- The paper demonstrates that integrating speculative decoding in RL post-training can achieve up to 1.8× rollout speedup without altering the target output distribution.
- The paper details a rigorous system integration using EAGLE-3 and a vLLM backend to manage both synchronous and asynchronous rollout generation.
- The paper’s experiments and simulations outline actionable configuration strategies that enable significant scalability benefits in RL training.
System-Integrated Speculative Decoding for Efficient RL Post-Training Rollouts
Motivation and Background
Reinforcement learning (RL) post-training of LLMs is fundamentally constrained by the cost of autoregressive rollout generation. For frontier-scale LLMs, rollout generation frequently dominates training time, especially on reasoning-intensive or agentic workloads. Existing system-level optimizations—such as asynchronous pipelines, replay buffers, low-precision generation, and prompt filtering—address throughput by relaxing policy or optimization constraints, but each modifies the original sampling or optimization regime. Speculative decoding offers a distinct efficiency primitive: it accelerates rollout generation while preserving the target model’s exact output distribution via rejection sampling, thus avoiding distribution mismatch for RL policy updates.
System Integration and Architecture
The paper presents a rigorous integration of speculative decoding in the NeMo RL framework, leveraging a vLLM backend to execute rollout trajectories via draft/token proposals. The primary system contributions are focused on supporting both general drafting mechanisms (EAGLE-3 for models without native multi-token heads) and native paths (MTP-enabled models), ensuring weight synchronization and draft-policy coherence in a continuously updating RL loop.
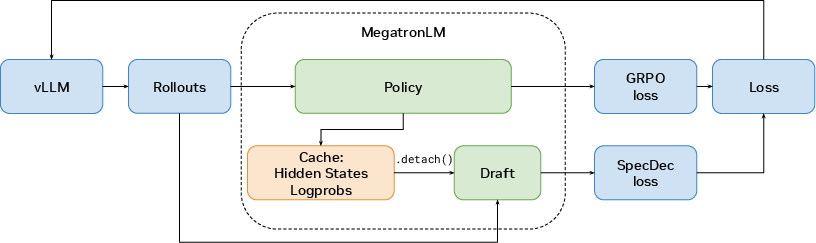
Figure 1: System overview of NeMo RL with speculative decoding; the verifier (policy) model's forward pass caches hidden states and log-probabilities for use in detached draft supervision, guaranteeing the integrity of the policy gradient signal.
Speculative decoding operates synchronously and asynchronously, directly targeting generation latency and supporting lossless trajectory sampling. The design enforces that log-prob, KL penalty, and policy loss remain computed against the verifier policy rather than the draft, guaranteeing the RL signal's fidelity. The system enables both offline draft initialization—using policy responses for in-distribution alignment—and online adaptation, where draft heads are updated via trajectory supervision in detached mode.
Experimental Evaluation
The empirical study investigates RL post-training on mathematical reasoning workloads using GRPO-based optimization. Comparative experiments on RL-Think (continued reasoning refinement) and RL-Zero (base model) demonstrate that speculative decoding with EAGLE-3 reduces rollout generation time by 1.8× for RL-Zero and 1.5× for RL-Think, capping total RL step speedup at 1.41× and 1.35×, respectively. These improvements are realized under synchronous RL on 8B-scale models across high-performance GPU clusters.
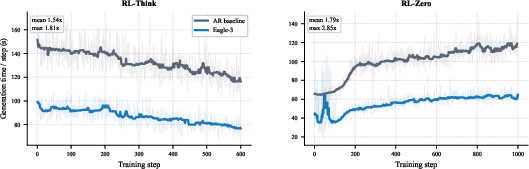
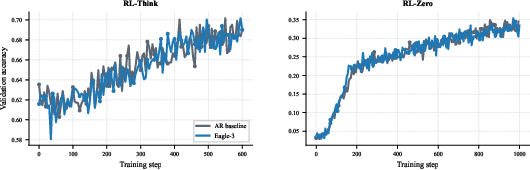
Figure 2: Generation latency per training step; EAGLE-3 outperforms autoregressive decoding throughout training, with substantial acceleration on both RL-Think and RL-Zero.
Validation accuracy curves for autoregressive and speculative decoding are nearly identical, corroborating that speculative decoding does not alter optimization dynamics or final performance on the AIME-2024 benchmark. Importantly, naive (e.g., n-gram) drafting fails to deliver practical speedups, as verification overhead dominates unless the acceptance rate and alignment are adequately optimized.
Draft Initialization, Length Selection, and Adaptation
The system-level sensitivity analysis highlights three operational levers for speculative decoding:
- Draft Initialization: In-distribution initialization (DAPO-aligned) markedly outperforms generic chat-domain initialization in both acceptance length and realized speedup.
- Draft Length: Shorter drafts (e.g., k=3) provide optimal speedup, with longer drafts increasing verification cost and speculative overhead beyond gains from higher acceptance. This empirical observation validates theoretical expectations from Amdahl's law applied to step-level RL pipeline decomposition.
- Online Adaptation: Online draft maintenance offers modest gains only for weaker initializations, acting as insurance against trajectory drift rather than a universal accelerator.
Synergy with Asynchronous Execution
The integration of speculative decoding with asynchronous RL is shown to be complementary. In asynchronous environments, much of rollout generation is hidden by pipeline overlap, diminishing—but not eliminating—the critical path speedup obtainable from speculation. Empirical results report an effective step speedup of 1.24× under asynchronous policy lag, with learning curves unaffected.
Deployment Scale Simulation and Opportunity Envelope
The study extends the empirical findings through simulation-based projections across deployment scale, draft length, acceptance length, and policy lag. Simulations on Qwen3-8B and Qwen3-235B-A22B indicate:
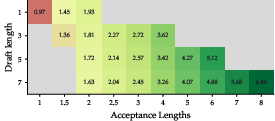
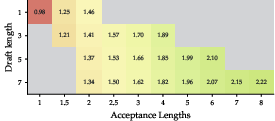
Figure 3: Rollout generation speedup; longer drafts yield larger speedup only when acceptance length is high and generation dominates the RL step.
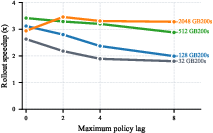
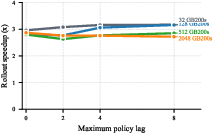
Figure 4: Rollout speedup for Qwen3-235B-A22B across GPU count and policy lag; speedup is robust at large scale with moderate lag, matching end-to-end acceleration up to 2.5× in optimal configurations.
- For large models at frontier-scale (235B parameters, up to 2048 GPUs), speculative decoding exceeds 3× rollout speedup and 2.5× end-to-end RL speedup under favorable acceptance and pipeline configuration.
- The benefit scales with model size and hardware, but is bounded by the generation share and pipeline overlap; policy lag suppresses speedup at small deployment scales but not at larger ones.
- Practitioners should tune draft length and initialization to ensure maximal benefit; exceedingly long drafts or poor alignment can nullify speedup and even degrade throughput.
Implications and Future Directions
Practically, system-integrated speculative decoding enables scalable RL post-training on frontier models without compromising policy semantics, offering substantial wall-clock speedups in synchronous and asynchronous RL stacks. The deployment design space (draft mechanism, length, initialization, and overlap) is well-characterized, and opportunity envelopes from simulation provide actionable configuration guides for high-performance RL practitioners.
Theoretically, speculative decoding secures lossless sampling for RL, permitting optimization advances without distribution shift. Future developments may generalize adaptive draft scheduling, deeper integration in distributed RL systems, and hardware-aware speculative strategies as model and infrastructure scales increase. Further research could explore closed-form analysis for step-level speedup bounds in broader RL-optimization contexts, and extend speculative acceleration to non-autoregressive generations and multi-agent RL pipelines.
Conclusion
This work provides a comprehensive system integration and empirical characterization of speculative decoding for RL post-training in frontier LLMs. By enforcing exact-policy sampling and deploying well-aligned, short-length drafts—primarily via EAGLE-3—the approach achieves up to 1.5×0 rollout speedup and 1.5×1 overall RL step speedup at 8B scale, with simulation projections indicating 1.5×2–1.5×3 rollout and 1.5×4 end-to-end speedups at full deployment scale. The findings establish speculative decoding as a principled, lossless, and practical throughput acceleration primitive in RL training, with implications for system design and future scalability in agentic and reasoning-centric LLM training.