- The paper introduces a novel IB-Score metric that quantifies the balance between conditional entropy and mutual information to guide policy optimization.
- It integrates the IB-Score into a tree-based sampling framework (IB-TPO) that increases unique trajectory generation by 50% while outperforming GRPO by up to 3.6%.
- Empirical and theoretical analyses demonstrate that IB-TPO stabilizes RL training in LLMs, ensuring efficient token usage and consistent performance improvements.
Introduction
This paper addresses the persistent challenge of achieving exploration–exploitation balance in online reinforcement learning (RL) for LLMs. Existing RL methods for LLM post-training, notably Group Relative Policy Optimization (GRPO), either stagnate due to over-exploitation or suffer from unstable optimization when promoting naive entropy-driven exploration. The authors propose a principled framework employing the Information Bottleneck (IB) theory to analyze, quantify, and guide the exploration–exploitation trade-off during policy optimization. The core innovations include a novel metric—IB-Score—and the integration of this metric into a tree-based sampling and optimization framework, dubbed IB-TPO.
Most online RL approaches sample reasoning trajectories independently, which leads to premature convergence (Figure 1) and a sharp decrease in effective exploration as entropy vanishes. Attempts to regularize with higher entropy can result in unstable optimization. Empirically, the authors show that both clip-higher and entropy regularization augmentations to GRPO fail to improve performance or effective sampling rates over training.
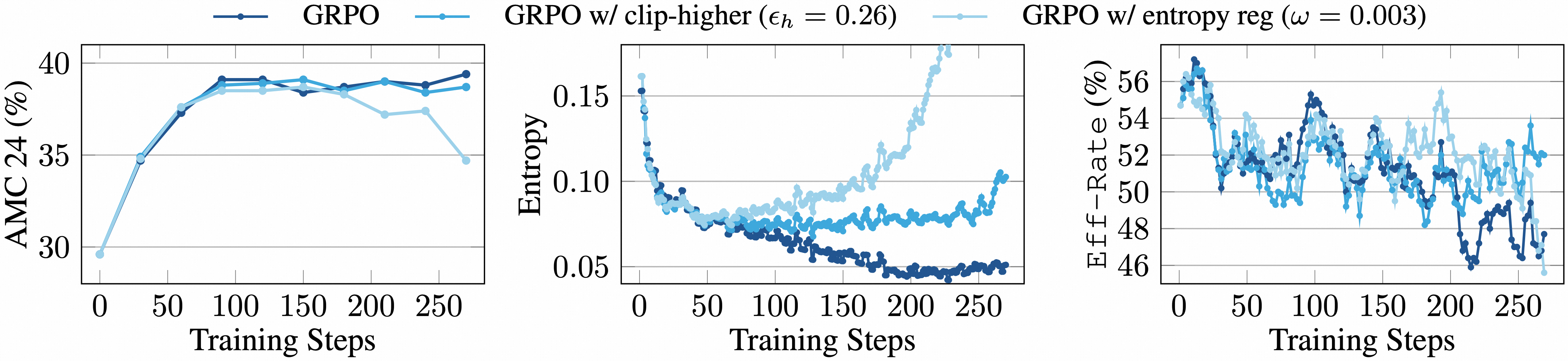
Figure 1: Training dynamics of GRPO baselines using Qwen3-8B-Base. Eff-Rate denotes the proportion of effective sampled groups with non-zero reward variance. Both clip-higher and entropy regularization fail to improve performance.
To theoretically elucidate these limitations, the paper adapts IB theory to RL for step-wise reasoning chains in LLMs. Building on mutual information approximations, the authors derive the IB-Score:
- The IB-Score quantifies the trade-off between conditional entropy over reasoning steps (diversity/exploration) and the mutual information each step shares with the correct answer (effective exploitation).
- Empirically, they show that GRPO and related baselines quickly lose positive covariance between “information gain” (η1) and policy confidence (η2), leading to suboptimal allocation of exploration versus exploitation (Figure 2).
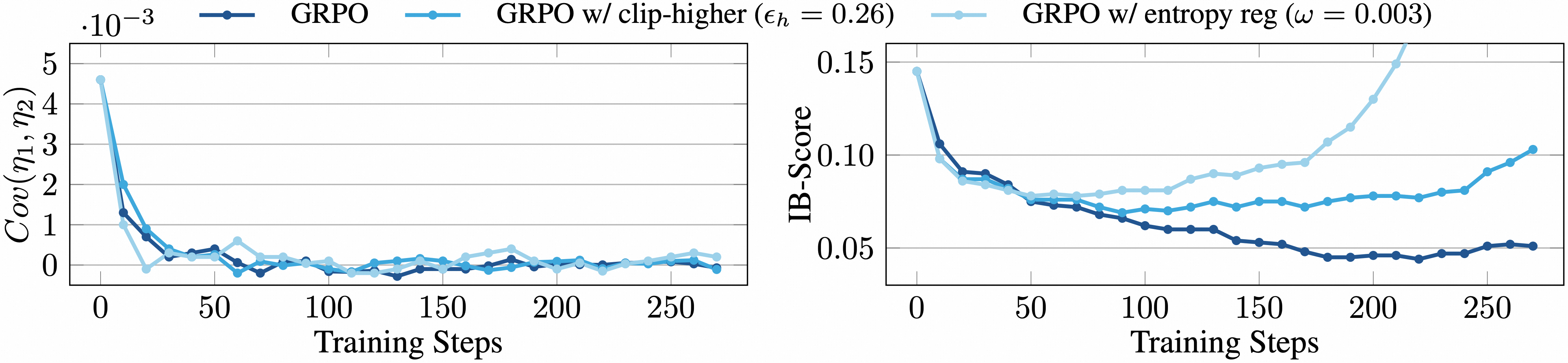
Figure 2: Training dynamics of Cov(η1,η2) and IB-Score for GRPO baselines. We use Qwen3-8B-base and β=5.
This analysis demonstrates that effective training requires not just increasing entropy but aligning confidence with informative paths, a property measured by IB-Score rather than entropy alone.
Figure 3: Striking an effective balance between exploration and exploitation remains a key challenge in online RL. We propose IB-Score to evaluate and encourage balanced policy optimization.
IB-Score: Definition and Efficient Estimation
The authors define a step-wise IB-Score:
- It is a function of both the diversity of model reasoning steps and their expected contribution to reaching the correct answer.
- Monte Carlo rollouts and surrogate entropy measures (e.g., Tsallis entropy) are leveraged for estimation stability.
Crucially, the IB-Score is explicitly factorizable into a product of environmental informativeness and policy confidence, enabling targeted optimization of confidence allocation rather than blanket uncertainty maximization.
The proposed IB-TPO framework integrates IB-Score as a fine-grained optimization objective and overcomes the sampling inefficiency of independent trajectories with an IB-guided tree search (IBTree):
- The reasoning tree expands from the problem root. At each iteration, nodes with the highest IB-Scores are selectively branched, which maximizes rollout efficiency and the expected exploration-exploitation benefit (Figure 4).
- The IBTree structure enables reusing shared prefixes, allowing 50% more unique trajectories under the same token budget compared to independent sampling.
- Step-level advantages are computed using both local and global reward densities, with the overall policy gradient incorporating the IB-Score-based advantage.
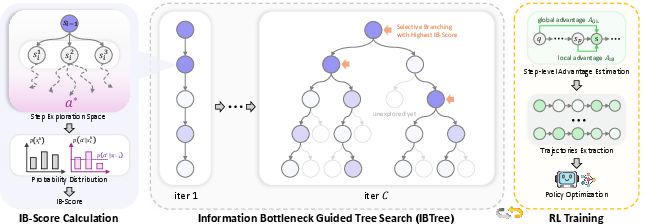
Figure 4: Overview of our method. We initialize IBTree with a given problem, then perform tree expansion in multiple iterations. In each iteration, we calculate the IB-Score of each node based on existing rollouts from it, and selectively branch at nodes with highest IB-Scores to improve exploration efficiency and effectiveness. After expansion, we compute global advantage and IB-based local advantage for each node, then optimize the policy model using step-level advantages.
Empirical Results
Comprehensive experiments on Qwen3-1.7B and 8B variants and challenging mathematical and out-of-domain benchmarks show strong empirical results. IB-TPO consistently outperforms GRPO and all state-of-the-art baselines, with performance gains of 2.9–3.6% over GRPO. The method produces higher validation accuracy and achieves superior pass@K scores, reflecting both increased diversity and quality in model reasoning.
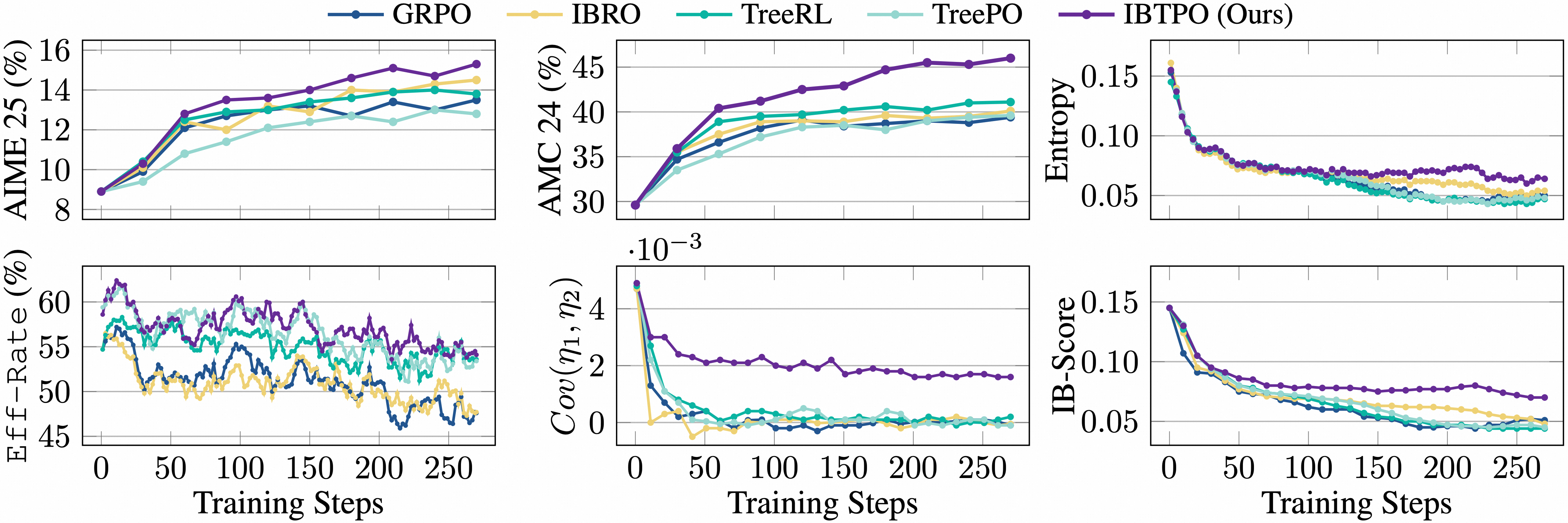
Figure 5: Training dynamics of our method compared with state-of-the-art approaches using Qwen3-8B-base.
Ablation studies substantiate that both the IB-guided exploration (via IBTree) and the advantage estimation are critical—altogether yielding the best accuracy and exploration rates under constant token constraints. IBTree is shown to be effective not only in maximizing coverage (eff-rate) and yielding higher accuracy, but also in reducing wall-clock time with modern inference accelerators for parallel sampling.
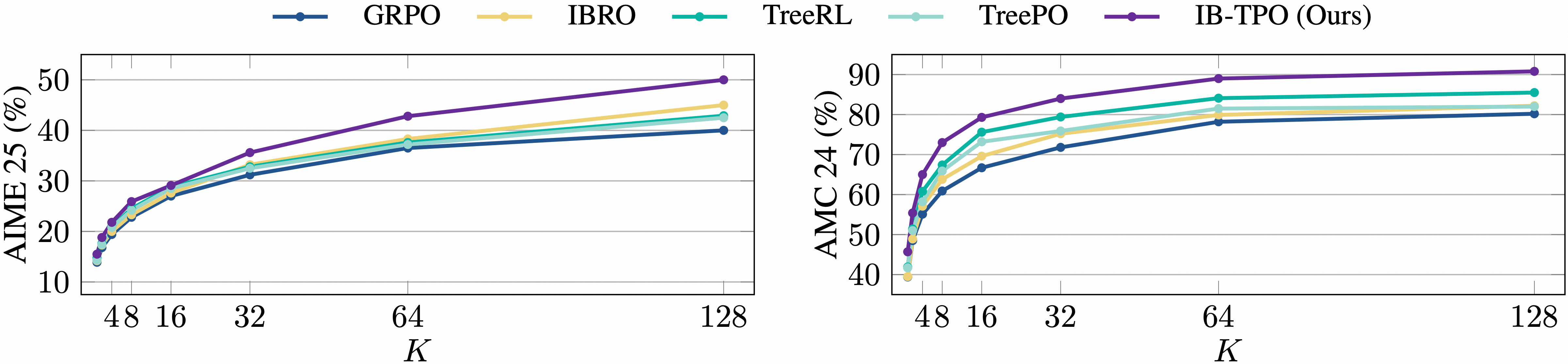
Figure 6: Comparison of pass@K accuracy trained on Qwen3-8B-Base.
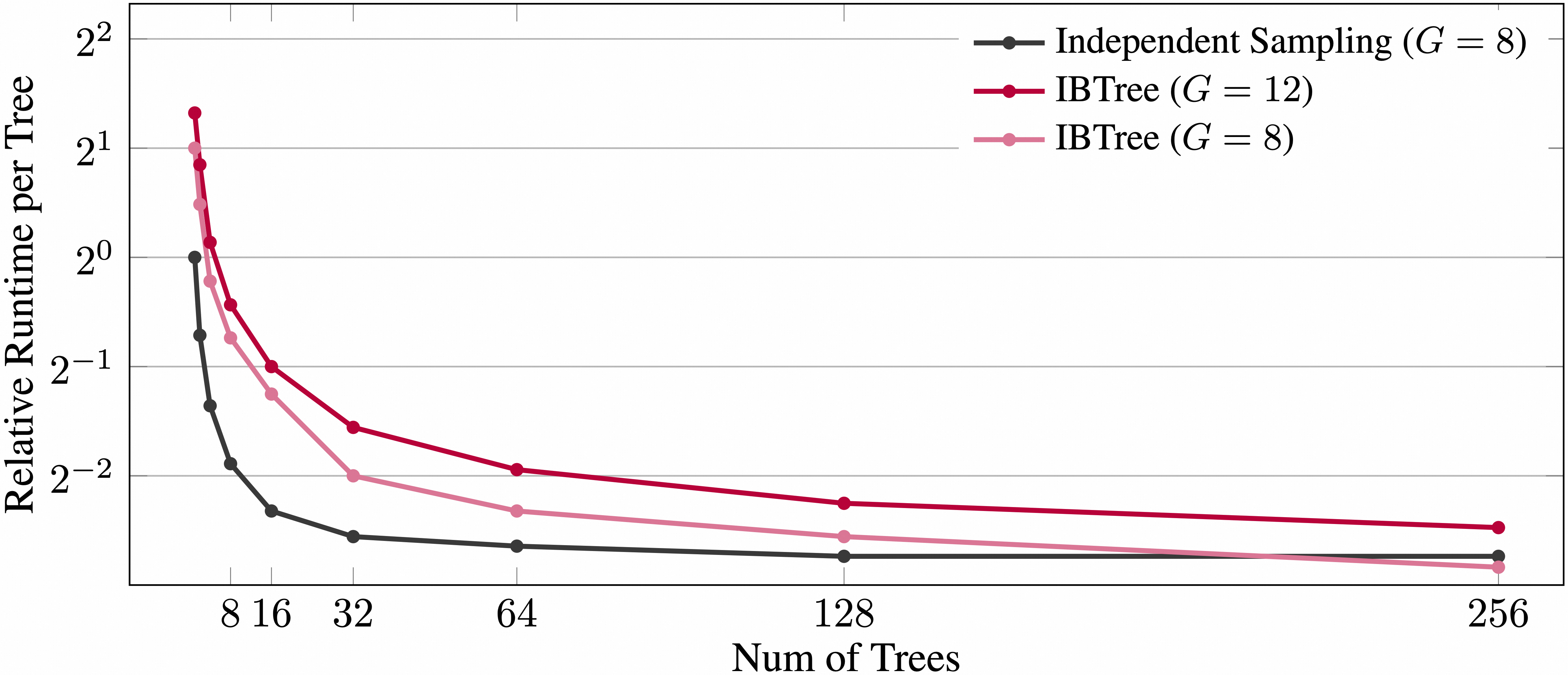
Figure 7: Comparison of wall-clock time consumption with respect to the number of trees sampled in parallel. For ease of comparison, we set the time consumption of independent sampling on single tree as baseline (1.0).
Practical and Theoretical Implications
Practically, IB-TPO enables the efficient post-training of LLMs for domains requiring deep, step-wise reasoning (e.g., mathematics, code generation) and is readily scalable to larger models and longer contexts. The explicit IB-Score guidance avoids both entropy vanishing and explosion, ensuring stable and effective RL convergence.
Theoretically, formalizing the exploration-exploitation trade-off via the IB principle provides a solid foundation for future RL algorithm design, making clear how confidence and informativeness must be jointly optimized. IB-TPO’s tree-based estimation also lays groundwork for more sophisticated search-guided RL in discrete action spaces, and can extend to multi-modal or function-calling domains.
Directions for Further Research
Future work will address remaining efficiency gaps in tree-based sampling, particularly when extending to very large reasoning spaces or long-context tasks. The IB-TPO principle is adaptable to other forms of structured exploration and potentially to off-policy settings or multimodal RL, as well as to domains with even sparser rewards.
Conclusion
The paper presents a unified framework for online RL in LLMs capable of robustly balancing exploration and exploitation. The IB-Score diagnoses policy imbalance at a fine reasoning-step granularity, and the IB-TPO method leverages this signal in a principled, efficient way via guided tree sampling. Experiments establish the method’s superiority over multiple strong baselines. This information-theoretic approach points to a promising trajectory for RL advances in LLM reasoning and general agentic problem solving.