Arithmetic Packing on Wide Integer Datapaths in DSP Primitives of Modern FPGA Devices
Abstract: Deep Neural Networks increasingly employ low-precision quantization to reduce computational requirements. While FPGAs are well suited for workloads with heterogeneous precisions, their dedicated digital signal processing (DSP) slices only feature fixed-width datapaths that are significantly underutilized by low-bitwidth arithmetic. While previous approaches have already introduced the packing of multiple values onto the same wide DSP datapath, they either only support specific fixed bitwidths or are wasteful regarding the use of additional support logic external to the DSP. This paper proposes an efficient method to dynamically pack multiple (un-)signed inputs with arbitrary bitwidths into a wide multiplier path by leveraging the DSP's internal pre-adder. Building on this, we present two distinct architectures, one optimized for matrix-vector multiplications and the other for convolutions. Our implementations are integrated into AMD's FINN framework. With these optimizations, we reduce the LUT utilization by 21% and increase the FPS/DSP by 36% for the UltraNet model compared to the FINN reference.

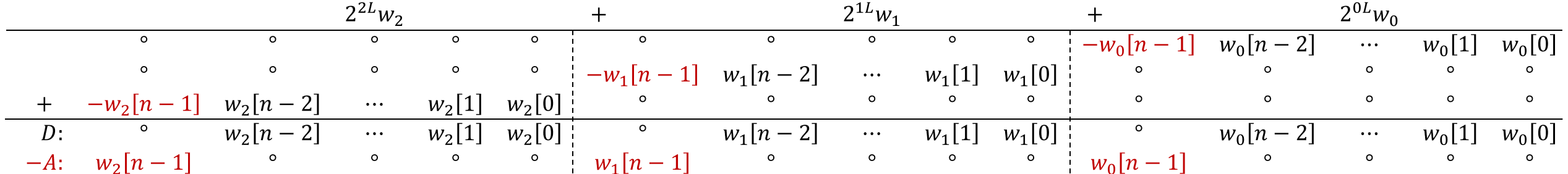

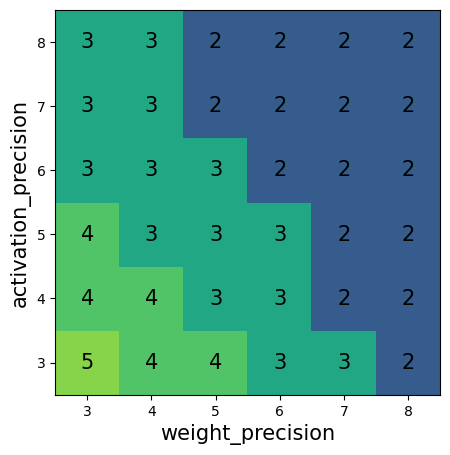
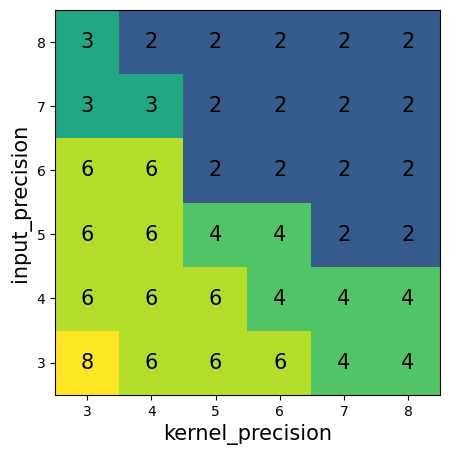
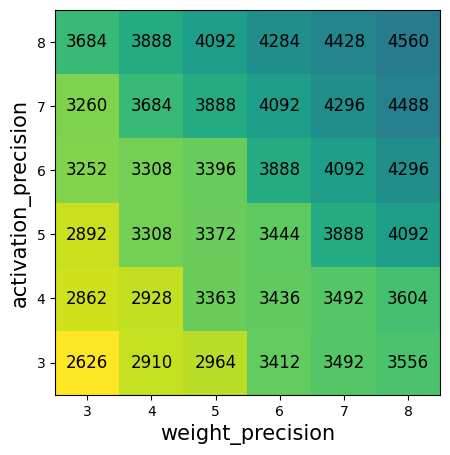
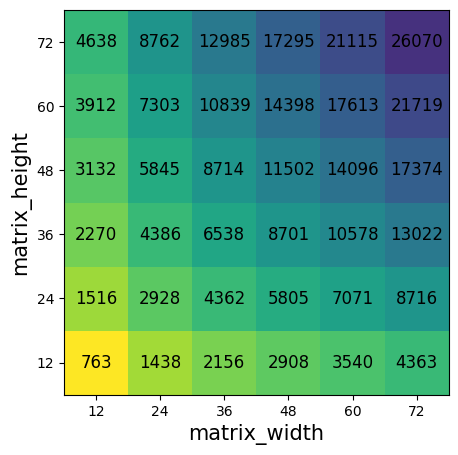
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making computers that use FPGAs run AI calculations faster and more efficiently, especially when the numbers they work with are very small (like 2–8 bits). Modern FPGAs have special calculator parts called DSP slices. These DSPs are “wide,” meaning they are built to handle big numbers. When AI models use tiny numbers to save time and energy, most of that wide space goes to waste. The authors show smart ways to “pack” many small calculations into those wide DSPs at the same time, so the hardware does much more work each clock cycle without using extra energy or extra space.
The main questions the paper asks
- How can we fit (pack) several small-number multiplications into a single wide DSP multiplier so we don’t waste hardware?
- How can we do this for any number size (not just fixed sizes like 8-bit), and also handle both positive and negative numbers correctly?
- Can we design practical building blocks for common AI tasks, like matrix–vector multiplications and convolutions?
- Will these ideas actually save hardware and increase speed in real AI models?
How they did it (in simple terms)
Think of a DSP as a big moving truck (wide datapath), and tiny-number calculations as small boxes. If you put only one small box in the truck, you waste space. The authors show how to load many small boxes into the same truck without them crashing into each other.
Here are the key ideas, using everyday analogies:
- Packing many small values into one path (lanes)
- The authors treat the wide DSP input like a row of parking spots (lanes). Each small number gets its own lane with a little space around it so results don’t spill into the next lane.
- They figure out the smallest safe “lane width” so that the parked results don’t overlap.
- Making negative numbers work without extra parts (the pre-adder trick)
- Computers store negative numbers in a way that can “spill” into neighboring lanes if you simply jam them together.
- Modern DSPs have a tiny calculator before the main one, called a pre-adder. The authors split off the sign bits (which say “this number is negative”) and subtract them inside the DSP using that pre-adder. This neat trick lets them pack many signed (positive/negative) values correctly, without adding extra hardware outside the DSP.
- Two flavors of packing for two common AI tasks
- Soft Datapath Vectorization (SDV): Pack on one side. This is great for matrix–vector multiplications (used in fully connected layers). Imagine loading many small boxes on one side of the truck and one big box on the other side.
- Binary Segmentation (BSEG): Pack on both sides. This is perfect for convolutions (used in image, sound, and vision tasks). Now both sides of the truck are filled with small boxes, multiplying many pairs at the same time.
- Preventing “lane collisions”
- SDV “listens” for tiny overflows (spill-overs) by checking just the lowest couple of bits—like using a sensor to detect small bumps. It then corrects the result so each lane is clean and accurate.
- BSEG uses “guard bits,” which are like bumpers between parked cars (lanes). These bumpers stop results from pushing into the next lane during accumulation. The DSP’s control inputs help add those bumpers efficiently.
- Making it usable in real life
- They integrated these designs into AMD’s open-source FINN framework, which builds FPGA accelerators for neural networks. That means other people can try these methods easily on real models.
What they found and why it matters
The authors tested their designs on real AI layers and a full object-detection model called UltraNet. Here are the highlights:
- More work per DSP
- For low-bit arithmetic (like 4-bit), they pack more parallel operations into each DSP than previous general solutions. This boosts speed without needing more DSPs.
- Works for any bit-width and for signed/unsigned numbers
- Unlike many earlier methods that only support fixed sizes (like exactly 8-bit or 4-bit), this approach supports arbitrary small sizes and both positive and negative numbers—making it flexible across different models.
- Big wins on a full model (UltraNet), integrated with FINN
- Compared to the FINN reference design, their improved design:
- Reduced LUT usage by about 21% (which saves general-purpose logic),
- Increased frames per second per DSP (FPS/DSP) by about 36%.
- Against a state-of-the-art convolution method (HiKonv), they:
- Used 27% fewer LUTs,
- Ran more efficiently per DSP (about 25% better FPS/DSP).
- In another test at maximum speed for a typical convolution:
- 63% fewer LUTs and 25% fewer DSPs than the FINN baseline, while keeping or slightly improving clock speed.
Why this matters:
- Better packing means higher speed and lower cost for the same chip.
- It helps edge devices (like drones, cameras, wearables) run AI faster and with less power.
- It makes low-precision AI (which saves energy) even more attractive, because the hardware no longer wastes space.
What this could mean going forward
- Faster, greener AI on small devices: With more efficient use of DSPs, companies can deploy AI at the edge with the same chips, less energy, or both.
- Flexibility across models: Because it works for many bit-widths and both signed and unsigned numbers, the same hardware design can serve different AI models and future quantization strategies.
- Open-source impact: Since the designs are integrated into the FINN framework, other researchers and engineers can adopt, test, and improve them quickly.
- Future directions: The authors suggest adapting packing on-the-fly (changing how tightly you pack based on the workload) and exploring similar ideas for compact floating-point numbers—potentially unlocking even more speed and efficiency.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper leaves the following items unresolved, which future researchers could address:
- Formal correctness of SDV spill-over tracking: Provide a rigorous proof that the modulo-4 tracking and correction scheme remains exact for all signedness combinations, continuous accumulations over long sequences, and across pipeline stages, and formally justify the sufficiency of the lane-size bound under realistic carry propagation scenarios.
- Quantitative limits of pre-adder–based signed packing: Derive device-specific bounds (DSP48E2, DSP58) on the maximum number of packed lanes and input widths that can be handled without overflow in the pre-adder subtraction (D − A), and characterize timing/area impact versus lane count.
- General guard-bit conditions beyond a single signedness case: Extend the BSEG guard-bit derivations (currently for signed kernels and unsigned inputs, with low-part width) to all signed/unsigned combinations, nonzero , and mixed-precision lanes; provide closed-form design rules and safe operating regions.
- Latency characterization: Report pipeline depths, per-layer latency, and end-to-end model latency, and analyze the throughput–latency trade-offs of SDV and BSEG versus FINN baselines under different unrolling/packing settings.
- Power and energy efficiency: Measure dynamic/static power and energy per inference for SDV/BSEG, and quantify how LUT/BRAM choices in the input generator and external tracking logic affect energy efficiency relative to throughput gains.
- Post–place-and-route timing robustness: Evaluate Fmax and timing closure after full implementation (not only out-of-context synthesis), including congestion and variability across multiple AMD devices (UltraScale+, Versal), speed grades, and Vivado versions.
- Memory system requirements and policies: Model and validate the bandwidth/buffering needs of the input generator (BRAM vs LUTRAM), the impact on on-chip interconnect and backpressure, and develop an automated policy to choose memory type and tiling given channel count, kernel shape, and throughput targets.
- Broader workload coverage: Benchmark common 2D kernels (e.g., 3×3, 5×5, 7×7), varying stride/dilation/padding, depthwise/group convolutions, large-channel configurations, and transformer/GEMM-style workloads to substantiate generality beyond UltraNet and the 1D conv reference.
- Numerical stress testing and validation: Verify exactness under worst-case values (e.g., most-negative inputs, maximum products, long accumulations), including adversarial input distributions, and document rounding/truncation behavior and saturation vs wrap-around choices.
- Interaction with native DSP modes: Systematically assess when DSP58 native INT8 accumulation or other DSP modes outperform SDV/BSEG, and design hybrid per-layer selection strategies (including automatic switching) that exploit native modes where beneficial.
- Automated design-space exploration: Replace the heuristic lane-size choice (min L or L+1) with an optimization framework that co-optimizes lane size, low/high-part widths, guard bits, packing factors, buffering, and pipelining under resource/timing/accuracy constraints.
- Quantization scaling and bias integration: Describe how per-layer scaling factors, zero-points, and biases (common in quantized DNNs) are incorporated into SDV/BSEG packing and accumulation without breaking guard-bit assumptions or signed packing correctness.
- Portability to Intel/Altera DSPs: Provide an adaptation path for Agilex/Stratix DSP architectures with native low-precision support, including which parts of SDV/BSEG change and how guard-bit/sign-packing strategies map to their pre-adders and accumulation paths.
- Tensor-layout flexibility: Quantify the cost of channels-first and other layouts, and propose architectures or reordering strategies that reduce input generator overhead for layers with many input channels.
- External high-part tracking impact: Model how fabric-based high-part extraction/accumulation scales with kernel size and packing depth, and its effect on critical paths and timing closure for large kernels.
- Runtime-dynamic packing: Specify reconfiguration mechanisms, control signaling, and consistency guarantees for dynamic packing strategies that adapt precision/packing factors at runtime, and evaluate benefits in multi-tenant or variable-precision scenarios.
- Low-precision floating-point support: Define packing/guard-bit schemes for FP8/bfloat8 (handling exponents, subnormals, rounding modes), and evaluate correctness and performance relative to integer packing.
- Hybrid SDV+BSEG strategies: Investigate combined approaches for layers where BSEG’s input generator becomes expensive (e.g., many channels), including data-layout changes, hierarchical packing, or partial sharing to reduce generator cost.
- Toolchain assumptions and fallbacks: Document dependencies on DSP RND and fracturable LUT behavior; provide verified configuration recipes and robust fallbacks for devices/tool versions where these features differ.
- Reproducibility assets: Release complete synthesis/implementation scripts, constraints, and floorplanning guidelines (CI-ready) to ensure that reported performance/resource results can be faithfully reproduced across environments.
Practical Applications
Practical Applications Derived from the Paper
The paper introduces two hardware techniques—Soft Datapath Vectorization (SDV) for matrix–vector operations and Binary Segmentation (BSEG) for convolutions—that pack multiple low-bitwidth signed/unsigned operands onto wide FPGA DSP datapaths with minimal external logic. By leveraging the DSP pre-adder for dynamic signed packing and guard-bit strategies for accurate lane separation, the methods increase operations per DSP and reduce LUT overhead. The implementations are integrated into AMD’s open-source FINN framework and demonstrated on UltraNet with a 36% FPS/DSP gain and 21% LUT reduction.
Below are actionable, real-world applications, grouped by immediacy, linked to sectors, and annotated with tools/workflows and feasibility assumptions.
Immediate Applications
- Edge vision inference accelerators (manufacturing, logistics, retail, drones)
- Deploy low-precision CNNs (e.g., object detection, counting, defect inspection) on AMD Zynq UltraScale+ and Versal FPGAs with higher throughput per DSP and reduced LUTs. Use BSEG for convolution layers and SDV for fully-connected/classification heads to maximize utilization under 8-bit quantization.
- Tools/workflows: FINN integration; quantize models to ≤8-bit (often 2–4-bit viable); deploy via Vivado on ZCU104/Versal; channels-last stream layout.
- Assumptions/dependencies: Accuracy acceptable at low precision; memory bandwidth sized for higher throughput; tensor layout matches FINN; AMD DSP48E2/DSP58 availability; input generator cost remains manageable for high-channel layers.
- Audio and time-series analytics on the edge (predictive maintenance, keyword spotting, wearables)
- Accelerate 1D convolutions/correlations (BSEG) and dense projections (SDV) for long sequences (e.g., vibration, ECG/PPG, KWS). Demonstrated LUT/DSP savings translate to better battery life and higher on-device throughput.
- Tools/workflows: FINN dataflow designs; INT2–INT4 quantization; DSP C-port/RND guard-bit injection; LUTRAM/BRAM input generator.
- Assumptions/dependencies: Robust quantization-aware training; stream-friendly data ingestion; careful kernel/lane sizing to limit guard overhead.
- Network and signal-processing IPs (telecom/SDR, radar/sonar, industrial sensing)
- Improve density for MAC-heavy blocks such as FIR filters, correlators, matched filters, and sliding dot-products. SDV packs low-bitwidth taps/input samples; BSEG supports correlation-style accumulation with built-in partial sum stacking.
- Tools/workflows: Parameterizable IP cores using the proposed packing; RND/C input for guard-bit bias; SystemVerilog modules from the paper.
- Assumptions/dependencies: Fixed-point datapaths dominate; tap/sample precisions ≤8 bits; signed/unsigned mix handled by pre-adder packing.
- Cloud FPGA inferencing (data center video analytics, recommendation models with low-bit ops)
- Increase throughput per FPGA (e.g., Alveo cards) for quantized CNNs/transformer sub-blocks mapped to conv, GEMV/GEMM slices. Reduces instance count or power at fixed SLA.
- Tools/workflows: FINN or custom HLS/RTL wrapping SDV/BSEG; cluster deployment via containerized FPGA runtimes.
- Assumptions/dependencies: Model graph convertible to low-bit fixed-point; PCIe/DDR bandwidth balanced; operator scheduling aligns with SDV/BSEG strengths.
- Robotics perception and control (AMR/AGV, cobots, UAVs)
- Run quantized perception stacks (e.g., semantic segmentation front-ends, small detectors) at lower power on embedded FPGAs; use SDV for control/dense layers, BSEG for convs.
- Tools/workflows: FINN-generated IP integrated into ROS2 pipelines; Zynq MPSoC heterogeneous deployment (PL for packed DSP compute, PS for control).
- Assumptions/dependencies: Real-time deadlines met with 250–590 MHz measured clocks; sensor I/O and DMA scheduling preserve throughput.
- Privacy-preserving on-device inference (consumer IoT, healthcare devices)
- Execute inference locally instead of streaming to cloud by leveraging improved DSP efficiency at 2–8-bit—reducing transmit energy and exposure of sensitive data.
- Tools/workflows: Quantization-aware training; FINN build; Zynq-based smart cameras/speakers/wearables.
- Assumptions/dependencies: Model accuracy at target quantization acceptable; device thermal envelope supports sustained operation.
- Academic teaching and research prototyping (computer engineering, ML systems)
- Use the open-source implementations to teach DSP packing, quantized inference, and hardware–algorithm co-design; replicate UltraNet experiments; extend to new topologies.
- Tools/workflows: FINN repo; Vivado 2025.x; ZCU104 lab kits; course labs on SDV/BSEG parameter sweeps.
- Assumptions/dependencies: Access to AMD FPGA boards; adherence to FINN tensor layout and streaming interfaces.
- EDA/IP vendor library upgrades (software/semiconductor tooling)
- Incorporate signed pre-adder packing and guard-bit lane offsets into DSP macro libraries/HLS templates to yield denser IP by default for low-precision MACs.
- Tools/workflows: RTL/HLS macro re-use; automated lane-size selection; synthesis directives for DSP48E2/DSP58 usage.
- Assumptions/dependencies: Vendor tool support for pre-adder configurations and RND; stable timing closure after packing.
Long-Term Applications
- Runtime-adaptive packing and precision elasticity (edge AI orchestration)
- Dynamically adjust lane sizes/packing density (and even bitwidth) per scene/workload to trade accuracy vs. throughput/energy in real time.
- Tools/workflows: Runtime controllers; partial reconfiguration or multi-bitstream management; telemetry-driven policies.
- Assumptions/dependencies: Fast context switching or PR flows; robust accuracy monitoring; metadata to select SDV vs. BSEG per layer at runtime.
- Low-precision floating-point packing on DSPs
- Extend techniques to pack multiple low-precision floating-point (e.g., FP8, micro-FP) multiplies per DSP slice for DNNs or scientific DSP kernels.
- Tools/workflows: New encoding-aware packing and guard analyses; enhanced pre-adder use; mixed fixed/float operator libraries.
- Assumptions/dependencies: Research on error models and lane interference; DSP-friendly FP formats; training support for low-precision FP.
- Automatic operator selection in ML compilers (end-to-end co-optimization)
- Compiler passes that pick SDV (MatVec) or BSEG (Conv) per layer and choose lane sizes/guard schemes to optimize FPS/DSP and LUTs subject to timing/bandwidth constraints.
- Tools/workflows: Integration into FINN, Vitis AI, or TVM; cost models for LUT/DSP/timing; hardware-aware NAS that favors pack-friendly topologies.
- Assumptions/dependencies: Accurate resource/perf estimation; stable timing with dense packing; standard tensor layouts or layout-aware transforms.
- Cross-vendor portability (Intel/other FPGAs)
- Port packing concepts to Intel Agilex DSP architectures with native low-precision modes; build vendor-agnostic libraries.
- Tools/workflows: Architecture-specific pre-adder/packing rewrites; abstraction layers in FINN-like frameworks.
- Assumptions/dependencies: Different DSP datapath widths and pre-adder features; re-derived guard and lane-size conditions.
- Certified safety-critical deployment (automotive, medical, avionics)
- Use higher DSP efficiency to meet real-time constraints within tighter power/thermal/area budgets; pursue DO-254/ISO 26262-ready IP for quantized inference.
- Tools/workflows: Formal verification of lane isolation and correctness; deterministic timing analyses; safety artifacts for SDV/BSEG blocks.
- Assumptions/dependencies: Mature verification of packed arithmetic; stable toolchains; long-term device availability.
- 5G/6G vRAN and PHY acceleration
- Apply packing to low-precision correlators, beamforming, and CNN-based channel estimation/equalization in O-RAN-aligned hardware.
- Tools/workflows: vRAN FPGA accelerators; standardized APIs; SDV/BSEG-based PHY kernels.
- Assumptions/dependencies: Algorithm suitability for ≤8-bit; deterministic latency within slot timing; integration with NIC and fronthaul stacks.
- Energy- and policy-driven green AI adoption
- Inform procurement and sustainability policies that prioritize low-precision FPGA inference (higher FPS/DSP, fewer LUTs) for edge AI deployments in public infrastructure.
- Tools/workflows: Benchmarking with standardized models (e.g., UltraNet-like variants) and energy/KPI dashboards.
- Assumptions/dependencies: Policy frameworks that value energy proportionality; availability of quantized public models and datasets.
- Clock-pumped ultra-dense DSP kernels
- Combine arithmetic packing with multi-pumping (clock doubling/quadrupling) to further scale throughput per DSP slice for high-rate analytics.
- Tools/workflows: PLL-based multi-pumping; time-division multiplexed control in RTL; verified interleaving of packed lanes.
- Assumptions/dependencies: Timing margin at higher internal clocks; error-free clock domain crossing; power integrity at elevated toggle rates.
- Domain-specific accelerators with co-designed models
- Co-design models that are “packing-friendly” (e.g., favoring 2–4-bit kernels, depthwise/grouped conv arrangements) to fully exploit BSEG/SDV efficiencies in embedded vision, AR/VR, and smart city sensors.
- Tools/workflows: Hardware-aware training; pruning/quantization pipelines; architectural templates tuned to DSP packing limits.
- Assumptions/dependencies: Task accuracy preserved under aggressive quantization; dataset/model availability; upstream framework support.
Notes on feasibility across applications:
- The methods assume AMD DSP48E2/DSP58-style pre-adders and datapaths; Intel or other FPGA families require tailored strategies.
- Benefits grow as precisions drop below 8 bits; model retraining with quantization-aware methods often needed to preserve accuracy.
- BSEG delivers the largest gains on convolutional workloads but may incur input-generator cost for many-channel tensors; SDV may be preferable for such layers.
- Achieved frequencies (250–590 MHz reported) depend on device, floorplanning, and memory bandwidth engineering.
Glossary
- AXI-Streams: A streaming interface protocol used on FPGAs for high-throughput data transfer between IP blocks. Example: "data input and output via AXI-Streams assuming a channels-last tensor layout."
- Binary segmentation (BSEG): A packing technique that places multiple low-precision operands on both multiplier inputs so several partial products are formed and some summed within the multiplier, well-suited to convolutions. Example: "we call it binary segmentation (BSEG) when packing is used on both multiplier input paths."
- BRAM: On-chip block RAM memory in FPGAs used for buffering and storage. Example: "The memory required for this input generator can be implemented using either BRAM or LUTRAM."
- C-input: The dedicated add/accumulate input port on a DSP slice used to inject partial sums or biases. Example: "we use the C-input of the DSPs"
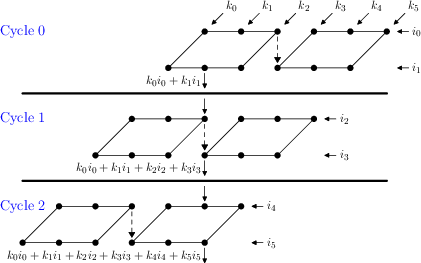
- Cascade path: A dedicated inter-DSP connection that forwards signals (e.g., operands) directly between adjacent DSP slices for pipelined chaining. Example: "utilizing the dedicated cascade path of the B-input."
- Channels-last tensor layout: A tensor memory/stream ordering where channel dimension is last (e.g., NHWC), affecting how data must be fed to hardware. Example: "data input and output via AXI-Streams assuming a channels-last tensor layout."
- Clock pumping: A technique to increase effective operations per cycle by clocking internal structures faster or time-multiplexing within a DSP. Example: "readily compatible with clock pumping"
- Critical path: The longest combinational path in a circuit that limits the maximum clock frequency. Example: "resource utilization and critical path timing."
- Dataflow inference: An execution style where layers or operators stream data through pipelines with parallelism tuned across the design. Example: "FINN produces highly customizable dataflow inference solutions."
- DSP slice: A specialized FPGA primitive that implements fast arithmetic (e.g., multiply-accumulate) with fixed-width datapaths. Example: "the dedicated DSP slices provide only a fixed-width, relatively wide multiply-accumulate datapath."
- DSP48E2: A specific Xilinx/AMD DSP slice generation found in UltraScale+ families with defined multiplier/adder widths. Example: "specifically for the DSP48E2 and DSP58 slice generations"
- DSP58: A newer DSP slice generation (e.g., in Versal) with additional modes for low-precision arithmetic. Example: "The DSP58 on Versal devices supports a native INT8 mode"
- Fracturable LUTs: FPGA lookup tables that can operate as one larger logic function or be split into multiple smaller functions sharing inputs. Example: "Modern AMD FPGAs feature fracturable LUTs that can implement either one arbitrary Boolean 6-input function or two arbitrary 5-input functions with shared inputs"
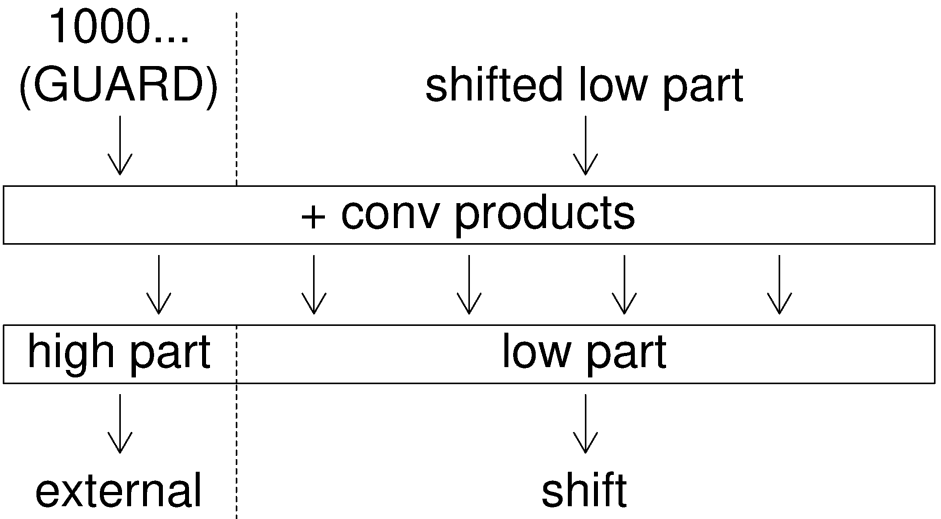
- Guard bits: Extra bits inserted as offsets into packed lanes to prevent positive/negative overflow between adjacent lanes. Example: "Guard bits separate the individual lanes."
- Guard value: A preset biased value loaded into a lane between accumulation stages to re-center its range and avoid overflow. Example: "It is replaced by a guard value that re-biases the lane value, preparing it for the next accumulation stage"
- Input generator: A pre-processing unit that buffers, reorders, and packages incoming stream elements into the format required by parallel DSP inputs. Example: "the BSEG architecture requires a preceding input generator to not only buffer the stream but to reorder and package the specific elements needed for the parallel DSP inputs."
- Lane: A logical segment within a packed datapath that carries one independent low-precision operand/result. Example: "Packing must space the inputs sufficiently to ensure that the result lanes can be separated easily."
- Lane size: The bit width allocated to a lane, including the value and padding/guard to enable correct extraction. Example: "Let the lane size , be the number of bits occupied by one value plus the padding introduced to assist the ultimate extraction of individual results."
- Lookup tables (LUTs): Configurable logic elements in FPGAs that implement combinational logic via truth tables. Example: "the available resources, such as lookup tables (LUTs), flip-flops (FFs) and digital signal processing slices (DSPs)"
- LUTRAM: Small on-chip memories built from LUTs, used as flexible RAM for buffering and storage. Example: "either BRAM or LUTRAM."
- Multiply-accumulate (MAC): A fused arithmetic operation computing a product and adding it to an accumulator. Example: "INT8 multiply-accumulate (MAC) operations per clock cycle"
- Multiplier matrix: The internal array of partial-product adders in a multiplier that forms sums of bitwise products. Example: "the stacking of multiple vertical additions of partial products within the multiplier matrix."
- Negative radix weight: In two’s-complement, the sign bit contributes a negative weighted value, enabling subtraction via sign extension. Example: "the sign bit of a number carries a negative radix weight."
- Operational density: The number of useful arithmetic operations performed per DSP per cycle, indicating packing efficiency. Example: "improve the operational density of a design (i.e., the number of operations per DSP and cycle)."
- Out-of-context synthesis: A synthesis flow that compiles modules independently of the full design to assess resource/timing in isolation. Example: "using out-of-context synthesis in Vivado 2025.2"
- Overpacking: Intentionally packing beyond exact separability, allowing controlled approximation to increase density. Example: "Sommer et~al.~\cite{sommer2022dsp} explore overpacking for a further increase of the operational density at the cost of producing approximate results,"
- Pre-adder: A small adder before the multiplier inside a DSP slice, used here to combine sign and magnitude words for packing. Example: "leveraging the DSP's internal pre-adder."
- RND parameter: A DSP configuration option that injects an internal rounding/offset value into computations. Example: "they can alternatively be introduced via the internally configured RND parameter."
- Soft datapath vectorization (SDV): Packing applied to only one multiplier input so multiple products share a common other operand. Example: "we will refer to the technique of applying packing to only one multiplier input as soft datapath vectorization (SDV)."
- Spill-overs: Carries or value overflows that propagate from one packed lane into its neighbor during accumulation. Example: "Differences observed in the accumulation results computed by the DSP represent spill-overs between lanes."
- Systolic array: A hardware architecture where data flows rhythmically through an array of processing elements performing local operations. Example: "with an optimized systolic array structure specifically for INT4 precision."
- Two's complement: A signed integer representation where negative numbers are encoded by inverting bits and adding one, enabling consistent arithmetic. Example: "In two's complement arithmetic, the sign bit of a number carries a negative radix weight."
- Unrolling: Duplicating computation across dimensions to exploit parallelism and increase throughput. Example: "its parallelism is, nonetheless, flexibly tunable by unrolling along the input width, kernel height and output channel dimensions independently."
- Versal: An AMD/Xilinx FPGA SoC family featuring advanced DSP slices (DSP58) and AI-optimized capabilities. Example: "The DSP58 on Versal devices supports a native INT8 mode"
Collections
Sign up for free to add this paper to one or more collections.