- The paper presents a novel mixed-radix CORDIC technique that reformulates the sigmoid function via tanh, enabling efficient FPGA implementation solely with shift-add operations.
- The paper demonstrates superior performance using only 835 logic slices and achieving a mean absolute error of 4.23×10⁻⁴, significantly outperforming prior FPGA-based designs.
- The paper offers a fully pipelined architecture that eliminates DSP usage, ensuring low latency and high throughput ideal for real-time neural network acceleration.
Hardware-Efficient FPGA Realization of the Sigmoid Function via Mixed-Radix Hyperbolic Rotation CORDIC
Introduction and Context
The direct implementation of nonlinear activation functions like the sigmoid poses significant hardware execution challenges, particularly for FPGAs employed in resource-constrained, low-latency, energy-efficient neural accelerators. While designs for ReLU and other piecewise-linear activations are straightforward, the sigmoid function's exponential and division operations hinder their deployment. This is especially pertinent for LSTMs, GRUs, and classical MLPs that depend on the sigmoid for gating and probabilistic output. The work "Hardware-Efficient FPGA Implementation of Sigmoid Function Using Mixed-Radix Hyperbolic Rotation CORDIC" (2604.23547) addresses this challenge by introducing a methodology combining mathematical reformulation and a CORDIC-based hardware pipeline optimized for the sigmoid within a normalized input domain.
Figure 1: Sigmoid activation function over a range [−6,6].
Rather than implementing the canonical sigmoid definition directly, the paper utilizes the identity σ(x)=21(1+tanh(2x)). This recasts the problem as a tanh computation, followed by two cheap linear operations. Given the favorable computational properties of CORDIC for evaluating hyperbolic functions using only shift and add, this transforms the high-cost design problem into a DSP-free, LUT-based formulation. The normalization of the input range to [−1,1] enables tanh to operate within [−0.5,0.5], greatly improving CORDIC convergence and reducing hardware resource requirements.
Mixed-Radix Hyperbolic Rotation CORDIC: Algorithmic Structure
A standard CORDIC operating in hyperbolic mode (HRC) can compute sinh and cosh; the tanh can then be derived as their ratio. However, radix-2 CORDIC alone has slow convergence, while higher-radix versions such as radix-4 typically require input-dependent scaling corrections which complicate pipelining and degrade numerical stability. The proposed mixed-radix scheme (MR-HRC) integrates both approaches.
The first algorithmic stage applies R2-HRC for j=2 to j=9, ensuring stable convergence and residual angle minimization. Subsequently, the R4-HRC is invoked starting at j=4 to refine the result efficiently, leveraging the fact that its scale factor converges to unity for small angles, thereby requiring no further normalization. The combined effect is rapid, robust convergence without area overhead from scaling logic.
The CORDIC core produces tanh0 and tanh1, while a downstream R2-based Linear Vectoring CORDIC (R2-LVC) efficiently computes the tanh output by vectoring in fixed-point arithmetic with a single adder per pipeline stage.

Figure 2: Proposed CORDIC-based methodology organized as a three-stage processing pipeline.
Architecture and Hardware Design
The hardware architecture consists of a pipelined implementation dividing the process into clear computational phases: MR-HRC (R2 and R4 stages), R2-LVC, and final scaling. Each pipeline stage uses dedicated hardware and registers, ensuring high throughput and short critical path.
- MR-HRC Core: Implements the shift-and-add based iterations for radix-2 and radix-4 modes with adder/multiplexer-based control logic. Radix-4 stages employ a digit selection mechanism derived from the SRT division paradigm with minimal comparator complexity, critical for pipelined depath minimization.
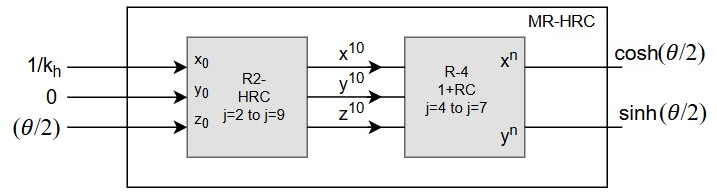
Figure 3: The architecture of proposed MR-HRC algorithm.
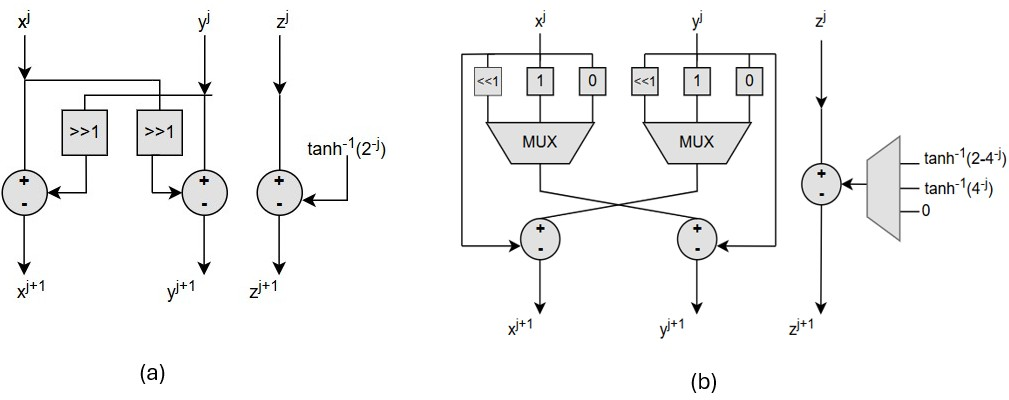
Figure 4: (a) Architecture of R2-HRC algorithm (b) Architecture of R4-HRC algorithm.
- R2-LVC Stage: This stage computes the tanh as tanh2 employing shift-add and adder logic, guaranteeing the convergence range covers the required normalized tanh region.
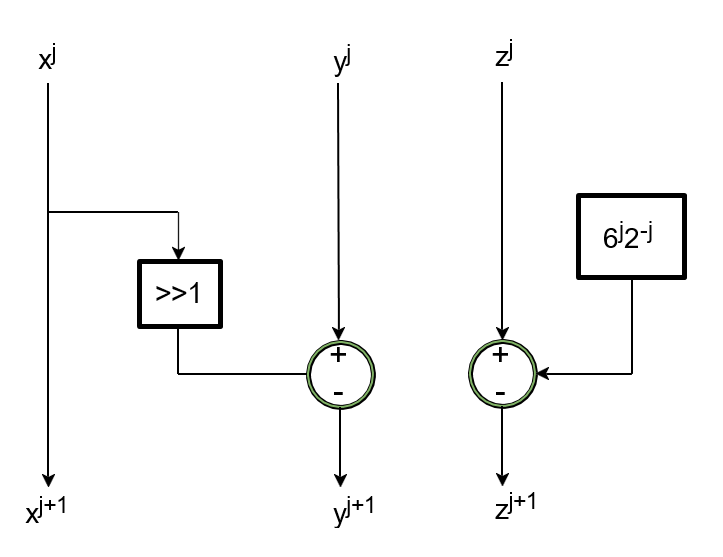
Figure 5: The architecture of the R2-LVC algorithm with adder.
All computation is performed in 16-bit fixed-point representation—sufficient for real-time inferencing without incurring floating-point complexity.
Quantitative Evaluation
On Xilinx Virtex-7 (16-bit datapath), the proposed pipeline occupies only 835 logic slices, utilizing zero DSPs—contrasting sharply with other reported FPGA sigmoid designs (e.g., 2093 and 3362 slices for [p13] and [p16], respectively, due to high DSP usage). The mean absolute error is tanh3, significantly outperforming prior FPGA-targeted approaches (which exhibit errors typically in the tanh4 range, with the best competitor at tanh5).
Strong Claims:
- No DSP or multiplier requirement: All operations are shift-add based, with complete removal of dedicated multiplier or DSP logic.
- Superior numerical accuracy: Achieves lower MAE while maintaining lower hardware utilization than prior work.
- Latency and throughput advantage: Fully pipelined operation with minimized critical path per stage due to the mixed-radix acceleration and hardware-adapted digit selection.
Practical and Theoretical Implications
The results demonstrate the viability of CORDIC-based, fully logic-fabric nonlinear operators for use in low-power, high-throughput inference accelerators. This eliminates the traditional necessity of LUTs, multipliers, or division blocks in on-device ML inference, which is relevant for FPGA-embedded, portable, and real-time autonomous systems. In theory, the mixed-radix paradigm can be systematically extended to other transcendental functions (such as tanh6, tanh7, and softplus), enabling general-purpose hardware function blocks for neural and signal processing pipelines.
Prospects for Extension and Future Work
Potential extensions include:
- Support for wider bitwidths: Analysis of dynamic range, quantization error, and resource trade-offs for higher-precision or mixed-precision arithmetic.
- Generalization to other non-linearities: Direct MR-HRC adaptation for GELU, swish, or other non-linearities required in modern transformer-based architectures.
- ASIC and edge integration: Silicon implementation studies, including power and frequency scaling and adaptation for emerging AI-accelerated IoT systems.
- Batch pipelining and multi-channel support: Architectural optimizations for concurrent multi-activation computation in parallelized matrix operations.
Conclusion
This work provides a rigorous, resource-efficient, and highly accurate hardware solution for the sigmoid function targeting modern FPGA platforms. By leveraging a mixed-radix CORDIC structure, the design achieves both algorithmic and architectural efficiency, with empirical results demonstrating low area, absence of multipliers or DSP units, and state-of-the-art numerical precision. These capabilities will facilitate the broader deployment of hardware-integrated neural functions in edge AI, real-time inference, and neuromorphic hardware domains.