- The paper presents a reconfigurable multiplier architecture that dynamically switches between exact and approximate operations using controllable error registers.
- It integrates reconfigurable compressor designs in an 8-bit core scalable to 32-bit, achieving up to 68% power reduction and 13% area savings.
- The results validate energy-efficient computing in edge AI by balancing controlled approximation error with maintained system performance.
A Reconfigurable Multiplier Architecture for Error-Resilient Applications in RISC-V Core
Introduction
The paper introduces a reconfigurable multiplier architecture tailored for error-resilient applications, with integration into a RISC-V processor pipeline targeting energy-constrained edge AI contexts. Recognizing the inherent error tolerance of neural network workloads, the design exploits dynamic, runtime-controllable approximation in multiplication for substantial energy savings. The novelty lies in supporting both exact and approximate computation, with fine-grained, programmable error control via dedicated CSRs, in contrast to previous static or limited-granularity designs.
Architectural Design: Runtime-Configurable Multiplier Integration
The proposed architecture is realized in the open-source phoeniX RISC-V core, featuring a 3-stage pipeline (IF/ID, EXE, MEM/WB). Critical to the architecture is the execution stage, where the standard fixed-precision multiplier units are replaced by a single, runtime-reconfigurable multiplier. The design leverages the mulcsr CSR register, enabling dynamic switching between exact and approximate modes and providing dedicated bitfields for controlling the error level in the multiplier's datapath.
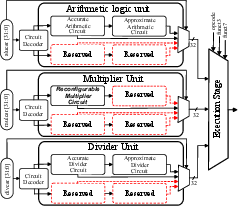
Figure 1: Execution stage of the processor showing integration of the proposed reconfigurable multiplier.
A typical software-level use case is demonstrated via RISC-V assembly, setting the approximation policy before invoking compute-intensive operations.
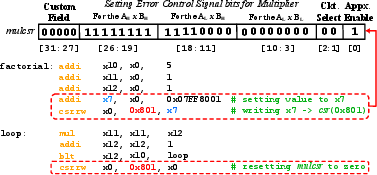
Figure 2: Sample assembly code showing the use of mulscr for runtime approximation control in a factorial computation.
Reconfigurable Compressor Design
Two reconfigurable 4:2 compressor primitives are designed as the cornerstone of the multiplier architecture:
- RFA/DFC: The Reconfigurable Full Adder-based compressor supports exact/approximate operation per error control signal, exhibiting a higher error rate but greater energy savings.
- SSC: The Single-Stacking-based compressor provides a more conservative accuracy/efficiency tradeoff, with fewer erroneous combinations and limited error distance.
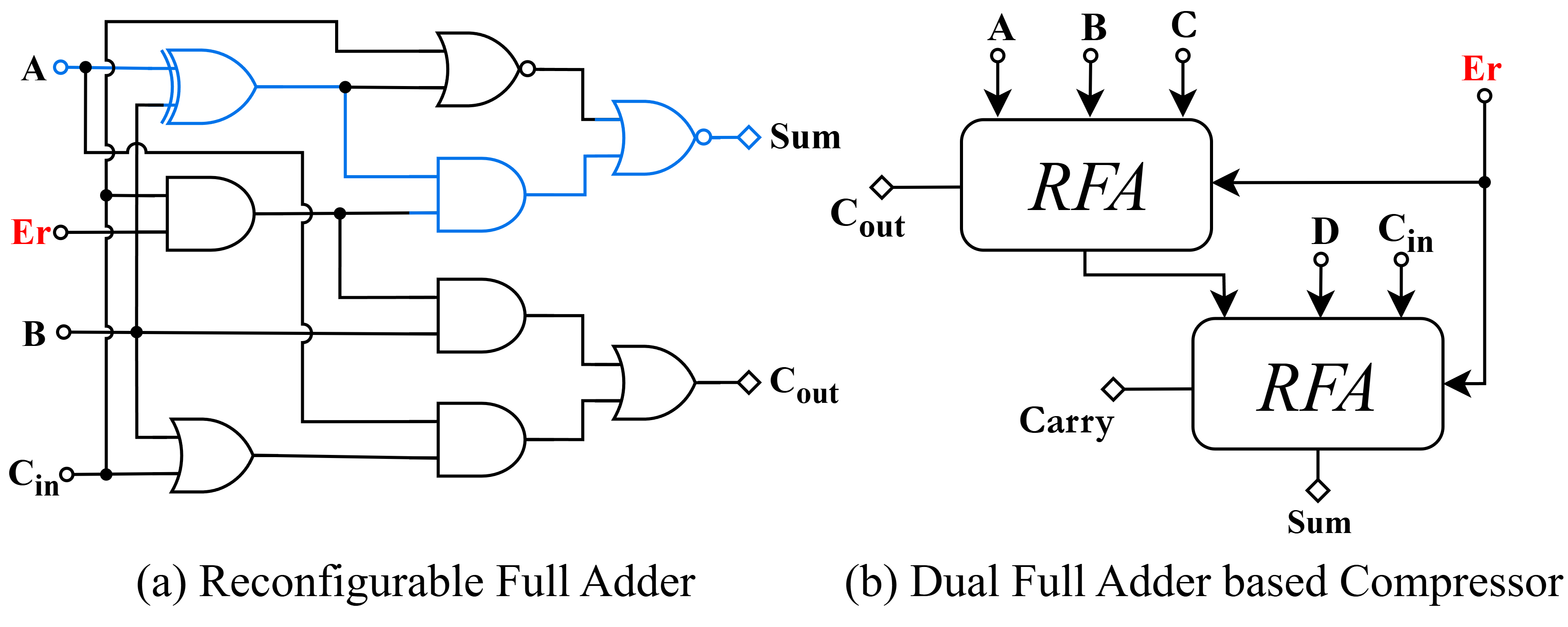
Figure 3: Architectural block diagrams of the proposed Reconfigurable Full Adder (RFA) and Dual Full Adder-based Compressor (DFC).
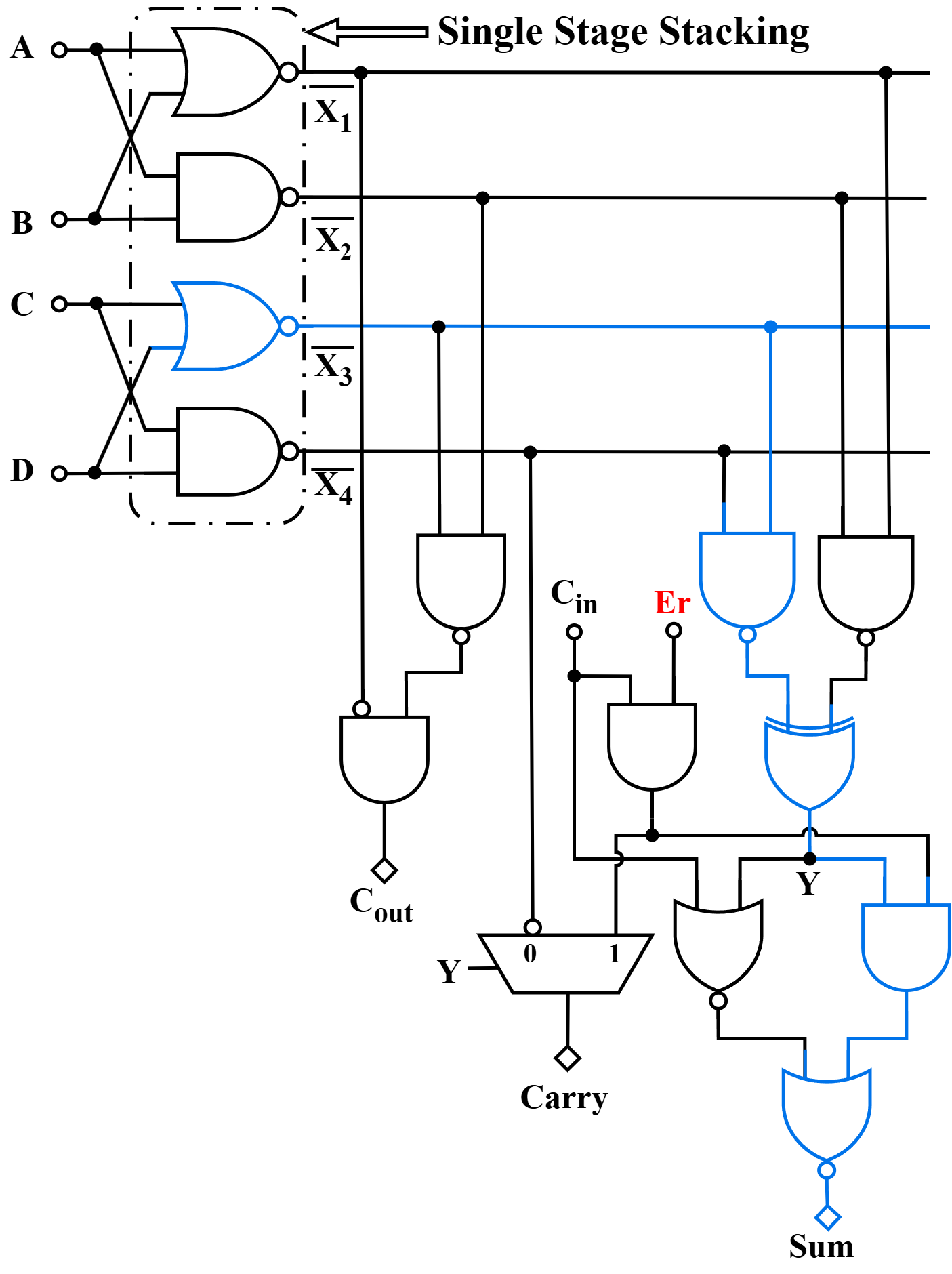
Figure 4: Structure of the Single Stacking-based reconfigurable Compressor (SSC).
Multiplier Microarchitecture and Scalability
The compressor cells are instantiated in an 8-bit unsigned multiplier core, whose columns are partitioned into "reconfigurable" regions controlled in real time via the Er error signal. DFM employs the DFC compressor for aggressive approximation, while SSM uses the SSC for applications with tighter error bounds. The design is hierarchically expanded for 16-bit and 32-bit multipliers required by the RV32I(E)M ISA by multiplexed and parallel instantiation, facilitating per-segment approximation control.
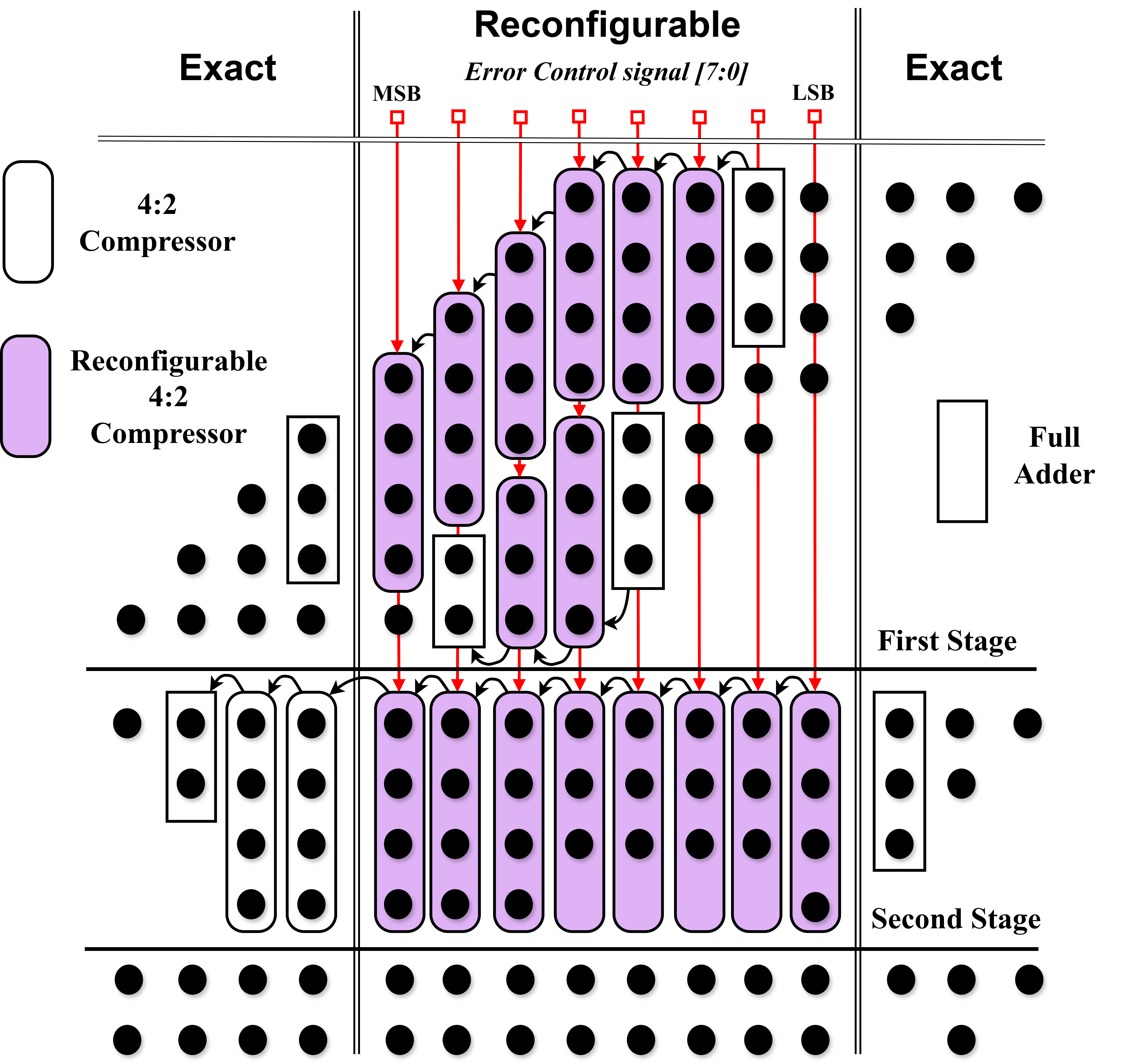
Figure 5: Schematic of the proposed reconfigurable 8-bit multiplier with control signal ER.
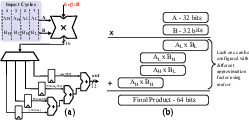
Figure 6: Compositional structure for 16-bit and 32-bit reconfigurable multipliers using the 8-bit core.
The design enables up to 255 resolution levels of approximation, with full software visibility through the CSR interface.
Error Behavior and Programmability
A detailed analysis presents the tradeoff between error metrics (mean relative error distance, error rate) and controlled approximation. SSM consistently exhibits lower error rates but higher positive bias in MRED, whereas DFM demonstrates higher error rates but with error cancellation effects on MRED due to symmetric error injection.
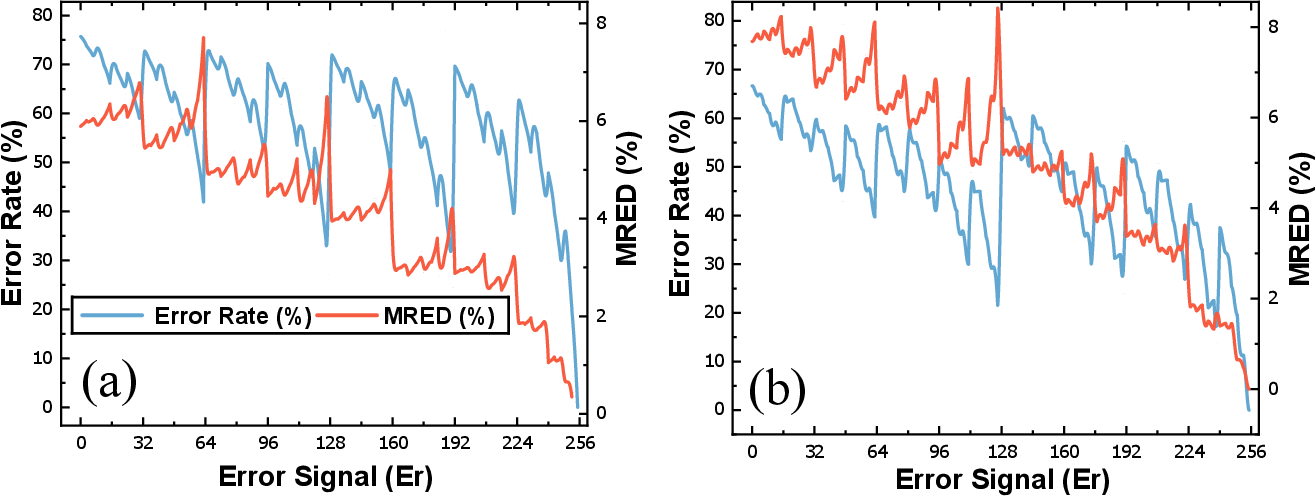
Figure 7: MRED and error rate variation as a function of error control signal (Er) for SSM and DFM designs.
The programmable architecture allows runtime adaptation of multiplier fidelity at the level of each sub-multiplier (8/16/32b), critical for deploying diverse applications with variable error sensitivity.
Hardware Implementation and System-Level Results
The architecture is synthesized on UMC 90nm CMOS using Synopsys/Cadence flows and benchmarked in real RISC-V edge-class processor cores. The unified reconfigurable multiplier yields a 13% area and 11% power reduction compared to baseline multi-multiplier designs, with no penalty in core performance (1.89 DMIPS/MHz sustained).
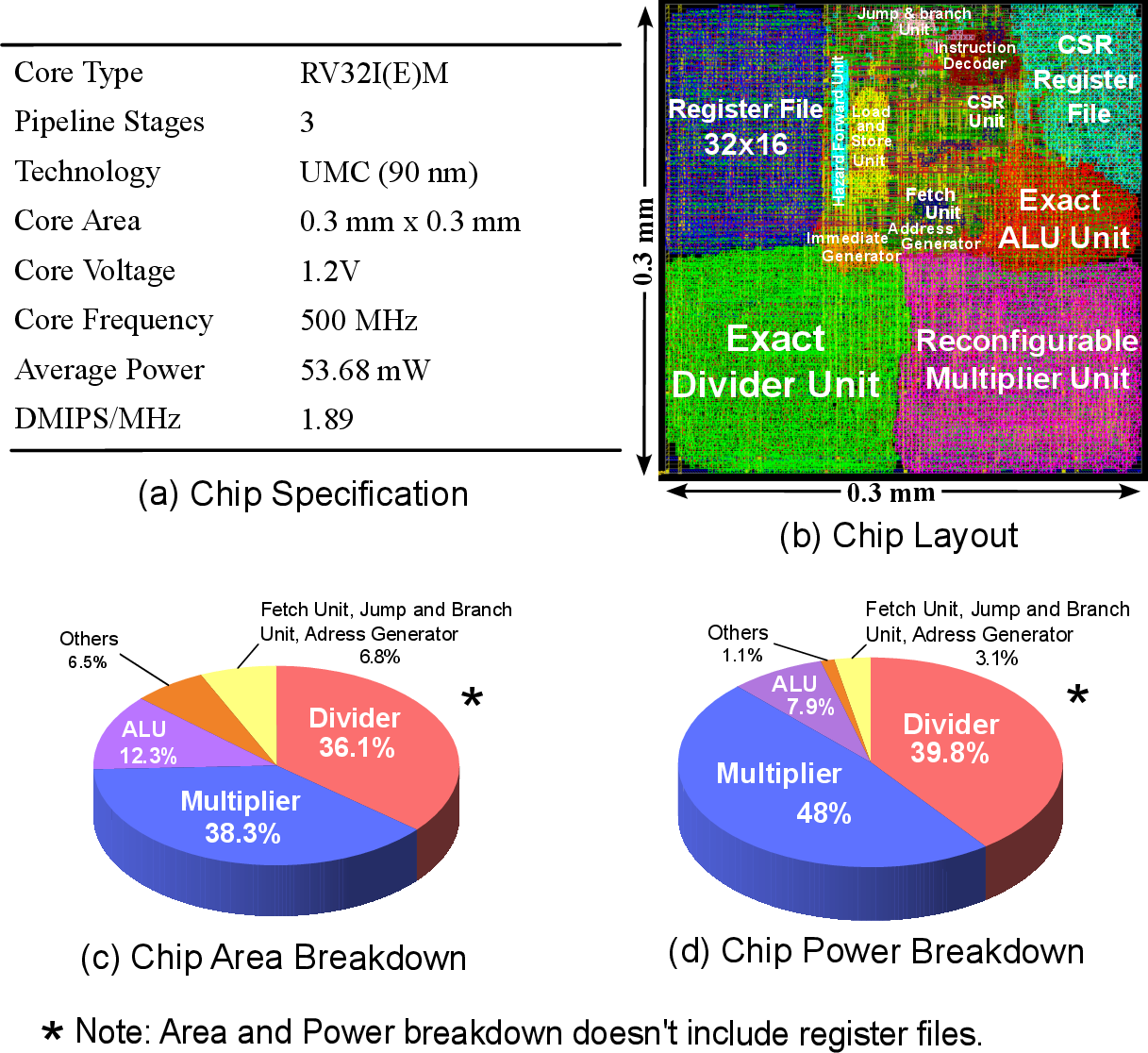
Figure 8: (a) Modified phoeniX core specification, (b) chip layout, (c) area distribution, and (d) power breakdown in the core.
A breakdown highlights the dominant share of datapath area and power attributed to the multiplier; consolidation to a single runtime-morphable unit results in significant efficiency gains.
Evaluation in Edge AI and Error-Resilient Workloads
Empirical validations employ compute-dominated workloads (2D Convolution, Matrix Multiplication, DSP kernels, factorial computation), all exhibiting a high degree of native error tolerance.
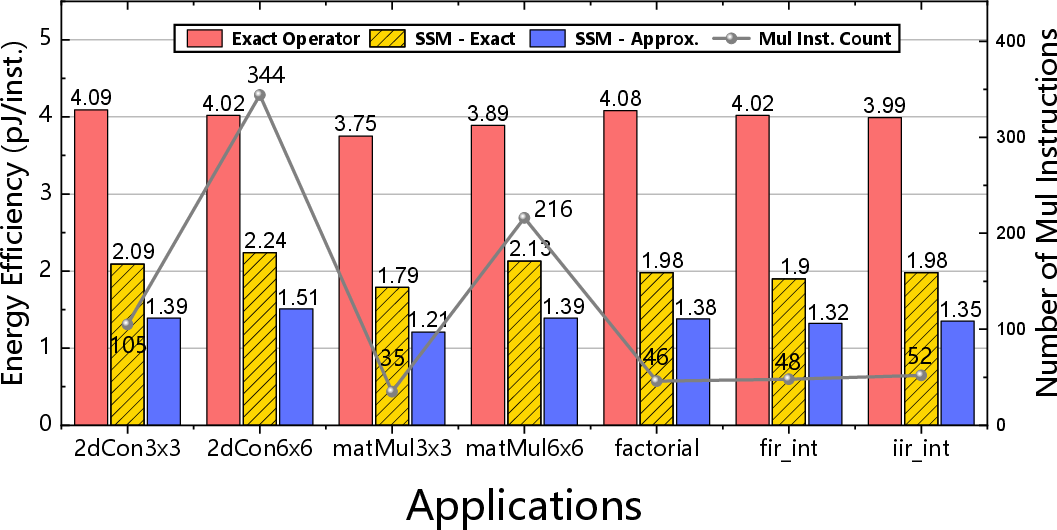
Figure 9: Energy efficiency (pJ/instruction) alongside count of mul and mulh instructions in typical edge workloads.
Approximate mode achieves up to 63% energy savings (matrix multiplication), with per-instruction energy at 1.21 pJ and power reduction in the approximate SSM configuration reaching 68%, all without affecting overall system throughput.
Additional experiments on power and CPI affirm that switching to approximate mode halves or further reduces multiplier power, with minimal impact on cycles-per-instruction due to sustained pipeline utilization.
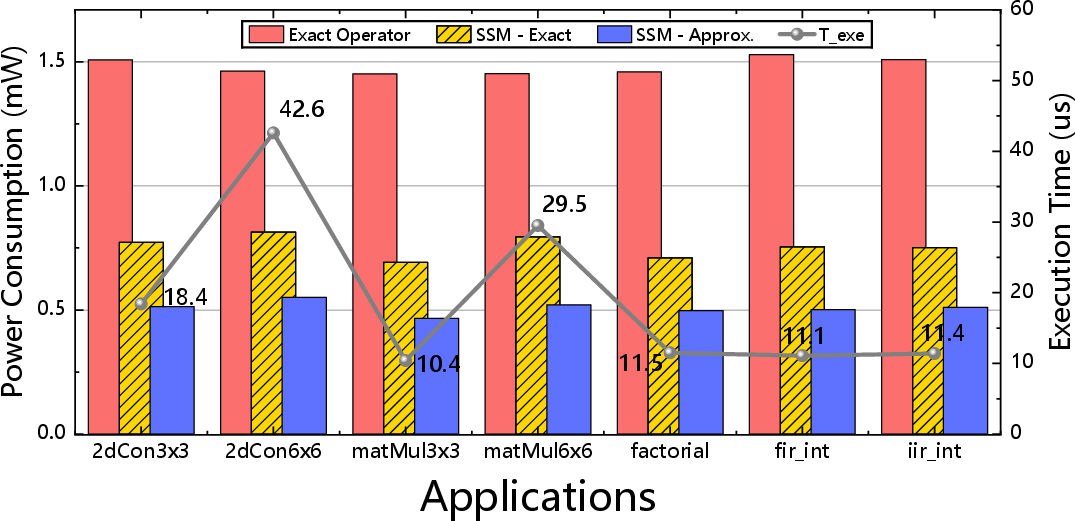
Figure 10: Multiplier unit power consumption and workload execution time profiles.
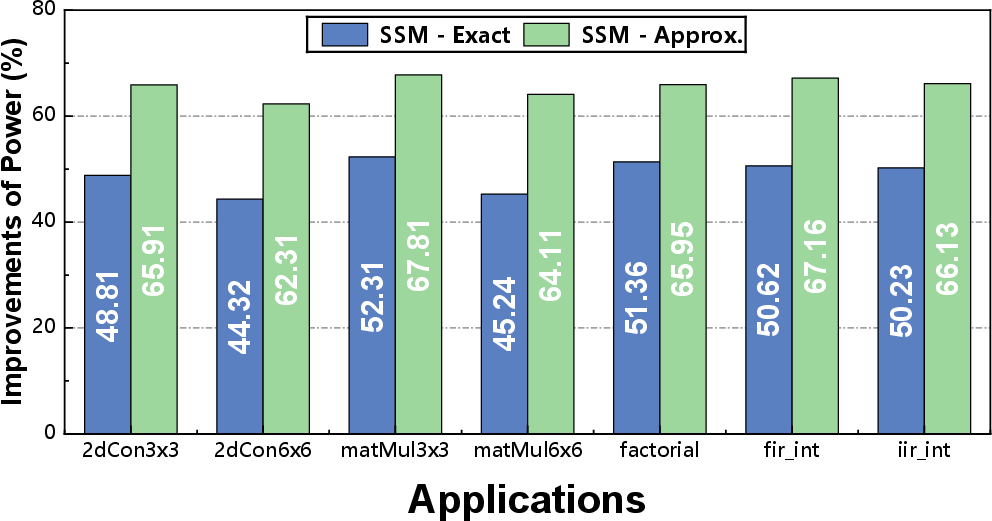
Figure 11: Power consumption improvements (relative reduction) for SSM in both exact and approximate modes.
Implications and Future Research Directions
The proposed multiplier architecture demonstrates that seamless, fine-grained runtime tradeoffs between accuracy and power consumption can be achieved without area/performance compromise at the system level. This has several direct implications:
- Energy-proportional AI: Edge AI workloads can dynamically select optimal energy/accuracy envelopes per task or layer.
- Security, Reliability, and Adaptation: The programmable error profile exposes new control surfaces for adaptive error resilience, hardware security via controlled obfuscation, and workload-aware computation.
- Standardization in ISA Extensions: The approach is flexible for extension to signed, floating-point, or vectorized operations and motivates further ISA support for hardware approximation primitives.
- Hardware-Software Co-Design: The runtime reconfiguration paradigm promotes software-hardware co-design for deploying quantized/approximate inference in resource-constrained environments.
Conclusion
This work presents a scalable, runtime-switchable multiplier architecture for RISC-V cores offering controlled accuracy/power tradeoffs through software-accessible CSRs. By integrating reconfigurable compressor units and supporting both exact and multiple approximation schemes, the design achieves substantial energy savings—up to 68%—with negligible area and no performance regression. The approach provides a practical pathway for adaptive, error-resilient, and energy-efficient computing in embedded and edge AI domains.

