- The paper introduces RoboBench, a comprehensive benchmark evaluating MLLMs as embodied brains for complex robotic manipulation.
- It systematically measures instruction comprehension, perception reasoning, generalized planning, affordance prediction, and failure analysis.
- Experimental results reveal significant performance gaps in implicit instruction processing and spatial-temporal reasoning, highlighting key areas for improvement.
RoboBench: Evaluating Multimodal LLMs as Embodied Brains
Introduction
The paper "Robobench: A Comprehensive Evaluation Benchmark for Multimodal LLMs as Embodied Brain" (2510.17801) presents RoboBench, a benchmark specifically designed for evaluating the cognitive capabilities of Multimodal LLMs (MLLMs) when applied to complex robotic manipulation tasks. RoboBench addresses deficiencies in existing benchmarks by offering a systematic evaluation across five core dimensions: instruction comprehension, perception reasoning, generalized planning, affordance prediction, and failure analysis. This comprehensive framework is predicated on the embodied brain model, employing MLLMs as high-level reasoning components within robotic systems, serving as a cognitive core.
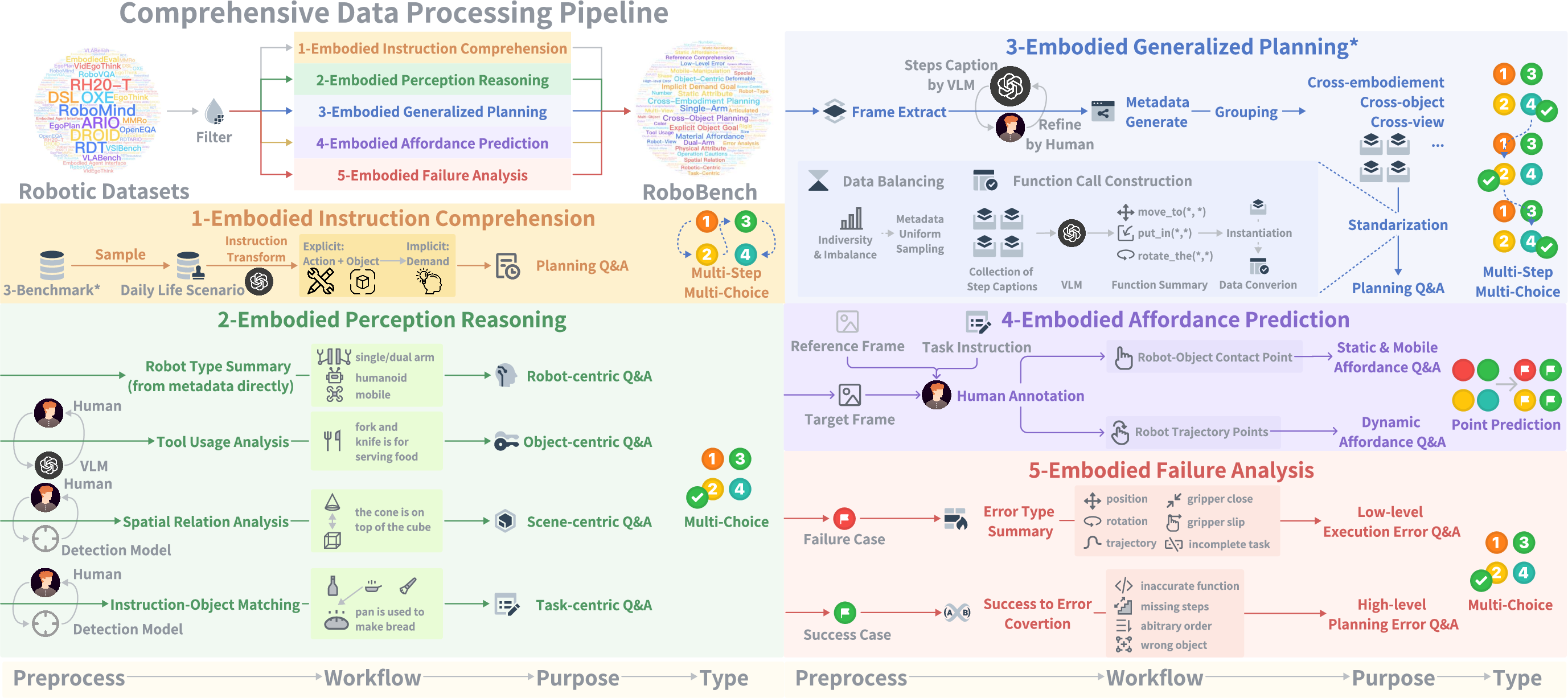
Figure 1: Dataset Construction Pipeline. RoboBench customizes data workflows for each dimension: \textcolor{orange}{orange} for instruction, \textcolor{OliveGreen}{green} for perception, \textcolor{blue}{blue} for planning, \textcolor{purple}{purple} for affordance, and \textcolor{red}{red} for reflection.
Core Capabilities and Benchmark Construction
Instruction Comprehension
RoboBench evaluates the ability of MLLMs to interpret both explicit and implicit task instructions, transforming them into actionable plans. This dimension simulates real-world scenarios where human instructions often lack explicit syntactic structure, requiring advanced context-aware reasoning.
Perception Reasoning
This dimension assesses the MLLM's capability to perceive task-relevant information in complex scenes. RoboBench evaluates four aspects: robotic-centric views, object-centric attributes, scene-centric spatio-temporal relations, and task-centric object identification. These tests challenge models on their ability to integrate perception with functional task requirements.
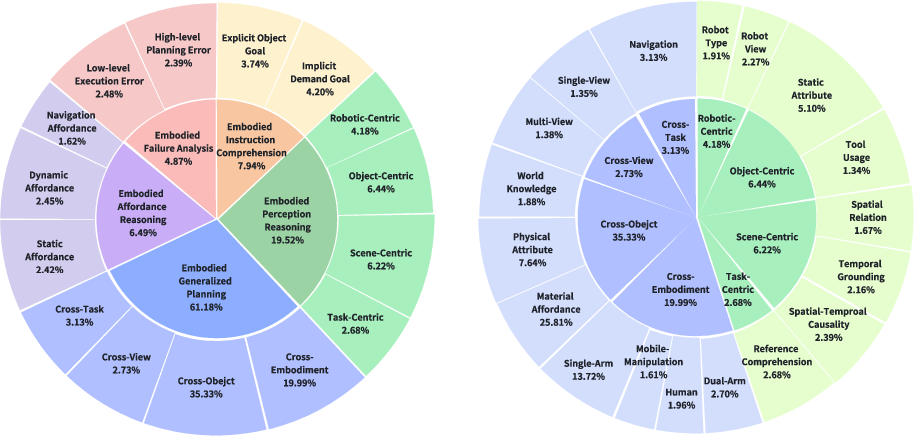
Figure 2: Dimension Distribution of RoboBench.
Generalized Planning
RoboBench introduces a unique MLLM-as-world-simulator framework for planning tasks, evaluating models on their ability to generalize planning across different robotic embodiments, object interactions, view perspectives, and task types.
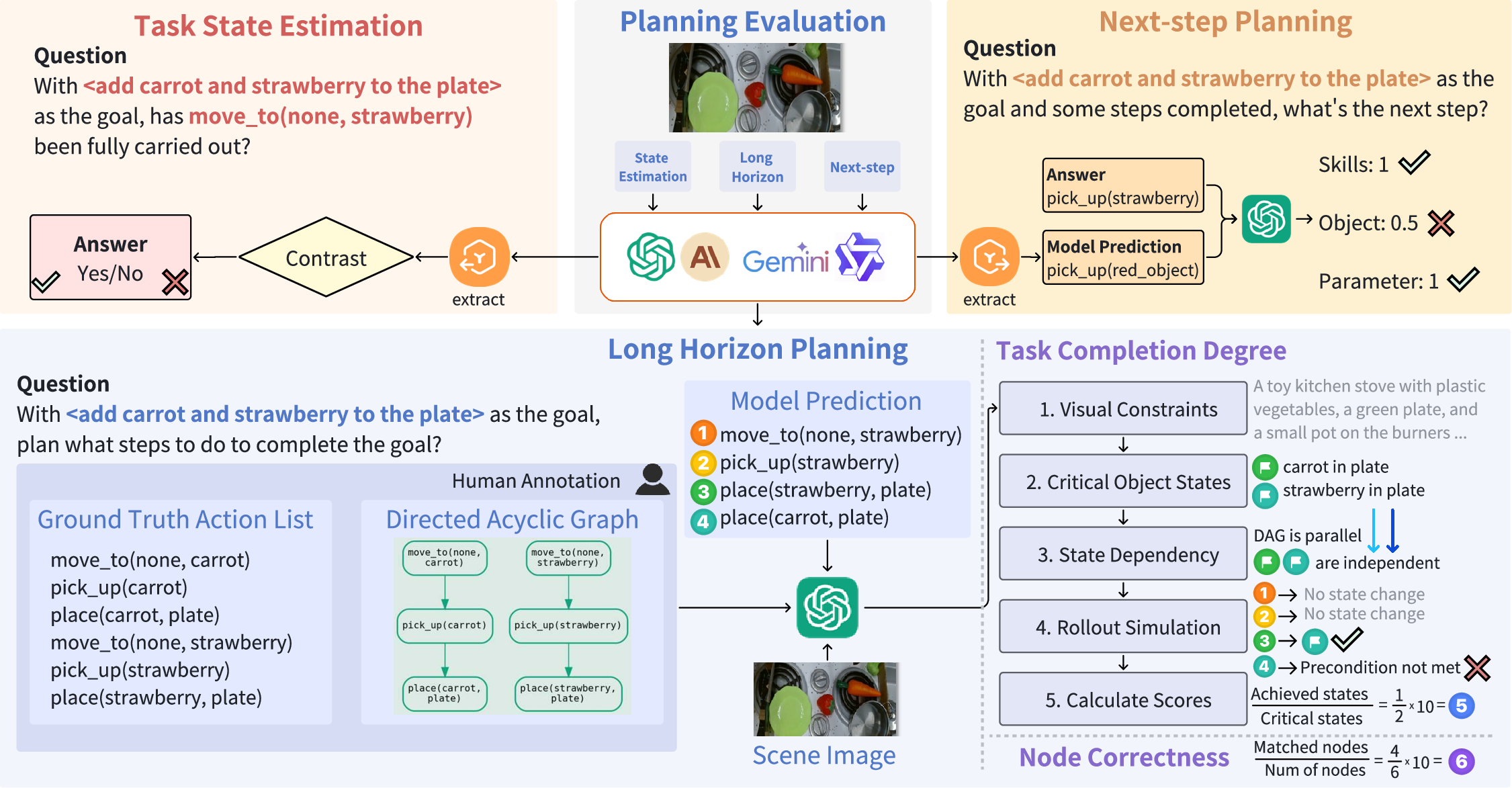
Figure 3: Planning Evaluation Pipeline. The planning benchmark includes three task types: long-horizon planning, next-step planning, and task state estimation. They are evaluated respectively with our proposed MLLM-as-world-simulator framework, LLM scoring, and binary accuracy.
Affordance Prediction
This aspect tests the model's ability to provide refined spatial cues for task execution, ensuring that sub-goals align with low-level control actions required for successful task completion.
Failure Analysis
This dimension looks at the model's capability to detect, diagnose, and rectify execution or planning errors in the face of task failures, a critical component of robust and adaptable robotics.
Evaluation Framework and Metrics
RoboBench introduces a novel MLLM world-simulator framework for evaluating long-horizon planning. The framework evaluates both structural plan correctness and embodied feasibility, assessing whether proposed plans achieve key object-state changes. Additional metrics include multiple-choice accuracy for perception and failure analysis tasks, and Euclidean and RMSE for affordance prediction. Each metric aligns with specific task requirements, offering insights into the nuances of embodied cognition.

Figure 4: Representative error cases from our evaluation.
Experimental Results
Experiments with state-of-the-art MLLMs, including Gemini-2.5-Pro, demonstrate fundamental performance disparities, particularly in implicit instruction comprehension and complex planning scenarios. The evaluation reveals the gap between human-level and current model performances, with models struggling with implicit instructions, spatial-temporal reasoning, and execution failure diagnosis.
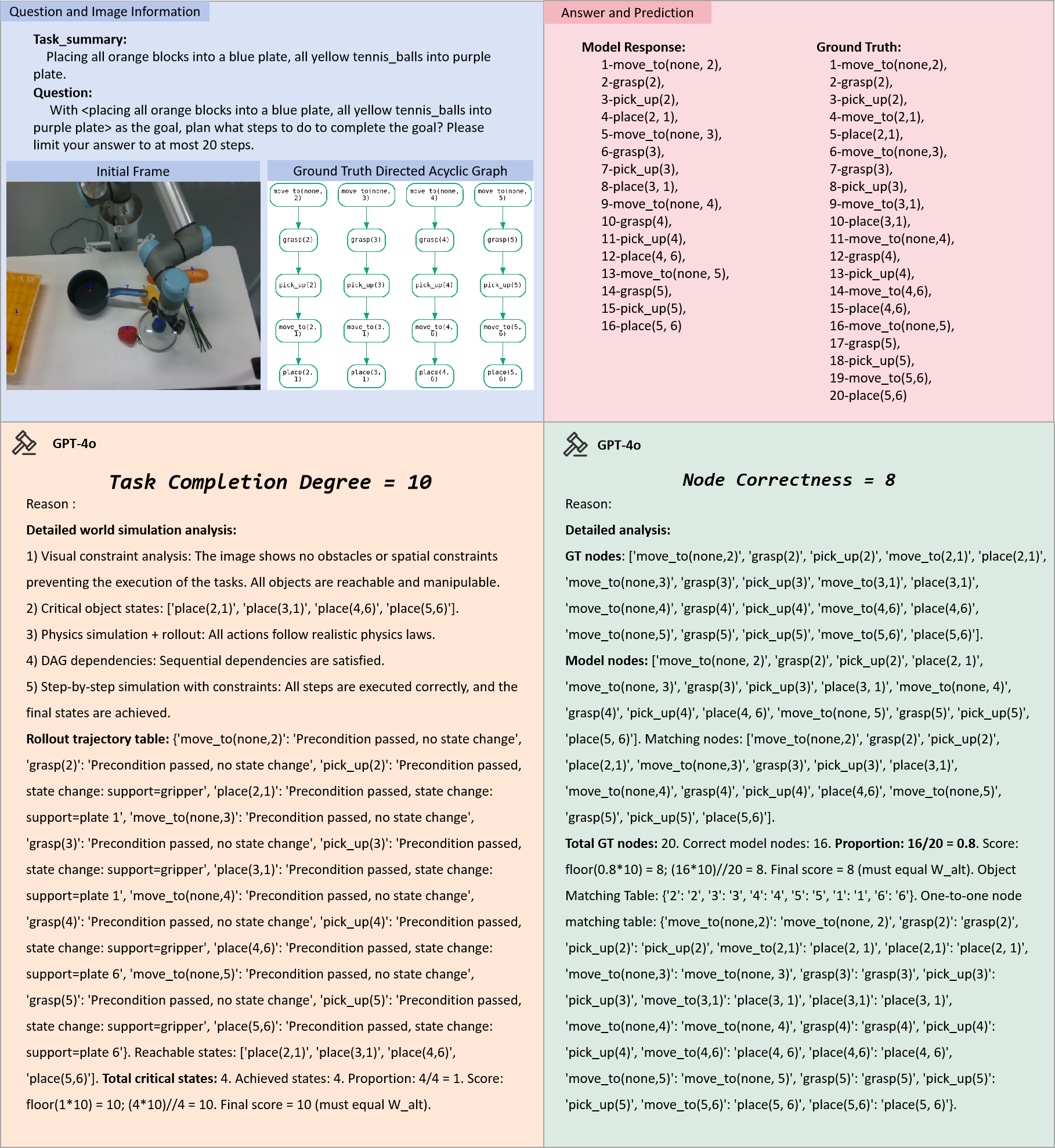
Figure 5: Successful evaluation examples illustrating robustness.
Conclusion
RoboBench provides a holistic framework for assessing the high-level cognitive capabilities of MLLMs in robotic manipulation contexts. Through diverse task dimensions and comprehensive evaluation metrics, RoboBench seeks to guide the improvement of MLLMs, steering the development of robust artificial intelligence systems capable of complex, integrated reasoning in dynamic environments. This benchmark is poised to serve as a crucial tool for advancing the state of embodied AI research, equipping MLLMs with the ability to effectively operate as the cognitive core in interactive, real-world robotic systems.