- The paper presents a novel algorithm-hardware co-design for deploying Vision Mamba models on FPGA, integrating dynamic quantization and pipelined SSMs.
- It introduces per-channel activation smoothing and APoT weight quantization to mitigate degradation from dynamic outliers and preserve accuracy.
- Empirical results show up to 4.96× speedup and 59.8× energy efficiency gain versus GPU baselines in low-batch ImageNet inference.
ViM-Q: Scalable Algorithm-Hardware Co-Design for Vision Mamba Model Inference on FPGA
Introduction
The paper "ViM-Q: Scalable Algorithm-Hardware Co-Design for Vision Mamba Model Inference on FPGA" (2605.01935) pioneers the deployment of Vision Mamba (ViM) models on resource-constrained FPGA platforms through an algorithm-hardware co-design paradigm. ViM models leverage linear-complexity Selective State Space Models (SSMs), offering a computationally attractive alternative to Transformers for visual tasks without sacrificing representational power. However, their deployment faces crucial bottlenecks: activation and weight quantization often degrade accuracy due to dynamic outliers; hardware accelerators struggle to support dynamic quantization efficiently and to parallelize recurrences; and scalability across model configurations is limited by rigid hardware designs.
Addressing these, ViM-Q introduces a synergistic quantization strategy, a runtime-parameterizable FPGA accelerator, a LUT-based linear engine, and a fine-grained pipelined SSM engine. The result is robust task fidelity and a substantial improvement in low-batch inference latency and energy efficiency relative to state-of-the-art GPU baselines.
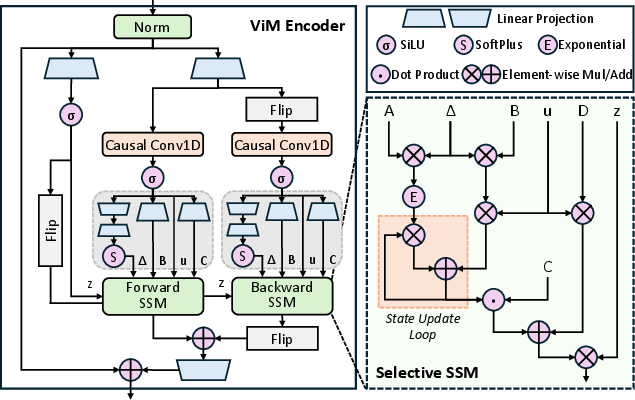
Figure 1: Architecture of the ViM encoder and detailed dataflow of the selective SSM mechanism.
Hardware-Aware Quantization
ViM-Q identifies unique quantization challenges stemming from both persistent channel-wise activation outliers and highly dynamic input-dependent per-token outliers. To mitigate these, the paper combines per-channel activation smoothing—fusing scaling factors into weights—and dynamic per-token activation quantization, where real-time maxima of each token determine optimal scaling for INT8 quantization.
For weights, the model exploits Additive Power-of-Two (APoT) quantization. Unlike uniform schemes, APoT concentrates quantization levels near zero, aligning with the Gaussian-like weight distribution and enabling the replacement of multiplications with bit-shift operations. Granularity is increased via per-block quantization, with local scaling, which substantially improves representational accuracy under low-bit regimes.
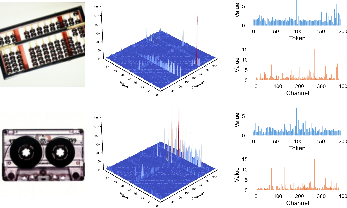
Figure 2: Input images and corresponding activation distributions at the 22nd layer of ViM-tiny, highlighting per-token outlier dynamics.
FPGA Accelerator Architecture
ViM-Q's hardware adopts a modular streaming engine design, partitioned into three primary computational modules:
- Unified Linear Engine: Capable of executing any linear transformation with integrated dynamic activation quantization and APoT-based LUT computation. Multiplications are replaced by pre-computed shift-add via LUTs, and complex nonlinearities are approximated in hardware-efficient fashion.
- Fine-Grained Pipelined SSM Engine: Decomposes SSM computation into concurrent macro-stages, maximizing spatial parallelism along the state dimension while maintaining temporal recurrence fidelity. Matrix and element-wise operations are fused, reducing intermediate accesses and latency.
- Auxiliary Engines: Responsible for patch embedding, convolution, normalization, and residual/gating functionality, all optimized for streaming data compatibility.
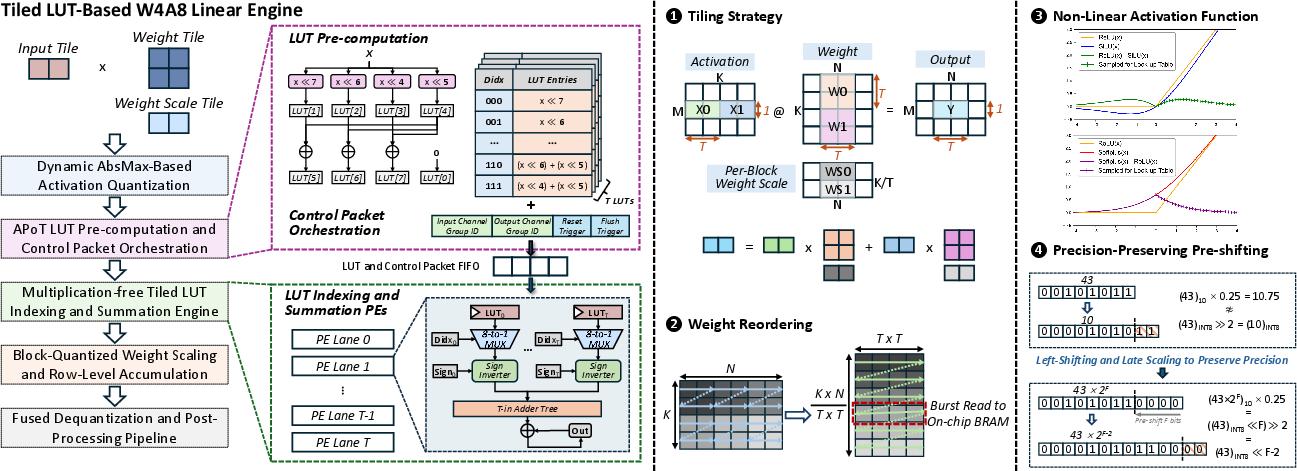
Figure 3: Unified linear engine design with LUT pre-computation and optimizations for streaming tiling, memory-efficient weight layout, LUT-based activations, and precision management.
Quantized Linear Engine and Runtime Optimization
Dynamic quantization imposes significant runtime overhead on GPUs, which struggle to compute token-level scaling and perform INT8-to-FP dequantization efficiently. ViM-Q's FPGA linear engine hides this latency by:
- Computing quantization parameters on-the-fly within a streaming pipeline.
- Leveraging APoT quantization properties for lightweight shift-add arithmetic.
- Employing memory-aligned weight layouts and tiling strategies for flexible runtime reconfiguration.
Latency breakdowns empirically demonstrate the inefficiency of dynamic quantization on GPUs, with the FPGA design decisively outperforming the baseline.
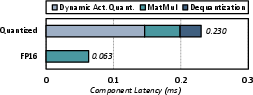
Figure 4: Latency breakdown comparing quantized and FP16 linear layers on NVIDIA RTX 3090.
Pipelined SSM Engine: Parallelizing Sequential Recurrence
Associative scan accelerates SSMs on GPUs but is misaligned with FPGA streaming. ViM-Q resolves this via a three-stage macro-pipeline:
- State Space Update: Parallelized discretization and recurrence, tiling along the state dimension.
- State Projection: Streaming reduction compresses high-dimensional state to features.
- Fused Output Generation: Residual and gating operations are combined in a single pass.
Improvements in spatial parallelism and dataflow allow efficient handling of recurrence without costly memory transpositions.
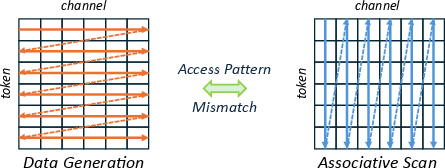
Figure 5: Misalignment in data access between token-major streaming and channel-major associative scan traversal.
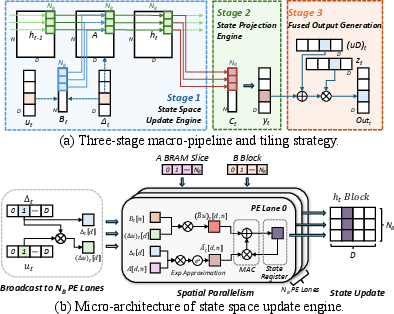
Figure 6: Fine-grained pipelined SSM architecture with macro-stage tiling.
Quantization Efficacy and Design Space Exploration
Experiments benchmark the quantization scheme across ViM-t, ViM-s, and ViM-b. APoT per-block quantization recovers substantial performance relative to uniform and constrained PoT quantization, with negligible accuracy loss for larger models under W4A8 precision. Design space exploration reveals a steep performance drop below 4-bit weights; 4-bit is identified as a practical optimum.
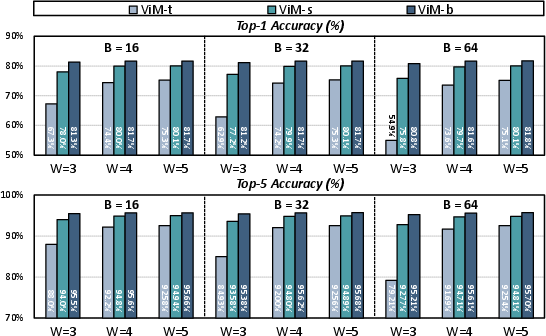
Figure 7: Design space exploration of weight bit-widths W and quantization block sizes B, demonstrating sharp accuracy drops below 4 bits.
Ablation studies reinforce necessity: removing activation smoothing or reverting to static quantization leads to catastrophic accuracy degradation.
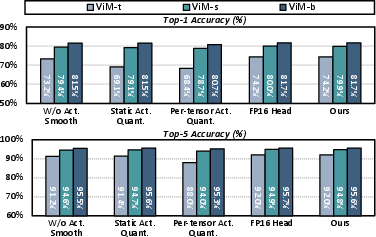
Figure 8: Ablation study on activation smoothing, dynamic quantization, and granularity.
The FPGA implementation achieves robust timing closure, occupying dominant block RAMs for weights and states, while maintaining balanced logic and DSP utilization. Power consumption is modest, and incremental optimizations in the linear engine—spatial tiling, memory alignment, bit-shift arithmetic, precision pre-shifting, and LUT precomputation—maximize throughput and minimize logic overhead.
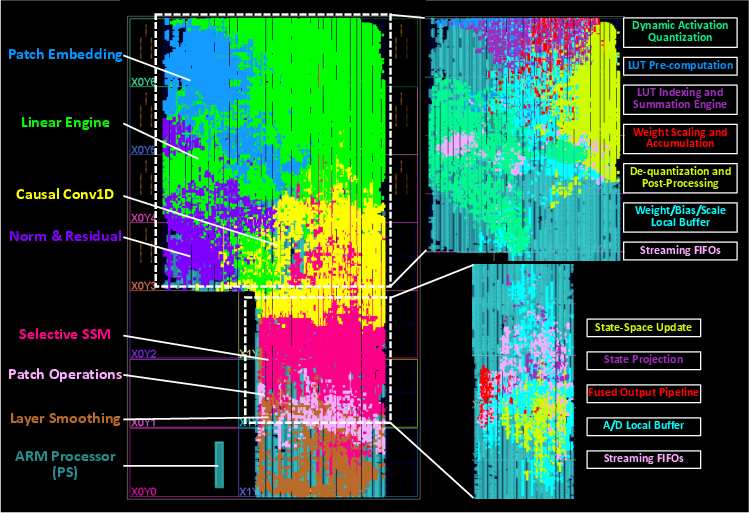
Figure 9: Physical floorplan of ZCU102 FPGA implementation post place-and-route.
Comparison against GPU baselines validates the architectural advantages: ViM-Q attains 4.96× average speedup and 59.8× energy efficiency gain for ViM-t on low-batch ImageNet inference. The quantized GPU baseline is slower than FP16 due to quantization overhead—a problem eliminated by ViM-Q's hardware-centric design.
Throughput and energy scaling across resolutions further reveal the inefficiency of GPUs under low-workload edge scenarios, with ViM-Q preserving its advantage.
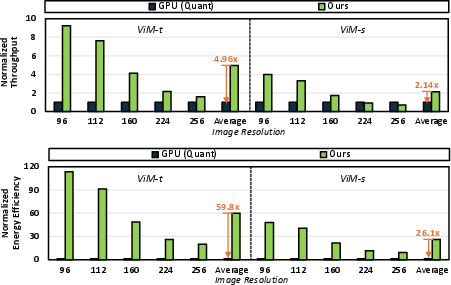
Figure 10: Normalized throughput and energy efficiency across input resolutions; the GPU is normalized to one.
Implications and Future Directions
ViM-Q sets a precedent for algorithm-hardware co-design in vision SSM accelerators. The integration of dynamic, fine-grained quantization with hardware-friendly arithmetic (APoT, LUTs) and spatially recursive SSM pipelines enables model scalability, task fidelity, and dramatic efficiency gains on FPGAs. Practically, these advances will enable robust deployment of vision SSMs in real-time, low-power, edge-centric applications where traditional transformer-based solutions are untenable.
Theoretically, the established quantization and pipeline frameworks respond to nonuniform and dynamic data distributions inherent in SSMs and point toward further integration between model architecture and hardware adaptation. Enhancements could include mixed-precision compute, adaptive tiling, support for larger ViM variants, and generalization beyond vision to sequence modeling or multimodal SSMs.
Conclusion
ViM-Q demonstrates a scalable algorithm-hardware co-design methodology for efficient Vision Mamba inference on FPGA by tightly coupling a dynamic quantization framework with modular hardware accelerators. Its approach yields robust accuracy, significant latency reduction, and unmatched energy efficiency under edge deployment constraints. The architectural insights and quantization techniques presented are likely to influence future efficient SSM and transformer model deployments across a variety of platforms and tasks.