- The paper introduces an autonomous multi-agent framework that transforms free-form user intent into continuously updatable embodied spatial benchmarks.
- It employs a modular, skill-guided pipeline with contract-driven quality control for efficient error repair and reproducible evidence binding.
- Empirical validation on UAV benchmarks demonstrates significant diagnostic power, spatial consistency, and efficiency gains over static datasets.
Autonomous Multi-Agent Benchmark Construction for Embodied Spatial Intelligence
Motivation and Problem Setting
The persistent lag in high-quality, maintainable benchmarks for embodied spatial intelligence motivates the development of autonomous construction frameworks. Contemporary advances in VLMs and MLLMs, as well as feedback-driven model improvement cycles, place intensive demands on benchmark ecosystems. Most existing benchmarks are either static datasets or exhibit limited adaptability, resulting in rapid saturation, poor diagnostic yield for new architectural advances, and high manual labor costs for expansion and maintenance. Redundancy and overlap among benchmarks—quantified through representational similarity measures—further underscore inefficiencies in current practices, hindering targeted assessment of underexplored spatial competencies. The need to systematize, modularize, and automate this process is evident.
System Architecture: Multi-Agent, Skill-Guided Pipeline
Embodied-BenchClaw introduces an autonomous, agentic framework that operationalizes user-driven intent into updatable, executable benchmark packages for evaluating embodied spatial intelligence. The system is governed by three principal agents: a planning agent that formalizes user intent into construction blueprints; a construction agent responsible for the materialization of benchmarks via a five-stage modular pipeline; and a process quality-control agent enforcing contract-based quality, provenance, and repair (Figure 1).
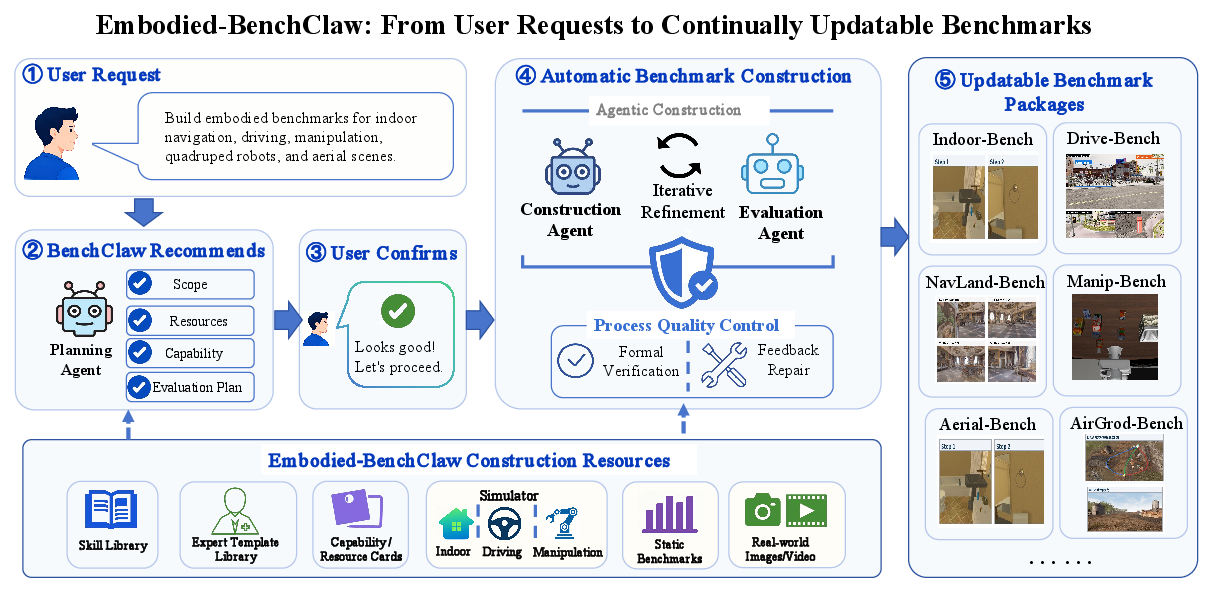
Figure 1: Overview of Embodied-BenchClaw’s agentic benchmarking system—encompassing intent specification, resource and capability selection, and the use of reusable, verifiable resources for benchmark package construction and update, orchestrated by multi-stage quality control.
At the core of Embodied-BenchClaw is a hierarchical, skill-guided workflow, articulated as stage-wise DAGs. Skills—defined through explicit input/output contracts, tool bindings, and executable validation/repair logic—are modular units for planning, data acquisition, cleaning, synthesis, and evaluation (Figure 2). The pipeline ensures traceability and repair at fine granularity: failed artifacts are identified via provenance, and repair is restricted to localized subgraphs, maximizing efficiency and debuggability while minimizing computational and annotation overhead.
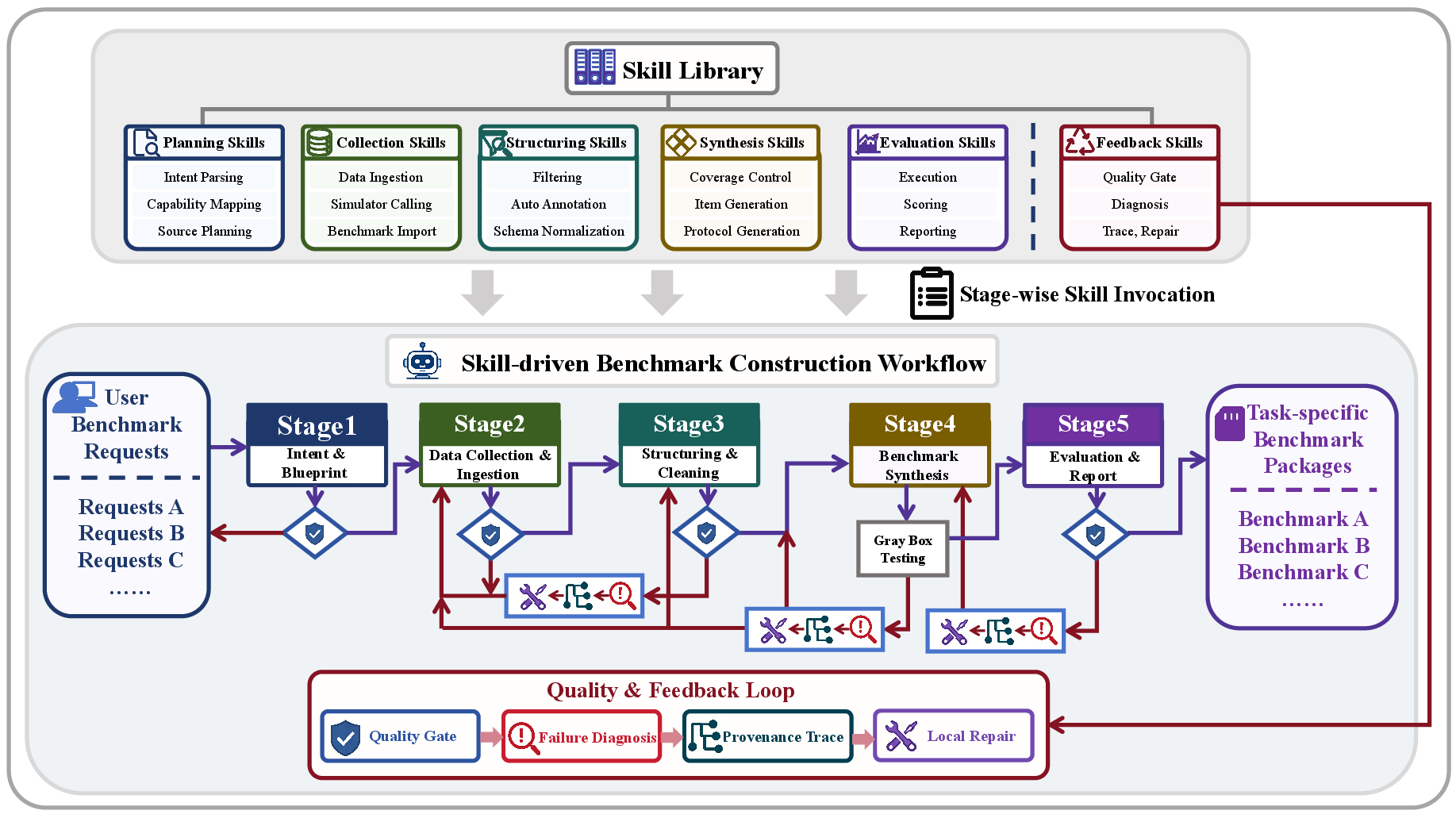
Figure 2: Skill-driven, staged benchmark construction in Embodied-BenchClaw—encompassing intent blueprinting, data collection, structuring/cleaning, synthesis, and evaluation, with embedded quality gates and local repair.
The mechanism further incorporates reusable expert templates and capability/resource cards—codifying both epistemic patterns for question generation and formalizing the resource-action space for various data sources and toolchains. This structured modularity facilitates straightforward extension to novel embodied embodiments, sensors, or reasoning skill categories.
Quality Assurance: Contract-Guided Verification and Repair
BenchClaw’s process-level quality control is realized as contract-driven verification at every skill node. Contracts not only stipulate formal schema and evidence requirements but also enforce constraints on input/output artifact validity, answer derivability, scoring executability, ambiguity, and redundancy within the generated benchmark package. Upon contract violation, localized repair is triggered via artifact dependency tracking—contrasting starkly with prior approaches that re-execute entire workflows or apply ad hoc error mitigation solely as post-processing.
This mode of operation produces benchmarks that are not only reproducible and inspectable but also accompanied by rich provenance (e.g., derivation chains for reference answers, evidence bindings, and scoring scripts).
Benchmark Instantiation and Scenario Coverage
Embodied-BenchClaw has instantiated six classes of benchmarks—spanning indoor and outdoor spatial reasoning, object manipulation, quadruped robot navigation, UAV/aerial-view understanding, and static benchmark refinement. These settings encapsulate a diversity of embodied agents, sensory modalities, data sources (simulator-based, real-world images, user-provided, and legacy datasets), and spatial action constraints.
Each output package contains not just QA items, but also structured evidence records (e.g., object masks, semantic maps, trajectories), reference answers with derivational traces, executable scoring protocols, model leaderboard logs, and update/diff suggestions for continual refresh.
Experimental Validation
Comprehensive experiments substantiate Embodied-BenchClaw’s advances in:
- Coverage: The system reliably supports a broad spectrum of embodied tasks, data modalities, and agent embodiments, delivering standardized benchmark packages for diverse settings.
- Reliability and Evidence Grounding: Benchmarks pass stringent quality gates for evidence binding, schema compatibility, and answer derivability, with high valid yields and human acceptability.
- Spatial Consistency and Action Feasibility: Artifacts are executable—spatial relations, navigation, and manipulation constraints are verified against geometric and physical requirements.
- Process Controllability and Repair: Localized repair enables high sample validity and efficient error correction, evidenced by high repair success rates and reduced manual intervention.
- Diagnostic Power: Produced benchmarks achieve substantial model separability on state-of-the-art VLMs/MLLMs, as shown in detailed evaluation of UAV/aerial-view spatial understanding. For instance, the average gap between vision-language and blind (language-only) performance on a 5,000-item UAV benchmark exceeds 35%, with closed- and open-source models exhibiting differentiated skill profiles across question types.
- Efficiency: Compared to human-assisted and LLM-only baselines, Embodied-BenchClaw attains dramatically lower human review times, lower cost per valid sample, and supports efficient benchmark updates for new capability emergence.
Empirical Results: UAV/Aerial-View Benchmark
The UAV/aerial-view benchmark—constructed via BenchClaw—comprises 5,000 items spanning object recognition, counting, spatial relation, area-scale, and depth reasoning. Vision-LLMs achieve an average score of 65.39%, versus a blind baseline of 29.82% (random: 33.3%), reflecting strong visual evidence dependencies. Model-wise, GPT-5.5 achieves 74.13%; Qwen3.6-27B achieves 71.27%. Performance stratifies by question type: binary comparison and ranking tasks are higher-scoring (>80%), while set/integral reasoning (multi-choice, interval selection) exposes consistent model weaknesses.
While systems such as Dynabench (Kiela et al., 2021), BenchAgents (He et al., 2024), and AutoBencher (Li et al., 2024) provide partial automation and incorporate agents for pipeline orchestration, their applicability to embodied spatial tasks remains limited. Code2Bench (Chen et al., 23 Mar 2026) and PRDBench (Fu et al., 28 Oct 2025) serve code-centric or workflow automation, not physically-grounded spatial reasoning. EmbodiedBench (Yang et al., 13 Feb 2025) and RoboCasa (Nasiriany et al., 2024) provide valuable simulation-based embodied evaluation, but the automated construction process is limited in scope and not systematically modularized for scalability, targeted repair, and evidence diagnosis.
Embodied-BenchClaw advances the field by (i) fully automating the transformation from free-form user intent to continuous, agent-updatable embodied spatial benchmarks, (ii) introducing skill- and contract-driven modularity and quality control, and (iii) empirically validating cross-domain coverage, diagnostic depth, and operational efficiency.
Implications and Future Directions
Practically, Embodied-BenchClaw enables scalable, low-overhead evaluation aligned with the rapidly evolving capabilities of VLMs/MLLMs in physically situated tasks. The system’s modular approach offers extensibility to new domains—such as interactive, real-time robotic control; sensor fusion; and cross-agent communication—by composing new skills, templates, and capability cards. Theoretically, this framework points toward a future of dynamic, agentic benchmarking ecosystems with continual feedback loops for both evaluation and benchmark generation, closing the model-benchmark update gap.
Potential future developments may include closed-loop benchmarking (with embodied robots in real environments), integration with real-world actuation feedback, higher-order reasoning benchmarks (temporal, causal, or multi-agent), or adaptive curriculum construction for model diagnosis and improvement.
Conclusion
Embodied-BenchClaw introduces a rigorously agentic, modular, and contract-governed approach for the autonomous construction, execution, and maintenance of embodied spatial intelligence benchmarks. Its skill-DAG architecture and process-level quality control provide a clean separation of concerns, ensuring traceability, evidence-centered reasoning, and reduced redundancy. Empirical results demonstrate not only high reliability and efficiency gains but also robust diagnostic capabilities for modern VLMs/MLLMs—offering a scalable path forward for embodied AI evaluation.

