- The paper's main contribution is the first unified, photorealistic benchmark for UAV embodied search and rescue that integrates semantic reasoning and long-horizon planning.
- It employs Unreal Engine 5 and AirSim to simulate diverse, event-driven environments with 13 weather types and realistic UAV flight physics.
- Empirical evaluation shows aerial-adapted agents outperform ground-based methods, yet all exhibit significant challenges in safety and efficiency.
ESARBench: A Comprehensive Benchmark for Embodied UAV Search and Rescue Agents
Embodied Artificial Intelligence for aerial robotics is rapidly transitioning from ground-based navigation to 3D, real-world heterogeneous environments, with Search and Rescue (SAR) being a high-stakes, archetypal application domain. While advances in Multimodal LLMs (MLLMs) have augmented UAVs' semantic reasoning and decision-making capabilities, existing SAR research remains tightly coupled to perception-path planning stacks and lacks a unifying, realistic benchmark for embodied intelligence assessment. "ESARBench: A Benchmark for Agentic UAV Embodied Search and Rescue" (2605.01371) addresses this deficit by proposing the Embodied Search and Rescue (ESAR) task and establishing a new photorealistic, event-driven, and multi-metric benchmark for UAV-based SAR agents.
The ESAR task paradigm compels UAV agents to actively explore large-scale, complex terrains, sequentially discover and semantically interpret mission-relevant clues, and localize victims under uncertain, dynamic environmental conditions. Unlike traditional instruction-following or narrow-scope navigation, ESAR combines open-ended perception, cognitive scene understanding, spatial memory, and long-horizon planning, aligning evaluation criteria with the cognitive and operational demands of real-world SAR.
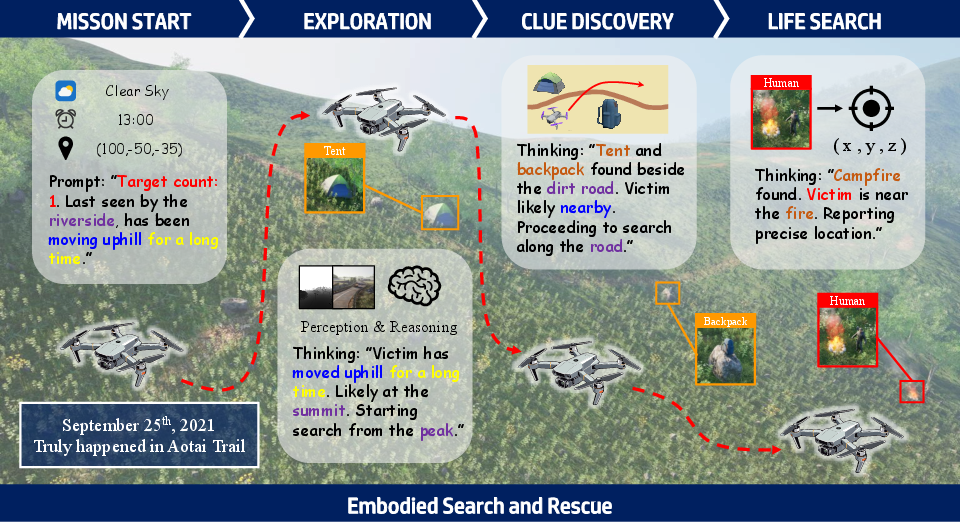
Figure 1: Illustration of the ESAR workflow, in which the UAV agent integrates continuous perception, clue discovery, and adaptive reasoning across four operational phases, culminating in precise victim localization.
The ESARBench platform establishes a rigorous simulation foundation for embodied agent evaluation by leveraging Unreal Engine 5 for high-fidelity terrain rendering and AirSim for accurate UAV flight physics. Four large-scale environments—modeled after high-incidence SAR regions in China (alpine, desert, snowy peak, and coastal cliff)—are reconstructed using real-world GIS and 12m DEM data, guaranteeing both photorealistic visuals and topographical authenticity. The agent's challenge space is further diversified with 13 distinct weather types and day-night cycles, forcing robust adaptation to rapidly shifting visibility and physics constraints.
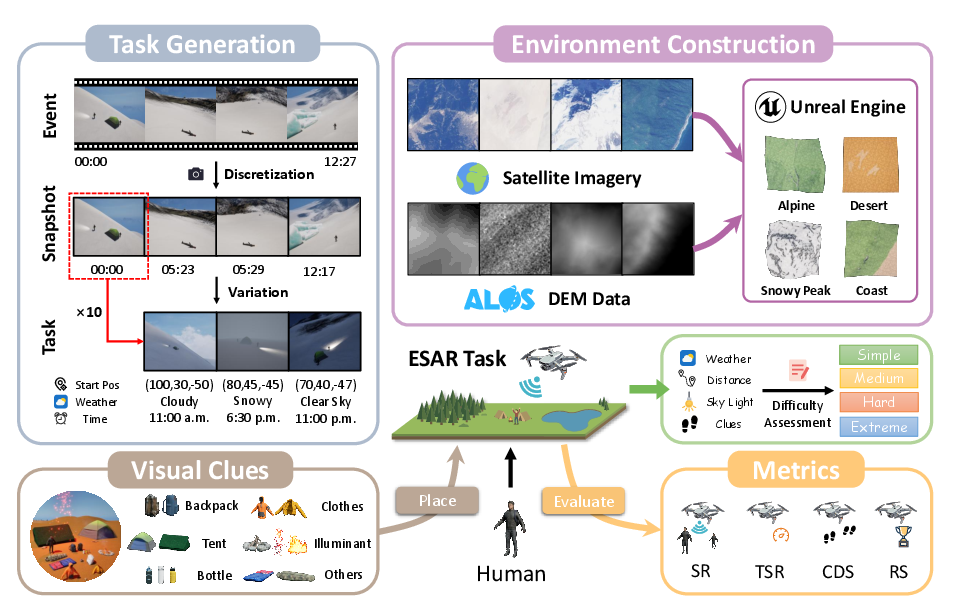
Figure 2: Pipeline for high-fidelity environment construction and stochastic, complexity-stratified ESAR task generation using real event-driven logic and GIS data integration.
Critical mission clues (tents, backpacks, bonfires, etc.) and victims are placed using an "Event-Snapshot-Task" hierarchy rooted in actual historical SAR cases. Each "Event"—a real, temporally-extended SAR incident—is discretized into static time snapshots with variable initializations, yielding 600 tasks across four stratified difficulty levels. Sensor simulation (RGB, depth, LiDAR, IMU, GPS) enables multi-modal input policy learning.
Figure 3: Visualization of the four ESARBench environments, each mapped to a distinct topological archetype and supporting diverse environmental dynamics.
Dataset Structure, Stratification, and Evaluation Metrics
The dataset design follows a principled hierarchical structure: Events (historical SAR narratives) → Snapshots (fixed temporal configurations) → Tasks (instantiated with stochastic parameters). Task difficulty incorporates initial distance, meteorological challenge, illumination, number of victims, and presence/absence of "strong clues."
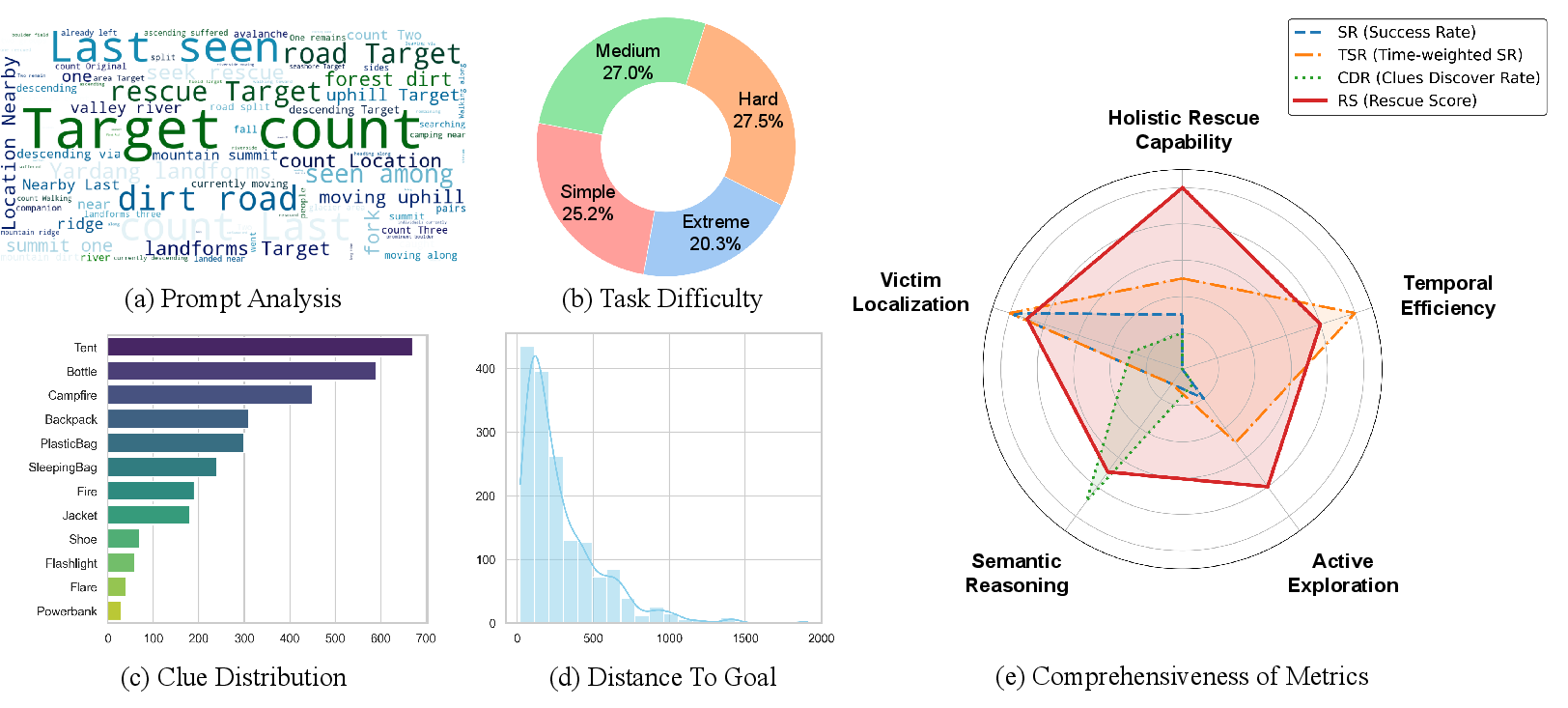
Figure 4: Dataset statistics, including prompt diversity, task difficulty distribution, clue type frequency, initial distance histogram, and evaluation metric spectrum.
Comprehensive evaluation is performed via four core metrics:
- Success Rate (SR): Ratio of victims localized within an error threshold, computed via Hungarian bipartite assignment.
- Time-weighted Success Rate (TSR): Efficiency-aware SR penalizing high task completion times.
- Clue Discovery Score (CDS): Joint metric balancing spatial accuracy and strict semantic correctness using LLM-based evaluation logic.
- Rescue Score (RS): Aggregate metric integrating SR, CDS, efficiency, and flight safety (with explicit penalty for mission-crashing policies).
Baseline Agents and Empirical Evaluation
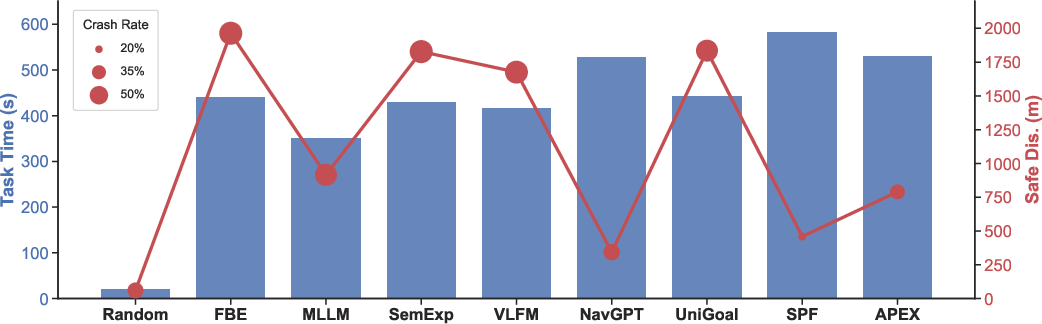
Baseline architectures span random policies, classical frontier-based and semantic exploration, ground and aerial ObjectNav agents (with and without MLLM reasoning), and state-of-the-art MLLM-powered UAV control. All baselines use a unified interface for fairness, with the YOLO-World RGB-D module for object and clue detection, and Qwen3.5-Plus as the base MLLM where applicable.
Key empirical findings include:
Notably, all evaluated agents fall far short of solving ESAR tasks: the highest CDS obtained is 4.14, and best SR is 13.89 on a 100-point scale, underscoring the unresolved difficulty imposed by multi-modal exploration, semantic clue integration, and safe, efficient 3D navigation.
Implications and Future Research Directions
ESARBench exposes severe challenges for SAR-oriented embodied agents, demanding progression beyond isolated perception or navigation toward joint semantic reasoning and adaptive exploration in unstructured 3D domains. The benchmark unveils bottlenecks in spatial memory (required for large-scale environments), aerial adaptation (for shifting viewpoints and physics), and long-horizon temporally-extended planning.
The roadmap for future development, conceptualized in Figure 6, foresees:
- Operational scaling: From stable open spaces to volatile, cluttered disaster environments
- Architectural complexity: Transition from single UAVs to swarming, collaborative multi-agent systems
- Task diversification: Inclusion of auxiliary objectives (risk assessment, supply delivery, hidden victim detection)
- Multi-modal fusion: Expansion to non-visual modalities (thermal, acoustic, etc.)
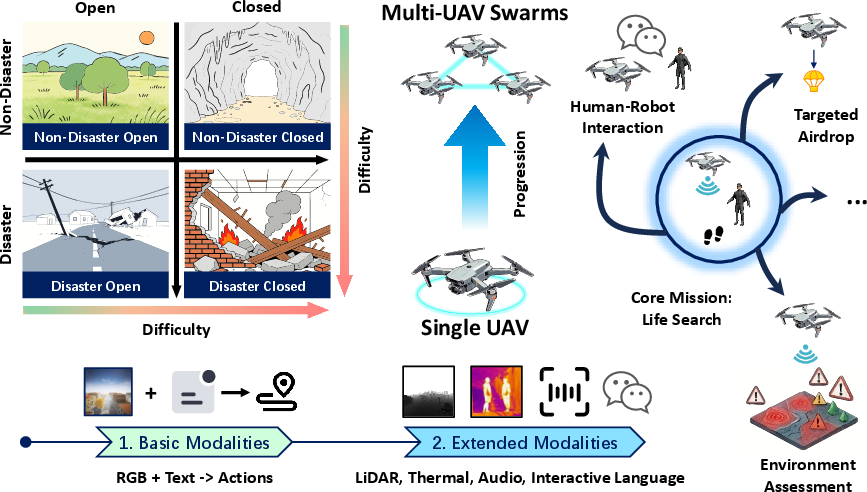
Figure 6: ESAR research roadmap detailing scenario complexity, agent architecture advancement, auxiliary task expansion, and integration of richer sensor modalities.
The authors validate the approximation of static environment snapshotting for embodied evaluation, given that real-world SAR victims have negligible mobility relative to search agents; however, capturing rare "slip-through" adversarial behaviors remains an open research frontier. Real-world deployment will further require simulation-to-reality transfer enhancements, robustness to sensor corruption, and active uncertainty modeling.
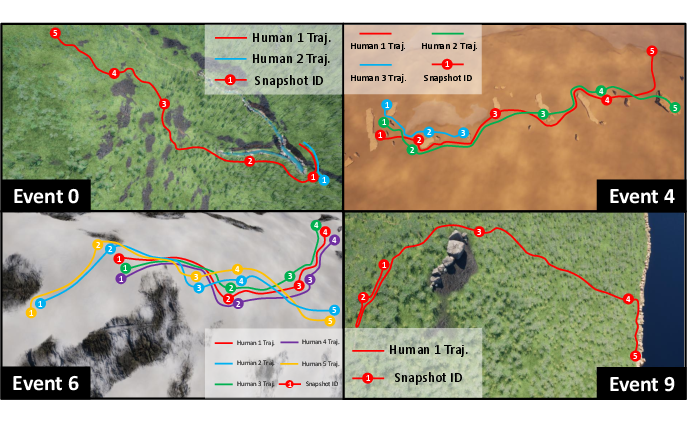
Figure 7: Visualization of four real SAR events employed for task generation, illustrating the mapping from real-world incident timelines to simulation task instances.
Conclusion
ESARBench provides the first unified, photorealistic, and semantically rich benchmark for embodied UAV agents in search and rescue. Experimental analysis demonstrates that the integration of robust perception, grounded semantic reasoning, spatial memory, and policy adaptation remains a major open problem. ESARBench is positioned to advance embodied AI by standardizing evaluation and driving research toward truly agentic, aerial, socially critical intelligence in SAR contexts. Further developments will necessarily focus on sensor fusion, collaborative architectures, and transfer learning for robust real-world deployment.