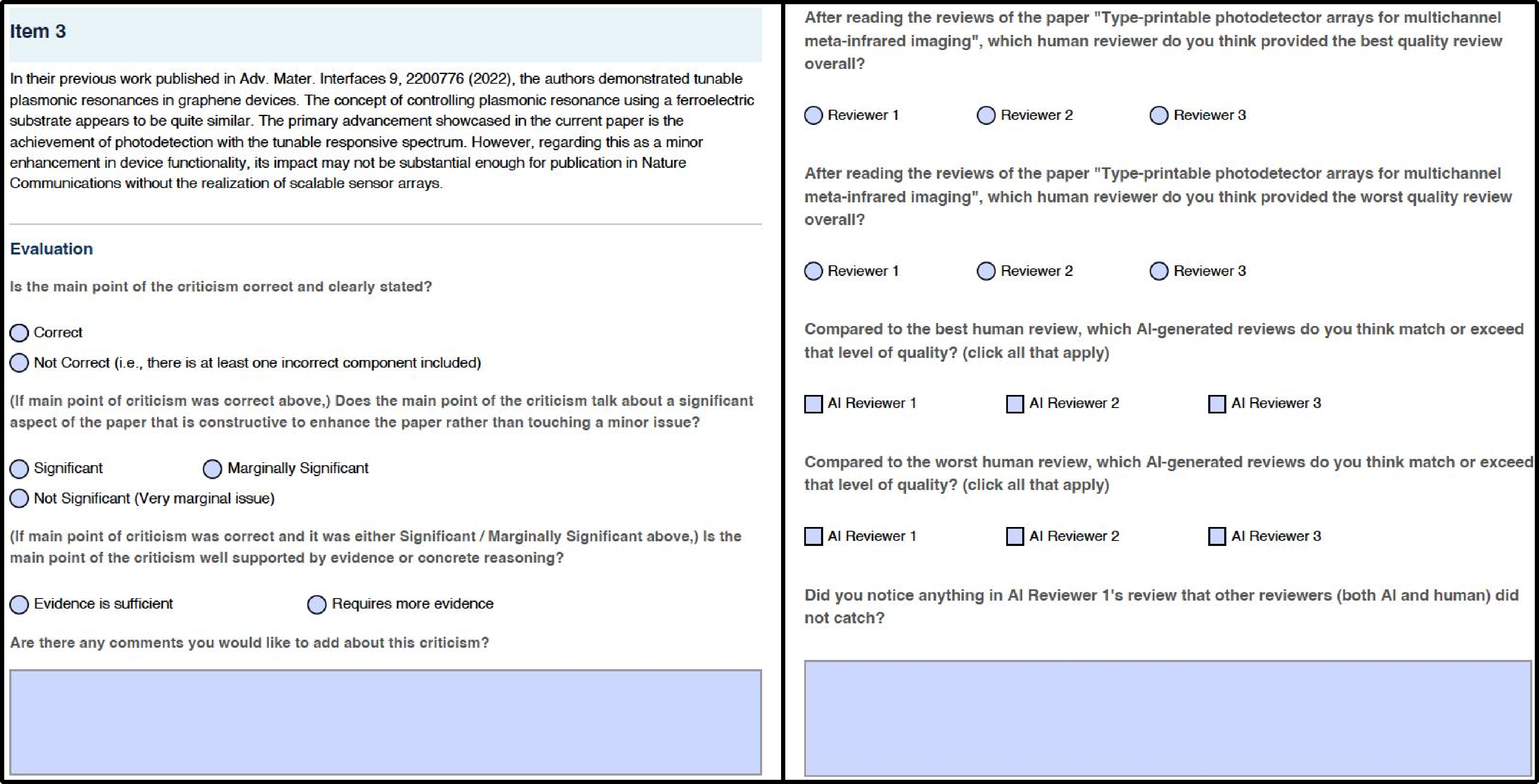
- Then, 45 expert scientists spent 469 hours judging 2,960 individual review items. For each item, experts rated:
- Correctness: Is the point factually right and clearly stated?
- Significance: If it’s correct, does it matter? (Is it a big, medium, or tiny issue?)
- Evidence: If it’s correct and matters, does the reviewer provide enough proof or examples?
To make sure the ratings were trustworthy, some papers were judged by two different experts, and the experts usually agreed—especially on whether a point was correct and whether the evidence was enough.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- AI can be very helpful, sometimes as good as top humans on overall quality:
- When combining correctness, significance, and evidence into an “overall good” score, GPT-5.2 did better than the best human reviewer on the same paper (60% vs 48%). The other AIs (Claude Opus 4.5 and Gemini 3.0 Pro) were roughly similar to the top human or a bit below—but all AIs were better than the weakest human reviewers.
- AI points are often more important and better supported, but they make more mistakes than the best humans:
- Compared to the top human, AI reviewers were more likely to raise important issues and include strong evidence (like direct quotes or code references).
- However, they were also more likely to be wrong on some points. So AI can be bold and insightful, but it also misfires more often than the best human.
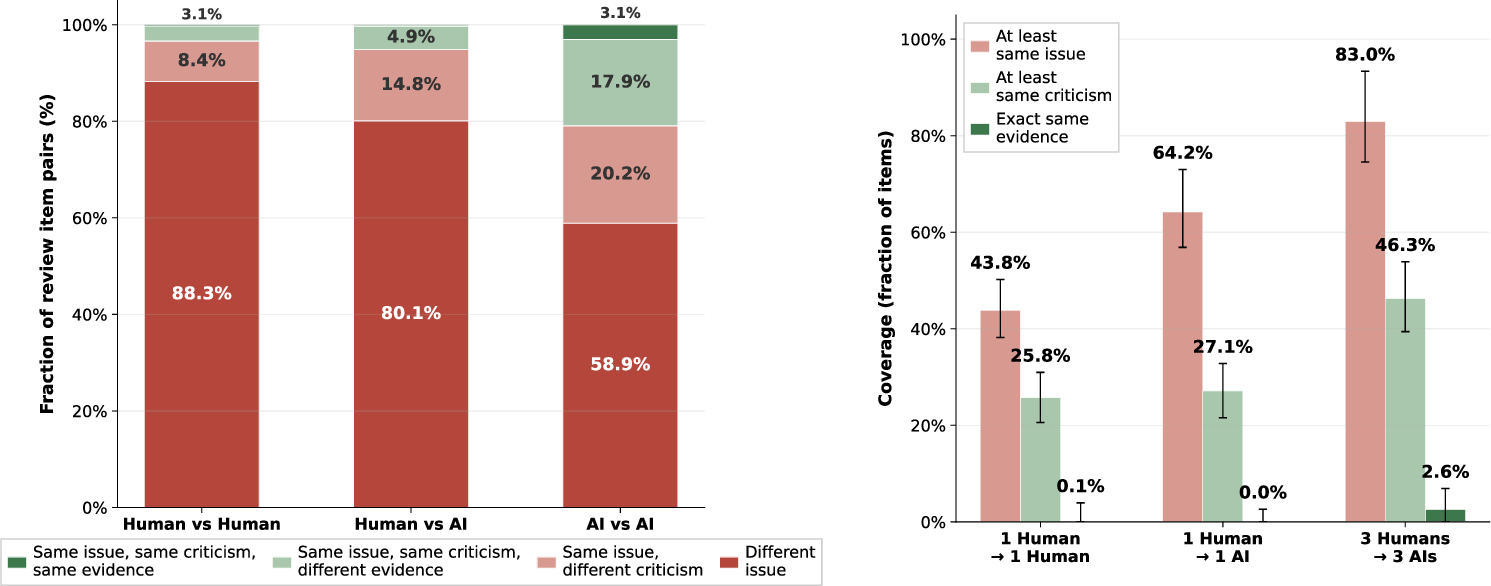
- AI brings new perspectives—but overlaps too much with other AIs:
- About a quarter of the issues raised by AI were things no human brought up, which means AI can catch fresh, overlooked problems.
- But different AI reviewers tended to repeat each other much more than humans do. This reduces the variety of opinions if you use several AIs at once.
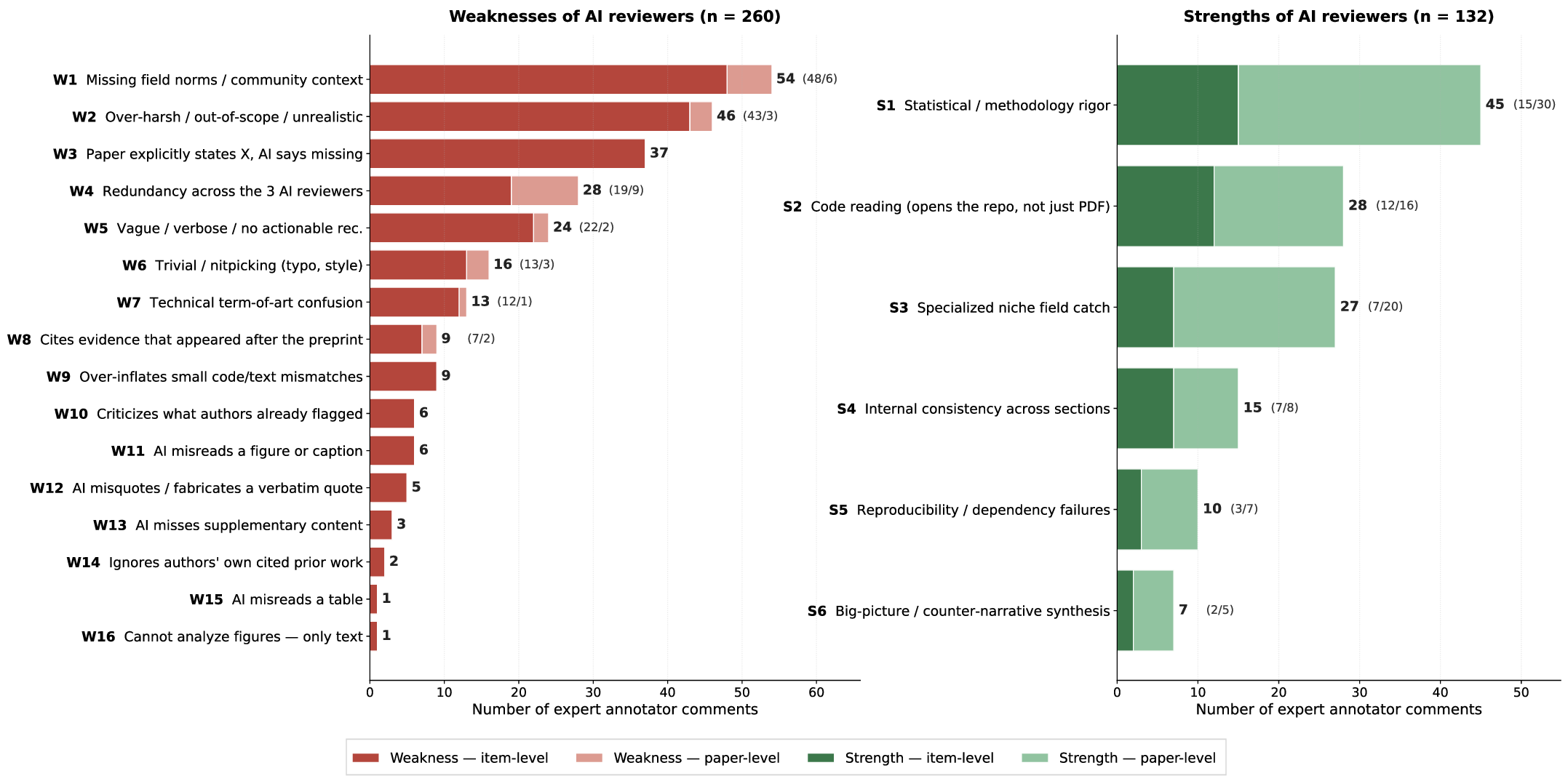
- Repeating weaknesses show where AI needs help:
- Limited knowledge of very specific subfields (they can miss “insider” details).
- Trouble keeping track of very long documents and multiple files (they lose the thread across main text, supplements, and code).
- Being too harsh on small issues (making minor things sound major).
- Expert judgments matched the numbers:
- Experts said GPT-5.2 matched or beat the best human on about half the papers, and beat the weakest human on about three-quarters. The other AIs did similarly well against the weakest human, but less often matched the very best human.
Why this matters: Good peer review is critical to science. If AI can help find important problems and back them up with evidence, it can save time, improve papers, and help journals handle more submissions. But because AI can be wrong and sometimes repeats itself, it isn’t ready to replace people.
What could this change in the future?
The authors suggest treating AI as a powerful assistant, not a replacement:
- Use AI to add coverage: AI can spot issues humans miss (like checking code or tracking details across files), helping authors improve their work before submission or helping editors get a faster first pass.
- Keep humans in the loop: Humans are still better at avoiding mistakes and using deep, niche knowledge. A mixed team (humans + AI) likely gives the best results.
- Aim for diversity: Don’t use multiple AIs as your “panel” of reviewers without careful design—they tend to overlap too much with each other. Mixing human experts with one AI might give better variety and fairness.
- Build better tools and tests: The authors released:
- PeerReview Bench, a dataset and benchmark to measure AI reviewer quality over time (newer models still have lots of room to improve).
- CMU Paper Reviewer, an open-source AI review tool that produced higher-quality items than other platforms they tested.
In short, AI reviewers are promising teammates. They can help find important problems and support them with evidence, but they still need human partners to catch mistakes, bring deep expertise, and ensure a healthy mix of viewpoints.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The study provides valuable, fine-grained evidence about AI reviewer capabilities, yet several methodological and substantive uncertainties remain that future work could address:
- Generalizability beyond Nature-family journals: the corpus is dominated by Nature Communications (73/82), potentially limiting conclusions for conferences, society journals, specialized venues, and disciplines outside Physical/Biological/Health sciences (e.g., social sciences, mathematics, engineering design, humanities).
- Selection bias from inclusion criteria: requiring transparent peer review and a Research Square pre-review version likely skews the sample toward specific subfields and author behaviors; quantify how included vs. excluded papers differ.
- Risk of model pretraining leakage: although publisher domains were blocked at inference, models may have seen these papers during pretraining; conduct membership-inference or contamination checks and replicate on post-cutoff manuscripts.
- Lack of annotator blinding to reviewer identity: domain scientists knew which items were AI vs. human, inviting expectancy effects; replicate with fully blinded item-level evaluation.
- Potential conflicts of interest: many annotators are co-authors on the paper; run an independent replication with external experts unaffiliated with the project.
- Limited field stratification: no detailed breakdown of AI vs. human performance by subfield, method type, or paper modality (e.g., theory vs. empirical, with vs. without code); provide stratified analyses and interactions.
- Context-length effects unquantified: long-context failure modes are reported but not tied to measurable features (tokens, number of files/figures, code size); perform controlled ablations over document and repository scale.
- Tooling/configuration ablations missing: the agent’s tool suite (shell, editor, web search) was fixed; systematically vary tool access (code execution/sandboxes, PDF parsers, citation databases, math/CAS tools, retrieval) to map capability gains and risks.
- Single-shot generation per model: stochastic variability, seed effects, and run-to-run consistency were not assessed; measure variance across multiple runs and prompts per paper.
- Prompt/design asymmetry: AI reviewers were instructed to structure claims and attach evidence, while human reviewers were unconstrained; run a controlled study where humans are asked to supply structured evidence to isolate true evidence-quality differences.
- Cap of five AI items per paper: the hard cap likely forces prioritization toward higher-perceived significance; quantify the impact by removing or varying the cap and comparing precision–recall trade-offs.
- Outcome-level impact unmeasured: item-level quality does not establish whether AI reviews improve manuscripts, shorten decision times, or change acceptance outcomes; conduct longitudinal revision-and-resubmission studies.
- Multi-round, interactive reviewing untested: only first-round reviews were analyzed; evaluate AI performance across multi-round dialogues, author rebuttals, and editor-mediated negotiation.
- Overlap methodology reliability: the similarity taxonomy for item overlap is introduced but its annotation process, IRR, and potential automation are not detailed; validate overlap labeling and explore scalable matching methods.
- Ensemble diversity and assignment policy: AI–AI overlap is high (21%) but there is no exploration of diversification strategies (e.g., heterogeneous prompts/tools/models) or optimal human–AI mixing; develop assignment algorithms that maximize marginal coverage under quality constraints.
- Failure-mode mitigation not evaluated: 16 recurring weaknesses are cataloged but not tested against targeted interventions (domain retrieval, methodology-specific checklists, long-context memory aids, calibration training); design and assess targeted fixes.
- Error severity and harm not quantified: incorrect items vary in gravity; introduce severity-weighted metrics and measure downstream harms (e.g., misleading methodological claims).
- Broader quality dimensions omitted: beyond correctness, significance, and evidence, aspects like actionability, tone/constructiveness, reproducibility guidance, and ethical risk detection were not assessed; extend the rubric and validate reliability.
- Inter-annotator reliability gaps: only moderate agreement on significance (AC1 ≈ 0.44); refine scale anchors, train annotators, and test alternative scales (e.g., 5-point) for higher reliability.
- Statistical multiplicity and robustness: many pairwise tests are reported without explicit multiple-comparison control; provide adjusted p-values and sensitivity analyses to dependence structures.
- Benchmark validity and circularity: PeerReview Bench “automatically applies” expert criteria, but its scoring mechanism, calibration to human experts across subfields, and robustness to model-judge bias are not fully specified; audit the benchmark and report agreement vs. independent experts.
- Service evaluation transparency: CMU Paper Reviewer’s reported gains (e.g., 95.5%) lack detail on datasets, annotator independence, and blinding; release protocols and replicate with third-party evaluators.
- Cost, latency, and carbon footprint: compute/time costs for AI reviews vs. human effort are not reported; quantify economic and environmental trade-offs under realistic throughput scenarios.
- Confidentiality and compliance: risks around sharing unpublished data/code with AI agents (data governance, IP, patient privacy) are not analyzed; develop and test compliant deployment protocols.
- Fabrication and misquotation rates: while “evidence sufficiency” is rated, the frequency and detection of fabricated references/quotes or subtle miscitations are not explicitly measured; add targeted checks and detectors.
- Robustness to adversarial authorship: authors might optimize manuscripts to exploit known AI reviewer heuristics; simulate and defend against gaming strategies.
- Fairness and bias across research communities: no analysis of differential performance across geographic regions, institutional resources, or subfields with divergent conventions; conduct fairness audits.
- Non-textual modality handling: the ability to reason over figures, complex equations, and specialized data formats is not quantified; create modality-specific probes and metrics.
- Code execution and reproducibility checks: it is unclear whether agents executed code or just inspected it; evaluate actual reruns, environment management, and reproducibility validation accuracy.
- Human baseline representativeness: comparisons are to the “Top-Rated” and “Lowest-Rated” human per paper, not to the median or full distribution; report effects vs. typical human performance and editor decisions.
- Optimal editorial integration: beyond “complement not substitute,” concrete workflows (triage, red-flag detection, checklist auditing, literature cross-checks) and their efficacy are not evaluated; perform editor-in-the-loop trials.
- Temporal stability: rapid model version drift threatens reproducibility; document exact model snapshots and re-run key analyses on updated versions to quantify drift.
- Cross-lingual generalization: only English manuscripts were considered; test AI reviewers on non-English or translated manuscripts and multilingual code/commentary.
Practical Applications
Summary
This paper rigorously evaluates AI “reviewers” at the level of individual, evidence-backed criticisms, using 45 domain scientists to rate 2,960 review items across 82 Nature-family papers. Key findings: (1) AI reviewers surface more significant, better-evidenced issues than top human reviewers but with a non-trivial correctness gap; (2) GPT-5.2 matches/exceeds top human aggregate item quality, while all tested AIs surpass the lowest-rated human; (3) AI reviewers overlap with each other more than humans do, and exhibit recurring failure modes (e.g., limited subfield knowledge, long-context across files, overly critical stance on minor issues). The authors release two resources: PeerReview Bench (a benchmark that automates their evaluation criteria) and CMU Paper Reviewer (an open-source agentic reviewer service). Results emphasize AI as a complement, not a substitute, for human peer review.
Below are practical, real-world applications derived from these results, methods, and tools.
Immediate Applications
These use cases can be implemented now with current models and the released tools, assuming basic editorial or organizational buy-in and access to manuscript artifacts.
- AI-assisted pre-submission feedback for authors
- Sector: Academia; cross-cutting to industry R&D
- What: Deploy CMU Paper Reviewer (or equivalent) as an Overleaf/LaTeX/Word add-in or lab “preflight check” to generate structured review items (claim + evidence) on draft manuscripts, code, and supplements.
- Why (paper-enabled): The study shows AI raises significant, well-evidenced items and adds ~26% distinct issues not raised by humans.
- Dependencies/assumptions: Access to manuscript files and code; privacy safeguards; appropriate model/API availability; clear disclaimers about correctness gaps.
- Editorial triage and augmentation in journals/conferences
- Sector: Academic publishing (e.g., Nature-family, society journals; conferences)
- What: Use a single AI reviewer routinely alongside 2 human reviewers to (i) surface high-impact issues early, (ii) reduce reviewer burden, and (iii) shorten time-to-decision.
- Why: AI items often significant and well-evidenced; AI complements humans but should not replace them.
- Dependencies/assumptions: Editorial policies governing AI-assisted review; human oversight; workflow integration with systems like ScholarOne/Editorial Manager.
- Diversity-aware reviewer assignment and de-duplication
- Sector: Academic publishing; program committees
- What: Introduce overlap analytics (from the paper’s overlap framework) to (i) avoid multiple AI reviewers on the same paper (AI-AI overlap is high), (ii) select human reviewers to maximize diversity of perspectives relative to AI output.
- Why: AI-AI overlap (~21%) is far higher than human-human (~3%); one AI + diverse humans likely maximizes coverage.
- Dependencies/assumptions: Basic tooling to compute overlap categories (target/criticism/evidence); editorial buy-in.
- Reviewer training and QA using the three-part rubric
- Sector: Academia; research integrity/quality units
- What: Train students and early-career reviewers to write structured, evidence-backed criticisms using the paper’s cascading rubric (correctness → significance → sufficiency of evidence) and calibrate via PeerReview Bench samples.
- Why: The rubric had high inter-annotator agreement (esp. on correctness/evidence), making it a practical training scaffold.
- Dependencies/assumptions: Curriculum time; access to de-identified examples; institutional support.
- Structured “review item” templates for all reviews
- Sector: Academic publishing; internal R&D reviews
- What: Require that reviews be submitted as atomic, evidence-linked items (claim + target + evidence), standardizing expectations and improving author actionability.
- Why: The item structure underpins higher-quality, auditable critiques and enables downstream analytics.
- Dependencies/assumptions: Template adoption in editorial systems; reviewer guidance.
- Code and supplement inspection agents for reproducibility risks
- Sector: Software/AI/ML research; broader R&D
- What: Use agentic reviewers with file-system tools to scan submitted code (e.g., numerical stability of eigen-solvers as in the paper) and supplementary materials for robustness gaps or missing diagnostics.
- Why: The study’s agent setup showed concrete code-level issues can be found with evidence quotations.
- Dependencies/assumptions: Submitted, runnable code or at least readable source; secure sandboxes; strict data handling.
- Departmental or funder “mock review” services
- Sector: Universities; grant offices; philanthropic and public funders
- What: Offer AI-assisted pre-reviews of grant proposals and technical reports to identify significant issues before submission.
- Why: AI surfaces significant, well-evidenced issues; improves proposal polish and methodological clarity.
- Dependencies/assumptions: Confidentiality agreements; data governance; funding agency policy compliance.
- Classroom modules on peer review and scientific writing
- Sector: Education
- What: Use CMU Paper Reviewer and PeerReview Bench-style items to teach critique construction, evidence citation, and prioritization of significance.
- Why: The rubric is easy to teach and aligns with observed expert agreement patterns.
- Dependencies/assumptions: Instructor authorization; student data privacy.
- Internal technical documentation review in industry
- Sector: Software, robotics, energy, finance, biotech
- What: Apply AI reviewers to internal design docs, risk analyses, and model cards to flag unsupported claims and missing evidence, improving audit readiness.
- Why: The structured-review format and evidence linking translate directly to compliance-centric documentation.
- Dependencies/assumptions: On-prem or private-cloud deployments; redaction mechanisms; SME oversight.
- Policy pilots and disclosures for AI-in-the-loop peer review
- Sector: Academic publishing; professional societies
- What: Introduce policies that (i) mandate disclosure of AI usage in reviews, (ii) require human accountability, (iii) restrict multiple-AI panels, and (iv) encourage structured items with evidence.
- Why: Paper’s evidence favors “complement, not substitute,” and highlights correctness/failure modes needing oversight.
- Dependencies/assumptions: Governance processes; stakeholder alignment.
Long-Term Applications
These use cases require further model improvements (e.g., correctness, subfield depth, long-context handling), scaling, standards, or policy development.
- Full-scale AI-assisted peer review pipelines with measurable SLAs
- Sector: Academic publishing; preprint servers
- What: Integrate agents into end-to-end editorial workflows (screening, assignment support, structured reviews, meta-review synthesis) with auditable metrics for correctness, significance, and evidence rates.
- Dependencies/assumptions: Improved correctness; robust long-document/context tools; stable APIs; cost controls; cross-publisher standards.
- Automated reproducibility and robustness audits
- Sector: Academia; software/ML; regulatory science
- What: Agents execute code, check data lineage, validate statistical claims, and report evidence-linked issues—beyond static reading.
- Dependencies/assumptions: Executable environments; containerized reproducibility; permissions; better tool-use reliability and safety.
- Domain-specialized AI reviewers with subfield expertise
- Sector: Healthcare, materials, physics, genomics, etc.
- What: Train/align reviewers per subfield to reduce misinterpretations of conventions (a key failure mode) and improve correctness without sacrificing significance.
- Dependencies/assumptions: High-quality subfield corpora; expert-curated supervision (e.g., via PeerReview Bench variants); continuous evaluation.
- Long-context and multi-file reasoning systems
- Sector: AI tooling; publishing
- What: New architectures/workflows for agents to track content across main text, supplements, figures, and large codebases, addressing current “losing track” failure mode.
- Dependencies/assumptions: Advances in memory, retrieval, and tool-use orchestration; benchmarked reliability.
- Reviewer-mix optimization using overlap models
- Sector: Academic publishing; conferences
- What: Algorithms that pick human–AI reviewer slates maximizing target/criticism diversity while meeting quality thresholds, using the paper’s overlap taxonomy as an objective.
- Dependencies/assumptions: Access to reviewer histories; standardized similarity metrics; fairness considerations.
- Regulatory-grade document assessors
- Sector: Healthcare (e.g., clinical protocols, device filings), finance (risk reports), energy (safety cases)
- What: Evidence-linked, structured critiques for compliance documents, with audit trails and model certification against domain-specific benches.
- Dependencies/assumptions: Regulatory acceptance; certification standards; robustness and traceability; secure deployments.
- Standardization of structured review item schemas
- Sector: Publishing; industry documentation standards bodies
- What: Community standards for “review item” schemas (targets, claims, evidence) enabling interoperability, analytics, and quality control across venues and vendors.
- Dependencies/assumptions: Multi-stakeholder coordination; tooling integration; incentives for adoption.
- Certified AI reviewer programs and vendor ecosystems
- Sector: AI industry; publishers
- What: Use PeerReview Bench (and successors) to certify AI reviewer performance, publish scorecards, and set minimum thresholds for editorial use.
- Dependencies/assumptions: Bench expansion across disciplines/languages; governance for certification; audit processes.
- Multi-agent reviewer panels with deliberate diversity
- Sector: Publishing; enterprise QA
- What: Assemble panels of differently trained AI agents (diversified by training data, prompting, or toolkits) to reduce AI–AI overlap and improve coverage.
- Dependencies/assumptions: Demonstrated diversity gains without collapsing correctness; orchestration costs; deduplication methods.
- IDE/notebook-integrated “methods and evidence linter”
- Sector: Software/data science education and practice
- What: Live feedback on missing evidence, ambiguous claims, or statistical pitfalls while writing methods or analysis notebooks.
- Dependencies/assumptions: Stronger local tooling; domain-tuned checks; minimized false positives.
- Open science pipelines with automated critique at submission
- Sector: Preprint servers, data repositories
- What: On-upload generation of structured critiques and checklists, aiding authors and readers in assessing readiness.
- Dependencies/assumptions: Platform collaboration; compute funding; opt-in privacy controls.
Notes on Assumptions and Dependencies (Cross-Cutting)
- Model capability and stability: Current results depend on frontier LLMs with agentic tool use; correctness gaps and failure modes must be mitigated for high-stakes use.
- Access to artifacts: Effectiveness improves when agents can read supplements, figures, and code; many submissions lack or restrict these.
- Privacy, IP, and compliance: Strong data governance and on-prem deployment options are often required (grants, regulatory filings, corporate R&D).
- Human oversight: The paper’s conclusion (complement, not substitute) implies accountable humans remain in the loop for decisions and fact-checking.
- Cost and throughput: Editorial deployments must balance compute costs with turnaround-time gains.
- Generalizability: Results are from Nature-family papers in physical/biological/health sciences; other disciplines and languages may require adaptation.
- Stakeholder acceptance: Editors, reviewers, authors, and regulators need clear policies on disclosure, accountability, and conflict-of-interest.
These applications translate the paper’s core contributions—a criticism-level evaluation rubric, overlap-aware perspective on reviewer diversity, identified failure modes, and two public resources (PeerReview Bench and CMU Paper Reviewer)—into deployable workflows today and a roadmap for scaled, audited, and domain-specialized AI-assisted reviewing tomorrow.
Glossary
- Active-learning MD: A molecular dynamics workflow that updates its underlying model on-the-fly using active learning to improve predictions during simulation. "so the reported active-learning MD workflow can fail unpredictably once training states become nearly linearly dependent."
- Bootstrap confidence intervals: Confidence intervals computed by resampling the data with replacement to approximate the sampling distribution of an estimator. "bootstrap confidence intervals (10{,}000 paper-level resamples, percentile method)"
- Canonical orthogonalization: A procedure (e.g., via eigen-decomposition) that transforms a non-orthonormal basis into an orthonormal one to improve numerical stability. "The manuscript does not describe any canonical orthogonalization, eigenvalue truncation, or other conditioning step for this solve."
- Carr-Parrinello MD: A first-principles molecular dynamics method that couples electronic structure and nuclear motion by propagating electronic degrees with fictitious dynamics. "the appropriate comparison could include Carr-Parrinello MD"
- CASPT2: Complete Active Space Second-Order Perturbation Theory, a post-CASSCF method that adds dynamic electron correlation corrections. "or better CASPT2"
- CASSCF: Complete Active Space Self-Consistent Field, a multireference electronic structure method that treats static correlation within a chosen active space. "using CASSCF, RASSCF, or better CASPT2"
- Cluster bootstrap: A bootstrap method that resamples at the cluster (e.g., paper or subject) level to account for within-cluster dependence. "95\% cluster-bootstrap CIs"
- Cohen's kappa: A chance-corrected measure of inter-rater agreement for categorical data. "we report Gwet's AC1 alongside raw percent agreement and Cohen's "
- Condition number: A numerical measure of sensitivity to perturbations, often the ratio of largest to smallest singular/eigenvalues; high values indicate ill-conditioning. "There is no diagnostic for the condition number of S"
- Definite positive: The text’s phrasing of “positive definite,” meaning a matrix with all positive eigenvalues. "or b matrix is not definite positive."
- Eigenvalue truncation: Stabilization technique that discards very small eigenvalues (and associated components) to mitigate numerical instability. "The manuscript does not describe any canonical orthogonalization, eigenvalue truncation, or other conditioning step for this solve."
- Generalized eigenvalue problem: An eigenproblem of the form Av = λBv, common when working in non-orthonormal bases (e.g., with an overlap matrix). "the diagonalization of a generalized eigenvalue problem"
- Generalized Linear Mixed Model (GLMM): A statistical model that extends generalized linear models by including random effects to account for hierarchical or correlated data. "A GLMM analysis with paper-level random intercepts reaches the same conclusions"
- Gwet's AC1: A chance-corrected agreement coefficient less sensitive than kappa to prevalence and marginal imbalance. "we report Gwet's AC1 alongside raw percent agreement and Cohen's "
- Hermitian: A matrix equal to its complex conjugate transpose; guarantees real eigenvalues and orthogonal eigenvectors. "Note that if input matrices are not symmetric or Hermitian, no error will be reported but results will be wrong."
- Ill conditioning: Numerical instability arising when a matrix is close to singular, making solutions highly sensitive to small perturbations. "overlap-matrix ill conditioning"
- Inter-annotator agreement: The degree of consistency between different annotators assessing the same items. "To measure inter-annotator agreement, 27 of the 82 papers were independently annotated by a second domain scientist"
- Kappa paradox: The phenomenon where Cohen’s kappa is low despite high percent agreement, typically due to skewed marginals. "the well-known kappa paradox under skewed marginals"
- LinAlgError: An exception indicating a numerical linear algebra failure (e.g., non-convergence or singular matrices) in scientific computing libraries. "triggers exactly this kind of LinAlgError"
- Overlap matrix: In quantum chemistry, the matrix of overlaps between non-orthonormal basis functions, often denoted S. "with the overlap matrix passed in unchanged"
- Paired t-test: A statistical test comparing means of two related samples (paired observations). "inferential comparisons use paired -tests (with Cohen's )"
- Rank-biserial correlation: An effect size associated with rank-based tests (e.g., Wilcoxon), measuring the difference in probability that one sample’s observations exceed the other’s. "the Wilcoxon signed-rank test (with rank-biserial correlation )"
- RASSCF: Restricted Active Space Self-Consistent Field, a variant of CASSCF that partitions the active space to reduce computational cost. "using CASSCF, RASSCF, or better CASPT2"
- Skewed marginals: Imbalanced category distributions that can bias agreement statistics like kappa. "the well-known kappa paradox under skewed marginals"
- Static and dynamic correlations: In electronic structure, static (near-degeneracy) and dynamic (short-range) electron correlation effects that require different treatments. "both static and dynamic correlations"
- Wilcoxon signed-rank test: A nonparametric test for comparing paired samples when normality assumptions may not hold. "the Wilcoxon signed-rank test (with rank-biserial correlation )"
- Wilson confidence interval: A binomial proportion interval with better coverage properties than the normal approximation, especially for small samples. "Wilson 95% CI"
Collections
Sign up for free to add this paper to one or more collections.