ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
Abstract: Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively uncover what is unseen - occluded structure, dynamics, containment, and functionality that cannot be resolved from passive sensing alone. We move beyond prior formulations of spatial intelligence that assume oracle observations by recasting the observer as an actor. We introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence spanning 10 task categories and 29 subcategories built on OmniGibson, grounded in Spelke's core knowledge systems. Agents must decide what abilities to deploy - perception, locomotion, and manipulation - and how to sequence them to actively accumulate task-relevant evidence. We conduct extensive experiments on state-of-the-art MLLMs and find that active exploration substantially outperforms passive counterparts, with agents spontaneously discovering emergent spatial strategies without explicit instructions, while random multi-view often adds noise rather than signal despite consuming far more images. Most failures stem not from weak perception but from action blindness: poor action choices lead to poor observations, which in turn drive cascading errors. While explicit 3D grounding stabilizes reasoning on depth-sensitive tasks, imperfect 3D representation proves more harmful than 2D baselines by distorting spatial relations. Human studies further reveal that unlike humans who seek falsifying viewpoints and revise beliefs under contradiction, models commit prematurely with high confidence regardless of evidence quality, exposing a metacognitive gap that neither better perception nor more embodied interaction alone can close.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces ESI-Bench, a big set of tests for a new kind of “spatial intelligence” in AI—how well an AI can figure out where things are and how they relate in space by actively moving around and interacting with the world. Instead of just looking at pictures, the AI acts like a person in a 3D virtual home: it can walk, turn its head, pick things up, pour water, and more. The goal is to close the perception–action loop: the AI should choose smart actions to collect the right information, then use that information to answer questions about the scene.
The big questions the researchers asked
- Can AIs do better at spatial reasoning if they actively explore (move and interact) instead of passively looking at whatever views they’re given?
- Are most mistakes due to poor “seeing” (perception) or poor “doing” (choosing the wrong actions)?
- Does building a 3D model of the scene help AI reason better, and when might it actually hurt?
- How do AIs compare to people when they can move around and investigate?
How they studied it
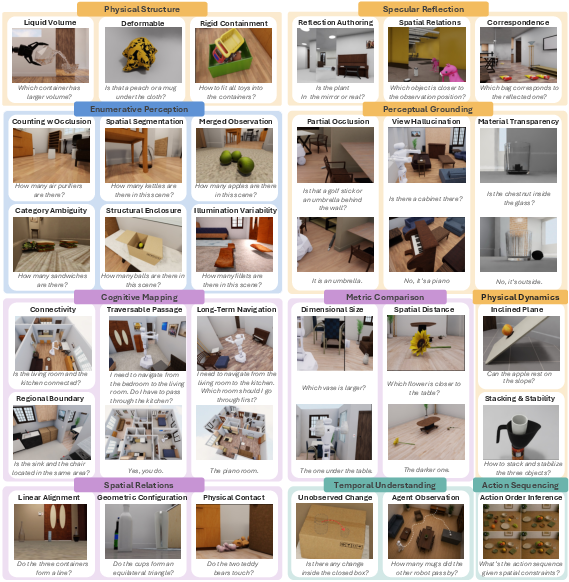
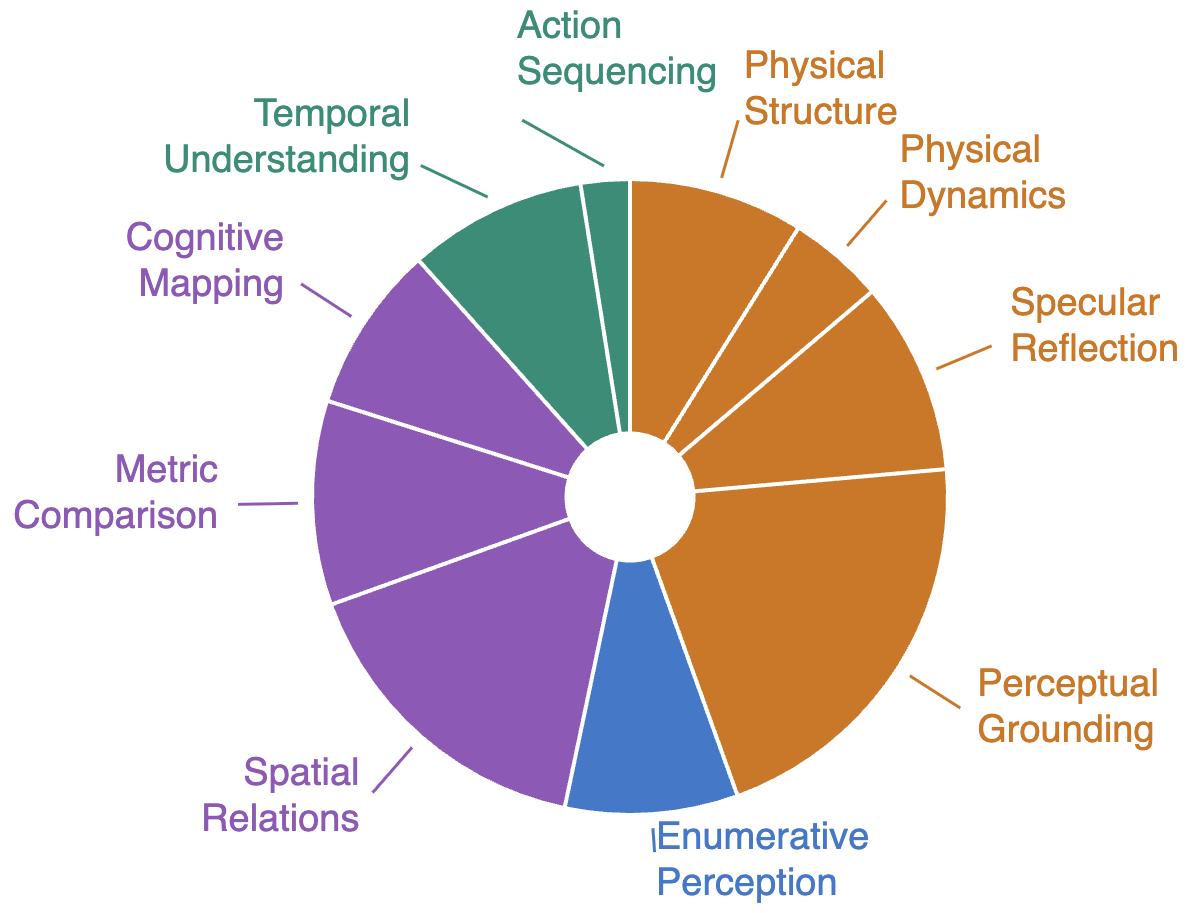
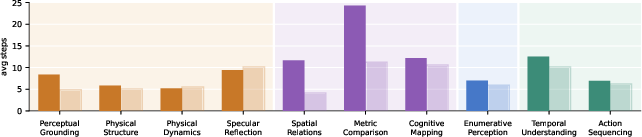
ESI-Bench is a collection of 3,081 tasks set in realistic 3D virtual environments (like homes, offices, and stores). These tasks cover 10 categories and 29 subcategories based on ideas from developmental psychology about how humans understand the world—for example:
- Objects and hidden stuff (like what’s inside a box)
- Layout and geometry (like which object is bigger or farther)
- Number and counting (even when things are partially hidden)
- Agents and actions (like figuring out what changed over time)
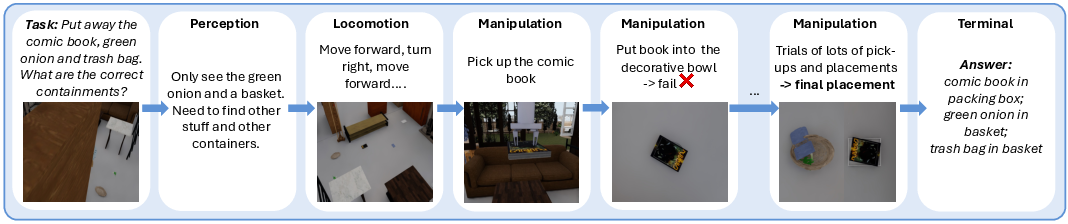
Here’s how a typical task works:
- The AI starts in a room and gets a question, such as “Is the small ball inside the glass?” or “Which cup is taller?”
- The AI has up to 30 steps to act: it can move around (walk forward, turn left), change its view (look up/down), or manipulate objects (pick up, pour, place).
- After exploring, the AI gives an answer (and how confident it is).
The team tested several conditions:
- Passive single view: one fixed image (like a typical photo test).
- Passive multi-view: 30 random views (lots of pictures, but chosen without thinking).
- Active exploration: the AI chooses its own actions and viewpoints.
- Oracle views: the “perfect” views along an expert’s ideal action path, to separate action mistakes from vision mistakes.
They evaluated advanced AI models (vision–LLMs) and also measured human performance for comparison. They also tried adding 3D scene reconstructions to see if that helps.
To make sure the tasks are fair and meaningful:
- Scenes were built in a physics-based simulator (so objects fall, roll, reflect, and fill with water realistically).
- Tasks were generated with help from a large model and then carefully checked by humans to avoid trick questions or shortcuts.
What they found (in plain language)
- Actively exploring beats passively looking.
- When AIs chose where to go and what to do, they did much better than when they just got a pile of random pictures.
- Randomly adding more views often made things worse (more noise, not more help).
- The main problem isn’t “seeing,” it’s choosing the right actions.
- If you hand the AI the ideal viewpoints (the oracle views), it usually answers correctly.
- This means many failures happen because the AI didn’t move to the right spot or didn’t try the right interaction (like looking behind an object or pouring water to reveal a cup’s capacity).
- Bad actions lead to bad views, which lead to more bad actions—a chain reaction of mistakes.
- 3D models help only if they’re accurate.
- A perfect 3D reconstruction (like a flawless map of the room) helps a lot on depth and occlusion problems.
- But an imperfect 3D model can be worse than just using 2D images because it warps the geometry and misleads the AI.
- Humans are better at “thinking about thinking.”
- People naturally move to disprove their first guess: they look from a different angle, check behind, and change their minds if evidence disagrees.
- Many AIs stick with their first idea and stay very confident—even when their evidence is weak. This “metacognitive gap” (poor self-checking) isn’t fixed just by giving them better cameras or more actions.
Why it matters
- For robots and AR assistants: To work safely and helpfully in the real world, AIs must learn to actively gather the right information—like checking if a shelf is stable before placing a heavy object, or confirming if a mug is actually full before moving it.
- For AI training: Teaching AIs to plan good actions (not just to recognize images) is key. Simply throwing more pictures at the problem isn’t enough.
- For 3D reasoning: 3D understanding is powerful but fragile—accuracy matters. Investing in reliable 3D sensing/reconstruction or ways to know when the 3D model is untrustworthy could be crucial.
- For AI safety and reliability: Closing the “metacognitive gap” (getting AIs to seek disconfirming evidence and adjust confidence) will make them more trustworthy and human-like in their problem solving.
In short, this work shows that smart action choice—knowing where to look and what to do—unlocks much better spatial understanding than passively watching. It also points to the next big challenges: teaching AIs to plan informative actions, to build and trust accurate 3D understanding, and to question their own first impressions like humans do.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point highlights what is missing or uncertain and suggests concrete directions future work could take.
- Sim-to-real transfer is untested: no evaluation on physical robots or real-world egocentric data to assess whether active strategies, 3D reasoning gains, and metacognitive findings survive domain shift beyond OmniGibson/BEHAVIOR-1K.
- Limited sensing modalities: tasks and baselines are vision-centric; the impact of depth sensors, stereo, tactile/haptics, audio, or proprioception on disambiguating occlusion, reflection, and enclosure remains unexplored.
- Constrained action space: only high-level, discrete actions (move/turn, pick/place, fill/pour) are supported; the role of richer and continuous control (open/close articulated objects, fine manipulation, tool use, grasp variants, compliant interactions) is not examined.
- No explicit penalty or metric for action inefficiency: accuracy is the main metric; there is no formal measure of information efficiency, path cost, action optimality, or exploration quality beyond an illustrative step count.
- Confidence is collected but not evaluated: the terminal action includes a confidence score c, yet no calibration metrics (e.g., ECE, Brier score, AUROC for selective answering) are reported or benchmarked.
- Passive multi-view baseline is weakly instantiated: “random multi-view” likely underestimates the utility of passive coverage; coverage-aware panoramas, next-best-view heuristics, or diversity-maximizing view sets are not evaluated.
- 3D reconstruction is evaluated with a single pipeline (VGGT): the sensitivity of performance to alternative 3D pipelines (stereo, RGB-D fusion, TSDF/NeRF, SLAM) and to reconstruction uncertainty is not analyzed.
- No uncertainty-aware 3D reasoning: how to represent and propagate geometric uncertainty to downstream reasoning (e.g., confidence-weighted scene graphs, probabilistic 3D features) is left open.
- Oracle 3D and oracle-view results may overestimate attainable gains: perfect point clouds and ground-truth trajectories are unrealistic in practice; methods to approach these or to degrade oracles to realistic noise levels are not studied.
- Learning to act is not investigated: all agents are zero-shot prompted MLLMs; the effectiveness of training (RL, IL, curricula) for action selection and evidence gathering on ESI-Bench remains unknown.
- Generalization and splits are unspecified: there is no train/val/test split for learning-based research, nor analysis of generalization to unseen scenes, object categories, materials, or task compositions.
- Generator bias persists as a risk: tasks are GPT-4o-proposed; while audited, a deeper quantitative analysis of linguistic/object bias, long-tail coverage, and robustness to alternative generators is not presented.
- Task diversity and difficulty tiers are not formalized: there is no difficulty calibration (e.g., occlusion severity, reflection complexity, clutter level) or controlled scaling to assess robustness and curriculum learning.
- Memory and mapping baselines are absent: the role of explicit SLAM/topological maps or persistent scene graphs in cognitive mapping and long-horizon tasks is not compared to purely LLM-based agents.
- Social/agent reasoning is minimal: the “agents and goal-directed actions” faculty does not include multi-agent interactions, intent inference, or social navigation; such settings remain untested.
- Limited physics coverage: beyond inclines, stacking, fluids, and deformables, richer physics (friction variability, elasticity, long-horizon causal chains, articulated constraints) and their impact on action selection are not evaluated.
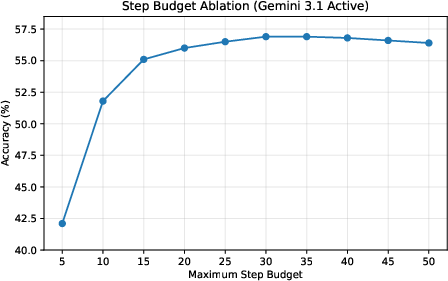
- Step-budget sensitivity is not fully characterized in the main text: the benchmark fixes T_max=30; the effect of different budgets, adaptive stopping, and budget-aware planning strategies is not systematically reported.
- Action feasibility and execution success are not scored separately: the benchmark evaluates QA accuracy rather than success of the chosen actions themselves (e.g., success/failure of pick/place), masking execution vs. reasoning errors.
- Prompting dependence is unclear: emergent strategies appear with specific prompting, but robustness to prompt style, ReAct variants, tool-use scaffolding, and self-critique/verification is not analyzed.
- Specular reflection tasks lack cross-validation with real data: it is unknown whether mirror/reflection findings in sim transfer to real optical phenomena (e.g., imperfect mirrors, lighting artifacts).
- Camera model effects are unstudied: how FOV, distortion, exposure, and motion blur influence forced perspective, size/distance judgments, and view selection is not analyzed.
- Object and environment scope is narrow: BEHAVIOR-1K covers indoor scenes; outdoor, industrial, or cluttered warehouse settings and unusual materials/geometries are not included, limiting ecological validity.
- Counting and number-representation scaling is limited: enumerative tasks are small-scale; how performance scales with larger counts, distributed across rooms, or under longer occlusion chains is unknown.
- No analysis of failure attribution granularity: while cascaded failures are noted, the benchmark does not provide per-step diagnostics (e.g., view informativeness, action regret) to localize error sources for learning.
- Closed-source model dependence: results rely on proprietary APIs (GPT-5, Gemini 3.1); reproducibility with open models, and the extent to which conclusions hold across architectures/sizes, are not assessed.
- Benchmark gamability is not ruled out: since success is QA-based, agents could hypothetically exploit priors or shortcuts (e.g., object co-occurrence) rather than truly closing the perception–action loop; stronger anti-shortcut diagnostics would help.
- Lack of formal metacognitive objectives: while a metacognitive gap is observed, there are no benchmark tasks/metrics that explicitly reward disconfirmatory search, belief revision, or information gain per step.
Practical Applications
Immediate Applications
Below are applications that can be deployed now or piloted with current tools (ESI-Bench, OmniGibson/BEHAVIOR-1K, existing VLMs/LLMs, and off‑the‑shelf 3D reconstruction). Each item names the sector(s), outlines a concrete tool/product/workflow, and flags key dependencies.
- Embodied AI evaluation and CI for robotics and software
- Sectors: software, robotics
- What: Adopt ESI-Bench as a standardized continuous-integration suite to regression-test embodied agents (navigation, manipulation, active perception) across object/layout/number/agent reasoning, with per-task attribution of “perception vs. action” errors using the paper’s passive/active/oracle paradigms.
- Dependencies/assumptions: OmniGibson/Isaac Sim setup; reproducible seeds; scenario reload via saved metadata; basic agent action APIs.
- Viewpoint-selection module to replace random multi-view scanning
- Sectors: robotics, XR/AR, mobile software
- What: Integrate an “active information acquisition” policy that plans a small number of targeted views instead of large passive sweeps, reducing latency, compute, and data noise (reflecting the finding that random multi-view often adds noise rather than signal).
- Dependencies/assumptions: Access to camera control (pan/tilt/zoom) or body pose; simple heuristics or learned policies trained/evaluated on ESI-Bench categories like Perceptual Grounding and Metric Comparison.
- Confidence-calibrated answering and abstention
- Sectors: software, robotics, customer support chatbots with perception
- What: Expose an API that returns answer + calibrated confidence (inspired by answer(ŷ, c)), with business rules to abstain/seek more evidence when c < threshold; log contradictions and force “falsifying viewpoints.”
- Dependencies/assumptions: Lightweight metacognitive wrapper around existing VLMs; threshold tuning on ESI-Bench; UX for “ask for another view.”
- 2D-first with 3D fallbacks and 3D quality gates
- Sectors: software, robotics, mapping
- What: Deploy a hybrid perception stack that uses 2D reasoning by default, upgrades to 3D only for depth-sensitive tasks, and employs a reconstruction-quality gate to avoid the harmful effects of imperfect 3D (a key finding).
- Dependencies/assumptions: A 3D quality estimator (e.g., reprojection error, completeness metrics); runtime routing between 2D/3D pipelines.
- Active counting and inventory validation in constrained spaces
- Sectors: logistics/retail, smart homes
- What: Use targeted viewpoint changes and simple manipulations (e.g., nudge, open container) to resolve occlusions and perform accurate counts (Enumerative Perception).
- Dependencies/assumptions: Basic manipulation or access; safety constraints; shelving/container metadata if available.
- QA-driven debugging of embodied agents
- Sectors: robotics, MLOps
- What: Use ESI’s oracle trajectories to isolate “action blindness” vs. “perceptual ceiling,” then iterate on planning policies where oracle views close the gap, and on perception when oracle views don’t help (e.g., specular reflections).
- Dependencies/assumptions: Logging of action–observation–answer chains; dataset slices by category.
- Training curriculum for active perception and action sequencing
- Sectors: robotics, education
- What: Use ESI categories (e.g., Action Sequencing, Physical Dynamics) to build staged curricula for VLA models and human training in simulators.
- Dependencies/assumptions: Simulator-in-the-loop RL/IL harness; step-budget constraints; reward shaping from task answers.
- AR guidance to “move your camera here” for better measurements
- Sectors: consumer mobile/XR, education
- What: Smartphone apps prompt users toward falsifying viewpoints or top-down angles to reduce forced-perspective errors in size/distance estimation (Metric Comparison).
- Dependencies/assumptions: Device motion tracking; lightweight viewpoint policy; UI to instruct users.
- Warehouse/bin-picking viewpoint control
- Sectors: manufacturing, logistics
- What: Add pre-grasp active view planning (tilt for occlusion, top-down for contact) to improve stability estimation and grasp success (Physical Contact, Stacking & Stability).
- Dependencies/assumptions: Robot kinematics; depth sensing or stereo; collision-safe camera motions.
- Safety and privacy by design via selective sensing
- Sectors: policy, compliance, consumer robotics
- What: Replace indiscriminate scene capture with task-targeted sensing to minimize extraneous data collection, aligning with privacy-by-design and lowering compute/energy.
- Dependencies/assumptions: Policy guidelines; audit logs of action/view choices; on-device processing where feasible.
- Embodied science and cognitive studies
- Sectors: academia (cognitive science, AI)
- What: Use ESI’s Spelke-grounded taxonomy to study human vs. model strategies (e.g., belief revision under contradiction, confidence calibration), designing interventions that specifically target the metacognitive gap.
- Dependencies/assumptions: Human-subject protocols; reproducible ESI tasks; confidence reporting interfaces.
- “3D sanity checker” tool
- Sectors: software, robotics
- What: A library that detects and flags geometric artifacts (holes, drift, self-intersections) and switches the agent to 2D-based reasoning where 3D is unreliable.
- Dependencies/assumptions: Access to recon meshes/point clouds; geometric diagnostics; routing policy.
- Education modules for spatial reasoning
- Sectors: education, edtech
- What: Courseware and interactive labs in VR/AR that teach geometry, topology, and basic physics via embodied tasks (Cognitive Mapping, Physical Structure).
- Dependencies/assumptions: Classroom-friendly simulators; scaffolded tasks; teacher dashboards.
Long-Term Applications
These depend on further research, scaling, or real-world integration (e.g., robust actuation, 3D sensing, certification, safety cases).
- Home service robots that “look before they act”
- Sectors: consumer robotics, eldercare
- What: Assistants that proactively select informative viewpoints, test hypotheses (e.g., is the mug empty?), and sequence actions safely (pour, open, lift).
- Dependencies/assumptions: Reliable manipulation hardware; robust sim2real transfer; household safety and liability frameworks; on-device confidence calibration.
- Certified evaluation standards for embodied AI
- Sectors: policy, standards, procurement
- What: Regulatory or industry benchmarks requiring agents to pass active perception tests, report calibrated confidence, and demonstrate recovery from failure cascades before deployment in homes, hospitals, or factories.
- Dependencies/assumptions: Standards bodies; third-party test labs; scenario coverage derived from ESI categories; reporting and audit trails.
- Industrial inspection with micro-drones or mobile manipulators
- Sectors: energy/utilities, construction, mining
- What: Agents that plan minimal, high-value viewpoints to detect defects under occlusion, handle specular/transparent surfaces, and revise plans under contradictory evidence.
- Dependencies/assumptions: High-fidelity SLAM; robust 3D reconstruction under challenging lighting; safety corridors; communication constraints.
- Surgical and medical robotics assistance for viewpoint planning
- Sectors: healthcare
- What: Systems that recommend endoscope/camera repositioning to disambiguate occluded anatomy, or verify counts (sponges/instruments) with active perception.
- Dependencies/assumptions: Clinical validation; strict safety and interpretability; domain-specific datasets reflecting ESI’s occlusion/containment logics; regulatory approval.
- Autonomous warehouses with active counting, packing, and stability checks
- Sectors: logistics, e-commerce
- What: Robots that combine cognitive mapping with contact/stability reasoning to plan pack sequences and verify load security using minimal extra views.
- Dependencies/assumptions: Advanced motion planning; real-time physics prediction; sensor fusion; integration with WMS/ERP.
- Robust 3D foundation models with self-assessed reliability
- Sectors: software, mapping, robotics
- What: Next-gen 3D models that output both geometry and uncertainty, enabling safe routing between 2D/3D reasoning and reducing the “3D hurts when imperfect” failure mode.
- Dependencies/assumptions: Large-scale multi-view datasets with uncertainty labels; training objectives for calibrated uncertainty; standardized quality metrics.
- Metacognitive agents that seek disconfirming evidence
- Sectors: software, robotics, education
- What: Agents trained to actively falsify their hypotheses and down-weight early impressions, closing the “premature commitment” gap shown in the paper’s human studies.
- Dependencies/assumptions: New training signals (counterfactual queries, contradiction detection); on-policy exploration; evaluation protocols for epistemic calibration.
- Disaster response and search with selective sensing
- Sectors: public safety, defense
- What: Agents that navigate unstable/occluded environments, strategically choosing views and actions to infer hidden structure (voids, passages) with minimal risk.
- Dependencies/assumptions: Ruggedized platforms; safety-aware action priors; domain-specific ESI-like tasks for rubble/structural assessment.
- In-home privacy-preserving embodied assistants
- Sectors: consumer robotics, policy
- What: Agents that collect only task-relevant evidence, discard redundant frames, and provide user-controllable transparency about what was sensed and why.
- Dependencies/assumptions: Edge compute; data minimization policies; UI for user consent and review; certification.
- Embodied STEM tutors with real manipulatives
- Sectors: education
- What: Physical+AR kits where learners collaborate with an agent that proposes actions (move here, rotate that) to reveal geometric relations or physical dynamics.
- Dependencies/assumptions: Affordable kits; safe actuation; classroom trials; pedagogy integration.
- Autonomous retail associates for shelf auditing and restocking
- Sectors: retail
- What: Agents that perform active enumeration under occlusion (front-facing product blocking), test containment (is stock inside bin?), and plan restock actions.
- Dependencies/assumptions: Store navigation permissions; nighttime operation; robust perception across packaging reflections/transparencies.
- Multi-agent coordination with shared cognitive maps
- Sectors: logistics, defense, smart buildings
- What: Teams of agents build and share topological maps, assign targeted view/act roles, and reconcile conflicting evidence to maintain consistent world models.
- Dependencies/assumptions: Communication protocols; distributed SLAM; conflict resolution and belief merging; latency constraints.
Cross-cutting assumptions and dependencies affecting feasibility
- Simulation-to-real gap: Policies trained/evaluated in OmniGibson/BEHAVIOR-1K need domain randomization, real-world fine-tuning, and safety guards.
- Sensors and actuation: Many applications assume RGB-D or stereo, controllable viewpoints, and basic manipulation; limited hardware constrains benefits.
- 3D reconstruction reliability: Gains rely on detecting when 3D is trustworthy; otherwise fallback to 2D is safer.
- Step budgets and latency: Real deployments must balance the benefits of active exploration with time/energy constraints.
- Safety, liability, and ethics: Handling liquids, lifting objects, or probing occlusions requires risk assessment and compliance, especially in healthcare and home settings.
- Data governance and privacy: Selective sensing reduces exposure but requires auditability and user controls over what is captured and retained.
These applications translate ESI-Bench’s main insights—active, selective sensing; attribution of perception vs. action errors; careful use of 3D; and calibrated decision-making—into concrete tools, products, and workflows across sectors.
Glossary
- 3D grounding: Using explicit 3D geometric representations to anchor spatial reasoning. "explicit 3D grounding stabilizes reasoning on depth-sensitive tasks"
- 3D reconstruction: Recovering 3D structure from images or views for downstream reasoning. "reconstructed from multi-view observations via VGGT"
- Action blindness: Failure to choose informative actions, leading to poor observations and compounding mistakes. "Most failures stem not from weak perception but from action blindness: poor action choices lead to poor observations, which in turn drive cascading errors."
- Action space: The set of all actions available to an agent in an environment. "where is the action space"
- Active exploration: Agent-driven movement and interaction to collect informative evidence before answering. "active exploration substantially outperforms passive counterparts"
- Active perception: Selecting or learning which observations to acquire through actions to improve understanding. "Active perception methods learn observation selection"
- Articulation: The movable joints or degrees of freedom of objects in simulation. "with physical properties such as friction, mass, and articulation."
- BEHAVIOR-1K: A large corpus of interactive 3D scenes used for embodied evaluation. "We build ESI-Bench on BEHAVIOR-1K within the OmniGibson simulator."
- Bounding box (bbox): A box enclosing an object’s extent used for geometry/vision computations. "object bounding boxes"
- Cascading errors: Compounding failures where early mistakes lead to increasingly worse outcomes. "which in turn drive cascading errors."
- Cognitive mapping: Building an internal map of connectivity and regions through exploration. "Cognitive Mapping"
- Egocentric observation space: Observations captured from the agent’s own first-person viewpoint. "where is the egocentric observation space"
- Egocentric video: First-person video streams used for spatial reasoning tasks. "egocentric video in VSI-Bench"
- Embodied spatial intelligence: Spatial reasoning that requires a physical or simulated body to act and perceive. "a comprehensive benchmark for embodied spatial intelligence"
- Epistemic calibration: Alignment between model confidence and the quality/uncertainty of its evidence. "a critical gap in epistemic calibration (i.e., a model’s confidence matches the quality and uncertainty of its evidence)."
- Forced-perspective: Viewpoint-induced distortions of perceived size or distance. "Overcome forced-perspective distortions in size and distance"
- Ground-truth action trajectory: The optimal sequence of actions that resolves a task, used as reference. "along the ground-truth action trajectory"
- Ground-Truth Passive: An evaluation setting that supplies views from the optimal trajectory to isolate perception from action errors. "Ground-Truth Passive provides the sequence of views rendered along the ground-truth action trajectory"
- Isaac Sim: NVIDIA’s simulation platform underpinning OmniGibson. "OmniGibson, built on NVIDIA Isaac Sim and PhysX 5"
- Kinematic sampling: Physics-aware sampling of object poses before allowing dynamics to settle. "physics-based kinematic sampling"
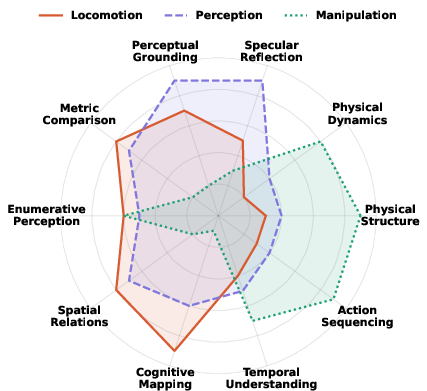
- Locomotion: Agent movement actions in space (e.g., forward, turn). "Agents must decide what abilities to deploy — perception, locomotion, and manipulation —"
- Manipulation: Actions that change object states or relations (e.g., pick, place, pour). "Agents must decide what abilities to deploy — perception, locomotion, and manipulation —"
- Metacognitive gap: A mismatch between a model’s self-evaluation and reality (e.g., overconfidence, poor belief revision). "exposing a metacognitive gap that neither better perception nor more embodied interaction alone can close."
- Metric-depth supervision: Training with absolute depth as a supervision signal for vision models. "metric-depth supervision"
- MLLM: A multimodal LLM that processes both vision and language. "state-of-the-art MLLMs"
- Multi-view: Using multiple viewpoints or images of the scene for reasoning. "passive random multi-view often adds noise rather than signal"
- Occlusion: When objects are hidden by others, complicating perception or counting. "Count objects despite occlusion, merging, or enclosure"
- OmniGibson: An embodied simulation environment used to build ESI-Bench. "We build ESI-Bench on BEHAVIOR-1K within the OmniGibson simulator."
- Oracle ablation: An evaluation using privileged inputs to isolate specific error sources. "serving as an oracle ablation that separates perception errors from action errors."
- Oracle observations: Assumed perfect observations used in analyses or baselines. "assume oracle observations"
- Particle-based fluids: Fluid simulation that represents liquids as interacting particles. "particle-based fluids"
- Perceptual grounding: Resolving perceptual ambiguities by anchoring to viewpoint-dependent evidence. "Perceptual Grounding"
- PhysX 5: NVIDIA’s physics engine for simulating rigid-body and other dynamics. "PhysX 5"
- Point cloud: A set of 3D points used to represent scene geometry. "perfect point clouds derived directly from simulator state"
- Projective symmetry: Ambiguity where different 3D layouts look similar under certain camera projections. "Navigate to vantage points that break projective symmetry"
- Quaternion: A 4D representation of 3D orientation used for rotations. "agent initial pose and quaternion "
- RGB-D: Image data containing both color (RGB) and depth channels. "uses RGB-D and depth-oriented QA"
- Rigid-body contact physics: Simulation of contact, collisions, and forces between solid bodies. "rigid-body contact physics"
- Scene graph: A structured representation of objects, their geometry, and relations. "extract a structured scene graph"
- Segmentation masks: Pixel-level labels used to verify object presence in images. "using segmentation masks"
- Selective sensing: Choosing only informative observations rather than passively consuming many. "selective sensing, where agents must determine which observations are worth acquiring"
- Specular reflection: Mirror-like reflection that creates reflected views of objects. "Specular Reflection"
- Spelke's core knowledge systems: A cognitive framework of innate domains (objects, geometry, number, agents). "Spelke's four core knowledge systems"
- Step budget: The maximum number of interaction steps allowed per episode. "cannot be recovered within the step budget."
- Topological representations: Abstract maps encoding connectivity and regions instead of precise metric details. "Construct topological representations through locomotion"
- Trajectory: The time-ordered sequence of observations and actions taken by an agent. "induces a trajectory "
- Vision-LLM (VLM): A model that processes both visual inputs and text. "2D vision-LLMs include GPT-5 and Gemini 3.1"
- View hallucination: Erroneously perceiving content in a view that does not exist. "on View Hallucination, from 39.9\% to 68.1\%"
Collections
Sign up for free to add this paper to one or more collections.