BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
Abstract: Reinforcement learning (RL) has recently become the core paradigm for aligning and strengthening LLMs. Yet, applying RL in off-policy settings--where stale data from past policies are used for training--improves sample efficiency, but remains challenging: policy entropy declines sharply, optimization often becomes unstable and may even collapse. Through theoretical and empirical analysis, we identify two key insights: (i) an imbalance in optimization, where negative-advantage samples dominate the policy gradient, suppressing useful behaviors and risking gradient explosions; and (ii) the derived Entropy-Clip Rule, which reveals that the fixed clipping mechanism in PPO-like objectives systematically blocks entropy-increasing updates, thereby driving the policy toward over-exploitation at the expense of exploration. Building on these insights, we propose BAlanced Policy Optimization with Adaptive Clipping (BAPO), a simple yet effective method that dynamically adjusts clipping bounds to adaptively re-balance positive and negative contributions, preserve entropy, and stabilize RL optimization. Across diverse off-policy scenarios--including sample replay and partial rollout--BAPO achieves fast, stable, and data-efficient training. On AIME 2024 and AIME 2025 benchmarks, our 7B BAPO model surpasses open-source counterparts such as SkyWork-OR1-7B, while our 32B BAPO model not only achieves state-of-the-art results among models of the same scale but also outperforms leading proprietary systems like o3-mini and Gemini-2.5-Flash-Thinking.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs to think and solve problems better using reinforcement learning (RL). The authors focus on a practical but tricky setup called “off-policy” RL—where the model is trained using older, previously collected data. While this makes training faster and more efficient, it can easily become unstable. The paper explains why that happens and introduces a new method, BAPO (Balanced Policy Optimization with Adaptive Clipping), that keeps training stable and helps the model learn more effectively.
What questions does the paper ask?
The paper investigates two simple questions:
- Why does off-policy RL often become unstable when training LLMs?
- Can we design a training trick that keeps learning balanced and prevents the model from getting stuck or collapsing?
How does the method work? (Explained with everyday language)
First, some quick translations of technical ideas:
- Reinforcement learning (RL): Think of RL as a coach giving feedback (rewards or penalties) to help a model improve its answers.
- Off-policy training: Imagine a student practicing with last year’s worksheets. It’s efficient (you don’t need new data), but the style might not match today’s lessons, which can cause problems.
- Entropy: This is a measure of “variety” or “exploration” in the model’s choices. High entropy means the model keeps an open mind and tries different paths. Low entropy means it sticks to one way and stops exploring.
- PPO and clipping: PPO is a popular RL method. “Clipping” is like setting a speed limit on how much the model’s behavior can change at once, to prevent wild swings.
What the authors noticed:
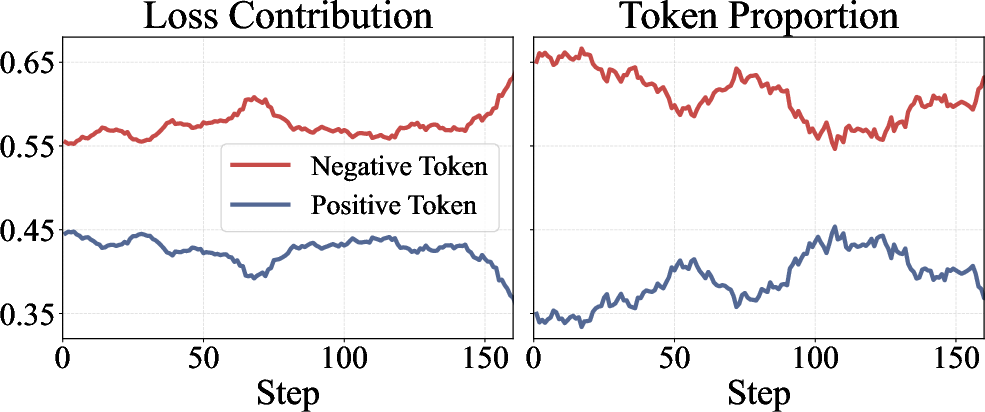
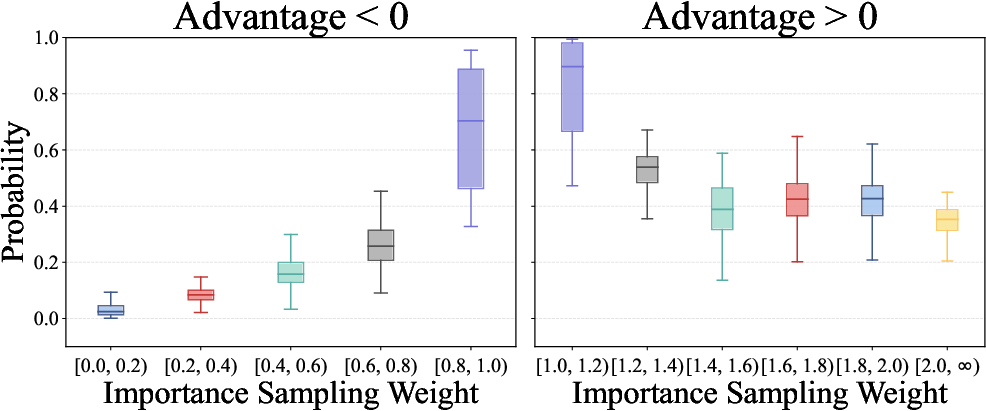
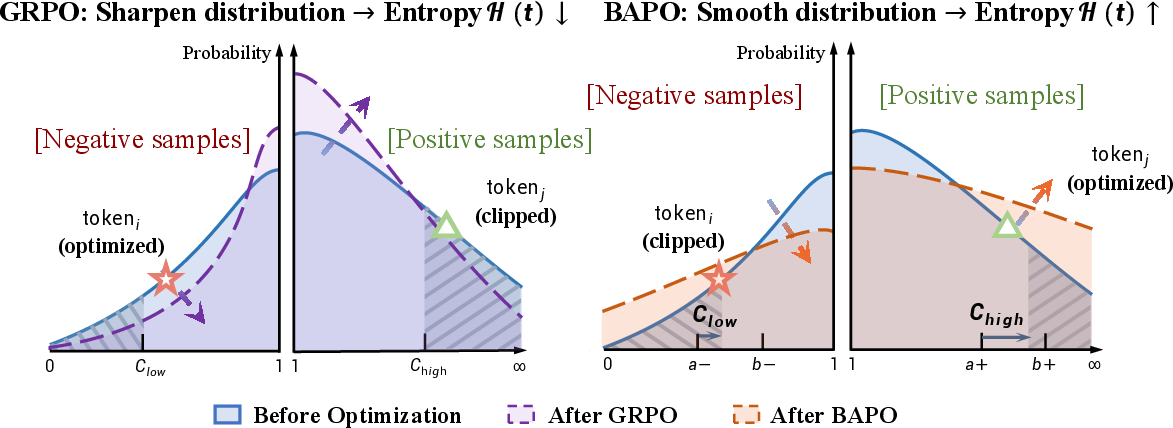
- Imbalanced coaching: During training, the model sees many more “negative” signals (penalties) than “positive” ones (rewards), especially on hard problems with long answers. This can overwhelm learning, pushing the model to over-correct and sometimes blow up (become unstable).
- The Entropy-Clip Rule: The default clipping trick in PPO often blocks updates that would increase entropy (i.e., encourage exploration). It lets the model over-focus on familiar answers and suppresses new, potentially good ideas—so the model becomes too rigid.
Their solution: BAPO (Balanced Policy Optimization with Adaptive Clipping)
- Instead of using fixed “speed limits” (clipping bounds) for all updates, BAPO adjusts them dynamically during training.
- It carefully opens the door for “positive” updates that come from low-probability tokens (rare but promising bits of an answer), while limiting overwhelming penalties from too many “negative” low-probability tokens.
- The method keeps track of how much positive feedback is actually influencing learning and automatically tunes the bounds until enough positive signals are included.
- In short: BAPO rebalances the praise and criticism so the model learns steadily and keeps exploring.
What did they find?
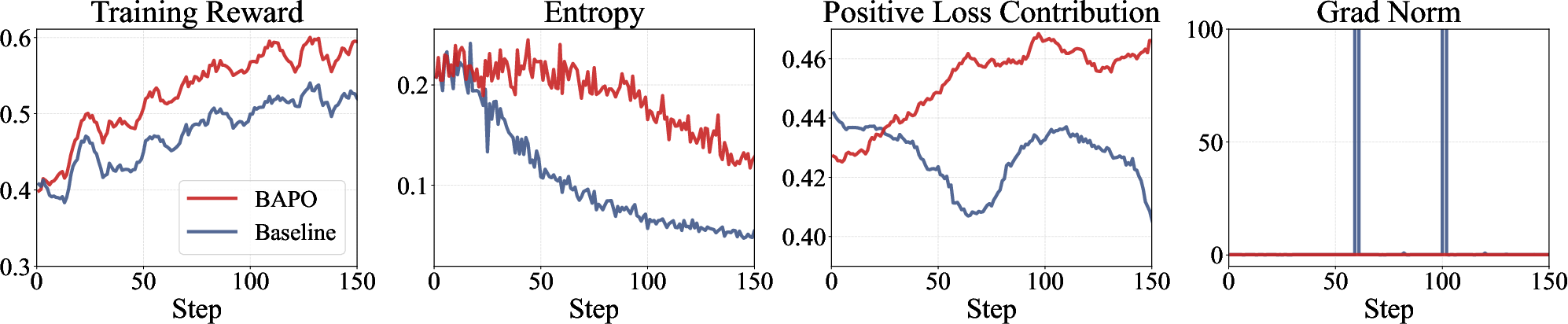
The authors tested BAPO in several off-policy setups (like replaying old data and partial rollouts where long answers are resumed later). The main results:
- Training stays stable: No sudden collapses. Entropy remains healthy, meaning the model keeps exploring.
- Faster and more efficient learning: The model improves quickly without needing only fresh data.
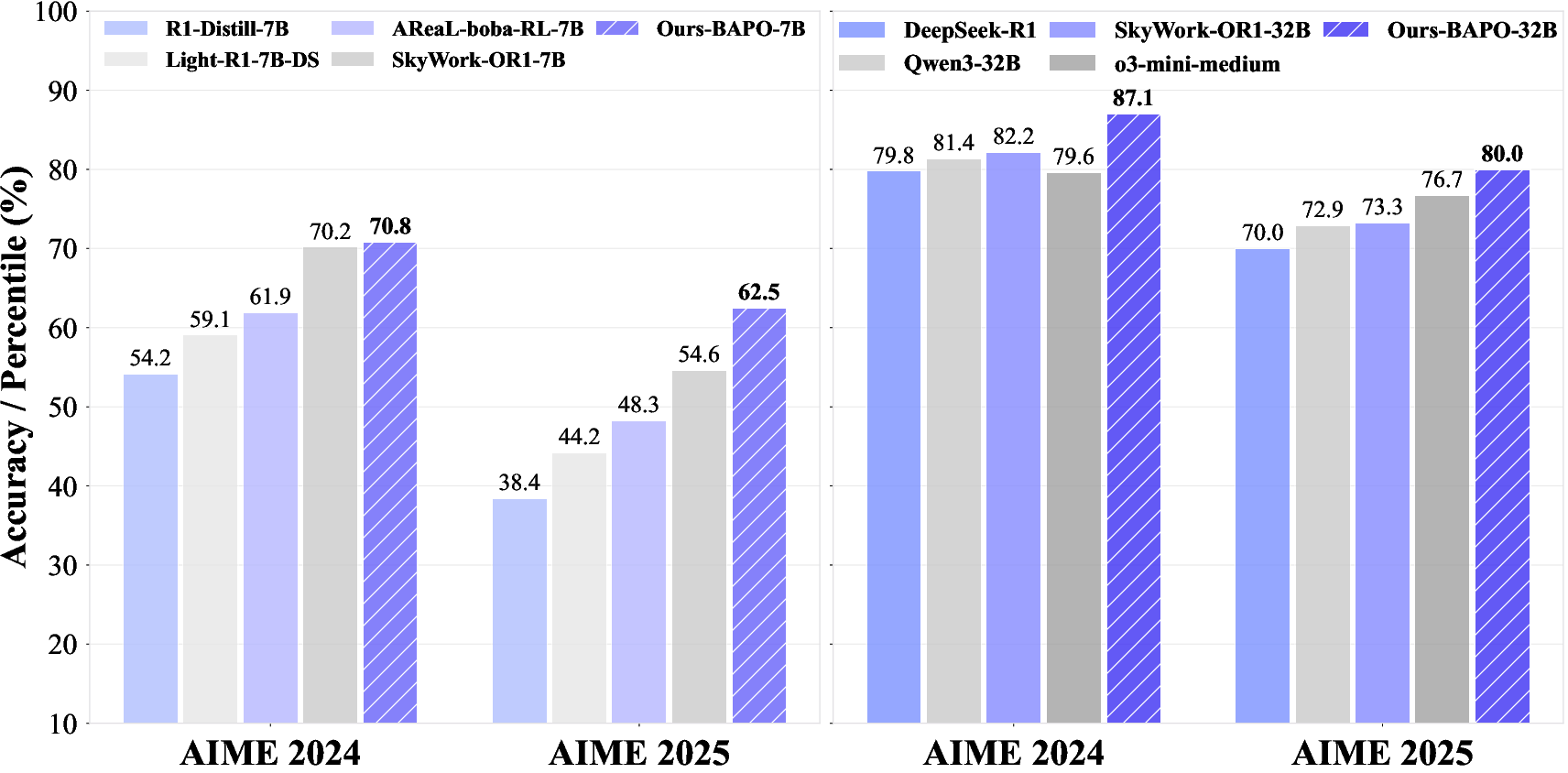
- Better performance on reasoning benchmarks:
- AIME 2024: Their 32B model scored 87.1; the 7B model scored 70.8.
- AIME 2025: Their 32B model scored 80.0; the 7B model scored 62.5.
- These scores beat many open-source models of similar size and even surpass some strong proprietary systems in certain cases (like o3-mini and Gemini-2.5-Flash-Thinking).
Why this matters:
- Stable off-policy RL means you can use large amounts of older data and modern training systems (like partial rollouts) without the training spiraling out of control.
- Preserving entropy keeps the model curious, improving its ability to reason through hard problems.
Why is this important?
- For the AI community: Off-policy RL is common in real training pipelines because it’s efficient. BAPO makes it safer and more reliable.
- For model reasoning: By preventing the model from becoming too narrow or “over-confident” in familiar patterns, BAPO helps it explore new solution paths—important for math, coding, and complex reasoning.
- For scaling systems: BAPO reduces the need for delicate manual tuning. It adapts as training runs, which is valuable for large-scale training where conditions change over time.
In simple terms: What’s the takeaway?
Training LLMs with older data is efficient but risky. The authors discovered that the usual training rules unintentionally shut down exploration and let negative signals dominate. Their method, BAPO, acts like a smart coach: it adjusts the rules on the fly to make sure the model gets enough constructive feedback and keeps trying new ideas. This leads to steadier learning and better results on tough reasoning tests.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future work:
- Theory scope and assumptions
- Specify the precise assumptions under which the Entropy-Clip Rule approximation holds (e.g., small update step sizes, independence assumptions, advantage estimation noise), and validate the rule under GRPO’s group-based rewards rather than PPO alone.
- Provide formal guarantees for BAPO (e.g., bounds on KL divergence, monotonic improvement, convergence rates) or characterize failure modes when guarantees do not hold.
- Bias/variance and off-policy correction
- Quantify the bias introduced by adaptive clipping to the importance-weighted policy gradient and analyze how BAPO affects the bias–variance trade-off relative to standard PPO/GRPO, V-trace, or Retrace.
- Evaluate BAPO in more extreme off-policy settings (highly stale/offline logged data) and compare against established off-policy corrections (e.g., V-trace, importance weight truncation) to assess stability and performance.
- Control of trust-region/KL and policy drift
- Measure and control the actual KL divergence per update under BAPO; study whether adaptive clipping can lead to policy drift and propose a coupled KL-target controller if needed.
- Analyze the relationship between adaptive clipping bounds and trust-region constraints; determine if bounds can be set to directly satisfy KL or JS divergence targets.
- Design of adaptive controller
- Justify the use of a global, batch-level positive-contribution threshold ρ₀ and the greedy increase rule for c_high/c_low; compare against principled alternatives (e.g., solving a constrained optimization with Lagrange multipliers to meet a target positive-contribution ratio or entropy change).
- Investigate token-, state-, or trajectory-conditional clipping (context-aware bounds) versus global bounds to handle heterogeneous token distributions.
- Develop an automatic tuning policy for ρ₀, step sizes (δ₁, δ₂), and bound ranges ([a⁻, b⁻], [a⁺, b⁺]) based on online signals (e.g., target entropy, KL, gradient norms), and study stability across training phases.
- Hyperparameter sensitivity and robustness
- Perform systematic sensitivity analyses and ablations of ρ₀, δ₁/δ₂, bound ranges, batch size, and staleness level; report variance across random seeds and provide confidence intervals for all main results.
- Quantify the compute/throughput overhead of the per-batch bound adjustment loop, its scaling with model size, and its impact in multi-node distributed training.
- Entropy and exploration metrics
- Go beyond entropy averages: measure exploration quality directly (e.g., diversity of chain-of-thoughts, solution modes, branching factor) and correlate with performance; determine whether BAPO’s entropy preservation improves exploration on tasks where exploration is essential.
- Establish safeguards to prevent uncontrolled entropy growth or over-smoothing and study exploitation–exploration trade-offs with richer metrics than entropy alone.
- Advantage estimation and reward noise
- Detail and evaluate the advantage estimator (e.g., normalization, baselines, credit assignment), and study BAPO’s robustness to noisy/sparse rewards and reward model misspecification (RLHF/RLAIF).
- Examine how BAPO behaves when advantage distributions are highly skewed or heavy-tailed (common in long-horizon reasoning) and whether clipping interacts adversely with advantage normalization.
- Handling negative low-probability tokens
- Assess the safety implications of down-weighting low-probability negative tokens: does this reduce the suppression of harmful or incorrect behaviors?
- Develop criteria to distinguish “usefully negative” tokens (safety-critical) from noisy negatives, and integrate safety-aware constraints or penalties.
- Task and domain generalization
- Evaluate BAPO beyond math reasoning (AIME/MATH): code generation, general dialogue, multilingual reasoning, tool use/agents, and long-horizon planning tasks; test on benchmarks with different reward structures.
- Validate on more base/backbone families and larger scales (≥70B/100B) to assess scalability, memory/latency trade-offs, and cross-architecture robustness.
- Comparisons and broader baselines
- Include head-to-head comparisons with closely related adaptive clipping methods (e.g., DCPO, asymmetric REINFORCE, token-level adaptive schemes) under matched compute, data, and staleness; add ablations isolating BAPO’s components.
- Benchmark under standardized off-policy infrastructures (e.g., prioritized replay, large asynchronous systems) with final task metrics, not only training dynamics.
- Partial rollout and staleness characterization
- Report final task performance under partial rollout (not just training curves) and quantify how different staleness profiles (resume depth, replay probability) affect BAPO’s gains.
- Model and predict the relationship between staleness and optimal clipping bounds; derive schedules or controllers that proactively adapt to measured staleness.
- Length bias and generation behavior
- Measure how BAPO affects response length distributions, brevity/verbosity bias, and solution completeness; ensure improvements are not due to reward gaming via shorter/longer outputs.
- Safety, alignment, and calibration
- Conduct safety and red-teaming evaluations to assess whether entropy-preserving updates increase unsafe, toxic, or hallucinated content; integrate safety-aware rewards or constraints with BAPO.
- Study effects on probability calibration and confidence estimation, given the deliberate inclusion of low-probability positive tokens.
- Data and evaluation rigor
- Provide multiple-seed runs with statistical tests; disclose data mixture, contamination checks, and cross-benchmark generalization (out-of-domain tasks) to rule out overfitting to AIME-style problems.
- Theoretical and empirical bridges
- Empirically validate the Entropy-Clip Rule’s predicted covariance patterns at token level across diverse tasks and training stages; analyze optimizer effects (e.g., Adam momentum) on the rule’s applicability.
- Extend the analysis from PPO-like objectives to other RL objectives used in LLMs (e.g., TRPO-like KL-penalized forms, direct policy optimization, sequence-level objectives) and verify whether analogous entropy–clipping relationships hold.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, drawing directly from the paper’s findings and the released implementation of BAPO.
- Stable off-policy RL training for reasoning-centric LLMs
- Sectors: software, education, finance, customer service
- What to do: Integrate BAPO into PPO/GRPO-based RLHF/RLAIF pipelines to reduce gradient explosions and entropy collapse when using replay buffers, partial rollouts, or stale data.
- Tools/products/workflows:
- A drop-in “BAPO Trainer” module for popular libraries (e.g., TRL/GRPO-style frameworks) that adaptively adjusts clipping bounds per batch.
- “EntropyGuard” metrics dashboard that tracks positive-token contribution ratio (ρ), entropy trends, IS-weight distributions, and clipping bounds over time.
- Assumptions/dependencies: Availability of advantage estimation and reward models; training stack can expose importance weights per token; logging pipeline for entropy and contribution metrics; reproducible off-policy data labeling (policy version tags).
- Robust partial rollout training in asynchronous RL systems
- Sectors: MLOps, cloud AI, enterprise AI platforms
- What to do: Use BAPO to stabilize training in systems that segment long trajectories and resume them later (e.g., AReaL-like infrastructure).
- Tools/products/workflows:
- “Staleness-aware replay buffer” that includes policy version metadata and invokes BAPO’s adaptive clipping each batch.
- Rollout orchestration recipes: set initial bounds, step sizes (δ1, δ2), and ρ0 targets; monitor bound evolution during training.
- Assumptions/dependencies: Replay buffer retains policy identifiers; training platform supports batch-level adaptive hyperparameters; reliable advantage estimation under partial rollouts.
- Data efficiency and cost control in RL training
- Sectors: energy, cloud cost optimization, sustainability
- What to do: Leverage BAPO’s tolerance to stale data to reuse historical trajectories, reducing new rollout cost while maintaining performance stability.
- Tools/products/workflows:
- Scheduling policies that bias toward replayed batches when entropy and positive contribution stay within target bands.
- “Compute budgets” linked to entropy floors to prevent wasteful over-exploitation.
- Assumptions/dependencies: Adequate stale data quality; careful tuning of entropy floors to avoid under-exploration; accurate tracking of compute/token budgets.
- Improved math and structured reasoning tutors
- Sectors: education (EdTech), test prep, STEM learning
- What to do: Adopt BAPO for fine-tuning math reasoning models (e.g., Qwen2.5-Math-derived models), then deploy in tutoring products where long chain-of-thought stability matters.
- Tools/products/workflows:
- Tutor models trained with BAPO, evaluated on AIME-like benchmarks; iterative improvements with curriculum + adaptive clipping.
- Assumptions/dependencies: Reliable math-specific rewards and evaluation datasets; guardrails for solution correctness and explanation quality.
- Operational guardrails for RL training stability
- Sectors: MLOps, AI quality assurance
- What to do: Add entropy and positive/negative token contribution checks as “training gates.” Halt or reconfigure training if the Entropy-Clip Rule signals over-sharpening or negative-dominant gradients.
- Tools/products/workflows:
- “Training health checks” that alert on rapid entropy declines, excessive clipping of positive low-probability tokens, or spikes of low-probability negative tokens.
- Assumptions/dependencies: Consistent logging of token-level stats; thresholds calibrated to task/domain.
- Curriculum learning synergy
- Sectors: academia, EdTech, applied research
- What to do: Pair BAPO with progressive difficulty schedules so early training isn’t overwhelmed by negative-advantage tokens, improving stability and speed.
- Tools/products/workflows:
- Curriculum schedulers that adjust difficulty and BAPO’s ρ0 target in tandem.
- Assumptions/dependencies: Access to curated curricula; monitoring to avoid tail degradation.
- Immediate adoption via open-source code
- Sectors: academia, startups, open-source community
- What to do: Use the authors’ GitHub implementation to replicate and extend their results on your domain-specific datasets.
- Tools/products/workflows:
- Reference BAPO config files for PPO/GRPO; example training scripts with staleness controls and entropy tracking.
- Assumptions/dependencies: Compatibility with your base model and RL framework; domain-specific rewards.
Long-Term Applications
These opportunities require further research, scaling, or development to reach production-grade maturity.
- RLHF/RLAIF alignment with entropy-aware governance
- Sectors: policy, safety, compliance
- What could emerge: Standards that specify entropy floors/ceilings and positive-token contribution targets (ρ0) for safe exploration in alignment pipelines.
- Tools/products/workflows:
- “Alignment compliance dashboards” that audit training runs for entropy stability, clipping behavior, and imbalance mitigation.
- Assumptions/dependencies: Broad agreement on metrics and thresholds; evidence that entropy governance correlates with safer behaviors across domains.
- Domain-specialist reasoning models in regulated fields
- Sectors: healthcare, legal, finance
- What could emerge: Off-policy RL with BAPO to safely and efficiently incorporate stale case logs and feedback, improving chain-of-thought reliability for decision support.
- Tools/products/workflows:
- “Case replay” training with annotated policy versions and adaptive clipping; post-training calibration for hallucination and bias.
- Assumptions/dependencies: High-quality domain rewards; rigorous validation and regulatory approvals; human-in-the-loop oversight.
- Multi-agent and robotics language-action RL
- Sectors: robotics, autonomous systems
- What could emerge: Stabilized language-conditioned policies where token-level entropy control translates to better exploration in action spaces, especially with off-policy replay.
- Tools/products/workflows:
- Policy bridges that map token-level clipping adaptations to action-level trust regions; simulation-to-real workflows that track entropy and advantage distributions.
- Assumptions/dependencies: Robust reward shaping; reliable perception-to-language grounding; safety constraints during exploration.
- Scalable foundation-model training with partial rollouts at cluster scale
- Sectors: cloud providers, large AI labs
- What could emerge: Distributed training stacks that exploit BAPO to manage extreme staleness across thousands of nodes, reducing collapse and improving throughput.
- Tools/products/workflows:
- “Cluster-wide adaptive clipping services” that broadcast bound updates; staleness-aware schedulers optimizing replay vs. fresh rollouts.
- Assumptions/dependencies: Efficient telemetry for entropy/contribution metrics; coordination overhead manageable at scale.
- Token-level or layer-wise adaptive trust regions
- Sectors: research, algorithm development
- What could emerge: Extensions of BAPO that adapt bounds per token, per layer, or per context type (e.g., reasoning vs. summarization segments).
- Tools/products/workflows:
- Fine-grained clipping controllers leveraging token priors, uncertainty estimates, or entropy gradients.
- Assumptions/dependencies: More complex modeling and compute overhead; careful regularization to avoid instability.
- Continual learning and federated feedback integration
- Sectors: enterprise, on-device AI
- What could emerge: Use BAPO to integrate intermittent, stale user feedback logs without regenerating full trajectories, enabling cost-efficient continual improvement.
- Tools/products/workflows:
- Federated replay buffers with policy version tags; privacy-preserving advantage estimation; adaptive clipping per client cohort.
- Assumptions/dependencies: Privacy and data governance; strong reward proxies; heterogeneity across clients.
- Energy-aware training policy recommendations
- Sectors: energy, sustainability policy
- What could emerge: Guidance that promotes entropy-preserving off-policy RL (like BAPO) to reduce redundant rollouts and energy use in large-scale training.
- Tools/products/workflows:
- “Carbon dashboards” tied to replay usage and entropy stability; policy incentives for energy-efficient training choices.
- Assumptions/dependencies: Verified energy savings across diverse tasks; alignment of incentives for labs and cloud providers.
- Cross-domain generalization and safety studies
- Sectors: academia, standards bodies
- What could emerge: Empirical frameworks testing the Entropy-Clip Rule and BAPO across tasks beyond math (code generation, planning, multimodal), informing best practices.
- Tools/products/workflows:
- Benchmark suites tracking exploration vs. exploitation; ablation libraries comparing fixed vs. adaptive clipping on varied reward landscapes.
- Assumptions/dependencies: Representative datasets; robust evaluation protocols; transparency of training runs.
Notes on feasibility across applications:
- BAPO assumes PPO/GRPO-style objectives with accessible importance weights and advantage signals.
- The choice of the positive-token contribution threshold (ρ0) and movable clipping ranges affects exploration/exploitation balance; defaults may need domain-specific tuning.
- Rewards must adequately reflect task quality; poor rewards can negate stability gains.
- Entropy stability is beneficial but must be balanced to avoid tail degradation and over-exploration in production systems.
Glossary
- Adaptive Clipping: A technique that dynamically changes PPO clipping bounds to regulate update magnitudes per batch. "BAlanced Policy Optimization with Adaptive Clipping (BAPO), a simple yet effective method that dynamically adjusts clipping bounds to adaptively re-balance positive and negative contributions, preserve entropy, and stabilize RL optimization."
- Advantage: An estimate of how much better an action is than the policy’s expected action at a time step. "where denotes the estimated advantage at time step "
- Asymmetric Clipping: Setting different lower/upper clipping bounds for positive vs negative updates. "Training dynamics of asymmetric clipping experiments."
- BAPO: An RL algorithm that performs balanced policy optimization via adaptive clipping. "we propose BAlanced Policy Optimization with Adaptive Clipping (BAPO), a new method for stable and effective off-policy RL."
- Behavior Policy: The rollout policy that generates data in off-policy RL. "where the rollout policy (behavior policy) differs from the training policy (target policy)"
- Clip-Higher: A PPO variant that raises the upper clipping bound to amplify positive updates. "prior work has proposed amplifying positive signals through the clip-higher technique"
- Clipping Bounds: The upper and lower limits used in PPO-style clipping of importance ratios. "dynamically adjusts the clipping bounds and "
- Clipping Mechanism: PPO’s operation that clips importance ratios to enforce a trust region. "The clipping mechanism in PPO serves to implicitly enforce a trust region between the behavior and target policies, preventing overly large policy updates that could destabilize training."
- Curriculum-Based Approaches: Training strategies that schedule problem difficulty over time to stabilize or improve learning. "This observation may help explain the effectiveness of certain curriculum-based approaches"
- DCPO: An algorithm that adjusts token-level clipping using prior probabilities. "The most similar to our work is DCPO \citep{yang2025dcpo}, which adjusts token-level clipping based on token prior probabilities."
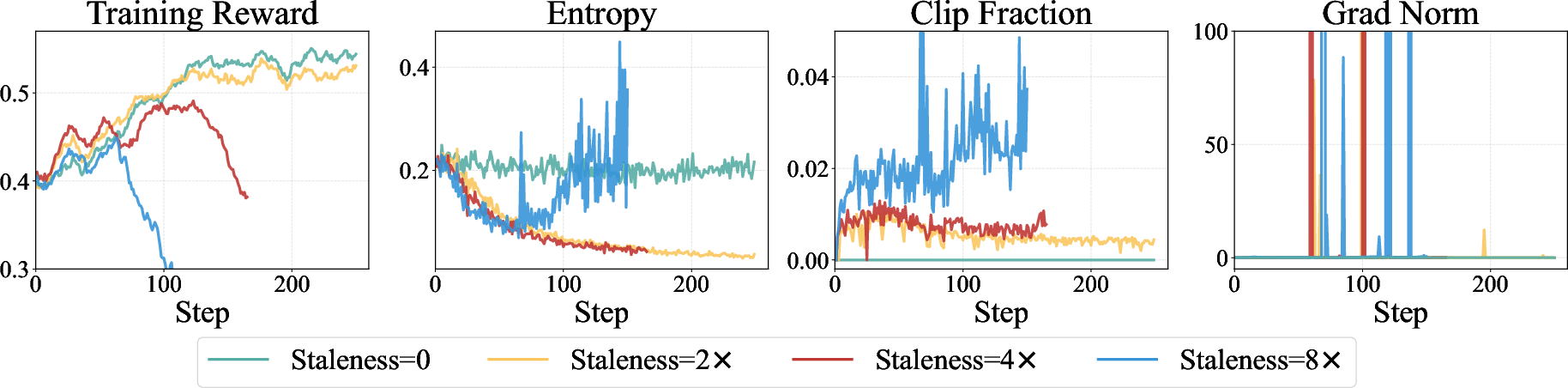
- Data Staleness: The age/mismatch of training data relative to the current policy in off-policy RL. "increasing data staleness leads to unstable optimization, exploding gradient and even collapse."
- Entropy-Clip Rule: A principle showing how clipping determines which updates change policy entropy. "We term this as the Entropy-Clip Rule."
- Exploration–Exploitation Balance: Maintaining sufficient exploration while capitalizing on learned behaviors. "achieving a better balance between exploration and exploitation."
- Gradient Explosion: Instability where gradients grow without bound, destabilizing training. "may cause gradient explosions"
- GRPO: Group Relative Policy Optimization for LLM reasoning. "We perform experiments under different levels of data staleness using the popular GRPO algorithm."
- Group-Based Rewards: Rewarding groups of trajectories to encourage long-horizon reasoning. "GRPO enhances long-horizon reasoning through group-based rewards."
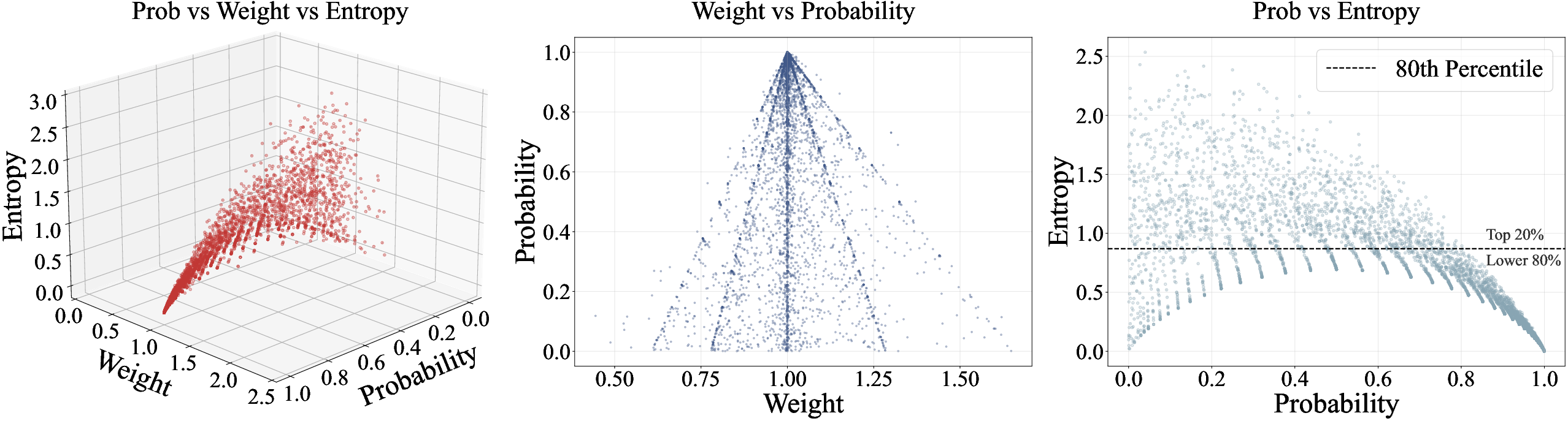
- Importance Sampling (IS) Weights: Weights correcting distribution mismatch between behavior and target policy. "tokens with either very high or very low IS weights tend to have low probabilities."
- Off-Policy Reinforcement Learning: RL where training policy differs from the rollout (behavior) policy. "off-policy RLâwhere the rollout policy (behavior policy) differs from the training policy (target policy)âemerges as particularly promising"
- On-Policy Training: RL where rollout and target policies are the same. "on-policy trainingâwhere rollout and target policies coincideâremains stable across metrics"
- Partial Rollout: Infrastructure technique that resumes unfinished trajectories later to save compute. "partial rollout being particularly noteworthy"
- Policy Entropy: A measure of uncertainty/spread in the policy’s token distribution. "policy entropy declines sharply, reflecting reduced exploratory capacity and a bias toward over-exploitation."
- Policy Gradient: Gradient of expected reward used to update the policy parameters. "negative-advantage samples dominate the policy gradient"
- PPO (Proximal Policy Optimization): A policy-gradient method using clipped importance ratios. "mainstream RL algorithms for LLMs typically adopt a PPO-like surrogate objective"
- Replay Buffer: Storage for unfinished or past trajectories used for later training. "the unfinished portion is stored in a replay buffer and resumed in later iterations"
- Surrogate Objective: An objective function approximating the true RL objective to stabilize optimization. "adopt a PPO-like surrogate objective"
- Tail Degradation: Overfitting to easy cases while failing on hard ones. "mitigates tail degradationâwhere the model overfits to easy problems but fails to handle more challenging ones"
- Target Policy: The policy being optimized during training. "training policy (target policy)"
- Trust Region: Constraint limiting policy update size to maintain stability. "implicitly enforce a trust region between the behavior and target policies"
Collections
Sign up for free to add this paper to one or more collections.

