Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling
Abstract: Reinforcement learning (RL) has become a key component in modern LLMs, yet the rollout stage remains the key bottleneck in RL training pipelines. Although Multi-Token Prediction (MTP) offers a natural solution to accelerate rollouts through speculative decoding, many studies have observed that MTP acceptance rates degrade significantly during RL training, leading to limited speedup performance. To address this bottleneck, we present Bebop, a systematic study of MTP in LLM post-training, and offer practical recipes to integrate MTP into large-scale RL pipelines. First, we reveal that the MTP acceptance rate is fundamentally bounded by the fluctuation of model entropy, which demonstrates a clear negative linear relationship with the rise of entropy in the RL stage. Second, we show that probabilistic rejection sampling largely alleviates the disturbance introduced by entropy in RL compared to greedy draft sampling. We further identify that the conventional MTP training objectives (cross-entropy or KL) are suboptimal in such settings, and therefore we propose a novel end-to-end TV loss that directly optimizes multi-step rejection sampling acceptance rate, yielding ~10% acceptance rate improvements, achieving up to 95% acceptance rates and up to 25% extra inference throughput gains across mathematical reasoning, code generation, and agentic tasks. Third, we test various online MTP training strategies during RL and show that pre-RL MTP training with e2e TV loss and rejection sampling achieves a consistent acceptance rate and speedup throughout the entire RL, eliminating the need for costly online MTP updating. We provide extensive experiments and analysis that validate our findings. Experimental results show our method achieves up to 1.8x end-to-end acceleration in async RL training of Qwen3.5, Qwen3.6, and Qwen3.7 models.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making LLMs learn faster when trained with reinforcement learning (RL). The authors introduce a method, called Bebop, that speeds up the slowest part of RL training: generating long answers (“rollouts”). They do this by improving how the model “drafts” multiple future words at once and then quickly checks them.
What problem are they solving?
- In RL for LLMs, most time is spent generating text during rollouts.
- A known speed-up trick, Multi-Token Prediction (MTP), drafts several next tokens and then verifies them in one go. But during RL, the “acceptance rate” (how many drafted tokens get approved per check) often drops, so the speed-up shrinks.
- Why does acceptance drop? Two main suspects: 1) The model becomes more “uncertain” (its predictions spread across many words), which is called higher entropy. 2) The main model keeps changing during RL, while the draft module is frozen, so they drift apart.
The key finding: the big culprit is the model’s uncertainty (entropy), not the drift.
How do they try to solve it?
Think of the process like this:
- A “draft model” proposes several next words.
- A “teacher” model checks them. The more they agree, the more tokens get accepted, and the faster generation goes.
The paper improves two parts:
- Switching how drafts are checked
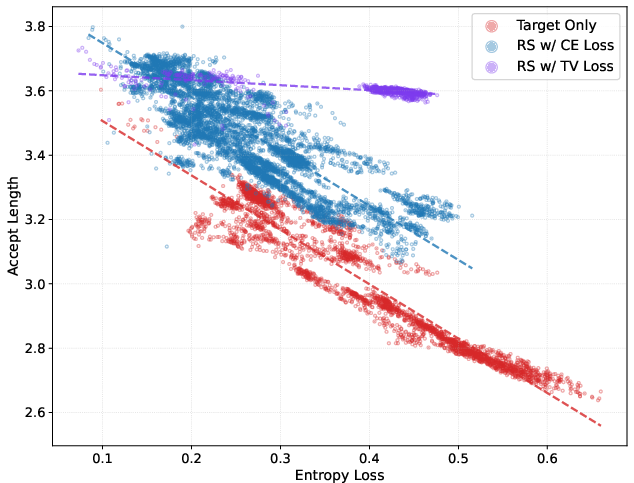
- Old way (target-only): Always pick the draft’s favorite word and accept it with the teacher’s probability. This works poorly when the teacher is uncertain (entropy is high), because the top probability shrinks, capping acceptance.
- New way (rejection sampling): Randomly sample a draft token and accept it based on how well draft and teacher line up for that token. This measures overall agreement, not just the top choice, so it’s much less sensitive to uncertainty.
- Training the draft model with a better goal
- Common training uses cross-entropy or KL loss. These don’t directly improve the thing that matters for rejection sampling: the overlap between the draft and teacher’s full distributions.
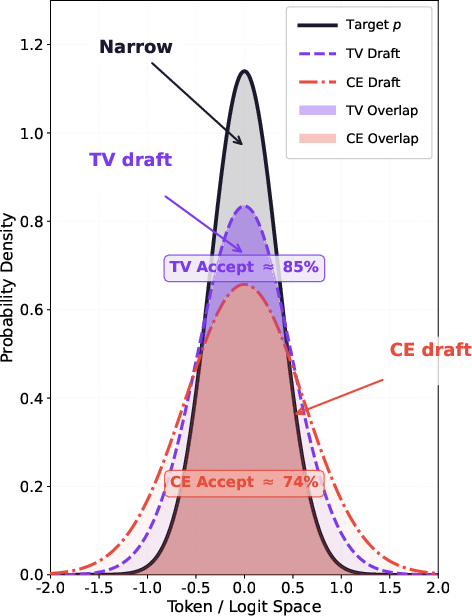
- The authors propose a new “TV loss” (Total Variation loss). Plainly: it directly trains the draft model to maximize overlap with the teacher across all likely words, which directly raises the acceptance rate for rejection sampling.
- They also create an “end-to-end” version that trains the draft model to do well across multiple steps in a row, not just one step, matching how MTP actually works in practice.
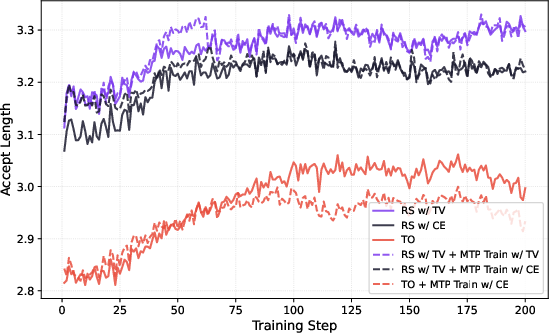
They also show a simple, practical recipe: train the draft model with this TV loss before RL starts (pre-RL), then keep it fixed. No need for complicated online updates during RL.
What did they find?
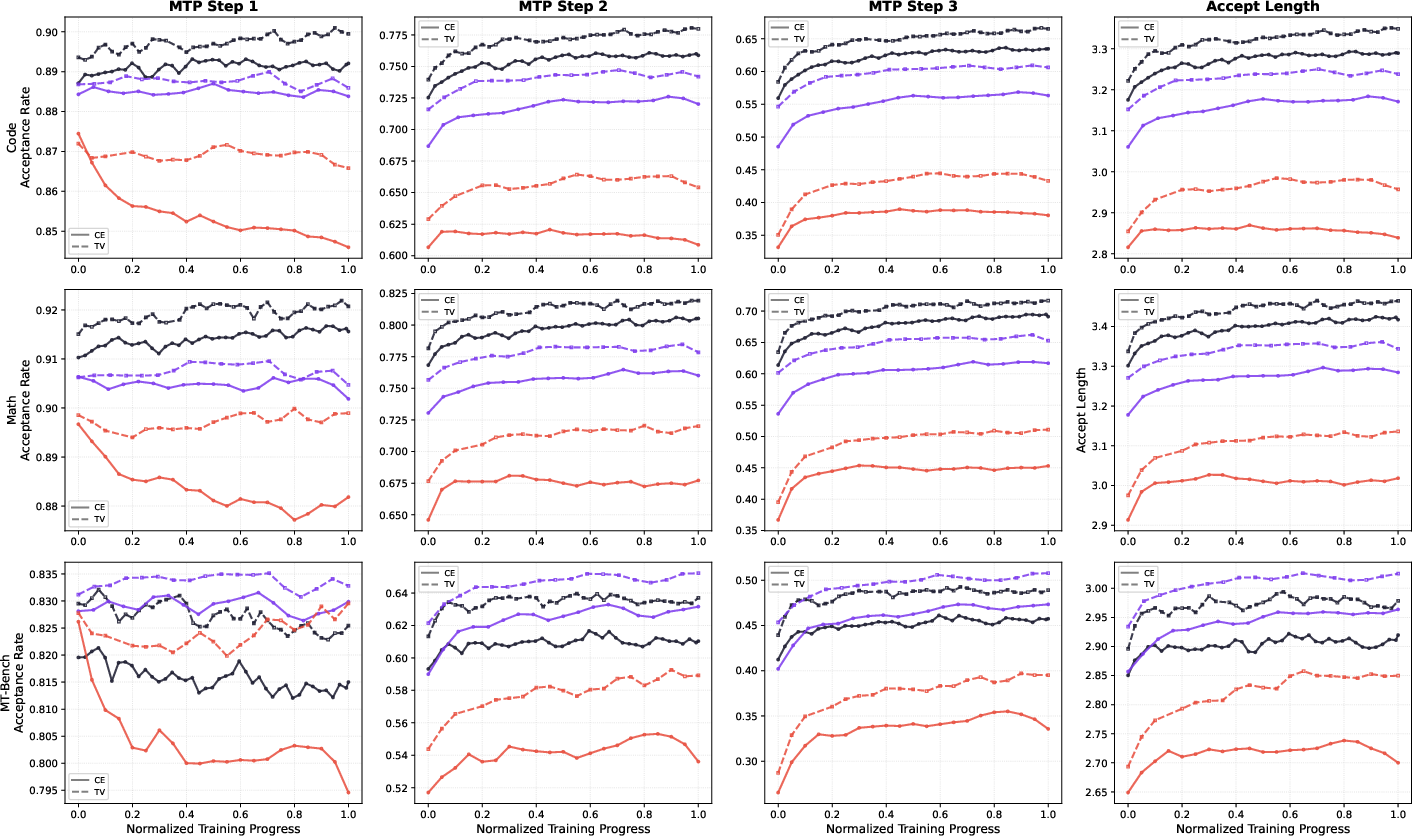
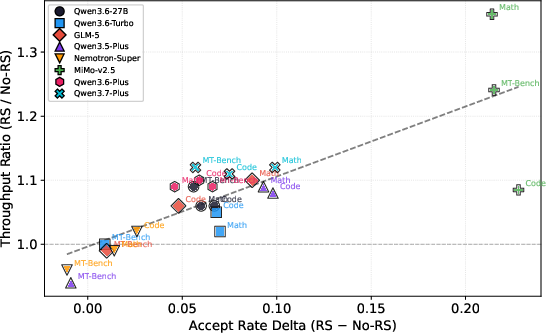
- Acceptance rates improve by about 10% on average with the new TV loss compared to standard training, and can reach up to about 95% on some tasks.
- This translates into up to 25% extra inference throughput during rollouts and up to 1.8× faster end-to-end RL training in their systems.
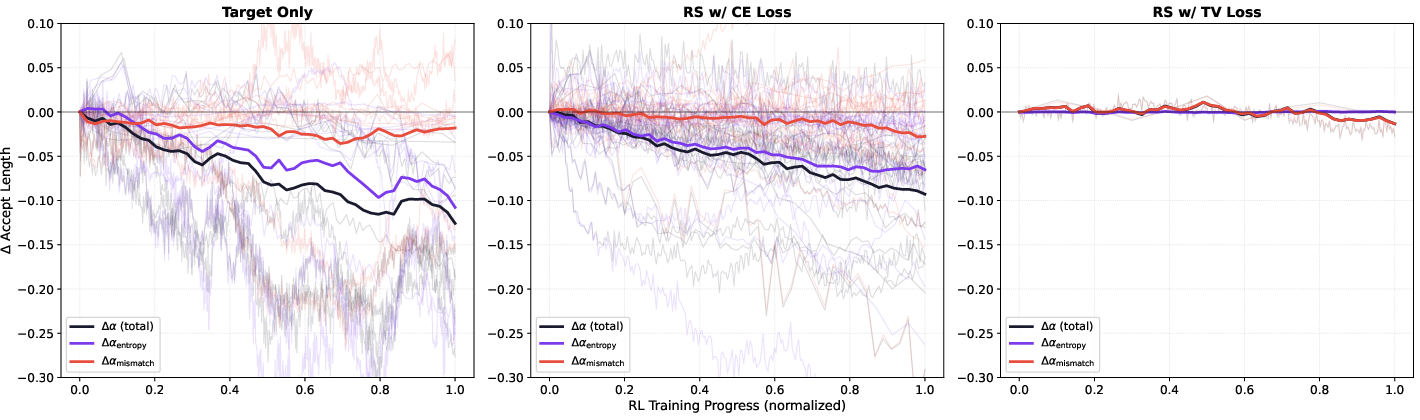
- Rejection sampling largely removes the harmful effect of rising entropy. With the TV loss, acceptance stays stable even when the policy becomes more “uncertain.”
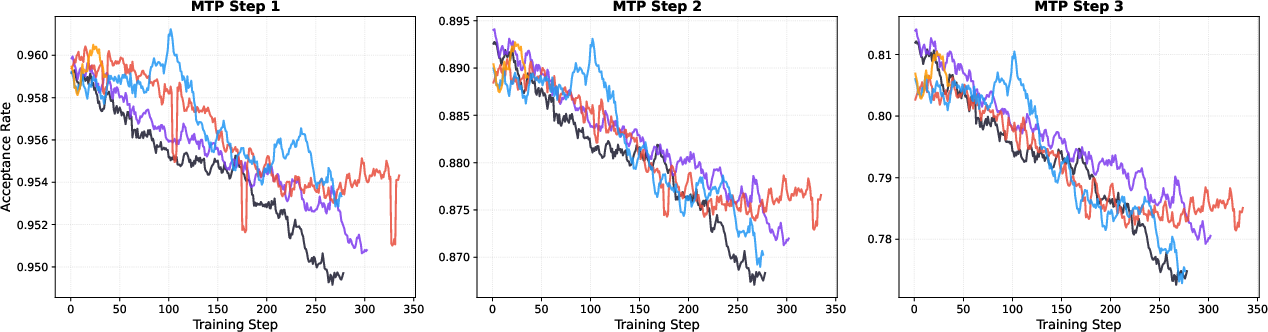
- The supposed “drift” between the draft and teacher during RL barely matters under rejection sampling. So updating the draft heads online during RL brings little benefit and can be skipped.
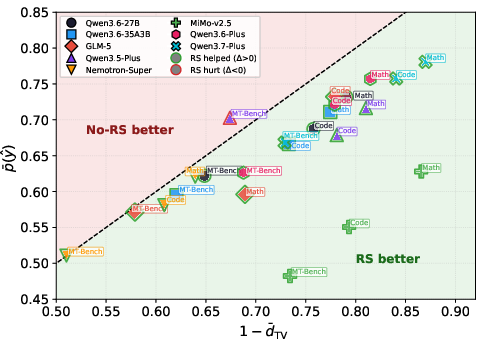
- Benefits are consistent across math reasoning, coding, and agent-style tasks, and acceptance generally gets better as model size increases.
Why is this important?
- Faster rollouts mean faster RL training for LLMs, saving huge amounts of compute and time.
- Stable acceptance during RL lets teams plan reliably: no surprise slowdowns as training progresses.
- The method is simple to apply:
- Train the draft heads once with end-to-end TV loss before RL.
- Use rejection sampling during rollouts.
- Skip expensive online updates of the draft heads during RL.
- The approach helps unlock practical, large-scale RL for LLMs on complex tasks like long reasoning, coding, and multi-step agent interactions.
A simple mental picture
- Draft model = a fast assistant who suggests several next words.
- Teacher model = the cautious expert who must approve them.
- Entropy = how indecisive the expert is; higher means more spread-out choices.
- Target-only checking = only trusting the assistant’s top guess; suffers when the expert is indecisive.
- Rejection sampling = considering the whole spread of suggestions and approvals; works well even if the expert is indecisive.
- TV loss = a training rule that teaches the assistant to match the expert’s tastes across the whole menu, not just the top dish, so more suggestions get approved more often.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that would help future researchers extend, validate, or stress-test the paper’s claims.
- Formalize multi-step acceptance vs. entropy: provide full proofs (beyond proof sketches) that relate policy entropy to expected multi-step acceptance under target-only and rejection sampling, including imperfect draft ranking and compounding effects across steps.
- Convergence guarantees for TV loss: analyze optimization properties of the (non-smooth) min/indicator-based TV objective (e.g., subgradient consistency, convergence rates, conditions preventing oscillation), and compare with smoothed surrogates.
- Capacity-dependent bounds: quantify how the claimed “entropy invariance” of TV-trained drafts depends on draft head capacity, number of heads, and γ; provide explicit upper bounds on the residual entropy–acceptance slope as a function of these factors.
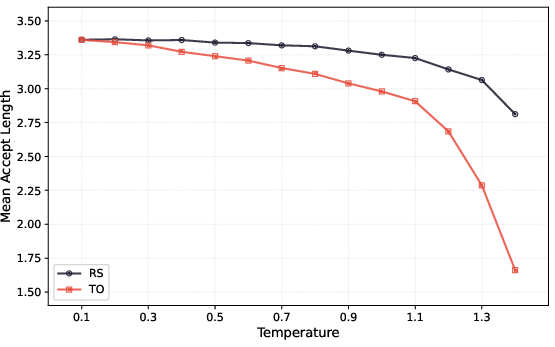
- Temperature and top-k/top-p effects: rigorously characterize how rollout temperature, top-k/top-p sampling, and entropy regularizers interact with acceptance rates for both RS and target-only methods, and whether TV training maintains robustness under typical RL exploration settings.
- Break-even analysis for RS overhead: develop a hardware-aware cost model that includes draft-probability caching, memory bandwidth, additional kernels, and synchronization; map acceptance-rate thresholds where RS overtakes target-only for different GPUs and batch/sequence regimes.
- e2e TV loss stability at depth: study gradient propagation through products of per-step acceptance (potential vanishing/exploding effects at larger γ); identify curricula or reweighting schemes that stabilize late-head learning without hurting early-head performance.
- Objective alternatives beyond TV: evaluate whether other f-divergences (e.g., Jensen–Shannon, α-divergences) or Wasserstein variants better correlate with RS acceptance while preserving stability and offering smoother gradients.
- Draft–backbone interference: quantify if (and when) pre-RL MTP training with e2e TV alters backbone calibration/perplexity or harms base-model likelihoods; analyze any trade-off between draft overlap and backbone quality.
- Domain and language generalization: extend acceptance and speedup evaluations to multilingual, conversational, and instruction-following domains beyond math/code/agent; measure robustness under significant domain shift (more comprehensive OOD datasets).
- Impact on RL learning quality: report final RL task metrics (accuracy, reward, pass@k) and sample efficiency under Bebop vs. baselines to confirm speed gains do not subtly degrade learning outcomes.
- Conditions where online MTP updates help: identify regimes (e.g., very aggressive policy updates, highly non-stationary tasks, extreme exploration settings) where mismatch under RS is no longer negligible and online MTP co-training becomes beneficial.
- Adaptive γ scheduling: study dynamic selection of MTP depth based on online estimates of entropy/overlap and system load; quantify gains vs. static γ.
- Interactions with group sampling in GRPO: characterize cumulative rollout speedups and contention when generating G trajectories per prompt; determine whether RS computation can be amortized or shared across the group.
- MoE backbones and sparse routing: test whether RS acceptance and TV training remain robust with mixture-of-experts targets (expert switches across steps could amplify mismatch).
- Very long-context and multi-turn limits: analyze acceptance drift and throughput for extreme context lengths and high-turn-count agent loops (beyond 128K/200 turns), including KV-cache pressure and cache-eviction effects on acceptance.
- Quantization and numerical precision: investigate how FP8/INT8 quantization, tensor-parallel sharding, and kernel fusion affect RS acceptance and the stability of TV loss training.
- Memory footprint of TV/RS: quantify additional memory for draft probability vectors, per-token min operations, and multi-head outputs during both training and rollout; provide recipes for fitting into constrained memory budgets.
- Calibration and uncertainty: measure whether TV training changes draft calibration (e.g., ECE/Brier) and whether calibration improvements (or degradations) explain acceptance changes, especially under high-entropy policies.
- Sampling-policy unbiasedness with truncation: prove and empirically validate unbiasedness (or controlled bias) of multi-step RS under truncated target distributions (top-k/top-p) used in RL rollouts.
- Robustness to adversarial/high-entropy prompts: characterize worst-case acceptance under intentionally flattened or adversarial policy distributions; provide safeguards or fallbacks when overlap collapses.
- Head architecture and placement: ablate draft-head depth, parameterization (e.g., linear vs. MLP), sharing across layers, and positional offsets; study how these design choices affect overlap and entropy invariance.
- Hyperparameter sensitivity: provide systematic sweeps for TV/e2e-TV learning rates, warmup, gradient clipping, loss scaling, and data curricula; distill robust default settings.
- Comparative system baselines: benchmark against advanced speculative decoders (e.g., tree-based Medusa/EAGLE variants) and assess whether e2e TV extends to those paradigms with similar entropy robustness.
- Comprehensive speed decompositions: report end-to-end speedups broken down by compute, memory, KV-cache ops, tool latency, and networking to clarify where the 1.8× gains come from and portability across clusters.
- Reproducibility and code release: release full training code for TV/e2e-TV objectives, data recipes, and scripts (beyond the RS inference PR) to enable independent replication and external validation.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings can be applied today across sectors, with notes on tools, workflows, and feasibility constraints.
- Accelerate RLHF/GRPO pipelines for LLMs (Industry, Academia; Software/AI)
- Use case: Cut rollout time and GPU cost in RL training by replacing target-only speculative decoding with rejection sampling and pre-RL e2e TV-loss MTP training. Reported gains: up to 1.8× end-to-end RL speedup, up to ~25% extra inference throughput, acceptance up to ~95%.
- Workflow:
- 1) Add MTP heads to the backbone;
- 2) Pre-train MTP with e2e TV loss on SFT data;
- 3) Use rejection sampling in rollout;
- 4) Skip online MTP updates during RL.
- Tools: SGLang (RS implementation available), veRL (or similar RL frameworks), PyTorch/DeepSpeed/Megatron for training.
- Assumptions/Dependencies:
- Inference engine must support RS (cache q and compute min(1, p/q)).
- Gains are larger when acceptance is high (γ≈3 works well in the paper).
- Pre-RL MTP training data aligned to upcoming RL tasks improves OOD robustness; otherwise, gains may be smaller.
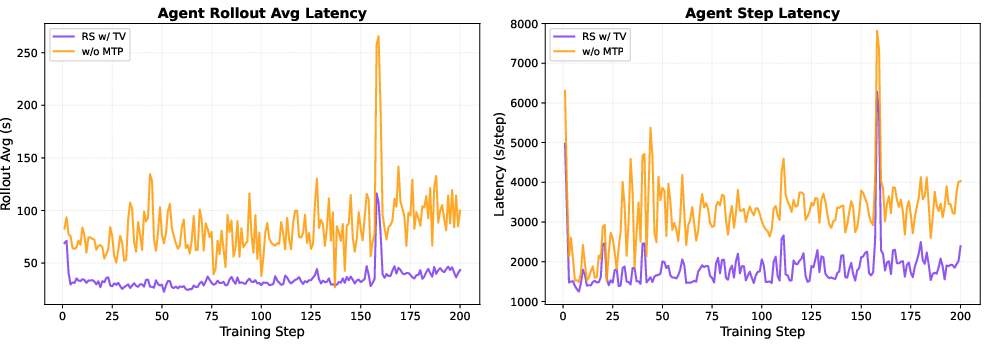
- Speed up multi-turn, tool-using agent training (Industry, Academia; Software/Agentic systems)
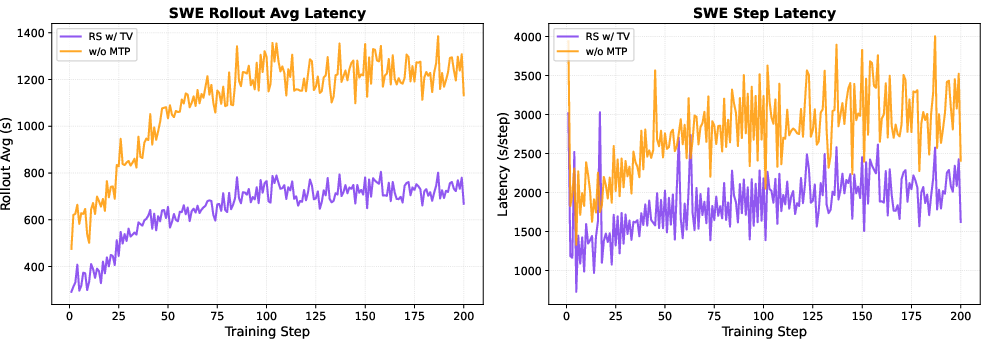
- Use case: Faster RL training for coding agents, tool-call planners, and software repair (e.g., SWE-bench-style tasks), where long-horizon rollouts dominate cost.
- Workflow: Integrate RS + TV-trained MTP into async RL frameworks for multi-turn tool use; avoid MTP co-training during RL to save memory and latency.
- Assumptions/Dependencies:
- Multi-turn sandbox and tool IO are supported;
- RS overhead is offset by high acceptance rates achieved with TV-trained MTP.
- Throughput and latency improvements in production inference for LLM agents (Industry; Software)
- Use case: Improve online inference throughput for complex agentic tasks (coding assistants, automation bots) by deploying RS with TV-trained MTP; observed acceptance up to ~95% on agent tasks.
- Products: Faster IDE copilots, customer support agents, and internal automation tools that rely on long chains-of-thought or tool interactions.
- Assumptions/Dependencies:
- Draft heads are present in deployed models;
- RS provides net gains only when acceptance is already high; otherwise, target-only may remain preferable.
- Cost and energy savings for training operations (Industry; Cloud/IT Ops)
- Use case: Reduced GPU-hours per RL run translate to lower cloud costs and energy use without changes to the backbone training objective.
- Workflow: Adopt RS + TV-loss MTP training as a standard pre-RL step; schedule RL jobs with updated throughput estimates.
- Assumptions/Dependencies:
- Infrastructure supports RS kernels and batching;
- Gains depend on rollout-dominant workloads.
- Diagnostics and monitoring: entropy-aware acceptance tracking (Industry, Academia; MLOps)
- Use case: Use the paper’s entropy–acceptance relationship to monitor and debug RL instability; use RS + TV-trained MTP to decouple acceptance from entropy fluctuations.
- Workflow: Track policy entropy and acceptance per step; switch between RS and target-only based on acceptance and overhead; tune temperature to maintain target acceptance ranges.
- Assumptions/Dependencies:
- Access to per-step entropy/accept length metrics;
- Incremental overhead for telemetry.
- Open-source replication and benchmarking (Academia; Software/AI)
- Use case: Reproduce results on non-Qwen backbones to validate generality; compare CE/KL vs. TV across datasets (math, code, agent, OOD).
- Tools: SGLang PR (linked in paper), public Qwen checkpoints, Megatron/Deepspeed.
- Assumptions/Dependencies:
- Engineers comfortable modifying training objectives and inference kernels.
- Education-focused model training (Industry, Academia; Education/EdTech)
- Use case: Faster RL training of reasoning-heavy tutors (math/coding), improving iteration speed for pedagogy and safety alignment.
- Workflow: Apply pre-RL TV-loss MTP training and RS during student-simulation rollouts.
- Assumptions/Dependencies:
- Reasoning tasks benefit more; OOD lesson domains may see smaller gains unless covered in pre-RL data.
- Safety/red-teaming RL loops (Industry, Academia; Safety/Compliance)
- Use case: Faster adversarial RL cycles for harmful-content avoidance or tool-use safeguards by cutting rollout latency.
- Workflow: Integrate RS + TV MTP into red-teaming RL pipelines to increase the number of training iterations per time budget.
- Assumptions/Dependencies:
- Safety wins rely on better/faster training loops, not on changes in reward models themselves.
Long-Term Applications
These opportunities require additional research, scaling, or engineering before broad deployment.
- Default RL training recipe for next-gen LLMs (Industry, Academia; Software/AI)
- Vision: Standardize RS + e2e TV-loss MTP as the default in RLHF/GRPO pipelines for large models and longer γ.
- Potential tools: Fused RS kernels, compiler-level speculative decoding optimizations, automatic γ tuning.
- Dependencies:
- Kernel/engine-level optimizations to reduce RS overhead at larger γ;
- Validation across diverse architectures beyond Qwen.
- Acceptance-optimized on-device or edge personalization (Industry; Mobile/Edge)
- Vision: Enable lightweight RL/personalization on-device (or at the edge) by leveraging high-acceptance MTP to cut compute/latency.
- Products: Private, on-device assistants that adapt via small RL loops.
- Dependencies:
- Efficient RS on low-power hardware;
- Memory footprint minimization for MTP heads;
- Privacy-preserving RL workflows.
- Cross-modal and embodied agent training (Industry, Academia; Robotics, Multimodal AI)
- Vision: Port TV-loss MTP + RS to language-planning components within robotics or multimodal RL, accelerating long-horizon training in simulation.
- Dependencies:
- Extension of MTP/RS for multimodal token streams;
- Empirical validation in closed-loop control.
- Generalized TV-based objectives for other autoregressive models (Academia; Speech, MT, Protein/NLP)
- Vision: Apply end-to-end TV-loss training for speculative decoding in speech, translation, code synthesis, or domain-specific autoregressors to increase acceptance and reduce latency.
- Dependencies:
- Speculative decoding primitives available in those domains;
- Careful calibration of TV gradients for different vocabularies and temperatures.
- Acceptance-aware RL curriculum and exploration control (Academia; RL Methods)
- Vision: Integrate acceptance-aware schedules (e.g., adaptive temperature/entropy) to balance exploration and high-throughput rollouts dynamically.
- Dependencies:
- Studies on the trade-offs between exploration quality, entropy targets, and acceptance length;
- Controller policies for auto-tuning temperatures.
- Policy and sustainability frameworks for efficient training (Policy, Industry; Sustainability)
- Vision: Establish best-practice guidelines and procurement standards that account for acceptance-aware RL pipeline efficiency to reduce carbon and costs.
- Dependencies:
- Consensus metrics for “accept length” and energy reporting;
- Wider adoption and auditing practices.
- RL-as-a-service with acceptance-aware scheduling (Industry; Cloud/Platforms)
- Vision: Managed RL training platforms that optimize job placement and batching based on predicted acceptance and throughput under RS + TV-trained MTP.
- Dependencies:
- Accurate predictors of acceptance vs. entropy per dataset/model;
- Integration with cluster schedulers and billing models.
- Security and compliance training at scale (Industry; Finance, Healthcare, Gov)
- Vision: Faster RL loops to refine domain-specific compliance assistants (e.g., HIPAA, SOX) using acceptance-aware rollouts; accelerate safe tool-use policies for sensitive domains.
- Dependencies:
- Domain data availability and suitable rewards;
- Regulatory validation of training pipelines;
- Ensuring that throughput gains do not compromise evaluation rigor.
- Hardware–software co-design for high-acceptance speculative decoding (Industry; Semiconductors)
- Vision: Architectures that co-optimize memory bandwidth and compute for RS acceptance paths, including caching strategies for draft distributions.
- Dependencies:
- New accelerator primitives and APIs;
- Stable software standards across frameworks.
Notes on feasibility across applications:
- The paper’s strongest evidence is in LLM RL pipelines (reasoning, coding, agent tasks) with γ≈3 and on Qwen 3.5–3.7. Porting to other architectures/tasks should be validated empirically.
- RS offers larger gains when acceptance is high; at low acceptance or small models, target-only may remain competitive due to RS overhead.
- TV-loss MTP training robustly reduces entropy sensitivity but does not remove it entirely; temperature and task entropy still influence acceptance.
- Pre-RL data quality matters: in-distribution tasks benefit more than OOD; broaden SFT mixtures to maximize generalization.
Glossary
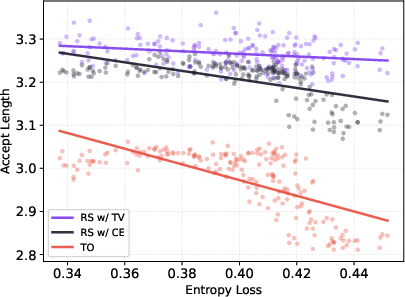
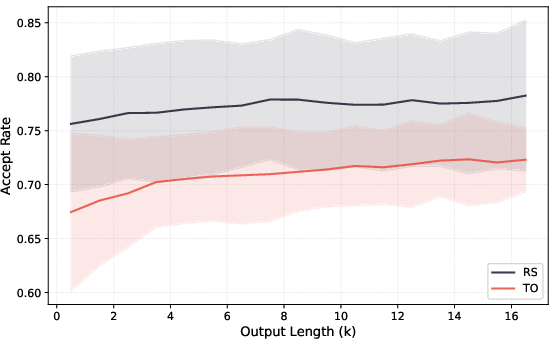
- Acceptance length: The expected number of tokens accepted per verification round in speculative decoding, determining throughput. "The expected number of accepted tokens per verification step, which we call the acceptance length, directly determines the inference throughput."
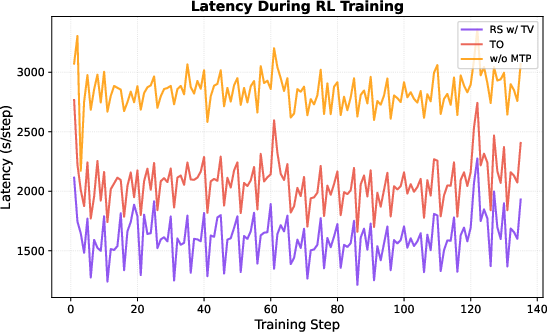
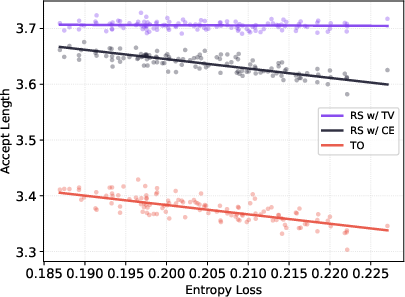
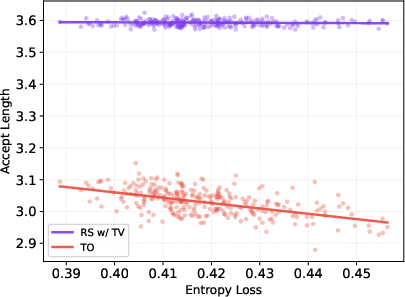
- Acceptance rate: The probability that a proposed (draft) token is accepted by the verifier; higher rates yield more speedup. "MTP acceptance rates degrade linearly with policy entropy fluctuation in RL; training MTP with our novel e2e TV loss largely eliminates this entropy dependence under rejection sampling."
- Agentic tasks: Tasks involving multi-step, tool-using, or autonomous agent behaviors (e.g., code editing with tools). "achieving up to 95\% acceptance rates and up to 25\% extra inference throughput gains across mathematical reasoning, code generation, and agentic tasks (\S\ref{sec:mtp_training})."
- Asynchronous RL: An RL training setup where rollout, reward, and update stages run concurrently to reduce latency. "Although recent progress in asynchronous RL frameworks~\citep{fu2025areal,wang2025roll,slime2025} can partially alleviate long-tail latency issues"
- Backbone (model): The main target LLM whose distribution the draft heads approximate. "Let denote the target (backbone) model's next-token distribution at position "
- Clipped surrogate objective: A PPO-style objective that clips policy updates to stabilize training. "and optimizes the clipped surrogate objective:"
- Cross-entropy (CE) loss: A standard loss minimizing divergence between target and draft distributions for next-token prediction. "Conventional MTP training minimizes the cross-entropy (CE) loss or the KL divergence between the target and draft distributions."
- Distribution mismatch: The divergence between the evolving target model distribution and the (often frozen) draft model distribution. "Recent work~\citep{minimax2026forge,chen2025respec,li2025mtp} primarily attributes this degradation to distribution mismatch."
- Draft head: A lightweight module that predicts future tokens ahead of the backbone to enable speculative decoding. "Multi-Token Prediction (MTP) augments autoregressive LLMs with lightweight draft heads that sequentially predict multiple future tokens"
- Draft-then-verify paradigm: A speculative decoding process where multiple tokens are drafted and subsequently verified in one pass by the target model. "During inference, MTP operates in a draft-then-verify paradigm"
- Effective support size: The number of tokens with non-negligible probability mass, scaling with the distribution’s entropy. "Since the effective support size scales as $|\mathcal{S}_{\mathrm{eff}| \approx \exp(\mathcal{H}(p))$"
- End-to-end TV loss: A multi-step objective that directly maximizes expected acceptance length by minimizing compounded TV distances across steps. "and therefore we propose a novel end-to-end TV loss that directly optimizes multi-step rejection sampling acceptance rate"
- Entropy (target entropy): A measure of uncertainty in the model’s next-token distribution; higher entropy generally lowers acceptance under some methods. "We define the target entropy as:"
- Forward KL divergence: The divergence measuring how well the draft matches the target; often used in training. "Throughout this paper, ``KL'' refers to the forward KL divergence $D_{\mathrm{KL}(p\|q)$ unless otherwise noted."
- GRPO: An RL algorithm variant that samples groups of trajectories and uses group-normalized advantages with clipping. "We adopt GRPO~\citep{grpo}, which samples a group of trajectories"
- Group-normalized advantage: An advantage term normalized within a sampled group to stabilize learning signals. "and is the group-normalized advantage."
- Importance sampling ratio: The ratio between current and behavior policy probabilities used to correct off-policy sampling. "where $r_{i,t} = \pi_\theta(y_{i,t} | x, y_{i,<t}) / \pi_{\theta_{\mathrm{old}(y_{i,t} | x, y_{i,<t})$ is the importance sampling ratio"
- Jensen's inequality: A convexity inequality used here to relate entropy to maximum probability mass. "By Jensen's inequality applied to the concave logarithm,"
- KL divergence: A measure of discrepancy between two probability distributions, often optimized during training. "However, the rejection sampling acceptance rate is determined by the TV distance (Eq.~\eqref{equ:rs_tv}), not the KL divergence."
- Megatron: A large-scale distributed training framework for transformer models. "training for 1 epoch with Megatron~\citep{shoeybi2020megatronlm}"
- Multi-Token Prediction (MTP): A speculative decoding technique where multiple future tokens are drafted before verification to accelerate inference. "Although Multi-Token Prediction (MTP) offers a natural solution to accelerate rollouts through speculative decoding"
- Partial rollout frameworks: Systems that split or pipeline rollouts to mitigate straggler effects and reduce training latency. "The asynchronous RL or partial rollout frameworks are commonly adopted to mitigate the bubble overhead caused by long-tail trajectories during rollout~\citep{fu2025areal,wang2025roll,slime2025,qin2025seer,minimax2026forge}."
- Pinsker's inequality: An inequality relating TV distance to KL divergence, providing an upper bound on TV. "By Pinsker's inequality, $d_{\mathrm{TV}(p,q) \leq \sqrt{D_{\mathrm{KL}(p\|q)/2}$"
- Policy entropy: The entropy of the policy’s output distribution, often increased to encourage exploration. "MTP acceptance rates degrade linearly with policy entropy fluctuation in RL"
- Policy gradient methods: Optimization methods that update policies directly via gradients of expected return. "and (3) update optimizes the policy inside a training engine using policy gradient methods."
- Reinforcement learning (RL): A learning paradigm where an agent optimizes actions by maximizing expected rewards through trial and feedback. "Reinforcement learning (RL) has become a key component in modern LLMs"
- Rejection sampling: A method that accepts a draft token with probability to ensure unbiased samples from the target. "Under rejection sampling \citep{leviathan2023fast,chen2023accelerating}, a draft token is accepted with probability ."
- Residual distribution: The re-normalized target distribution over tokens excluding the rejected draft token, used for unbiasedness. "the output token is resampled from the residual distribution $p_{\mathrm{resid}(y) \propto p(y)\,\mathbbm{1}[y \neq \hat{y}]$"
- Reverse KL divergence: The divergence emphasizing mode-seeking behavior of the draft relative to the target. "Reverse KL loss: Reverse KL divergence $D_{\mathrm{KL}(q \| p)$ (Eq.~\eqref{eq:rkl_gradient});"
- Rollout: The inference stage in RL where trajectories are generated by the current policy for training. "the rollout stage remains the key bottleneck in RL training pipelines."
- SGLang: An inference framework used here for efficient MTP with rejection sampling. "The throughput is measured using SGLang's MTP implementation with rejection sampling"
- Softmax: The function mapping logits to a probability distribution over tokens. "with ."
- Speculative decoding: An acceleration technique that drafts multiple tokens and later verifies them to reduce inference latency. "As an effective paradigm of speculative decoding~\citep{leviathan2023fast,chen2023accelerating}"
- Target-only sampling: An acceptance method that greedily drafts the top token and accepts it with the target model’s probability. "Under target-only sampling, the draft token is selected greedily as and accepted with probability "
- Total Variation (TV) distance: A metric of distributional difference equal to half the L1 distance; directly governs RS acceptance. "where $d_{\mathrm{TV}(p, q) = \frac{1}{2}\sum_{y} |p(y) - q(y)|$ is the Total Variation distance~\citep{levin2017markov}."
- TV loss: A training objective that minimizes TV distance to directly improve rejection sampling acceptance. "TV loss avoids these pitfalls by directly optimizing the acceptance-relevant quantity and producing a probability-proportional mismatch that decouples acceptance from target entropy."
Collections
Sign up for free to add this paper to one or more collections.