- The paper introduces PaperRecon, a framework that quantifies both presentation quality and hallucination in AI-generated scientific writing.
- It employs a section-wise rubric and agentic verification to isolate factual inaccuracies and improve evaluation fidelity.
- Findings reveal a trade-off where models excelling in presentation tend to generate more hallucinations, underlining key design challenges.
Paper Reconstruction Evaluation for AI-Generated Scientific Writing
Motivation and Problem Context
Systematic and high-fidelity evaluation of AI-driven scientific writing, particularly by coding agents, presents critical challenges for research rigor and academic integrity. The proliferation of agent-authored submissions in top conferences heightens the urgency for reliable metrics that can discern not only presentational adequacy but also ground factual correctness and minimize hallucination risk. Existing approaches predominantly focus on review-based evaluations, which inadequately penalize severe fabrications and exhibit a dangerous tendency for inflated assessment of hallucinated or unsound content. The lack of an orthogonal, fine-grained evaluation protocol leaves a major gap for both empirical tracking of agent progress and risk abatement in the integration of automated writing into the research publication pipeline.
PaperRecon: Evaluation Framework and Methodology
PaperRecon is introduced as a principled, dual-axis evaluation framework for quantifying the strengths and deficiencies of AI scientific writing agents. The core protocol involves compressing a published paper into a succinct, structured research overview—augmented only with minimalistic resources (figures, tables, code, and references)—and tasking an agent to reconstruct the target manuscript from these constraints.
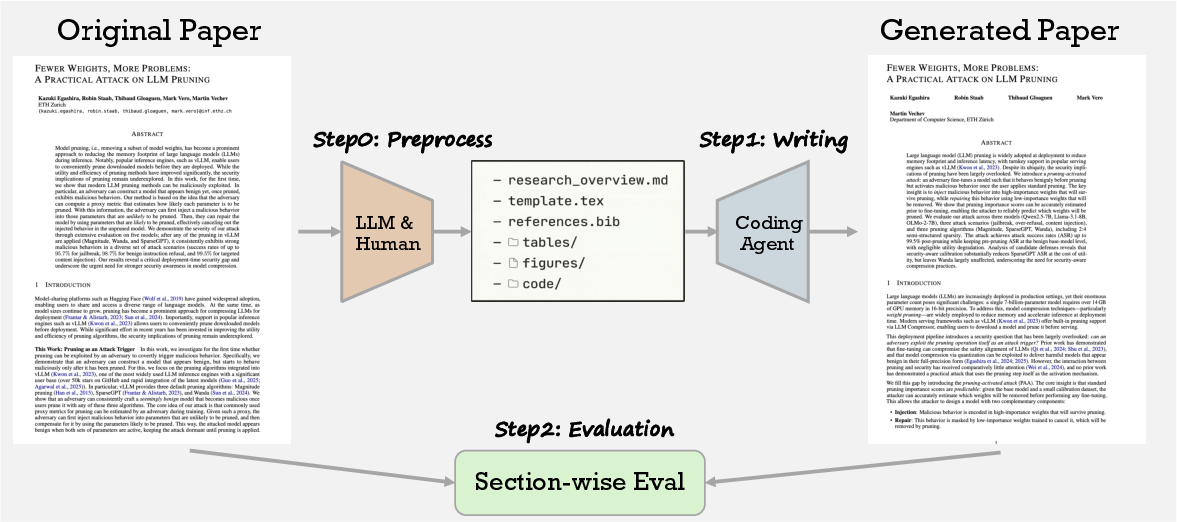
Figure 1: The paper reconstruction process provides a compressed paper summary and minimal resources as input for an agent, which then generates a full write-up; outputs are compared along axes of presentation quality and hallucination.
The approach isolates the writing generation capability from upstream tasks such as experimental design or reference retrieval, thus controlling for confounding factors. The reconstructed output is compared section-wise with the ground-truth manuscript to produce orthogonal measurements along two primary axes:
The evaluation is further enhanced by citation-level analysis, detecting citation hallucinations, omissions, and erroneous attributions. All metrics are operationalized within PaperWrite-Bench, a benchmark suite curated from 51 post-2025 top-venue papers spanning ML, CV, NLP, and multimedia, supporting statistically robust agent assessment.
Experimental Results and Quantitative Findings
Comprehensive experiments evaluate Claude Code (Sonnet 4/4.6), Claude Code Agent Teams, and Codex (GPT-5/5.4). Key results demonstrate:
- Claude Code achieves superior presentation quality, consistently attaining higher rubric scores across all paper sections relative to Codex. The best configuration (Sonnet 4.6) achieves a mean section score of 3.86/5, indicating effective structural and narrative preservation.
- Codex exhibits lower hallucination rates. Codex (GPT-5.4) restricts major hallucinations to an average of 3 per paper, compared with over 10 for Claude Code agents, evidencing a clear trade-off: models that better emulate human writing form frequently incur greater factual risk.
- Citation accuracy trends mirror hallucination trade-offs: while Claude-based agents have higher F1 on citation coverage, Codex produces fewer hallucinated attributions.
- All agent families show monotonic improvement with backbone advancement (e.g., GPT-5 to GPT-5.4), evidencing the value of PaperRecon-derived metrics for longitudinal benchmarking.
These results are validated through human blind-review studies and manual hallucination verification, where rubric-based assessments exhibit a strong Kendall's τb=0.578 with human preference ranking, and over 96% of detected hallucinations correspond to genuine contradictions.
Analysis, Ablations, and Domain Insights
Further analysis explores the influence of research overview granularity and disciplinary context:
- Increasing the detail in provided overviews systematically reduces hallucination rates and enhances presentation scores for all agents, demonstrating that input specificity is tightly coupled with achievable output fidelity.
- Domain-specific evaluation reveals NLP-focused papers score highest on both axes, likely attributable to reduced mathematical and architectural complexity in this subset; conversely, multimedia and CV sections expose more structural and factual reconstruction errors.
The framework explicitly considers agent error typologies, such as error propagation in multi-step section reconstruction, and identifies current LLM/agent weaknesses in handling deep domain-specific reasoning and in grounding factually consistent numerical evidence.
Implications and Future Trajectory
PaperRecon establishes the validity and necessity of section-level, claim-grounded comparative evaluation for agentic scientific writing. The dual-axis decomposition of metrics offers clear utility for triaging agent design trade-offs, model selection, and future research on hallucination-elimination. Results reveal that advances in language agent capabilities currently incur nontrivial, and often subtle, risks for factual distortion—a contradiction to the intuition that increased model size and fluency necessarily improve reliability.
Practical implications are direct: a shift is mandated from acceptance-focused or "reviewer fooling" protocols to granular, source-grounded measurement for review-automation, publishing acceptance, and real-world agent deployment. The approach creates a testbed for the future integration of agent teams, iterative retrieval, and human-in-the-loop protocols. The limitations of fixed resource provision and the challenges of style-diversity and cross-field generalization further motivate investigations into more robust, adaptive evaluation mechanisms and the integration of retrieval/verification augmentation—both to reduce hallucination rates and to extend to settings with greater diversity of writing style and structure.
Conclusion
PaperRecon provides a rigorous, orthogonally decomposed framework for the systematic evaluation of AI-driven scientific paper generation, with strong empirical evidence establishing its discriminative validity and actionable insights into the trade-off between presentation quality and factual reliability (2604.01128). The findings call for continuous methodological refinement as agent systems become increasingly embedded in science automation workflows and highlight the enduring necessity for robust, transparent, source-grounded benchmarks in AI scientific writing.


