- The paper presents a dual-precision MAC that supports FP8 and FP4 via a novel bit-partitioning multiplier architecture.
- It employs a fully-pipelined datapath with an EC+LUT based exponent comparator to reduce delay and maximize throughput.
- The design achieves up to 60.4% area and 86.6% power reductions, outperforming existing multi-precision MAC designs.
Dual-Precision Hybrid Floating Point Processing Elements for AI Acceleration
Context and Motivation
The proliferation of AI and deep neural network (DNN) workloads on edge devices and data centers has shifted the demand toward low-precision arithmetic to maximize throughput, reduce memory bandwidth, and minimize energy utilization. While FP16 and FP32 are entrenched in the training pipeline, aggressive low-precision formats such as FP8 and FP4 are increasingly favored for inference-centric deployments. The challenge arises from the lack of multiply-accumulate (MAC) engine architectures highly optimized for these narrow formats, as prevalent designs are biased toward higher-precision MACs, incurring unnecessary overhead in area and power. The paper "DHFP-PE: Dual-Precision Hybrid Floating Point Processing Element for AI Acceleration" (2604.04507) addresses this efficiency gap with a highly-optimized, dual-precision MAC processing element (PE) targeting FP8 (E4M3/E5M2) and FP4 (2×E2M1/2×E1M2) workloads.
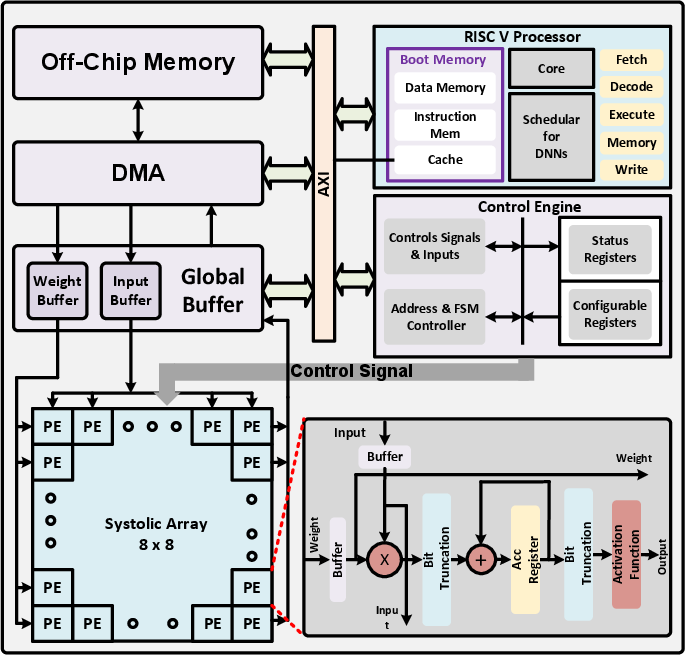
Figure 1: Typical AI Accelerator architecture with emphasis on the Processing Element (PE).
Architectural Innovations
Bit-Partitioned Dual-Precision Multiplier
A core innovation is the bit-partitioned unit multiplier, enabling the same 4-bit multiplier array to function as a 4×4 multiplier (FP8) or as dual 2×2 multipliers (FP4) without hardware replication. This allows for concurrent computation of two FP4 MACs or a single FP8 MAC, substantially improving resource utilization.
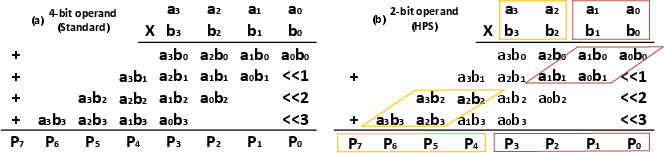
Figure 2: Proposed bit-partitioning method and Unit Multiplier: (a) 4-bit operand for FP8; (b) 2-bit operand for FP4.
This flexibility is crucial for supporting mixed-precision inference workloads, where some layers or blocks can exploit ultra-low precision, and for maximizing throughput in resource-constrained regimes.
Bit-Split-and-Combination MAC
The architecture eschews traditional combination and split MACs—both suboptimal for power and area efficiency—in favor of a bit-split-and-combination design. This approach shares the multiplier array, minimizing recombination and control-level overhead (which are substantial in pure split architectures), and achieves nearly optimal utilization across precisions.
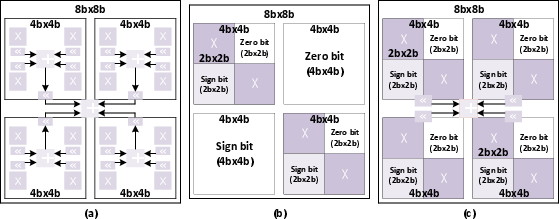
Figure 3: Implementation of variable precision MAC. (a) Combination MAC. (b) Split MAC. (c) Bit-Split-and-combination MAC.
Pipelined Datapath and EC+LUT Comparator
The MAC datapath is fully pipelined with six tightly-coupled stages: input decode, multiplication, alignment shifter, accumulation (using a CSA+CSLA tree), normalization, and output processing with integrated ReLU. The architecture incorporates a three-input EC+LUT-based exponent comparator enabling single-cycle determination of maximum exponents and alignment offsets, thus reducing pipeline depth and critical path delay.
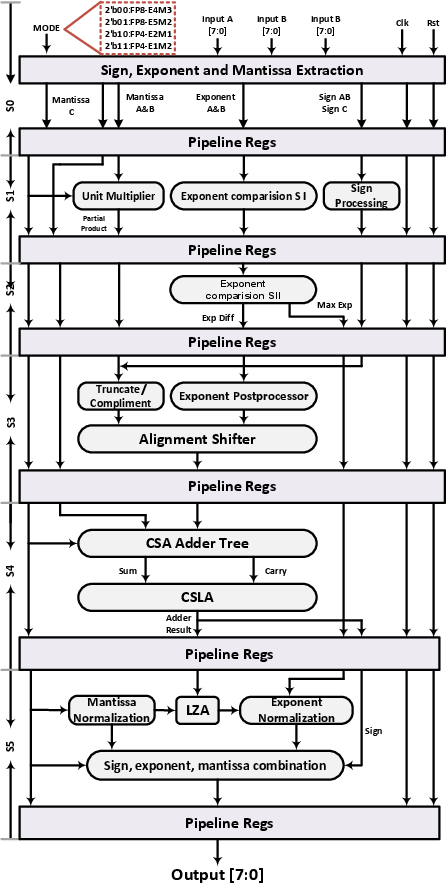
Figure 4: Datapath of the proposed fully-pipelined dual-precision PE.
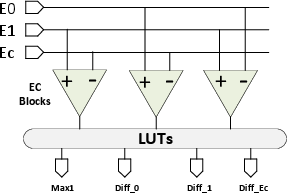
Figure 5: Exponent Comparison Using EC+LUT for Mixed-Precision MAC.
Area, Power and FPGA Resource Efficiency
Synthesized in TSMC 28nm, the design realizes a 0.00396 mm² area and 2.13 mW power at 1.94 GHz. Relative to leading counterparts, it demonstrates up to 60.4% area reduction and 86.6% power reduction, with reductions in FPGA LUT/FF usage of >90% versus recent benchmarks.
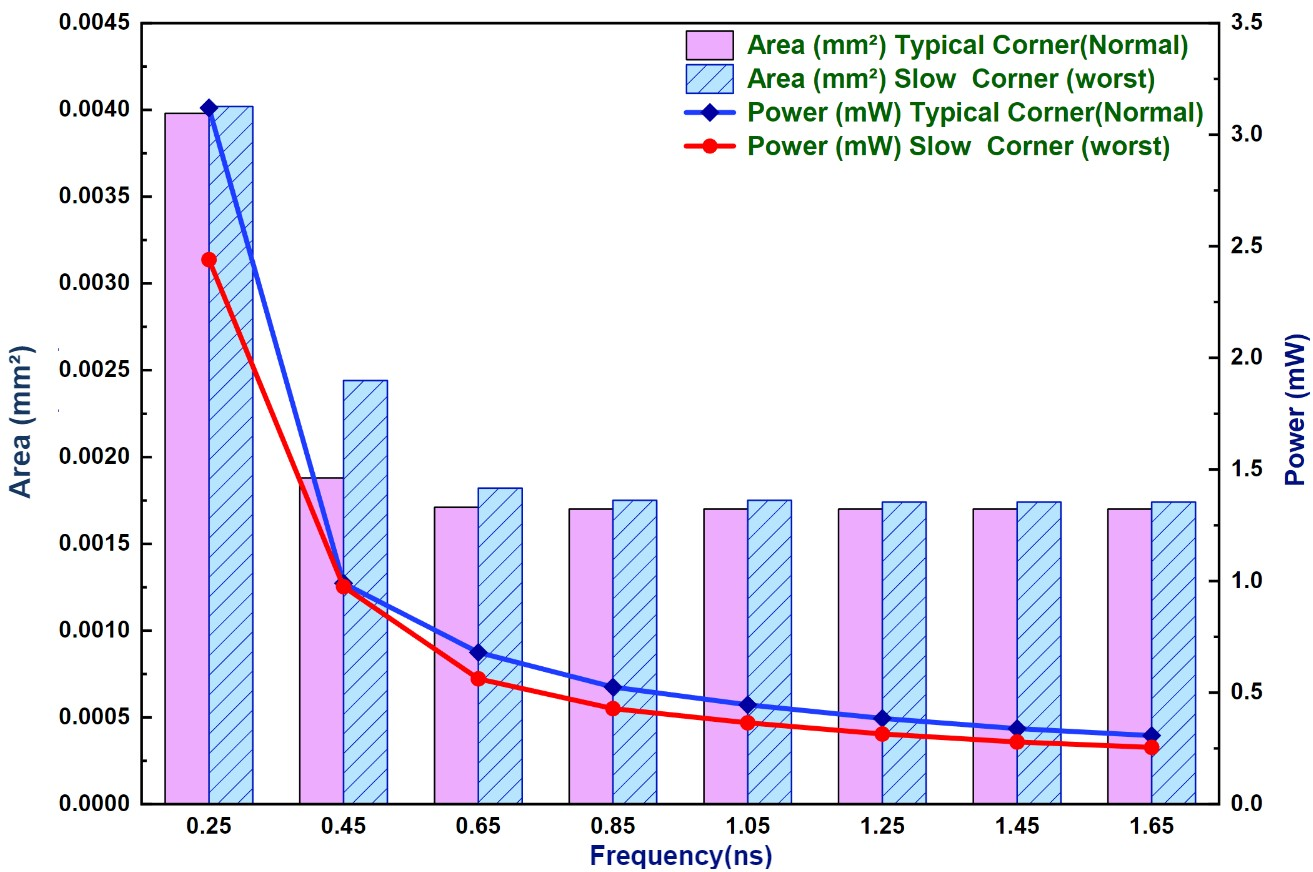
Figure 6: Area and power variations subject to different clock period constraints: Typical corner ; Slow corner.
Throughput and Energy Efficiency
The DHFP-PE delivers 7.75 GFLOPS (FP4) and 3.88 GFLOPS (FP8), with energy efficiencies of 3632 GFLOPS/W (FP4) and 1818 GFLOPS/W (FP8). These figures substantially exceed several recent multi-precision designs:
In comparison to multi-precision floating-point accelerators, the proposed PE is more area- and energy-efficient at the MAC level relative to large, monolithic designs such as FPnew [ref1] or the systolic arrays described in ISCAS'24. The central advantage remains the aggressive and practical dual-precision support without duplicating multiplier resources and with minimal control logic inflation, which is non-trivial in the 4-bit domain.
Practical and Theoretical Implications
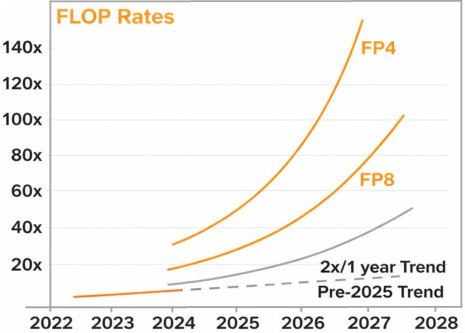
The work reaffirms the hardware trend forecasted by leading GPU vendors (as shown by the ROCm Precision Support Figure from AMD, Fig. 2) toward reduced precision for throughput scaling. The PE architecture’s compactness and precision-scalability provide a highly viable path for integrating substantial PE counts per mm², essential for massively parallel DNN accelerators and edge-AI deployments with stringent area and energy budgets.
From a theoretical standpoint, the design exemplifies optimality in multi-precision datapath utilization: the masking and partitioning methods avoid both logic underutilization (common in fixed full-precision MACs) and combinatorial expansion (in shift-recombine designs), showing that practical bit-level reconfiguration is feasible and high-performance at sub-8b precision.
The EC+LUT comparator also exemplifies architectural forward-mapping: addressable lookup tables replace deep combinational logic for exponent selection, a method that could be adapted in other ultra-low precision floating-point designs to resolve critical path bottlenecks.
Future Directions
Natural extensions include:
- Incorporating additional low-bit-width numerical formats (e.g., Posits, INT4/INT8) to broaden applicability to quantized networks.
- Array-level architectural integration into systolic arrays or SIMD clusters, where the benefits in PE area and power can compound, increasing PE density and system-level throughput.
- Deployment in open-source AI accelerator fabrics, exploring trade-offs in real workloads (such as attention blocks in transformers or MLP-mixers) where mixed-precision computation becomes a first-class architectural feature.
- Enhancements for on-the-fly dynamic precision reconfiguration based on workload profiling or layer-wise quantization awareness to maximize energy-delay-product across inference and (potentially) quantized training workflows.
Conclusion
"DHFP-PE: Dual-Precision Hybrid Floating Point Processing Element for AI Acceleration" (2604.04507) introduces a PE architecture that leverages a novel bit-partitioned multiplier and fully-pipelined datapath to optimally support FP8 and FP4 operations. The design achieves state-of-the-art area and power efficiency without compromising throughput, outperforming recent academic and industrial designs. Its approach to dual-precision and masking-driven hardware utilization provides a blueprint for the next generation of highly-parallel, inference-optimized AI accelerators. Further system-level integration and support for broader numerical formats will increase the practical impact and adoption in edge AI and high-density accelerator fabrics.