Beat the long tail: Distribution-Aware Speculative Decoding for RL Training
Abstract: Reinforcement learning(RL) post-training has become essential for aligning LLMs, yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper tackles a big slowdown in training LLMs with reinforcement learning (RL). When models are trained with RL, they must “roll out” answers by generating tokens one-by-one for many prompts. A few very long generations take much longer than the rest and end up controlling how long the whole training step takes. The authors propose a new system called DAS (Distribution-Aware Speculative decoding) that speeds up these slow rollouts without changing the model’s actual outputs or the quality of training.
Key Objectives
The paper asks simple, practical questions:
- Can we speed up RL training by making the rollout (token generation) phase faster?
- How do we deal with the “long tail,” where a small number of very long responses slow down everything?
- Can we use what the model generated in recent training steps to guess future tokens more accurately?
- How do we decide which prompts deserve more “guessing effort” to reduce total time the most?
Methods and Approach (with everyday explanations)
Think of generating text like writing a story, one word at a time. RL training needs to do this for many prompts before learning (updating the model) can continue. The problem: some stories are much longer and hold up the entire class.
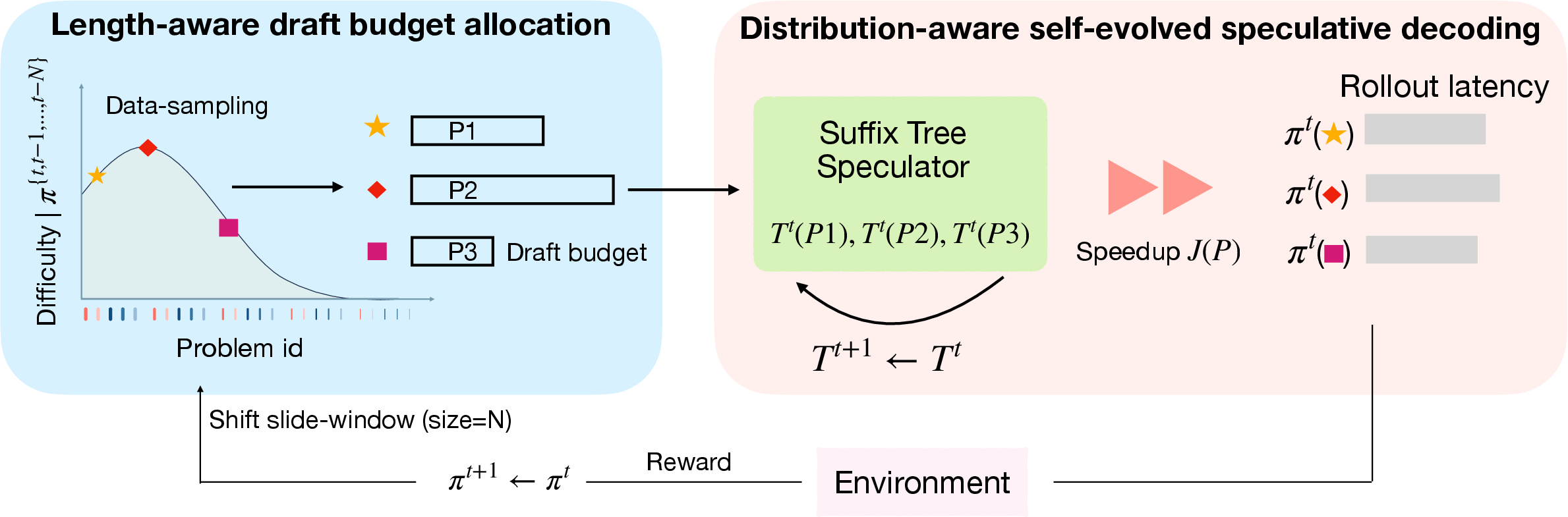
DAS uses speculative decoding, which is like having a helper quickly suggest several next words at once, and then the main author checks them in one go. If many of the helper’s suggestions are correct, the author can write faster. DAS combines two ideas:
- Adaptive drafter from recent history:
- Everyday analogy: Imagine your helper learns from the last few stories you wrote. If you often use certain phrases or patterns, the helper can suggest them again confidently.
- How it works: The system builds a “suffix tree,” a data structure that is like a compact map of past text fragments. When the model starts generating for a prompt, DAS looks up the longest matching piece in this map and proposes several likely next tokens in a row. Because it only uses very recent rollouts, it stays up-to-date as the model changes during training.
- Why not a fixed small “helper model”? In RL, the main model’s behavior shifts as it learns. A fixed helper gets out of sync and guesses worse over time. The suffix-tree approach updates itself quickly and cheaply.
- Length-aware speculation policy:
- Everyday analogy: If you’re juggling many essays, spend more helper time on the longest ones so the whole class finishes sooner.
- How it works: DAS predicts which prompts are likely to produce long answers (using recent history and what it has seen so far in the current generation). It then gives those longer prompts a bigger “draft budget” (more speculative tokens), and gives short prompts little or none. This focuses effort where it cuts the most waiting time.
- Balance of costs: The paper models the time taken per “check” (a forward pass of the model) and per token. The goal is to reduce both the number of checks and the total tokens processed. Proposing too many speculative tokens can backfire by adding overhead, so DAS tunes the budget smartly.
Technical terms explained simply:
- Rollout: The model’s process of writing an answer step-by-step during training.
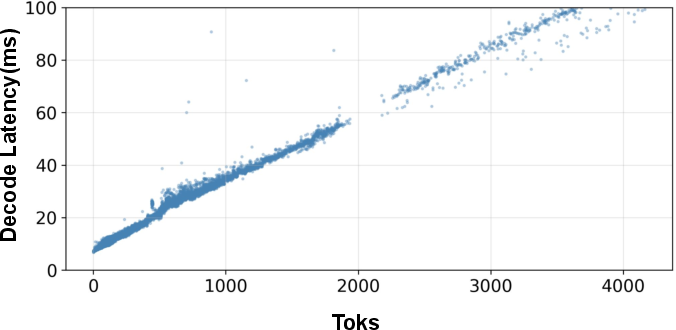
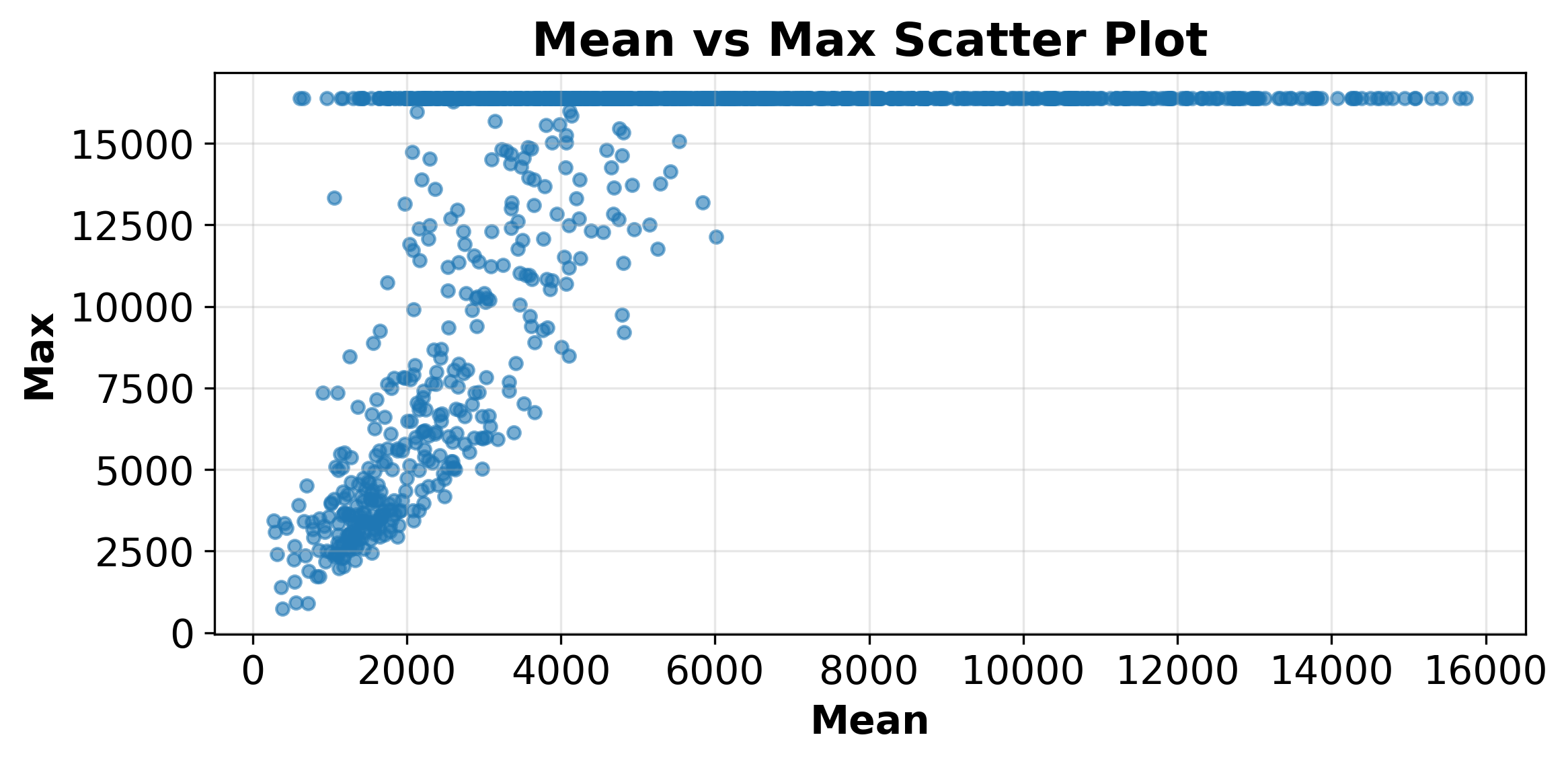
- Long tail: A small number of very long answers that drag down total time.
- Speculative decoding: Fast guesses of multiple next tokens, quickly verified by the main model.
- Suffix tree: A compact “memory” of recent text, used to find matching patterns and propose likely continuations.
- Acceptance rate: How many drafted tokens get confirmed by the main model. Higher is better (fewer checks, faster runs).
Main Findings and Why They Matter
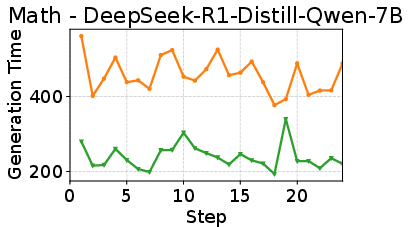
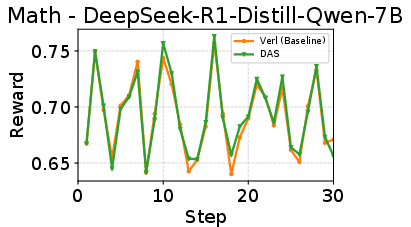
- Faster rollouts, same training quality:
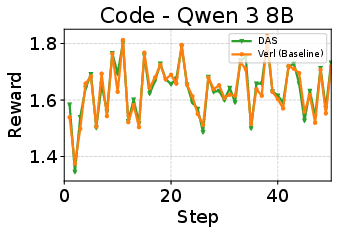
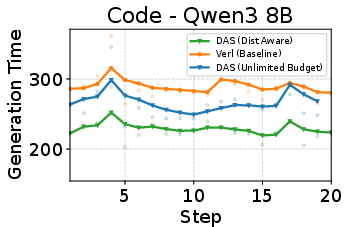
- On math reasoning tasks, DAS reduced rollout time by up to about 50% without changing rewards or final accuracy.
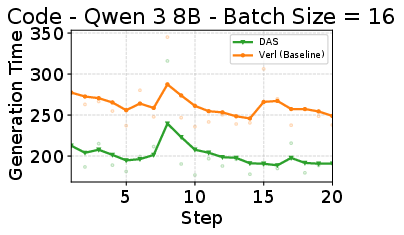
- On code tasks, DAS cut rollout time by about 25% with similar training quality.
- This is important because rollout often takes more than 70% of RL training time. Cutting it in half can make RL training much more practical at scale.
- History helps:
- Using recent generations to build the suffix tree kept the drafter aligned with the model as it learned, leading to more accepted tokens per check (faster decoding).
- Focus on long prompts:
- Giving more speculative budget to long, hard prompts sped up the “makespan” (the total time until all prompts finish in a training step). Blindly speculating everywhere or allowing unlimited speculation was worse because it added overhead and wasted checks.
- Robust across settings:
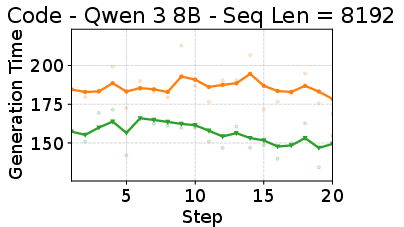
- DAS still sped up training when sequence length limits or batch sizes changed, showing it works in different practical configurations.
Implications and Potential Impact
Training large reasoning-capable LLMs with RL is powerful but increasingly time-consuming. By cutting rollout time significantly without changing model outputs, DAS:
- Makes RL post-training faster and cheaper, especially for reasoning-heavy tasks with long answers (like math and code).
- Improves hardware usage during training (less idling while waiting for long stragglers).
- Offers a simple, training-free helper: no need to retrain a separate draft model, just build and update a suffix tree from recent runs.
- Encourages systems that adapt to the model’s evolving behavior during RL, leading to stable speedups over time.
In short, DAS shows that being “distribution-aware” (knowing which prompts are long and using recent history to guess well) can beat the long tail and make RL training much more efficient—without compromising learning quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Distribution-preservation under stochastic sampling is not formally established: no proof or comprehensive empirical validation that speculative decoding preserves the output distribution under temperature sampling, top‑p, repetition penalties, and other logit processors commonly used in RL rollouts.
- Acceptance criteria and multi‑token verification details are under-specified: the paper does not describe the exact acceptance algorithm (e.g., mismatch handling, partial acceptance, resampling policies), making it unclear how correctness and distributional fidelity are enforced in practice.
- Closed-form budgeting parameters are not estimated: the optimization requires per-request parameters (, ), but the paper does not explain how these are estimated, validated, or used online; the deployed system instead relies on heuristics without comparing against the derived optimum.
- Length-class heuristic lacks accuracy and impact analysis: the Long/Medium/Short runtime classifier is not evaluated for prediction accuracy, misclassification rates, or sensitivity; its effect on speedup variability and rollout makespan is not quantified.
- Cold-start handling for unseen or rare problems is unspecified: when a prompt has little or no history, the behavior and performance of the suffix-based drafter (including fallback policies) are not assessed.
- Memory footprint and scalability of per-problem suffix trees are not reported: no measurements of memory overhead, limits with many prompts, large windows, or long contexts; no strategy for distributed maintenance or eviction under constrained memory.
- Query latency vs. prefix length is not characterized: although O(m) lookup is claimed, there is no empirical profiling of speculative/query latency as a function of context length m (especially with 16k+ tokens), nor worst-case bounds under realistic workloads.
- Adaptive window control lacks a principled policy: the “tie to optimizer step scale” heuristic is not formalized; no drift detection method, window resizing algorithm, or ablation comparing static vs. adaptive windows across tasks and models.
- Risk of drafting invalid or suboptimal continuations is not addressed: the system may match token-wise patterns from historically incorrect trajectories; no filtering, confidence calibration, or validity-aware scoring is proposed or evaluated.
- Interaction with RL exploration is unexplored: the impact of speculation on exploration diversity (e.g., entropy bonuses, temperature schedules, multi-sample diversity) and downstream policy optimization stability is not measured.
- Generalization across RL algorithms and training regimes is unclear: evaluation is limited to a specific framework; compatibility with PPO variants, GRPO settings, off‑policy/asynchronous training, and multi-agent setups remains untested.
- Tensor-parallel (TP) scaling and accelerator utilization are not analyzed: results focus on DP rollouts; no GPU utilization metrics, TP regime evaluation, or analysis of makespan reduction under different parallelism mixes.
- Environments with heavy reward computation are not considered: the method assumes rollout generation dominates; applicability to tasks where environment simulation or verification is the bottleneck (beyond the provided code RL setup) is not studied.
- Composition with other serving/training optimizations is unknown: integration with prefill-decode disaggregation, paged KV-cache, quantization, and scheduling policies (e.g., SLO-aware batching) is not explored; potential interference or synergies are unquantified.
- Token-level equality is not verified end-to-end: the claim of “identical outputs” is supported by reward curves but not by token-level trace comparisons across entire rollouts and sampling configurations.
- Training stability and sample efficiency effects are not measured: impacts on KL regularization, return variance, and convergence behavior are not reported, beyond reward parity.
- Resource fairness and scheduling implications are not addressed: the length‑aware budget prioritizes long prompts; potential starvation or degraded latency for short prompts, and policies for fairness or SLO compliance, are not discussed.
- Criteria for enabling/disabling prefix routing are ad hoc: the threshold for turning off the pre‑request prefix trie (due to CPU overhead) is not formalized; no automatic selection or cost model is provided.
- Data governance and privacy considerations are absent: storing and reusing historical rollouts (especially code) raises questions about sensitive content retention, access control, and compliance—none are discussed.
- Applicability to multi-turn dialogue/conversational RL is unknown: the approach is evaluated on single-turn math/code tasks; extension to multi-turn contexts with evolving states is not addressed.
- Cross-sample reuse within a prompt is not explored: with multiple samples per prompt, potential reuse across samples (and risks of homogenizing outputs) is neither leveraged nor analyzed.
- Formal drift detection and adaptation are missing: the system assumes recency bias but lacks a principled, model-agnostic drift estimator to guide window size and weighting.
- Hardware portability is untested: results are limited to H100 GPUs; performance, acceptance, and latency on A100s, consumer GPUs, CPUs, or mixed accelerators are unknown.
- End-to-end training time and energy reduction are not reported: measurements focus on rollout latency per step; net wall-clock training reductions (including learner, reward computation) and energy/cost savings are not quantified.
- Baseline coverage is limited: comparisons to self-speculative methods (e.g., SWIFT), online SD distillation, and serving-optimized goodput tuning are not provided; E2E fairness and memory/compute trade-offs are not systematically compared.
- Failure-mode handling is unspecified: when suffix drafts are frequently rejected (e.g., under rapid policy shift), the system’s fallback behavior, overhead impact, and recovery strategy are not detailed.
- Implementation specifics and reproducibility details are sparse: multi-token verification kernel design, batching policy, cache management, and system-level knobs needed to reproduce the reported speedups are not comprehensively documented.
Practical Applications
Immediate Applications
Below is a concise list of practical, deployable applications that directly leverage the paper’s findings and system design. Each item notes relevant sectors, potential tools/workflows, and key assumptions that affect feasibility.
- Faster RLHF/GRPO training pipelines for LLMs
- Sectors: software, cloud/AI platforms, finance, healthcare, education
- What emerges:
- A plugin/module that integrates DAS into existing RL post-training stacks (e.g., VeRL, OpenRLHF, vLLM)
- Length-aware draft budgeting policies in rollout managers to curb stragglers that dominate makespan
- Per-problem suffix-tree index maintained over a sliding window of recent rollouts
- Benefits: 30–50% rollout time reduction with identical training curves; lower compute cost per training step; faster iteration on reasoning-heavy domains (math, code)
- Assumptions/dependencies: Repeated prompts across epochs; availability of rollout history; target-model verification remains the same (lossless speculation); CPU/GPU balance such that suffix-tree query/update overhead doesn’t dominate; integration with vLLM or equivalent speculative kernels
- Managed “RL rollout accelerator” service for enterprises
- Sectors: cloud providers, AI platform vendors
- What emerges:
- A managed service tier offering distribution-aware speculative decoding for RL workloads
- Monitoring of acceptance rates, window sizes, and budget allocations; autoscaling of suffix-tree shards per problem
- Benefits: Immediate cost and latency reductions for customers training domain-specific LLMs; SLA improvements for time-to-train milestones
- Assumptions/dependencies: Multi-tenant isolation of rollout histories; data retention policies; compatibility with customer’s tokenization/LLM stacks; transparent lossless acceleration guarantees for compliance
- Cost- and energy-efficient training operations
- Sectors: energy/sustainability, finance (cost control), public sector IT
- What emerges:
- Energy and carbon accounting dashboards showing reduced GPU-hours for RL rollout phases
- CFO-level reporting of training cost savings via lowered wall-clock makespan
- Benefits: Reduced emissions and spend; more runs per budget; supports internal sustainability targets and procurement decisions
- Assumptions/dependencies: Accurate metering of compute/energy; long-tail generation skew present; acceptance rate sufficiently high to justify speculation overhead
- Academic experimentation at lower cost and higher throughput
- Sectors: academia, non-profit/open-source labs
- What emerges:
- An open-source library for suffix-tree-based, windowed, per-problem speculation
- Reproducible experiments with identical outputs (lossless verification) and greatly reduced rollout time
- Benefits: Enables broader hyperparameter sweeps and ablation studies on math/code reasoning RL; easier replication of results under limited budgets
- Assumptions/dependencies: Availability of rollouts, integration with common training frameworks (VeRL/OpenRLHF), and tolerance for minor engineering to plug in budget policies
- Domain-specific RL post-training where correctness is verifiable
- Sectors: code (DevTools, CI/CD), finance (compliance rule-checking), healthcare (clinical guideline adherence), education (grading and tutoring tasks)
- What emerges:
- RL loops that rely on verifiable rewards (e.g., unit tests, rules, rubrics) accelerated with DAS
- Workflow recipes for per-domain per-prompt suffix trees and sliding windows tuned to policy drift rates
- Benefits: Makes RL post-training feasible for organizations with limited compute; ensures safety by preserving output distribution while improving turnaround time
- Assumptions/dependencies: Strong reuse patterns across epochs; tasks with sufficient lexical/schematic repetition; operational guardrails for keeping history caches privacy-safe
- MLOps instrumentation for rollout-phase bottlenecks
- Sectors: MLOps tooling
- What emerges:
- Dashboards that track effective batch collapse, acceptance-per-verification-round, and latency components (base vs token cost)
- Automatic window-size tuning and length-class assignment (Short/Medium/Long) based on historical and runtime signals
- Benefits: Operational visibility and tuning knobs that translate directly to rollout speedups and better GPU utilization
- Assumptions/dependencies: Lightweight runtime length prediction; policy drift quantified; monitoring agents can run without introducing significant overhead
Long-Term Applications
These applications require further research, scaling, or productization but are well-motivated by the paper’s framework and results.
- History-aware speculative serving for enterprise workloads with recurring prompts
- Sectors: customer support, internal IT, finance/insurance ops, healthcare administration
- What could emerge:
- Per-tenant or per-workflow suffix-tree caches for repeated queries
- Length-aware draft budgets tuned to SLA (TTFT/TPOT) trade-offs
- Benefits: Reduced tail latency for known, recurring request types; improved throughput while preserving outputs
- Assumptions/dependencies: Sufficient recurrence; robust privacy isolation; policies for cache aging and drift handling; adaptation of RL-specific heuristics to serving constraints
- Generalization to multimodal and action-sequence RL
- Sectors: robotics, autonomous systems, multimodal tutoring
- What could emerge:
- “Trajectory-aware” speculation using nonparametric structures over mixed token/action sequences
- Suffix-tree-like indexes for action/state sequences with verification by the current policy
- Benefits: Potentially accelerates rollouts in simulation-heavy RL tasks; faster iteration in language-conditioned control
- Assumptions/dependencies: Verifiable rollout segments; suitable data structures for mixed modalities; stable acceptance semantics beyond text tokens; high-quality simulators
- On-device or edge personalization via efficient RL post-training
- Sectors: mobile, IoT, embedded systems
- What could emerge:
- Lightweight speculative structures for small models enabling continual, privacy-preserving on-device RL post-training
- Personalized tutors or assistants updated with minimal energy cost
- Benefits: Faster personalization cycles; improved privacy by keeping data local
- Assumptions/dependencies: Small LLMs amenable to on-device RL; memory-efficient suffix indexes; energy constraints; high acceptance from local history
- Automated cluster-level rollout schedulers that co-optimize speculation budgets and makespan
- Sectors: cloud/AI platforms, HPC systems
- What could emerge:
- Schedulers that use the paper’s latency model (base vs token cost) to assign speculative budgets, route requests to shards, and minimize global makespan
- Cross-node coordination for per-problem history indexes
- Benefits: System-wide reduction of straggler impact; improved utilization across heterogeneous clusters
- Assumptions/dependencies: Accurate real-time telemetry for length and acceptance; scalable distributed suffix-tree maintenance; integration into Slurm/Kubernetes/Ray
- Theory-guided autotuning of speculation parameters
- Sectors: research, MLOps tooling
- What could emerge:
- Estimators for accept-efficiency (α) and capacity (k) per request/problem to optimize budgets using closed-form solutions
- Confidence bands and robust control for non-stationary policies
- Benefits: Removes manual tuning; maximizes speedups under changing policy distributions
- Assumptions/dependencies: Reliable estimators; safe exploration strategies for budget changes; guardrails to avoid overhead spikes
- Privacy/security hardening of rollout-history caches
- Sectors: healthcare, finance, public sector
- What could emerge:
- Encrypted, access-controlled storage for per-problem histories; differential privacy mechanisms for speculative indexes
- Auditability features ensuring lossless verification and no unintended distribution shift
- Benefits: Compliance with strict data-handling standards; safe deployment of history-driven speculation in regulated environments
- Assumptions/dependencies: Robust cryptographic pipelines; clear policies for retention windows and route selection; performance overhead acceptable
- Standardized benchmarks and governance frameworks for “lossless acceleration”
- Sectors: policy, standards bodies, research consortia
- What could emerge:
- Benchmarks that separate training fidelity from rollout efficiency; reference implementations of DAS-like methods
- Procurement guidelines prioritizing energy-efficient RL training that preserves outputs
- Benefits: Encourages industry-wide adoption of provably lossless acceleration; aligns incentives for sustainable AI
- Assumptions/dependencies: Consensus definitions of “lossless” and acceptable variance; collaboration across vendors and labs; evolving best practices as models grow
- Productized acceptance monitoring and observability suites
- Sectors: MLOps SaaS
- What could emerge:
- Tooling that visualizes acceptance-per-round, window staleness, per-request length-class transitions, and speculative overhead impacts
- Benefits: Practical guardrails and diagnostics to keep speedups high in dynamic training regimes
- Assumptions/dependencies: Low overhead agents; access to rollout metadata; consistent tokenization and logging across training stacks
In all cases, the central idea is to exploit rollout history and long-tail behavior during RL training to reduce makespan without changing model outputs. This naturally favors workloads with repeated prompts across epochs and verifiable rewards, and it benefits most in regimes where long generations dominate latency and batch collapse exposes idle capacity that speculation can reclaim.
Glossary
- Actor–learner RL pipeline: An RL training architecture where actors generate trajectories and a learner updates the policy. "Integrating and continuously re-calibrating these components inside an actorâlearner RL pipeline, where checkpoints evolve over time, is considerably more complex than the intended inference-only use case."
- Autoregressive generation: Token-by-token sequence generation where each token depends on previous ones. "RL post-training generally follows three phases: generation of trajectories (autoregressive generation); preparation of trajectories, such as reward labeling; and training."
- Base cost (per-pass cost): The fixed overhead incurred by each forward pass during decoding. "The term $c_{\mathrm{base}$ captures per-pass overheads such as moving parameters/activations (global shared memory), kernel launches, and temporary allocations."
- Capacity factor: A parameter bounding the maximum fraction of tokens the drafter can have accepted. "drafter capacity factor , which denotes the maximal achievable fraction of accepted tokens for request ."
- Data-parallel (DP): A parallelism strategy that replicates the model across workers to process different data partitions concurrently. "In practice, systems like VeRL and OpenRLHF favor data-parallel (DP) rollout workers to scale decoding throughput, resorting to tensor-parallelism (TP) if the training model cannot fit into memory."
- Distribution-aware speculative decoding: Speculative decoding that tailors draft budgets to request length distribution to reduce straggler latency. "we propose DAS, a Distribution-Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs."
- Draft budget: The number of speculative tokens proposed per verification cycle. "we propose a distribution-aware speculative decoding method that allocates draft budget preferentially to high-difficulty, long-horizon prompts, those that dominate the rollout makespan rather than speculating uniformly."
- Drafter: The component that proposes speculative tokens for the target model to verify. "we propose an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree"
- EAGLE-2: A serving-time speculative decoding technique using a learned head to build a dynamic draft tree. "EAGLE-2 in particular depends on a well-calibrated drafter whose confidence closely predicts token acceptance, and it grows a dynamic draft tree accordingly"
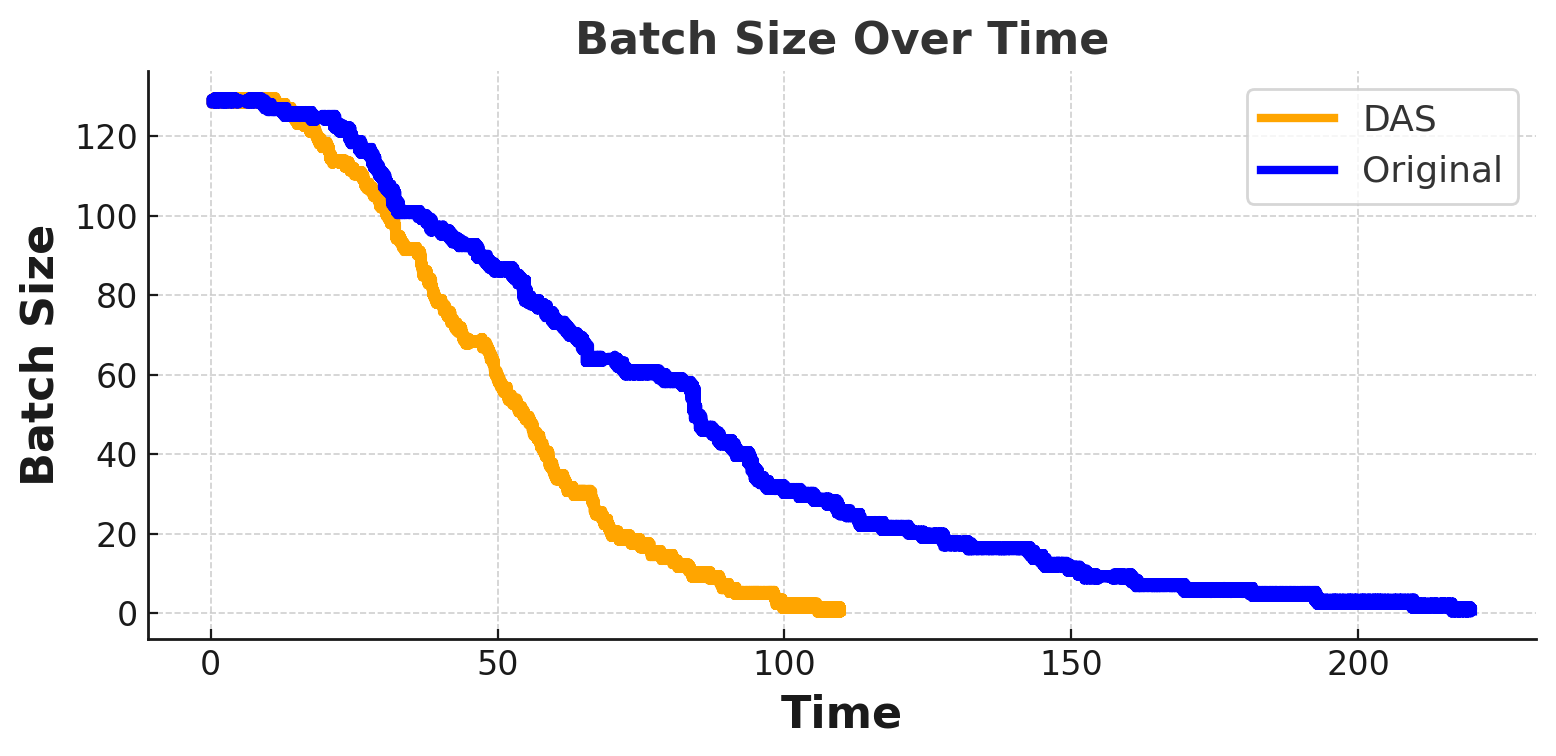
- Effective batch size: The number of active sequences being decoded concurrently; it shrinks as shorter sequences finish. "As decoding progresses, short sequences finish first and the effective batch size shrinks, leaving a few long stragglers to determine the step makespan."
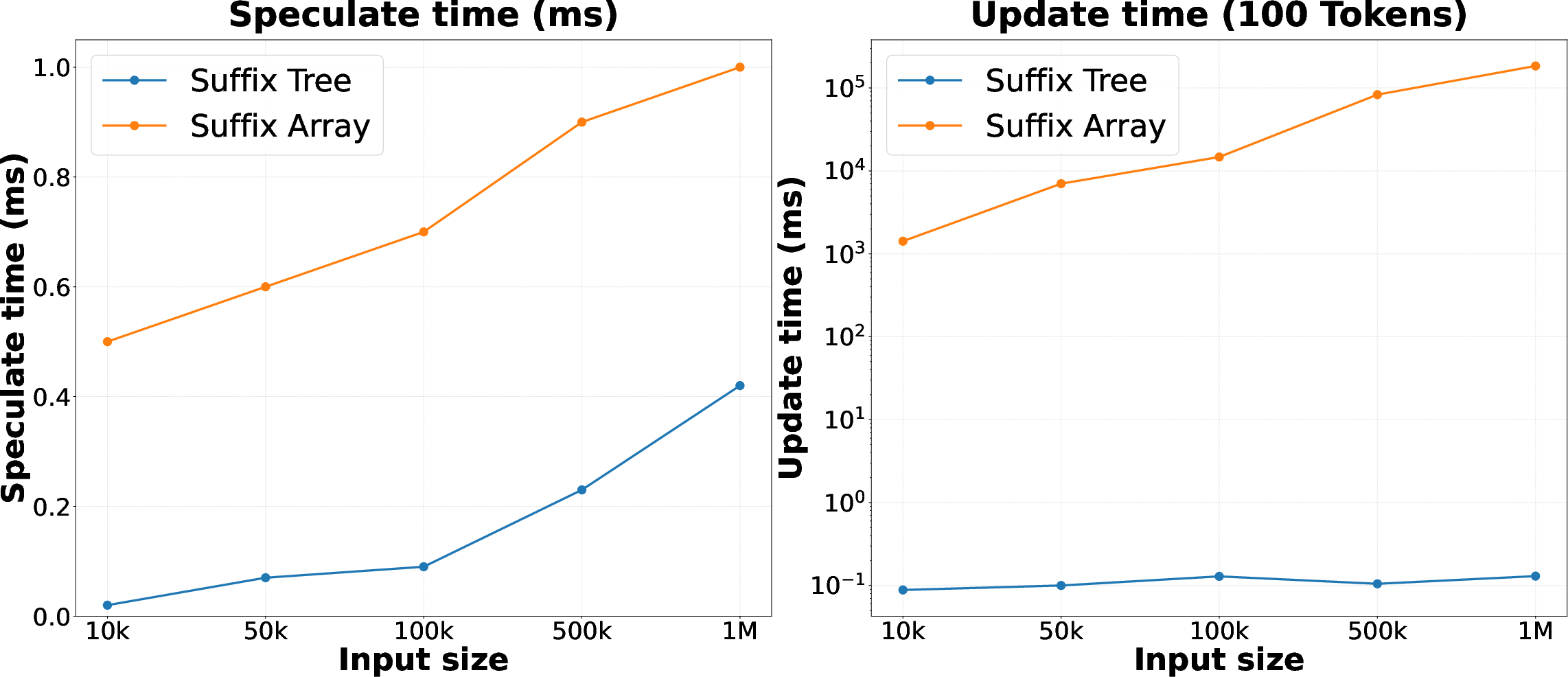
- Enhanced suffix array (ESA): A suffix-array variant supporting efficient pattern matching comparable to suffix-tree traversal. "using an enhanced suffix array (ESA)~\citep{abouelhoda2004replacing} enables pattern matching in time by effectively simulating suffix-tree traversal with better constants and cache locality."
- Goodput: Effective throughput accounting for useful accepted tokens per unit compute. "Liu~\cite{liu2024optimizing} defines goodput as the effective throughput and employs simulation-based search"
- GRPO: A reinforcement learning optimization method used for training LLMs. "the policy update step itself (e.g., GRPO ~\citep{guo2025deepseek} optimization in frameworks such as VeRL~\citep{sheng2024hybridflow}) is left unchanged."
- LCP array: Longest Common Prefix array used with suffix arrays to reduce comparisons in substring search. "Augmenting the SA with an LCP array~\citep{kasai2001linear} reduces the number of comparisons"
- Lenience parameter: A relaxation applied during acceptance that changes the output distribution. "SPEC-RL~\cite{liu2025specrl} uses prior trajectories as drafts, but introduces a lenience parameter for acceptance that changes the output distribution."
- Long-tail distribution: A distribution where a small fraction of long sequences dominates computation time. "the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall-clock time"
- Makespan: The total time to complete all sequences in a step, determined by the longest stragglers. "allocates more aggressive draft budgets to long trajectories that dominate makespan."
- Nonparametric drafter: A drafter not based on trained parameters, typically built from symbolic or retrieval structures. "we propose an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree"
- Non-stationary policy: A policy that changes over time due to continuous training updates. "In RL training, however, the policy is non-stationary: model weights change after every learner update"
- On-policy RL training: Training where data is gathered from the current policy in synchronous iterations. "whereas in synchronous on-policy RL training, longer generations dominate total latency while shorter ones contribute little."
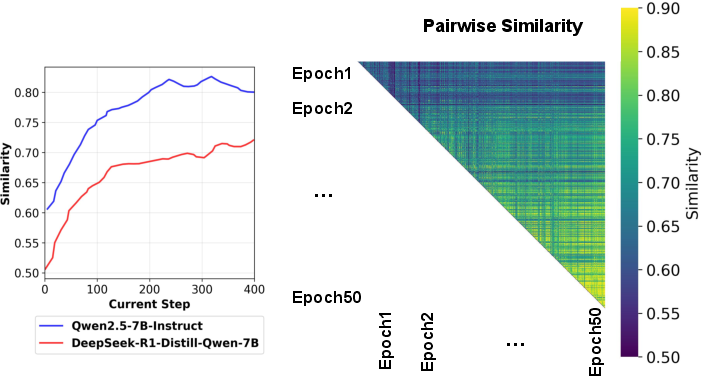
- Policy drift: The change in model behavior over training epochs causing older rollouts to become less predictive. "This reflects policy drift: as the policy is continually updated, older generations become less predictive of current behavior."
- Prefill-decode disaggregation: A serving optimization that splits the initial context processing (prefill) from token-by-token decoding. "prefill-decode disaggregation~\citep{zhong2024distserve}"
- Prefix trie: A tree structure used to route requests based on shared starting substrings. "we adopt a per-request suffix tree together with a lightweight pre-request prefix trie for routing."
- Problem difficulty-awareness: Sensitivity to prompt hardness to avoid speculating on misleading but similar trajectories. "Problem difficulty-awareness is important for efficiently decoding valid trajectories and not token-wise similar invalid ones."
- Self-speculative approaches: Methods that reuse the target model itself to generate drafts by skipping layers. "Self-speculative approaches eliminate external drafters by reusing the target model with layer skipping; later work (SWIFT) makes this selection adaptive at run time, avoiding offline tuning."
- Sliding window: A recency-based selection strategy for maintaining history used by the drafter. "We therefore construct the drafter from a sliding window of recent trajectories and refresh the index for each iteration."
- Speculator: A component that proposes multi-token drafts from historical suffix matches for verification. "we maintain a suffix tree speculator that is incrementally updated from most recent rollouts."
- Speculative decoding: A technique that proposes multiple tokens for parallel verification to reduce latency without altering outputs. "Speculative decoding~\cite{leviathan2023fast} accelerates autoregressive generation by trading additional computation for reduced latency."
- Suffix array (SA): An array of sorted suffixes used for efficient substring search. "A standard SA supports the search for substrings by binary search in time for a pattern of length "
- Suffix tree: A compressed trie of all suffixes enabling fast longest-match queries and dynamic updates. "maintaining a compact suffix tree over past generations."
- Tensor-parallelism (TP): A parallelism approach that splits model tensors across devices to fit larger models. "resorting to tensor-parallelism (TP) if the training model cannot fit into memory."
- Time-per-Output-Token (TPOT): A serving metric measuring average time to generate each output token. "Today's serving systems optimize for Time-to-First-Token (TTFT) and Time-per-Output-Token (TPOT), resulting in long sequences taking more time to complete their generation and causing long tail latency in RL rollout phase."
- Time-to-First-Token (TTFT): A serving metric measuring latency until the first token is produced. "Today's serving systems optimize for Time-to-First-Token (TTFT) and Time-per-Output-Token (TPOT), resulting in long sequences taking more time to complete their generation and causing long tail latency in RL rollout phase."
- Token-dependent cost: The compute cost that scales with the number of tokens processed. "The term $c_{\mathrm{tok}$ represents the average compute cost per-token on the GPU/CPU."
- Ukkonen algorithm: An online algorithm for building suffix trees in linear time suitable for incremental updates. "the construction of the suffix-tree and updates of the online suffix-tree are run in linear time through the Ukkonen algorithm~\citep{ukkonen1995line}"
- Verifiability-based rewards: Rewards derived from automatically checkable outcomes (e.g., correctness or unit-test pass). "optimizes a policy with preference- or verifiability-based rewards"
- Verification round: A cycle in which the target model checks (accepts or rejects) a proposed draft. "Average accepted tokens per verification round in RL training."
- Wall-clock time: The actual elapsed time measured during training or inference. "where a small fraction of long generations dominates wall-clock time"
- Window-awareness: Sensitivity to recency to avoid staleness in speculation as the policy evolves. "Window-awareness is crucial for adapting to policy distribution shift, as trajectories from early policies lack similarity to those from later policies (Fig.~\ref{fig:generation_sim})."
Collections
Sign up for free to add this paper to one or more collections.