- The paper presents TLT, an integrated system that combines an adaptive drafter with speculative decoding to achieve a 1.7–2.1× speedup in RL training for reasoning LLMs.
- It employs a BEG-MAB tuner and bucketed CUDAGraphs to optimize throughput and manage long-tail rollout inefficiencies in multi-GPU environments.
- Experimental results demonstrate that TLT preserves model quality while maximizing resource utilization, offering practical benefits for advanced RL training scenarios.
Efficient RL Training for Reasoning LLMs via Adaptive Speculative Decoding
Motivation and Workload Characteristics
The proliferation of LLMs with enhanced reasoning capabilities has led to a surge in complex RL training workloads, especially for domains such as mathematics, coding, and logic. Reinforcement learning frameworks, notably GRPO [DeepSeekMath], underpin the optimization of these models. However, RL training for reasoning LLMs is dominated by costly rollout phases exhibiting persistent long-tail distributions in response lengths—minority of responses consume disproportionate wall-clock time, causing workload skew and suboptimal resource utilization. Production-scale traces (Figure 1) demonstrate that rollout accounts for roughly 85% of step time in multi-day, multi-GPU training, and existing RLHF systems fail to mitigate this inefficiency.
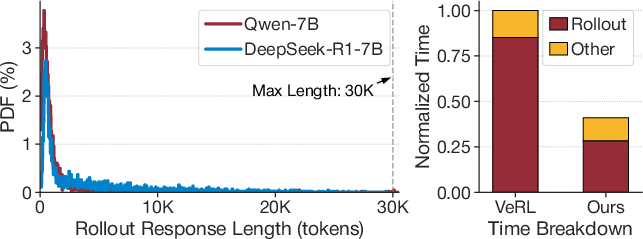
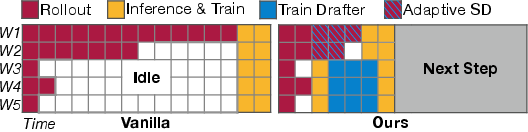
Figure 2: Distribution of response length and RL step time breakdown reveals the extreme long-tail phenomenon that causes the majority of RL step time to be consumed by a few very lengthy responses.
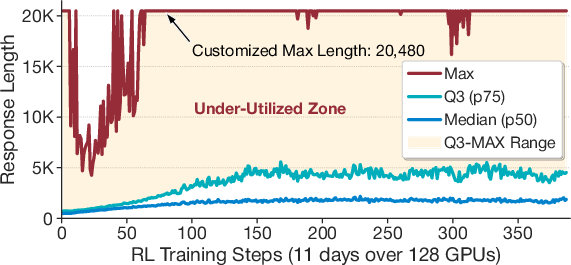
Figure 1: RL Training trace from ByteDance, showing persistent, resource-intensive long-tail rollout phenomenon for large-scale reasoning models.
This persistent rollout bottleneck necessitates system-level innovations that preserve mathematical fidelity—lossless output distributions—and ensure non-interference with the main RL training pipeline. Quantization and sparsity-based acceleration are often lossy, while speculative decoding is lossless but non-trivial to apply under a continuously-evolving target model in RL.
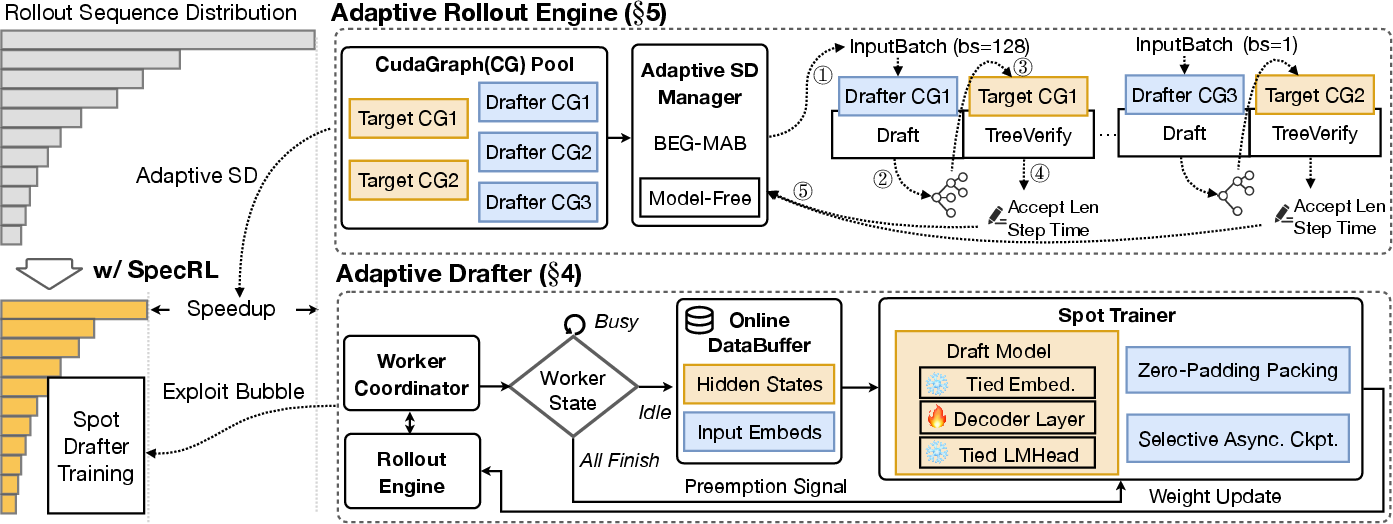
TLT: Adaptive Drafter and Rollout Engine
The proposed TLT system addresses these efficiency challenges through the synergy of two components:
The adaptive drafter reuses frozen embeddings and LM head weights, updating only its single decoder layer, and is trained asynchronously using cached hidden states from RL rollouts. The rollout engine leverages batched and bucketed CUDAGraphs (Figure 4) to mitigate linear memory growth with strategy/batch count, automatically tuning SD hyperparameters to maximize throughput for highly dynamic batch sizes.
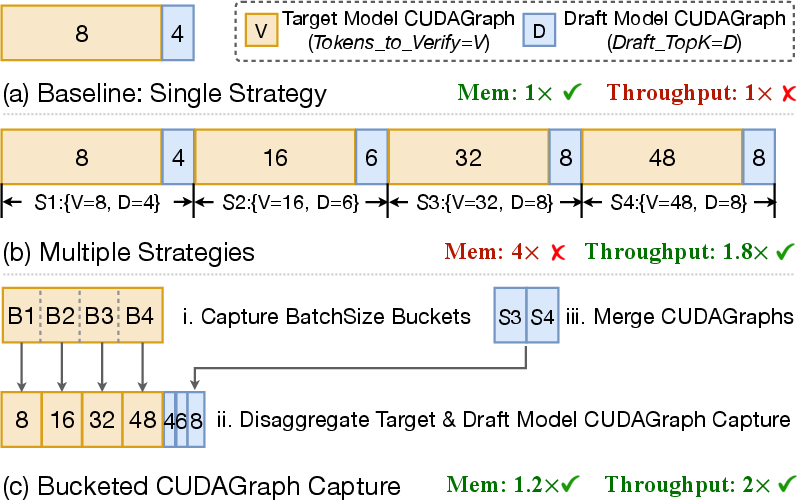
Figure 4: Memory footprint analysis for CUDAGraph strategies, with bucketed approach achieving significant reduction compared to vanilla static graphs.
Speculative Decoding in RL: Challenges and Solutions
Speculative decoding enables lossless throughput gains by parallel token verification but faces challenges in RL:
- Evolving Target Model: RL continually updates weights, causing draft-model staleness and degraded SD acceptance rates.
- Draft Model Training Overhead: Dedicated drafters typically demand substantial alignment training if updated offline.
- Dynamic Batch Sizes: RL rollouts involve variable batch sizes, complicating SD scheduling due to tradeoffs in accepted length and memory overhead.
TLT's spot trainer architecture initiates drafter training opportunistically during idle GPU phases, caches long sequences via a DataBuffer to address input length distribution mismatch, and employs asynchronous checkpointing to minimize preemption loss (Figure 5, Figure 6). Sequence packing further eliminates padding inefficiencies, enabling high-throughput, preemptible training.
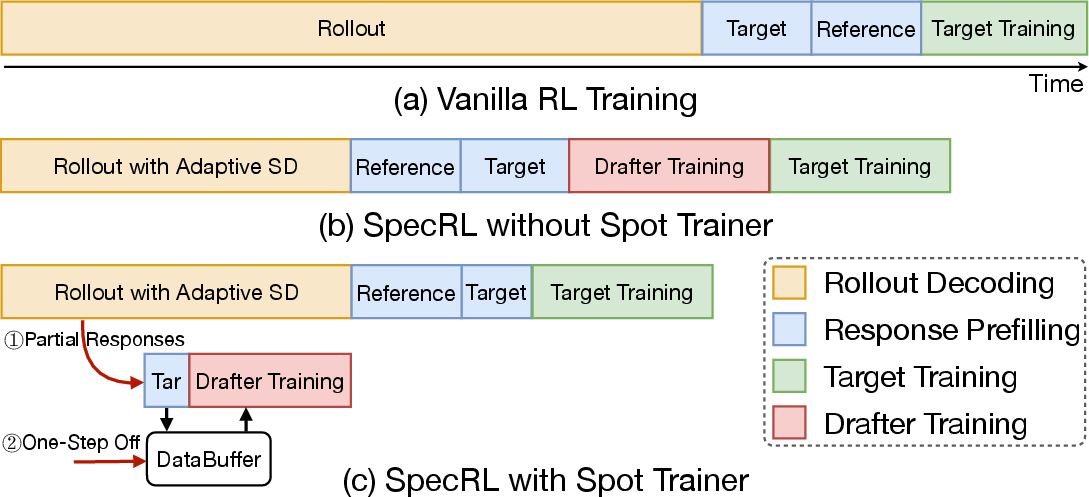
Figure 5: Spot Trainer Workflow, showing opportunistic, preemptible draft model training overlapping with ongoing rollouts.

Figure 6: Effect of selective asynchronous checkpointing and sequence packing in TLT, minimizing work loss and optimizing compute utilization.
Experimental Results and Numerical Findings
TLT demonstrates robust acceleration across diverse models (Qwen2.5-7B, Qwen2.5-32B, Llama-3.3-70B-Instruct) and hardware platforms (H100, A100), using Eurus-2-RL and coding/math benchmark datasets. Notable numerical outcomes include:
- 1.7–2.1× End-to-End RL Training Speedup: TLT yields up to 2.1× throughput improvement over state-of-the-art RL training system VeRL [HybridFlow], without accuracy loss.
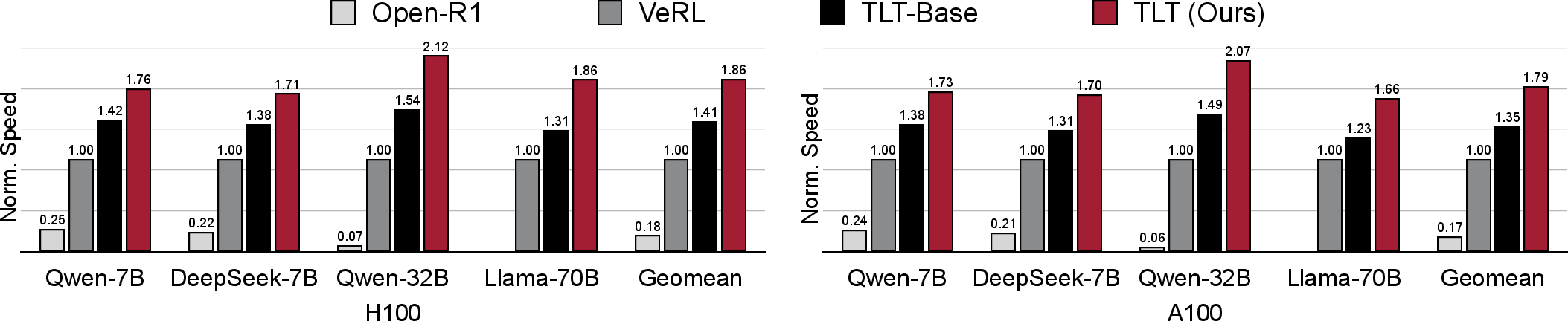
Figure 7: End-to-end Training Speed Evaluation, presenting relative throughput gains of TLT compared to VeRL and Open-R1 baselines.
- Model Quality Preservation: Reward curves for TLT and VeRL overlap significantly (Figure 8), affirming fidelity-preserving acceleration.
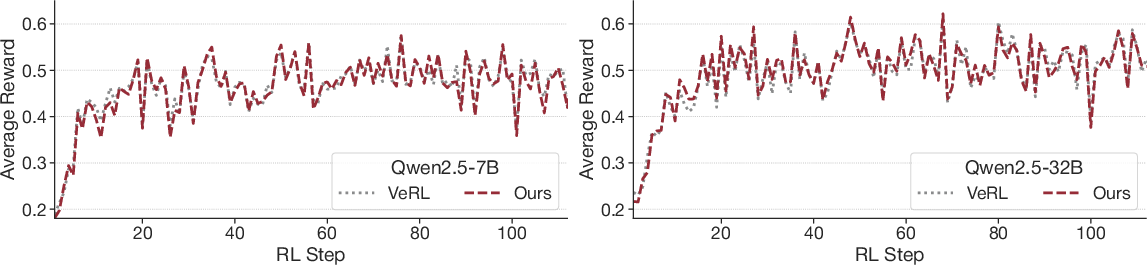
Figure 8: Average reward curves for VeRL and TLT, indicating negligible impact of speculative decoding and adaptive drafter on RL training dynamics.
- Efficient, Adaptive Speculative Decoding: BEG-MAB selector and bucketed CUDAGraph mechanism provide near-optimal SD configuration under dynamic batch sizes—speedups remain >2× up to batch size 32, and memory footprint for multi-strategy graphs drops by 2.8× versus vanilla approach.
- Adaptive Drafter Superiority: Top-3 token prediction accuracy continuously improves, recovering rapidly from target-model updates (Figure 9), and maintains higher acceptance probability for distant tokens (Figure 10).
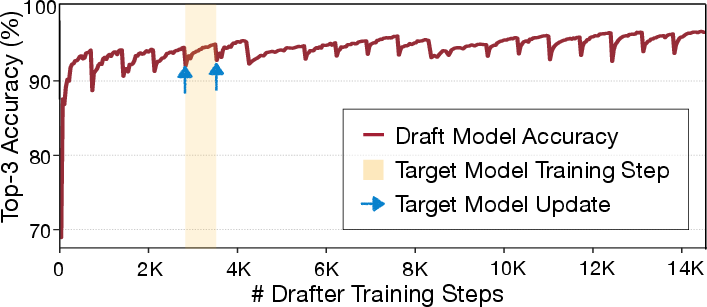
Figure 9: Drafter accuracy steadily improves due to adaptive training, with minor dips upon target model updates rapidly compensated.
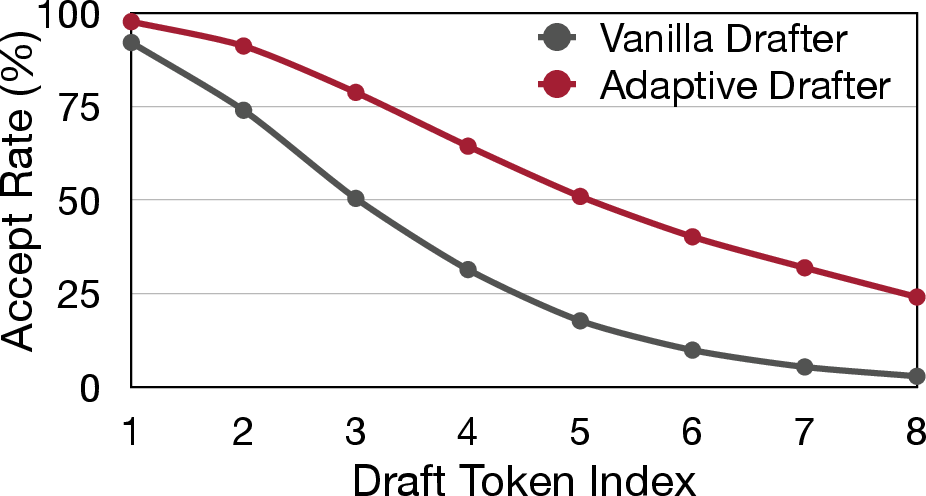
Figure 10: Token accept rates by draft model type; the adaptive drafter maintains higher accept rates for distant tokens, directly yielding longer effective accept lengths.
- Spot Trainer Effectiveness: Asynchronous checkpointing reduces latency by 9.2×, sequence packing boosts training throughput by 2.2× (Figure 6).
Theoretical and Practical Implications
TLT's architecture is fully compatible with diverse RL algorithms (GRPO, RLOO, DAPO, REINFORCE), as the adaptive drafter and spot trainer only depend on the overall training workflow. The system's lossless speculative decoding guarantees and non-interference design make it suitable for both dynamic RL training and static inference deployment.
These results suggest that adaptive speculative decoding is a practical solution not only for reasoning RL, but also for workloads with uniformly long responses, multi-turn rollouts, and edge deployments where variable response patterns persist. The system opens new avenues in asynchronous RL training—combining on-policy correctness with improved hardware utilization—subject to future algorithmic safeguards.
Model-free drafting is incorporated as a baseline and fallback, leveraging sequence similarity across rollouts for speculative token prediction, further broadening applicability.
Conclusion
TLT introduces an integrated system for efficient RL training of reasoning LLMs by opportunistically leveraging adaptive speculative decoding and spot-trained draft models. Substantial throughput gains are achieved without compromising learning fidelity, resource utilization is maximized, and an effective draft model is produced as a free by-product for inference deployment. The approach is generalizable across RL paradigms and model architectures, setting the stage for future system-level and algorithmic advances in scalable, reasoning-centric LLM training.